







一、样本ood方法(基于CLIP)
1.CoOp
2022年的《Learning to Prompt for Vision-Language Models》
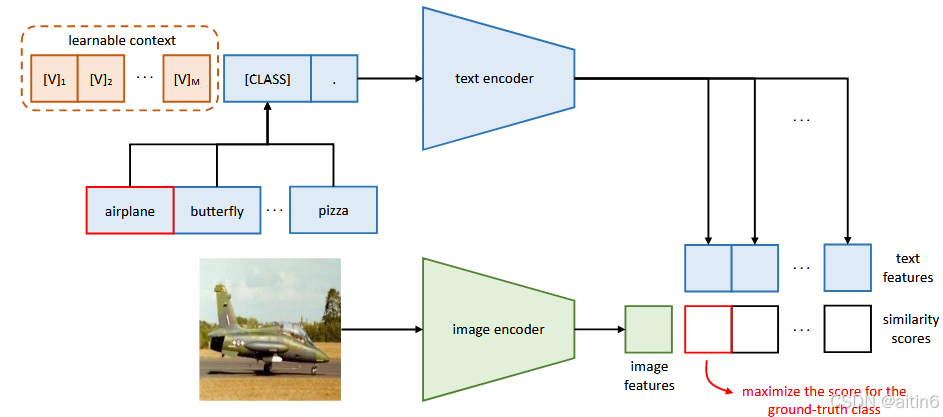
原本clip的文本是”This is a photo of ”,CoOp将这段文本表征变成可学习的参数,提升了泛化到下游任务的能力,开启了提示学习的时代。
2.CoCoOp
2022年的Conditional Prompt Learning for Vision-Language Models
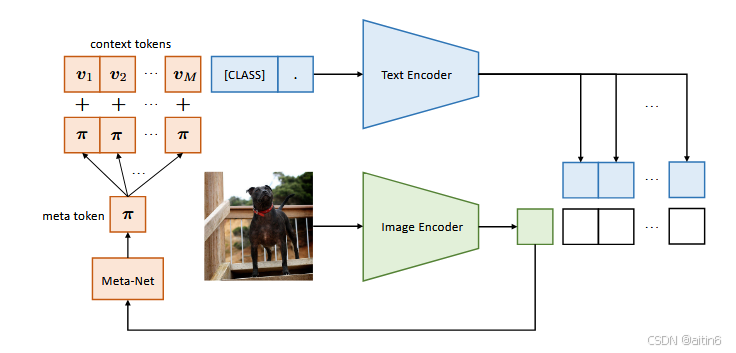
作者认为CoOp 过度拟合了训练期间观察到的基本类。
为解决该问题,他提出了一个meta-Net。每一张图片的表征都会经过meta-Net得到meta token再加到可学习的表征v上。
CoCoOp展现出更强的域泛化能力
3.LoCoOp
2023年的LoCoOp: Few-Shot Out-of-Distribution Detection via Prompt Learning
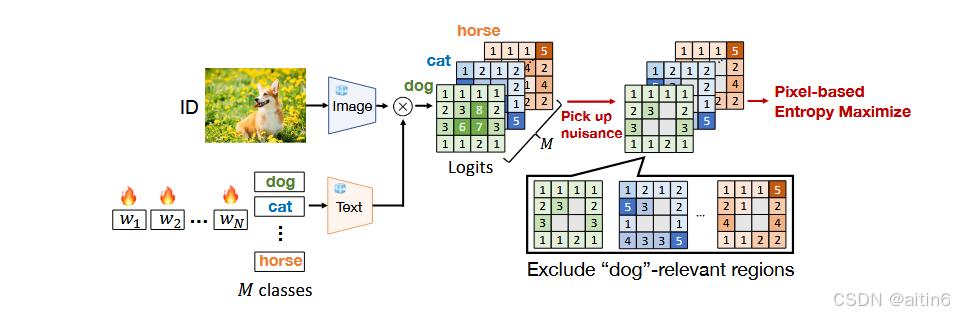
核心思想:图像中有与文本相关的ID区域,和不相关的OOD区域。让模型在图像OOD区域做出的预测logits熵最大化,从而提高模型的(小样本)OOD检测能力。
区分ID和OOD做法:将图片分割成若干区域,每块区域与M个种类的文本都会产生CLIP的M个预测logits,设定固定值k,若m个logits的前k个包含该标签的label,则图片视为ID,否则视为OOD
4.PLOT:
2023年的PLOT: PROMPT LEARNING WITH OPTIMAL TRANSPORT FOR VISION-LANGUAGE MODELS
Ps:讲真,最优传输这部分不是很懂,我只清楚这个适合做风格迁移等工作
核心思想:一个类不应该只由一个提示词来定义,但是多个提示词一起训练容易收敛到同一个点。作者提出最优传输的方式来训练多个不同的提示特征
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









