






一、综述阅读《Generalized Out-of-Distribution Detection: A Survey》
1. 各子任务分类与定义
异常检测(AD): 识别那些与大多数正常样本明显不同的样本(视为恶意)
新奇检测(ND):识别那些与大多数正常样本明显不同的样本(视为新知识)
开放集识别(OSR): 在训练时,模型只能接触到一部分的类别(ID类),在测试时需要不仅识别已知类别,还要区分不属于任何已知类别的样本(OOD类),一般限定在一个数据集。
出分布检测(OOD): 在多类别设定中与OSR任务类似,但允许从不同数据集获取OOD数据,以保证类别不重叠。
离群检测(OD): 异常值检测通常在训练数据集前进行,相当与数据集的预处理,与训练方案无关
2. 方法分类
(1 )协变量偏移:输入数据的分布发生了变化。
语义偏移:样本的语义或类别发生了变化。
(2)多类别与单类别
(3)是否需要对 ID数据 进行分类。ID数据 是指来自“已知域”(In-domain, ID)的数据,也就是模型在训练时已经接触过的数据。
(4)Transductive学习:要求模型在推理阶段同时访问训练数据(ID数据)和测试数据(包括ID和OOD数据)。在这种任务中,模型利用所有的观测数据(即ID和OOD数据)来进行预测。
Inductive学习:遵循常见的训练-测试(train-test)方案。在训练阶段,模型只接触训练数据(ID数据),并通过这些数据学习一个泛化的规则或模型。在测试阶段,模型对未知的测试数据进行推理。
3.ood方法
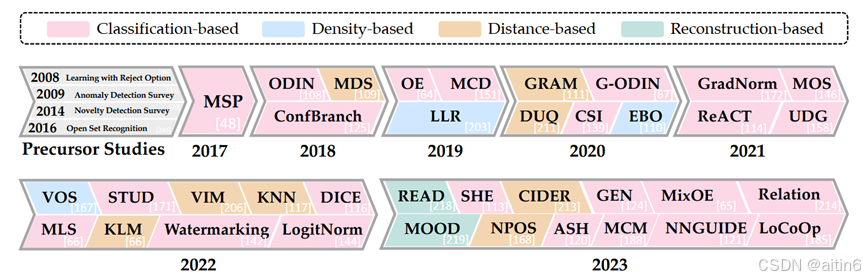
3.1基于输出
3.1.1.Post-hoc Detection
ODIN
使用温度缩放和输入扰动来放大ID/OOD的可分性
SHE
使用代表类的存储模式来测量 OOD 检测的看不见数据的差异,与经典能源方法相比,这是无超参数且计算效率高的。
ReAct
提议截断高激活率,从而建立强大的事后检测性能,并进一步提高现有评分函数的性能。
NMD
使用 BatchNorm 层的激活手段来解决 ID/OOD 差异。
DICE
基于 ReAct 考虑激活空间,提出了一个基于权重稀疏的 OOD 检测框架。
ASH
根据 top-K 标准从后层中删除了很大一部分(例如,90%)输入的特征表示,然后通过缩放或分配常量值来调整剩余的激活值(例如,10%)
3.1.2.Training-based Methods
G-ODIN
通过使用称为 DeConfC 的专门训练目标并选择超参数(如 ID 数据的扰动幅度)来扩展 ODIN
LogitNorm
一种简单的修复方法在训练中对logits施加一个常数向量范数来修正常见的交叉熵损失。
标签空间的重设计
自上而下的分类策略 和组 SoftMax 训练;词编码,稀疏的 one-hot 标签被来自不同 NLP 模型的多个密集词嵌入所取代,形成多个回归头,实现稳健训练
3.1.3基于异常值暴露
1)真实异常值(看不懂)
OECC、MixOE
2)异常值数据生成
GAN、元学习生成
VOS
从特征空间中的低似然区域合成虚拟异常值,这在较低维度的情况下更容易处理。
NPOS
也生成异常值 ID 数据,但采用非参数方法。
DOE
合成了导致最糟糕判断的硬 OOD 数据,以使用最小-最大学习方案训练 OOD 检测器
ATOL
使用辅助任务来缓解错误的 OOD 生成。在对象检测中,[171] 提议使用时空未知蒸馏从野外视频中合成未知对象
3.1.4基于梯度
ODIN
首先探索了使用梯度信息进行 OOD 检测。特别是,ODIN 提议通过添加从输入梯度获得的小扰动来使用输入预处理。ODIN 扰动的目标是通过加强模型对预测标签的信念来提高任何给定输入的 softmax 分数。最终,发现扰动在 ID 和 OOD 输入的 softmax 分数之间产生了更大的差距,从而使它们更容易分离并提高 OOD 检测的性能。
GradNorm
从梯度空间显式地推导出评分函数。
3.1.5基于贝叶斯模型
太数学啦看不懂
3.1.6基于基础模型
在训练数据中为具有特定语义(标签)空间的下游任务调整(调整)这些模型仍然是一个挑战
LoCoOp
将 OOD 正则化引入 CLIP 的局部特征的子集,被识别为 OOD,增强了提示学习以更好地区分 ID 和 OOD
LSA
使用双向提示定制机制来增强图像-文本对齐。
ZOC
训练一个基于 CLIP 的视觉编码器的解码器来创建用于 OOD 检测的候选标签。
MCM
选择了 softmax 缩放来使视觉特征与文本概念保持一致,以进行 OOD 检测。
CLIPN
创新性地在 OOD 检测中集成了 “no” 逻辑。
3.2基于密度的方法
使用一些概率模型显式地对内分布进行建模,并将低密度区域中的测试数据标记为 OOD
3.3基于距离的方法
测试 OOD 样本应该离分布类的质心或原型相对较远。
3.3.1.将图像分为前景和背景,然后计算两个空间之间的马氏距离比
3.3.2.最近的工作表明有很大的非参数最近邻距离对 OOD 检测希望
3.3.3.测试样本特征和类特征之间的余弦相似性来确定 OOD 样本
3.3.4.输入嵌入和类质心之间的径向基函数核 、欧几里得距离和测地线距离
3.3.5.主空间的正交补体空间中的特征范数
3.3.6.CIDER [213]探讨了嵌入在超球空间中的可用性,其中可以鼓励类间离散和内部类紧凑性。
3.4.OOD基于重建的方法
在 ID 数据上训练的编码器-解码器框架通常会对 ID 和 OOD 样本产生不同的结果。模型性能的差异可以用作检测异常的指标
MoodCat
不重建整个图像,而是掩盖了输入图像的随机部分,并使用基于分类的重建结果的质量来识别 OOD 样本。
READ
通过将原始像素的重建误差转换为分类器的潜在空间,将分类器和自动编码器的不一致组合在一起。
MOOD
与对比训练和经典分类器训练相比,用于预训练的掩码图像建模有利于 OOD 检测任务。
4.OSR的方法
其他方法其实大跟OOD大同小异,没有细看,只是把OSR的地方记录了一些。
OSR
基于分类的方法
CAP
显式地对类成员从 ID 点减少到 OOD 点的概率进行建模
EVT
专注于对具有极高/极低值的尾部分布进行建模
OpenMax
为神经网络实现了 EVT。OpenMax 将 softmax 层替换为 OpenMax 层,后者使用每类 EVT 概率模型(如 Weibull 分布)校准 logits。
基于重建的方法
C2AE训练一个以标签向量为条件的解码器,并使用EVT估计重建的图像以区分未知类别。
二、综述阅读:《Generalized Out-of-Distribution Detection and Beyond in Vision Language Model Era: A Survey》
这两篇文章是同一批人写的,上一篇是24年1月,这一篇是24年7月,这篇主要是针对近些年生成式模型在ood上的应用(点名CLIP)做的补充,一些基础知识跟上一篇重复部分不再赘述
Vision Language Models (VLMs)
视觉语言模型(VLMs)是一类能够同时处理视觉(图像、视频)和语言(文本)输入的模型。这类模型能够通过将视觉和语言模态相结合,解决如图像描述生成、图文匹配、跨模态检索等任务。
现在大多视觉模型方法依赖于CLIP
1.基于CLIP的OOD方法
1.1零映射ood:训练跟推理都不用ID图片,只有类别的文本信息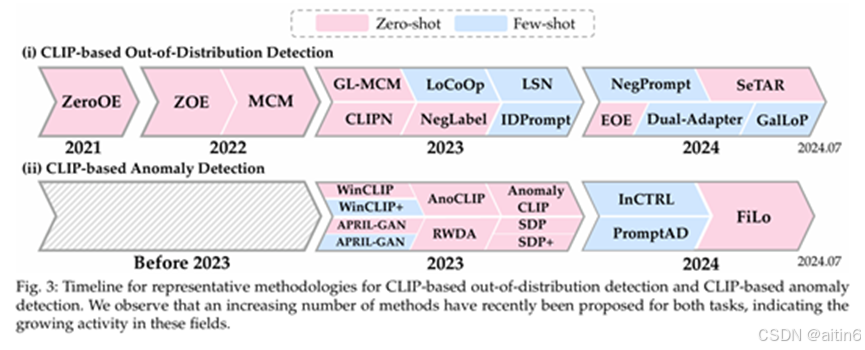
1.2基于ood prompt 的零映射:
早期方法:ZeroOE
通过将潜在的OOD标签输入到CLIP的文本编码器中来进行检测。然而,使用已知OOD标签的方法在实际应用中难以实现,因为它们不适用于实际的未知标签。
改进方法:ZOC
训练基于CLIP视觉编码器的OOD标签生成器,生成伪OOD标签用于检测。尽管这一方法在理论上具有优势,但在处理包含大量ID类别的大规模数据集时,生成器可能无法生成有效的候选OOD标签,导致检测性能不佳。
近期进展:高质量OOD标签的获取
近期研究集中在如何获取高质量的OOD标签,主要通过以下两种方法:
(i) OOD标签检索:
NegLabel:这是一种检索方法,通过计算从广泛语料库中提取的OOD标签与ID标签之间的距离,选择高质量的OOD标签。这种方法利用距离度量来筛选出与ID标签区分度较高的OOD标签,从而提高检测的效果。
(ii) OOD标签生成:
EOE(Enhanced OOD Estimation):EOE使用大型语言模型(LLMs)生成高质量的OOD标签。通过调整LLM的提示,EOE能够适应多种任务,包括远距离和近距离的OOD检测。生成的标签可以更好地覆盖实际场景中的OOD样本,提高检测性能。
1.3无ood prompt的零映射:
1.MCM 是一种简单但有效的方法,它通过调整Softmax的缩放来对齐视觉特征与文本概念,用于OOD检测。
2. GL-MCM增加一个局部MCM评分来增强细粒度检测能力,尤其是针对图像局部区域的异常检测能力。
3. SeTAR
通过使用一种简单的贪婪搜索算法,改变模型的权重矩阵,以提高检测的精度和稳定性。
这些方法被称为后处理方法,因为它们在已有的ID分类器基础上进行调整,用于OOD检测。
1.3基于辅助训练的零映射:
CLIPN :设计了一个可学习的“No”提示(prompt),并引入了额外的“No”文本编码器,用来捕捉图像中的否定语义。该方法通过学习否定信息,帮助模型在面对OOD样本时更有效地拒绝。
1.4无ood prompt的小样本OOD:
PEFT-MCM展示了参数高效微调与MCM结合的效果。
LoCoOp是提示学习在少样本OOD检测中的一个重要里程碑,专注于非ID区域的OOD正则化。
GalLoP进一步扩展了提示学习,利用ID区域实现更精细的检测。
1.5基于ood prompt的小样本OOD:
LSN (Learned Suitable Negative prompts) 和 NegPrompt 是同时提出的少样本OOD检测方法。
LSN 为每个类准备独特的负提示,并为每个类学习合适的负提示,以便更准确地检测OOD样本。
NegPrompt 则为所有ID类准备通用的负提示,并训练这些提示以学习表示任意给定类标签的负语义模板。
IDPrompt 采取了不同的策略,通过引入ID-like prompts,检测接近ID特征的OOD样本。IDPrompt在ID训练图像中提取ID-like的OOD区域,并用这些提取的OOD数据来训练ID-like提示。
LAPT 提出了自动样本收集策略,只利用ID类名来检索或生成训练ID图像,避免了图像收集和标注的成本。然后,LAPT执行分布感知的提示学习,通过区分ID类和OOD类的标记,来提高检测性能。
Open Vocabulary OOD (OV-OOD)检测:定义了一个ID标签的子集 YID,sub ⊂ YID,在训练期间只使用这个子集对应的训练数据集 Dtrain ID,sub。在推理阶段,使用所有ID类数据 YID 和OOD测试数据 Dtest OOD 来检测OOD。
1.6免训练的少数样本OOD检测
只有双适配器[99]属于这一类。Dual-Adapter 采用基于先验的方法 TipAdapter [113],该方法将文本和视觉特征与缓存模型相结合,无需训练即可提高性能。为了适应少数样本 OOD 检测,Dual-Adapter 采用了双缓存建模的概念,并构建了 Positive-Adapter 和 Negative-Adapter,并识别具有两个适配器预测差异的 OOD 样本。
1.7其他重要的研究方向
CLIP-based Full-Spectrum OOD (FS-OOD) detection
FS-OOD检测与标准OOD检测的主要区别在于,它不仅考虑了OOD泛化和OOD检测,还同时处理了语义偏移和非语义协变量偏移的问题。
Unsupervised Universal Fine-Tuning (UUFT)
特别适用于基于 CLIP 的无监督 OOD 检测。UUFT 任务关注无监督学习中的异常检测 (Outlier Detection, OD) 问题。它的目的是在无标签图像集中检测出 OOD 样本,而不依赖于准确的类别名称或与真实标签关联的先验知识,这使得该方法在真实世界应用中更为实用。
Open-world Prompt Tuning
一种针对开放世界场景的提示学习(Prompt Tuning)方法,旨在增强模型在不受限制环境中的表现。
DeCoOp:该方法将 OOD 检测集成到推理流程中,并改善了基础类别与新类别的可分离性,从而防止在新类别上性能下降的问题。
二、基于CLIP的AD方法
2.1.零样本的AD:
使用异常提示词的方法
CLIP-AC
直接做异常检测“(i.e., “normal [class]” vs. “anomalous [class]”)” 或者对正常类提示词计算相似度。
WinCLIP
在大量预定义的正常和异常模板上执行合成集成,并有效地提取和聚合与文本对齐的窗口/补丁/图像级特征。WinCLIP 的性能大大优于 CLIP-AC。由于其简单性和开创性工作,WinCLIP 已成为基于 CLIP 的 AD 的重要基准。
AnoCLIP
遵循 WinCLIP 的方法,即使用大量预定义的正常和异常模板,但将模板修改为域感知(例如,工业照片)和正常和异常的对比状态(例如,完美和不完美)
RVS
从大型模板中提取代表性向量的机制可控,从而允许多样化地选择代表性向量
基于辅助训练的方法
所有基于辅助训练的0映射AD方法都是open-vocabulary AD
该方法重要的原因(1)CLIP理解语义,但是异常往往表现为图像的局部特征,是非语义的(2)依赖手工构建的异常提示词,费时间且可能有未知错误
APRIL-GAN(VAND)
通过在视觉编码器中添加额外的线性层来解决语义和异常之间的领域差距。这些线性图层将每个比例的图像特征投影到文本空间中,在每个阶段创建和聚合异常图。
SDP+
将额外的线性层整合到 SDP 中,以有效地将图像特征投射到文本特征空间中,解决图像和文本之间的错位问题。
AnomalyCLIP
通过将异常提示替换为可学习的参数,它消除了准备大量手动预定义提示的需要,例如 WinCLIP [27] 中的提示。此外,与学习对象语义的 CoOp 不同,AnomalyCLIP 学习与对象无关的文本提示,这些提示可以捕获图像中的通用正常和异常,而不管其语义如何。为此,AnomalyCLIP 为正常和异常引入了与对象无关的文本提示模板,并执行全局和局部上下文优化。
FiLo
利用大型语言模型 (LLM) 为每个对象类别生成精细的异常描述。此方法将通用异常描述替换为 LLM 为每个样本生成的特定异常内容。通过在生成的异常提示之前添加可学习的提示,FiLo 可以执行全局和本地上下文优化,从而增强检测异常的能力。
RWDA
提出了一种利用 CLIP 的文本嵌入作为训练数据的数据增强方法。RWDA 将随机生成的单词添加到正常和异常提示中,以生成一组不同的正常和异常训练样本,并训练具有不同文本嵌入的常规前馈神经网络。
2.2小样本的AD方法:
使用异常提示词的方法
WinCLIP+
将一些正常的参考图像合并到内存库 [134] 中,并使用查询图像与内存库中最相似的图像之间的余弦相似度计算异常分数。
基于ID训练的方法
PromptAD
这是一种用于单类 AD(其中普通类由一个类组成)的提示学习方法。在单类 AD 中,用于多类分类的传统提示学习方法(例如 CoOp [24])效果不佳。为了解决这个问题,PromptAD 通过向普通提示添加可学习的异常后缀来创建大量异常提示。然后,它学习使视觉特征更接近正常提示,并远离异常提示,从而实现单类 AD 的提示学习。
基于辅助训练和基于参考的方法
APRILGAN (few-shot)
InCTRL
在推理过程中,InCTRL 通过测量查询图像的特征与目标数据集中的一些上下文内正常样本之间的差异来识别异常。
其他方向:
对异常检测进行定位
SAA跟SAA+
SAA 是一种简单的基线方法,它利用 Grounding-DINO [56] 作为异常区域生成器,将 SAM [57] 用于异常区域细化器。SAA+ 是 SAA 的一种改进方法,它将领域专业知识和目标图像上下文整合到 SAA 中。
medical AD
MVFA
将多个残差适配器整合到 CLIP 的视觉编码器中,以减少域间隙,从而逐步增强不同级别的视觉特征。
三、相关问题
全谱OOD检测:结合了泛化和OOD检测的需求,解决包含协变量偏移的多样化OOD检测任务。
开放世界提示微调:允许VLM在开放世界设定中处理未见类别。
四、大型视觉语言模型上的应用
无法解决问题检测(UPD)
LVLM识别和避免回答意外或无法解决的输入问题
异常检测的跨域扩展
LVLM在工业、医疗等多领域提供异常检测能力,通过自然语言生成异常描述。
三、联通任务:站点清洁提交
站点清洁
----------------------------------------------------------------------------------------------------------------------------
子问题1:地板污渍与杂物检测
1.算法逻辑及场景示例
地板污渍与杂物检测的检查点如下:
通过判断图片中是否存在常见的杂物,垃圾(扎带,纸盒、塑料袋、烟头、废纸、泡沫渣,废旧线缆等)以及明显的污渍,如果存在,不予通过。由于杂物与垃圾较小,目标检测难以实现。所以考虑将图片进行切割后,将其分类成正样本和负样本。当一张图片切割后的图片组中含有负样本时不予通过。
由于背景类对样本干扰巨大,所以使用了分割模型ground sam获取地板的mask,借此只对属于地板的图像块进行分类。
常见负样本



异常样本

当图片中出现白字且背景十分干净时,联通方给的数据训练集中不含白字信息,在实际应用中,模型可能把白字识别成污渍导致误判。

图片中不含地板时,ground sam分割的mask中没有地板信息,因此会出现不进行分类直接判正的情况。
2.算法描述
2.1. 算法原理
将图片进行按6*6网格均分切割后,将其分类成正样本和负样本。该大小下,基本可以完整识别到图片中的杂物,污渍。使用efficientNet训练一个分类器。
预测的第一步,先获取ground sam分割的mask,同样将目标图片分割成6*6的图片组,若含地板的比例大于一定比例,则将对应图片归为地板,不然则判为背景,并对其进行正负样本分类。
预测的第二步,6*6的方格中,每个地板方格对上下左右,左上,左下,右上,右下八个方向查看,若查看的方格为背景,则各取一半形成新的切割图像,并对其进行正负样本分类。这是因为垃圾杂物在ground sam中会被当成背景,为了避免漏查,进行查看图片的扩充。
若分类的图片组中含有负样本,则该图片组对应的图片为负样本。
2.2.算法流程
通过ground sam获取地板的mask


将 img 按照6*6网格均分成36个方格,并按照算法步骤分两步提取图像块,进行分类

若有分出一个图像块分类为负样本,则图片为负样本,否则为正样本
- 使用指南
3.1.Ground SAM配置
要求:python>=3.8, pytorch>=1.7, torchvision>=0.8
(1)安装segment_anything:
python -m pip install -e segment_anything
(2)安装GroundingDINO:
在该目录下继续进行步骤
注意:如果pip安装GroundingDIN失败,大概率电脑的C++有问题或者版本过低。
python -m pip install -e GroundingDINO
(3)安装diffusers:
pip install --upgrade diffusers[torch]
(4)安装grounded-sam-osx:
注意:需要下载好Bash
cd grounded-sam-osx
bash install.sh
(5)安装其他依赖:
pip install opencv-python pycocotools matplotlib onnxruntime onnx ipykernel
3.2预测代码与模型
代码文件
![]()
efficientnet预训练模型
![]()
3.3.输入/输出
(核心函数predict的输入和输出) 函数概述:
输入图片组image_list,
返回dic_list涵盖图片组中每个问题对应每个条目的情况以及总体结果
入参:
image_list:list(示例 [img1,img2]),输入图片组PIL格式文件
出参:
results_list:该组图片的分类类别[
[["地板污渍与杂物检测","该子问题是否需要判断","判断结果"]],
[["地板污渍与杂物检测","该子问题是否需要判断","判断结果"]]
]
有杂物或污渍则判断结果为负
total_result:整个工单的判断结果

















 2355
2355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









