






optim.SGD中的momentum:
SGD方法的一个缺点是,其更新方向完全依赖于当前的batch,因而其更新十分不稳定。解决这一问题的一个简单的做法便是引入momentum。momentum即动量,它模拟的是物体运动时的惯性,即更新的时候在一定程度上保留之前更新的方向,同时利用当前batch的梯度微调最终的更新方向。这样一来,可以在一定程度上增加稳定性,从而学习地更快,并且还有一定摆脱局部最优的能力。
warmup作用
由于刚开始训练时,模型的权重(weights)是随机初始化的,此时若选择一个较大的学习率,可能带来模型的不稳定(振荡),选择Warmup预热学习率的方式,可以使得开始训练的几个epoches或者一些steps内学习率较小,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳。
Wandb logging
wandb是Weight & Bias的缩写;保存训练运行中使用的超参数;搜索、比较和可视化训练的运行;在运行的同时分析系统硬件的情况如:CPU和GPU使用率;在团队中分享训练数据;永远保存可用的实验记录。
wandb.init — 在训练脚本开头初始化一个新的运行项;
wandb.config — 跟踪超参数;
wandb.log — 在训练循环中持续记录变化的指标;
wandb.save — 保存运行项相关文件,如模型权值;
wandb.restore — 运行指定运行项时,恢复代码状态。
Dropout
dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。注意是暂时,对于随机梯度下降来说,由于是随机丢弃,故而每一个mini-batch都在训练不同的网络。dropout是CNN中防止过拟合提高效果的一个大杀器.
utils
python utils是一个小型python函数和类的集合,这些函数和类使公共模式变得更短、更容易。
Python hasattr() 函数
用于判断对象是否包含对应的属性。hasattr(object, name):
object -- 对象。
name -- 字符串,属性名。
如果对象有该属性返回 True,否则返回 False。
repeat()
repeat参数和tensor维数相同时:repeat的参数是对应维度的复制个数。
repeat参数和tensor维数不相同时:先进行扩充在进行对应维度的复制。
先在第0维扩展一个维数为1的维度,然后按照参数指定的复制次数进行复制。
backbone:
大多时候指的是提取特征的网络,其作用就是提取图片中的信息。经常使用的是resnet、VGG等,直接加载官方已经训练好的模型参数,后面接着我们自己的网络。让网络的这两个部分同时进行训练,因为加载的backbone模型已经具有提取特征的能力了,在我们的训练过程中,会对他进行微调,使得其更适合于我们自己的任务。
head:
head是获取网络输出内容的网络,利用之前提取的特征,head做出预测。
neck:
是放在backbone和head之间的,是为了更好的利用backbone提取的特征。
bottleneck:
通常指的是网网络输入的数据维度和输出的维度不同,输出的维度比输入的小了许多。经常设置的参数 bottle_num=256,指的是网络输出的数据的维度是256 ,可是输入进来的可能是1024维度的。
GAP:
Global Average Pool即全局平均池化,就是将某个通道的特征取平均值,经常使用AdaptativeAvgpoold,在pytorch中,这个代表自适应性全局平均池化,就是将某个通道的特征取平均值。
embedding:
深度学习方法都是利用使用线性和非线性转换对复杂的数据进行自动特征抽取,并将特征表示为“向量”(vector),这一过程一般也称为“嵌入”(embedding)。
pretext task和downstream task:
用于预训练的任务被称为前置/代理任务(pretext task),用于微调的任务被称为下游任务(downstream task)。
temperature parameters
温度系数,常见形式如下:其中τ是温度系数,可以起到平滑softmax输出结果的作用。
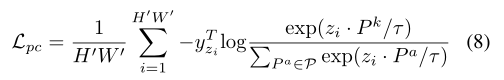
当大于1的时候,可以将输出结果变得平滑,当小于1的时候,可以让输出结果变得差异更大一下,更尖锐一些。如果比较大,则分类的crossentropy损失会很大,可以在不同的迭代次数里,使用不同的数值,有点类似于学习率的效果。
Warm up
Warm up(预热)指的是用一个小的学习率先训练几个epoch,这是因为网络的参数是随机初始化的,一开始就采用较大的学习率容易数值不稳定。
end to end
在论文中经常能遇到end to end这样的描述,那么到底什么是端到端呢?其实就是给了一个输入,我们就给出一个输出,不管其中的过程多么复杂,但只要给了一个输入,就会对应一个输出。单从结果来看,就是给了一个输入,输出了一个预测结果。End-To-End的方案,即输入一张图,输出最终想要的结果,算法细节和学习过程全部丢给了神经网络。
domain adaptation 和domain generalization
域适应和域泛化:域适应中,常见的设置是源域D_S完全已知,目标域D_T有或无标签。域适应方法试着将源域知识迁移到目标域。域泛化是将模型应用到完全未知的领域,正因为没有见过,所以没有任何模型更新和微调。
x.to(device)
将所有最开始读取数据时的tensor变量copy一份到device所指定的GPU上去,之后的运算都在GPU上进行。
enumerate()
用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标。
unpack()
按照一定的格式取出字符串中的子字符串。
item()
返回的是tensor中的值,且只能返回单个值(标量),不能返回向量,使用返回loss等。
loss.item()返回loss的值.
detach()
detach阻断反向传播,返回值仍为tensor。
cpu()
cpu()将变量放在cpu上,仍为tensor。
numpy()
将tensor转换为numpy:注意cuda上面的变量类型只能是tensor,不能是其他。
loss.backward()
将损失loss 向输入侧进行反向传播,同时对于需要进行梯度计算的所有变量 x(requires_grad=True),计算梯度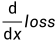 。并将其累积到x.grad中。
。并将其累积到x.grad中。
optimizer.step()
优化器对 x 的值进行更新。以随机梯度下降为例: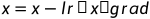 。沿着梯度反方向更新变量值(减号)。
。沿着梯度反方向更新变量值(减号)。
optimizer.zero_grad()
清除了优化器中所有 x的 x.grad,在每次loss.backward()之前,不要忘记使用,否则之前的梯度将会累积。
step()函数的作用是执行一次优化步骤,通过梯度下降法来更新参数的值。因为梯度下降是基于梯度的,所以在执行optimizer.step()函数前应先执行loss.backward()函数来计算梯度。
注意:optimizer只负责通过梯度下降进行优化,而不负责产生梯度,梯度是tensor.backward()方法产生的。
soft predictions and hard predictions
hard target 和soft target的区别:

soft target优于hard taget的地方:携带更多model学到的有用信息。
如何soft:加入温度系数τ
torch.max()
torch.max()返回tensor数据最大值和索引,输出的值有两个参数,第一个参数是最大值,第二个参数是最大值的索引(也就是分类label),主要用于神经网络输出与label的匹配。
torch.augmax()
torch.argmax()的作用与前面类似,我们只想要神经网络最终的标签,它输出的概率值并不关心,那么就可以直接用torch.argmax()返回tensor数据最大值的索引。
torch.where
torch.where(条件,x,y):根据条件,返回从x,y中选择元素所组成的张量。如果满足条件,则返回x中元素。若不满足,返回y中元素。
F.softmax()
F.sofrmax(x,dim)作用:根据不同的dim规则来做归一化操作。x指的是输入的张量,dim指的是归一化的方式。
dim=0:按列SoftMax,列和为1(即0维度进行归一化)求概率。
dim=1:按列SoftMax,行和为1(即1维度进行归一化)
伪标签阈值 Pseudolabel Threshold
深度学习中一种简单有效的半监督方法,阈值控制了伪标签的质量和数量之间的权衡。 无标签数据的伪标签准确性随着阈值的提高而增加,在0.95时达到峰值,但阈值设的越高,参与计算交叉熵的伪标签样本就越少,这表明,达到高准确度时,伪标签的质量比数量更重要。















 2011
2011

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









