







一、注册百度智能云并在本地安装百度智能云模块
百度智能云网址,注册好账号后进入百度智能云,点击右上角的管理控制台。

进入控制台后,按照下图方式,找到文字识别,点击进入。(若要使用其他api,自行选择即可)
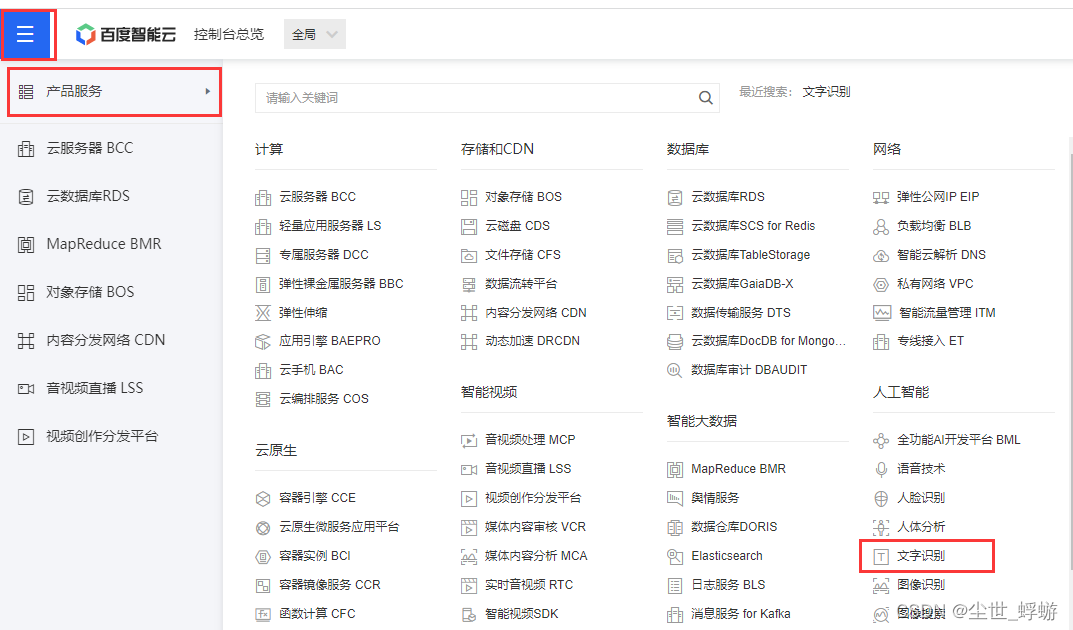
进入文字识别部分后,在左侧菜单选择“概述”,在此界面点击右侧领取免费资源,将里面能勾选的都选了就行。选完后返回,会和下图显示的一样,资源列表里出现了刚刚我们选的api。
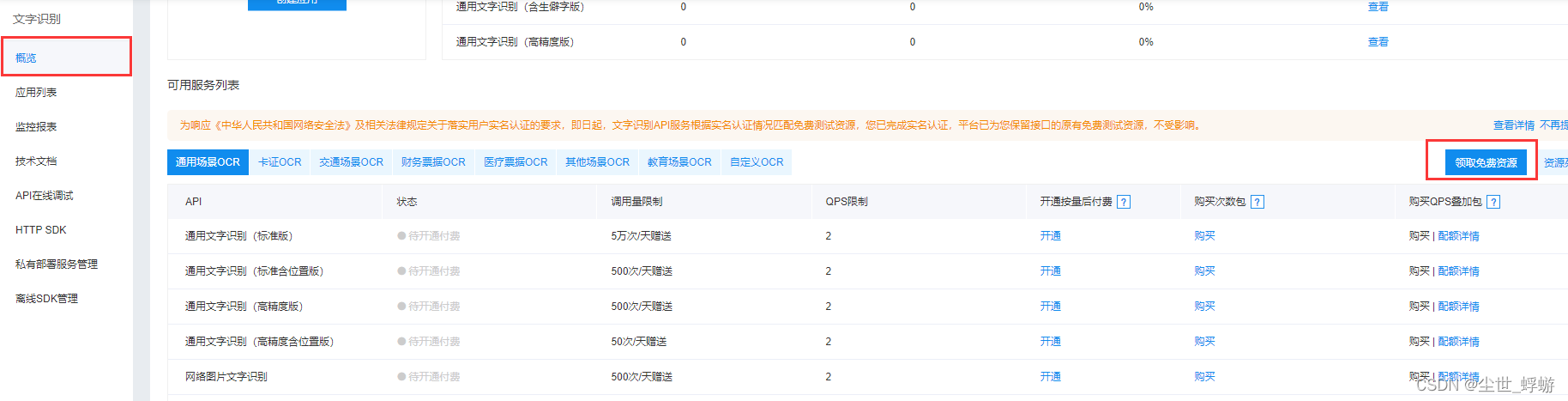
之后载应用列表里创建一个应用
创建完成后列表里会出现此应用信息,这三个信息一会要加入在咱们程序里,不要找不到地方哦。

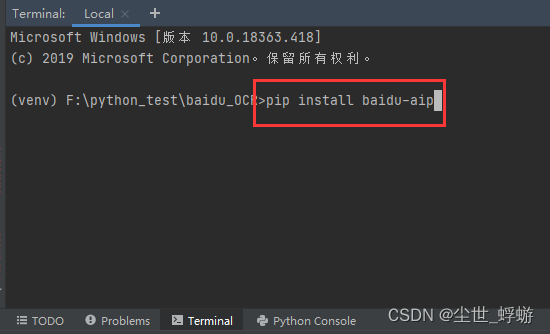
之后要在本地安装百度智能云模块,建议在pycharm的虚拟环境里安装,以防止出现No module named 'aip’的问题。
在命令行中输入pip install baidu-aip,安装即可。
二、提示No module named 'aip’问题
若未在pycharm中安装,可能会出现如下报错。应该是模块有冲突,有两个方法解决。

第一个方法就是去pycharm里建个工程,在其Terminal中安装baidu-aip。这里面是虚拟环境,工程里安装的第三方库不会与本地安装的其他库起冲突。
第二个方法,可以运行cmd,在命令行中输入pip uninstall aip,卸载aip模块。(本小白不清楚python的aip模块是啥,所以没敢卸载,选择了方法一)
三、提示No module named 'chardet’问题
处理完上述问题后,本小白还出现了“No module named ‘chardet’”的报错,少模块咱安装就完事了。
直接pip install chardet,解决。若还出现其他缺失模块的报错,根据报错信息依次安装即可。
四、测试代码
关键的几句代码:
from aip import AipOcr
APP_ID = '填自己创建的应用的ID' #填自己的信息,在上文所述的位置理由
API_KEY = '如上'
SECRET_KEY = '如上'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
image = get_file_content(filePath) #读取图像
result = client.basicGeneral(image) #调用百度的api,返回识别的信息
print(result['words_result']) #识别的信息打印
这是本小白根据自身需要,将图片信息识别并筛选到指定excel的程序。
from aip import AipOcr
import cv2
import xlwings as xw
import os
import shutil
Filepath = r"C:\Users\Administrator\Desktop\图片"
app = xw.App(visible=False, add_book=False)
wb = app.books.open(r"F:\python_test\baidu_OCR\sum.xlsx")
wb.sheets[0].range("A:C").api.NumberFormat = "@" # 文本格式,若不设置身份证信息等会被隐藏
sht = wb.sheets[0]
sht_row = sht.used_range.last_cell.row
sht_column = sht.used_range.last_cell.column
APP_ID = '填自己创建的应用的ID' #填自己的信息,在上文所述的位置理由
API_KEY = '如上'
SECRET_KEY = '如上'
str2 = ""
num = 1
row_line = 1
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
#img = cv2.imread(filePath, 1) #图片压缩,图片上传有要求不能超过4M
#cv2.imwrite(filePath, img, [cv2.IMWRITE_JPEG_QUALITY, 80])
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
def shibie(filePath):
global num
global row_line
image = get_file_content(filePath) #读取图像
result = client.basicGeneral(image) #调用百度的api,返回识别的信息
if( num % 2 == 0):
num = num + 1
row_line = row_line + 1
for item in result['words_result']: #对识别的结果进行筛选
str1 = item['words']
if( and (len(str1) >= 2): #去除一些干扰信息,将需要的信息复制到excl中
if( len(str1) == 11 ):
sht.range("C{}".format(row_line - 1 )).value = str1
elif( num % 2 == 1):
sht.range("A{}".format(row_line)).value = str1
num = num + 1
elif( num % 2 == 0):
sht.range("B{}".format(row_line)).value = str1
num = num + 1
row_line = row_line + 1
print("完成")
new_file = r"C:\Users\Administrator\Desktop\图片测试"
for root, dirs, files in os.walk(Filepath):
# root 表示当前正在访问的文件夹路径# dirs 表示该文件夹下的子目录名list
# files 表示该文件夹下的文件list # 遍历文件
for f in files:
file_path = os.path.join(root, f)
print(file_path)
if (file_path.endswith(".jpg") == True):
shibie(file_path)
dst = os.path.join(new_file, os.path.basename(file_path))
shutil.move(file_path, dst) #一副图片处理完后移动到另一个文件夹
sht.autofit(axis="columns")
wb.save()
wb.close()
app.kill()















 1154
1154











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









