







 本文探讨了ClickHouse中副本的基本概念,包括副本写入流程、配置方法,重点介绍了如何创建副本表以及副本同步的原理,涉及zk目录结构、merge同步策略。深入理解了副本间数据的协同与一致性保障机制。
本文探讨了ClickHouse中副本的基本概念,包括副本写入流程、配置方法,重点介绍了如何创建副本表以及副本同步的原理,涉及zk目录结构、merge同步策略。深入理解了副本间数据的协同与一致性保障机制。
文章目录
clickHouse接入指南和排坑日记
clickHouse分区和分片详解
clickHouse本地表和分布式表
1. 副本的基本概念
1. 1 什么是副本
副本的目的主要是保障数据的高可用性,即使一台ClickHouse节点宕机,那么也可以从其他服务器获得相同的数据。
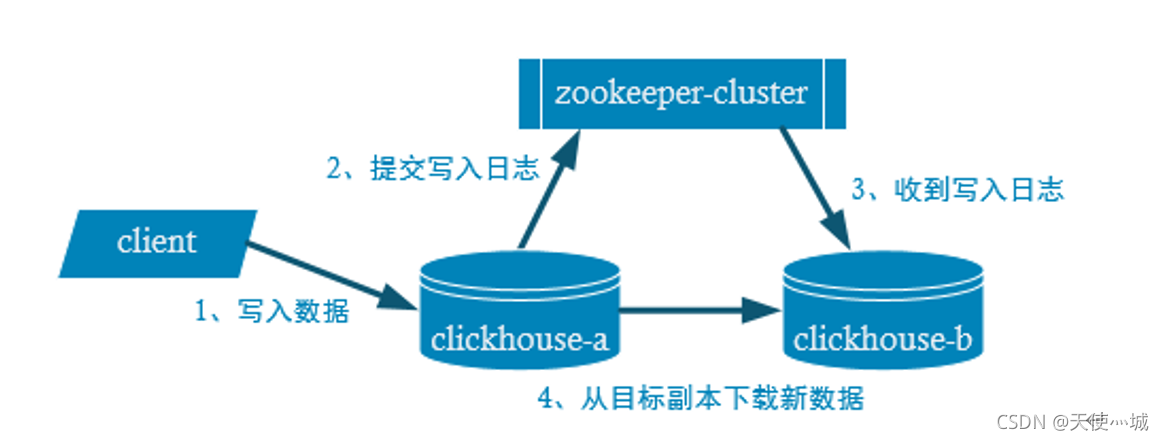
1. 2 副本写入流程简单示例
client通过jdbc或者http的方式进行clickhouse-01节点的本地表(写分布式表的时候,数据会进行拆分进而分发到多个本地表)写数据的时候,提交写入日志给zookeeper,clickhouse-02有一个监听器来监听zookeeper接收到日志之后从clickhouse-01中下载数据。
1. 3 多副本的配置
1. 4 clickhouse创建副本表
之前创建分布式表和本地表的时候,我们使用了MergeTree家族引擎,而创建分布式表,只需要在前面加上Replicated就成了支持副本的合并树引擎。
CREATE TABLE IF NOT EXISTS ka_10002538_f83b454416104dbfa083369f35759549.tmc_sms_url_click_local
on cluster clickhouse_csig_smartretail_2_replica
(`kaId` String, `create_time` String,
`os` String, `ipCity` String, `ip` String, `dataType` String,
`receive_time` Int64, `mobile` String, `contentId` String, `ipCountry` String,
`batchId` String, `import_date` String, `path` String, `osVersion` String,
`report_time` Int64, `domain` String, `browserVersion` String,
`browser` String, `customerId` String, `ipProvince` String, `model` String,
`tmcTenantId` String, `timestamp` Float64, `campaign` String,
`campaignName` String) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/ka_10002538_f83b454416104dbfa083369f35759549/tmc_sms_url_click_local', '{replica}') PARTITION BY import_date ORDER BY import_date
基于副本表去创建分布式表和MergeTree一样,如下:
CREATE TABLE IF NOT EXISTS ka_10002538_f83b454416104dbfa083369f35759549.tmc_sms_url_click on cluster
clickhouse_csig_smartretail_2_replica
(`kaId` String, `create_time` String, `os` String, `ipCity` String, `ip` String, `dataType` String, `receive_time` Int64, `mobile` String, `contentId` String, `ipCountry` String, `batchId` String, `import_date` String, `path` String, `osVersion` String, `report_time` Int64, `domain` String, `browserVersion` String, `browser` String, `customerId` String, `ipProvince` String, `model` String, `tmcTenantId` String, `timestamp` Float64, `campaign` String, `campaignName` String)
ENGINE = Distributed('clickhouse_csig_smartretail_2_replica', 'ka_10002538_f83b454416104dbfa083369f35759549', 'tmc_sms_url_click_local', rand())
2. 副本同步原理
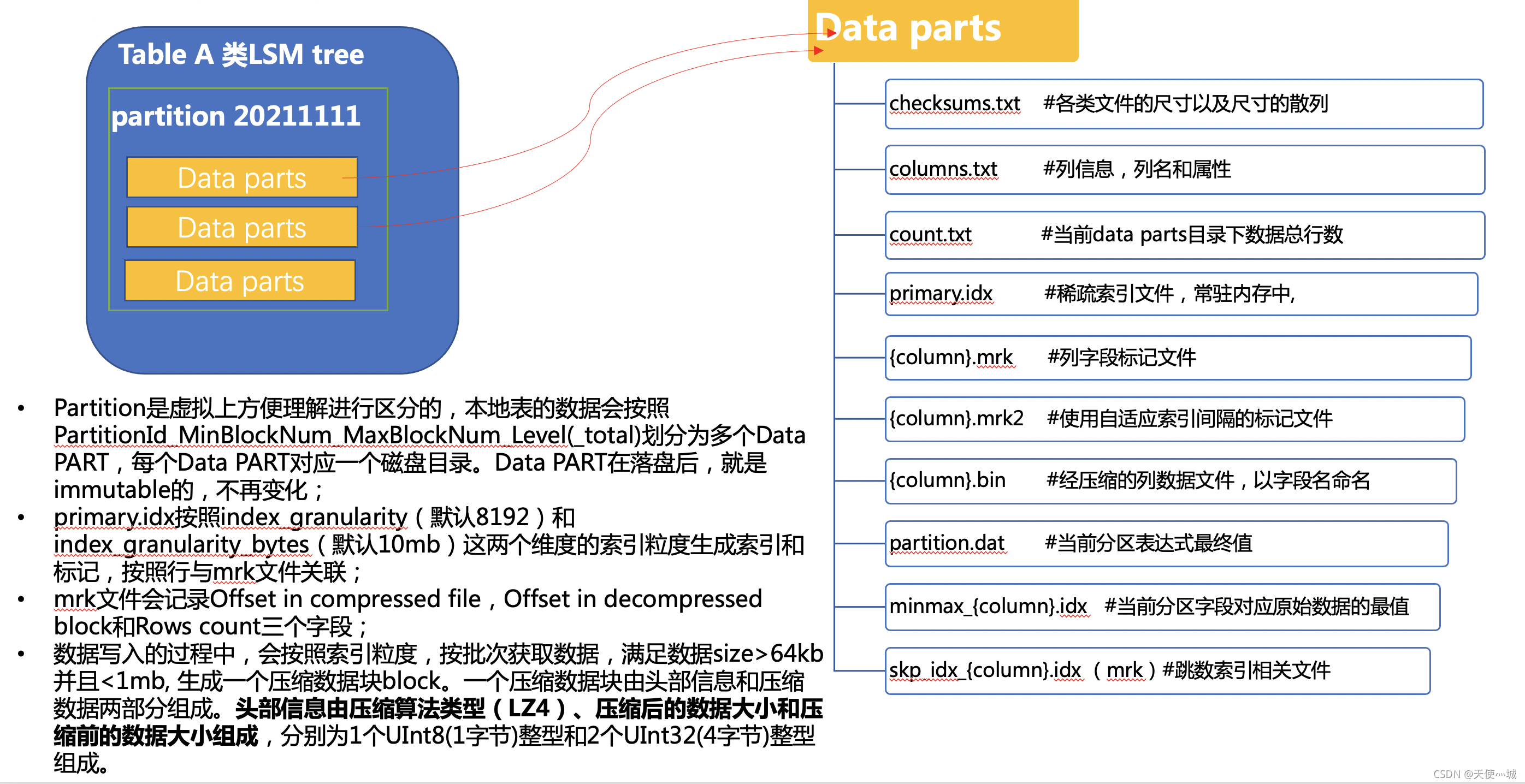
2.1 clickhouse目录
table_name #表名
├─ partition_minBolckNum_maxBlockNum_level_total #某个分区下的data parts目录
│ │ # 基础文件
│ ├─ checksums.txt BIN #各类文件的尺寸以及尺寸的散列
│ ├─ columns.txt TXT #列信息
│ ├─ count.txt TXT #当前分区目录下数据总行数
│ ├─ primary.idx BIN #稀疏索引文件,常驻内存中
│ ├─ {column}.bin BIN #经压缩的列数据文件,以字段名命名
│ ├─ {column}.mrk BIN #列字段标记文件
│ ├─ {column}.mrk2 BIN #使用自适应索引间隔的标记文件
│ │
│ │ # 分区键文件
│ ├─ partition.dat BIN #当前分区表达式最终值
│ ├─ minmax_{column}.idx BIN #当前分区字段对应原始数据的最值
│ │
│ │ # 跳数索引文件
│ ├─ skp_idx_{column}.idx BIN #跳数索引文件
│ └─ skp_idx_{column}.mrk BIN #跳数索引表及文件
│
└─ partition_minBolckNum_maxBlockNum_level_total #某个分区下的data parts目录
max_compress_block_size
在压缩写入表之前,未压缩数据块的最大大小。 默认情况下,1,048,576(1MiB)。 如果大小减小,则压缩率显着降低,压缩和解压缩速度由于高速缓存局部性而略微增加,并且内存消耗减少。 通常没有任何理由更改此设置。
不要将用于压缩的块(由字节组成的内存块)与用于查询处理的块(表中的一组行)混淆。
min_compress_block_size
为 MergeTree"表。 为了减少处理查询时的延迟,在写入下一个标记时,如果块的大小至少为 ‘min_compress_block_size’. 默认情况下,65,536。
块的实际大小,如果未压缩的数据小于 ‘max_compress_block_size’,是不小于该值且不小于一个标记的数据量。
让我们来看看一个例子。 假设 ‘index_granularity’ 在表创建期间设置为8192。
我们正在编写一个UInt32类型的列(每个值4个字节)。 当写入8192行时,总数将是32KB的数据。 由于min_compress_block_size=65,536,将为每两个标记形成一个压缩块。
我们正在编写一个字符串类型的URL列(每个值的平均大小60字节)。 当写入8192行时,平均数据将略少于500KB。 由于这超过65,536,将为每个标记形成一个压缩块。 在这种情况下,当从单个标记范围内的磁盘读取数据时,额外的数据不会被解压缩。
通常没有任何理由更改此设置。
2.2 ClickHouse在zk的目录结构


- metadata:存的是表的元数据信息,主键,分区键,index_granularity(索引粒度 mark标记的行);
- temp:临时目录,用于存储ck工作时的一些临时文件的存储,比如mutation过程等;
- mutations:记录数据的变更,除了表结构相关ddl之外,更新和删除异步执行的批处理操作也会记录在这里;
- log:每一个insert语句,都会生成一个data parts,对应的是一个block,block_id规则是PartitionID_MinBlockNum_MaxBlockNum_Level,然后会记录到log目录下,副本同步也是监听这个目录的变动去同步拉data parts;
- leader_election:这里包含所有可用的副本,决定哪个副本作为主副本,查询时优先选择该副本,节点是leader_election-xxxx这种格式,这些副本信息都是临时节点,如果实例异常,会自动删除,如果实例恢复,会再次写入;
- columns:存储了该表的所有列信息,列名和类型;
- blocks:最新的PartitionID对应的所有block记录,命名格式PartitionID_MinBlockNum_MaxBlockNum_Level,partitionID由分区键(PARTITION BY)的取值决定,最好设计为日期类型。blockNum是每个分区按照日期自增长的,level是合并的次数和深度,最终的block数据保存在system.clusters,格式是20211123_0_1200_30_4500,前面四个参数含义一样,最后一个参数,代表当前分区的总的blockNum数量,可以通过
SELECT partition, name, table, database ,active FROM system.parts WHERE partition = '20211122' and table = 'table_name'查看;
2.3 副本同步
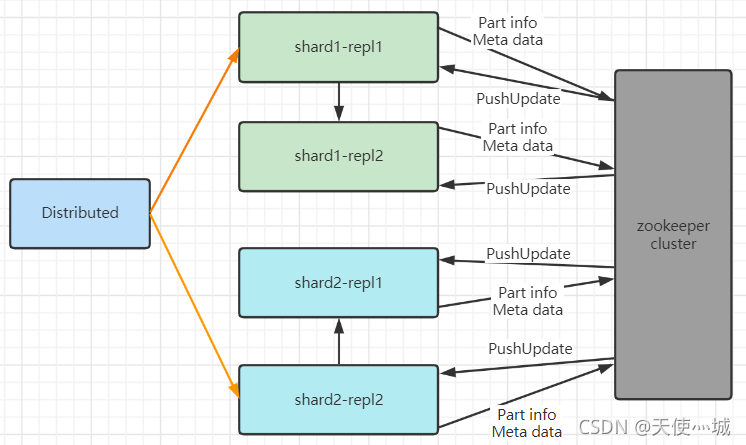
ReplicatedMergeTree 需要依靠 ZooKeeper 的事件监听机制以实现各个副本之间的协同,副本协同的核心流程主要有:INSERT、MERGE、MUTATION 和 ALTER 四种。副本之间依靠 ZooKeeper 同步元数据,保证文件存储格式完全一致,可以理解这种方式是物理一致。同时, 副本间数据的同步,通过监听log目录,从对应有数据的副本拉取data parts到本地。
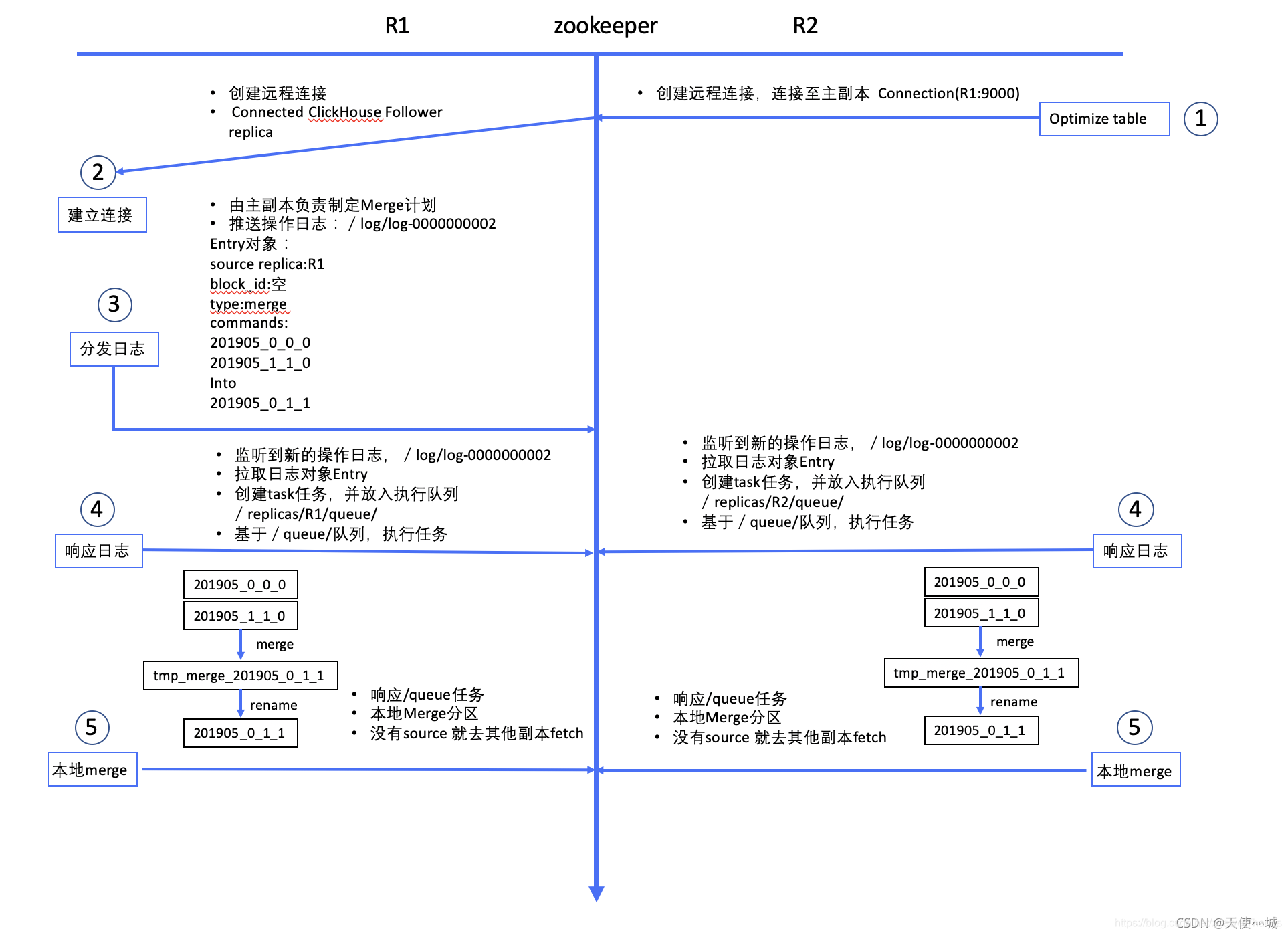
2.4 副本间merge同步
同分片下不同副本merge流程通过zookeeper来协调,不然各副本并发merge容易乱套,各个分片merge流程一样,互不影响,并行merge
- 不管谁接收到请求,都由主副本来发起merge计划,20.5 之后没有主的概念了;
- 把计划推到zookeeper,各个副本监听,一起执行,如果发现自己没有某些part会从别的副本拉取。


















 1237
1237

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









