






爬虫部分
用爬虫从百度获取关键词的图片,进行简单的人工删选后作为训练用的原始数据。爬虫代码可从网上方便找到。
# -*- coding:utf-8 -*-
import re
import requests
import os
word = 'something'
download_dir = './pic/'
#创建文件夹
def mdir():
if not os.path.exists(download_dir):
os.mkdir(download_dir)
if not os.path.exists(download_dir+word):
os.mkdir(download_dir+word)
os.chdir(download_dir+word)
#获取图片的地址
def geturl(page_number):
url = "http://image.baidu.com/search/avatarjson?tn=resultjsonavatarnew&ie=utf-8&word=" + word + "&cg=girl&rn=60&pn=" +str(page_number)
html = requests.get(url).text
pic_url = re.findall('"objURL":"(.*?)",',html,re.S)
return pic_url
#下载图片
def downimage(pic_url, page_number):
i = 1
for each in pic_url:
print(each)
try:
pic= requests.get(each, timeout=5)
except requests.exceptions.ConnectionError:
print('========Error!CAN NOT DOWMLOAD THIS PICTURE!!!========')
i -= 1
continue
except requests.exceptions.Timeout:
print("========REQUESTTIMEOUT !!!========")
i -= 1
string = word+ str(page_number) + '-' + str(i) + '.jpg'
fp = open(string,'wb')
fp.write(pic.content)
fp.close()
i += 1
if __name__ == '__main__':
mdir()
page_number = 10
page_count = 60
while True:
mPicUrl = geturl(page_count)
downimage(mPicUrl, page_number)
page_count += 60
page_number += 1
数据处理部分
将下载好的图片进行批处理,先把图片大小转化为神经网络输入的尺寸(这里是(64,64,3)),再生成pkl文件(当然也可以用其他格式,如tfrecord)。
# -*- coding:utf-8 -*-
import PIL.Image as Image
import numpy as np
import random
import pickle
import os
#改变图像大小为(64,64)
new_x, new_y = 64, 64
def resize(folders_path):
folders = os.listdir(folders_path)
for folder in folders:
files = os.listdir(folders_path +folder)
i=0
for file in files:
#读取图片,PIL.Image库没有close方法,会导致运行出错,因此用内置的open
with open(folders_path+ folder + '/' + file ,'rb') as f:
img = Image.open(f).convert('RGB')
try:
resized =img.resize((new_x, new_y), resample=Image.LANCZOS)
resized.save(folders_path +folder + '/resize-' + str(i)+'.jpg', format="jpeg")
except:
print('Get ERROR in '+folders_path +folder + '/' + file)
#删除原图
os.remove(folders_path + folder + '/' + file)
i += 1
#函数调用:生成数据集
def initPKL(imgSet_shuffle, train_or_test):
imgSet = []
labels = []
label_names = []
if train_or_test == 'train':
set_name = 'trainSet.pkl'
else:
set_name = 'testSet.pkl'
for i in imgSet_shuffle:
imgSet.append(i[0])
labels.append(i[1])
label_names.append(i[2])
imgSet = np.array(imgSet)
labels = np.array(labels)
label_names = np.array(label_names)
arr = (imgSet,labels,label_names)
#写入文件
data = (arr[0],arr[1],arr[2])
output = open(set_name, 'wb')
pickle.dump(data, output)
output.close()
def initArr(folders_path):
i = 0
imgSet = []
folders = os.listdir(folders_path)
for folder in folders:
#类别个数,几个0代表几类
label = [0,0,0]
files = os.listdir(folders_path +folder)
label[i] = 1
for file in files:
#读取图片
img_arr = np.array(Image.open(folders_path+ folder + '/' + file)) / 255
imgSet.append((img_arr, label,folder))
i += 1
return imgSet
#将图片转换成数组
train_folders_path= './train/'
test_folders_path= './test/'
resize(train_folders_path)
resize(test_folders_path)
train_imgSet =initArr(train_folders_path)
test_imgSet =initArr(test_folders_path)
#打乱顺序
random.shuffle(train_imgSet)
random.shuffle(test_imgSet)
train_set_shuffle= np.array(train_imgSet)
test_set_shuffle =np.array(test_imgSet)
# 分别生成训练集和测试集
initPKL(train_set_shuffle,'train')
initPKL(test_set_shuffle,'test')
#测试生成的数据集
f = open('./trainSet.pkl', 'rb')
x, y, z =pickle.load(f)
f.close()
print(np.shape(x[3]), y[3], z[3])
深度学习部分
这里用比较简单的AlexNet作为例子,构建了一个小型的神经网络,要注意输入和输出的大小((64,64,3)和3)。除了训练,代码还增加了断点保存,模型加载,预判预测等功能。
# -*- coding:utf-8 -*-
import numpy as np
import tflearn
from tflearn.data_utils import shuffle
from tflearn.layers.core import input_data, dropout, fully_connected
from tflearn.layers.normalization importlocal_response_normalization
from tflearn.layers.conv import conv_2d, max_pool_2d
from tflearn.layers.estimatorimport regression
from tflearn.data_preprocessing importImagePreprocessing
from tflearn.data_augmentation import ImageAugmentation
import time
import pickle
_loadModel = False
_trainModel = True#False
# 加载数据集
X, Y, Y_name=pickle.load(open("trainSet.pkl", "rb"))
X_test, Y_test,Y_test_name =pickle.load(open("testSet.pkl", "rb"))
# 打乱数据
X, Y, Y_name=shuffle(X, Y, Y_name)
#数据处理
img_prep =ImagePreprocessing()
img_prep.add_featurewise_zero_center()
img_prep.add_featurewise_stdnorm()
# 翻转、旋转和模糊效果数据集中的图片,来创造一些合成训练数据.
img_aug =ImageAugmentation()
img_aug.add_random_flip_leftright()
img_aug.add_random_flip_updown()
img_aug.add_random_rotation(max_angle=25.)
img_aug.add_random_blur(sigma_max=3.)
# Building'AlexNet',注意输入维数
network =input_data(shape=[None, 64, 64, 3])
network =conv_2d(network, 96, 11, strides=4, activation='relu')
network =max_pool_2d(network, 3, strides=2)
network =local_response_normalization(network)
network =conv_2d(network, 256, 5, activation='relu')
network =max_pool_2d(network, 3, strides=2)
network =local_response_normalization(network)
network =conv_2d(network, 384, 3, activation='relu')
network =conv_2d(network, 384, 3, activation='relu')
network =conv_2d(network, 256, 3, activation='relu')
network =max_pool_2d(network, 3, strides=2)
network =local_response_normalization(network)
network =fully_connected(network, 4096, restore=True, activation='tanh')
network =dropout(network, 0.5)
network =fully_connected(network, 4096, restore=True, activation='tanh')
network =dropout(network, 0.5)
network =fully_connected(network, 3, restore=True, activation='softmax')
network =regression(network,
optimizer='adam',
loss='categorical_crossentropy',
learning_rate=0.0001)
# 把网络打包为一个模型对象
model =tflearn.DNN(network,
tensorboard_verbose=3,
tensorboard_dir = './logs/',
best_checkpoint_path = './best_checkpoint/best_classifier.tfl.ckpt')
if _loadModel == True:
model.load("./modelSaved/my_model.tflearn")
tic = time.time()
poss = model.predict(X_test)
toc = time.time()
print('预测所用时间:%.3fms' % (1000*(toc-tic)))
print('有%.2f%%的概率是**,有%.2f%%的概率是**,有%.2f%%的概率是**' % (100*poss[0][0], 100*poss[0][1], 100*poss[0][2]))
print('实际为'+str(Y_test_name[0]))
if _trainModel == True:
model.fit(X, Y,
n_epoch=1000,
shuffle=True,
validation_set=0.1,
#对训练数据执行数据分割,10%用于验证
show_metric=True,
batch_size=64,
snapshot_step=200,
snapshot_epoch=False,
run_id='AlexNet')
model.save("modelSaved/my_model.tflearn")
print("Networktrained and saved as my_model.tflearn !")训练结果
在命令行输入命令如:
tensorboard --logdir=classifier\logs\AlexNet
启动tensorboard查看训练结果
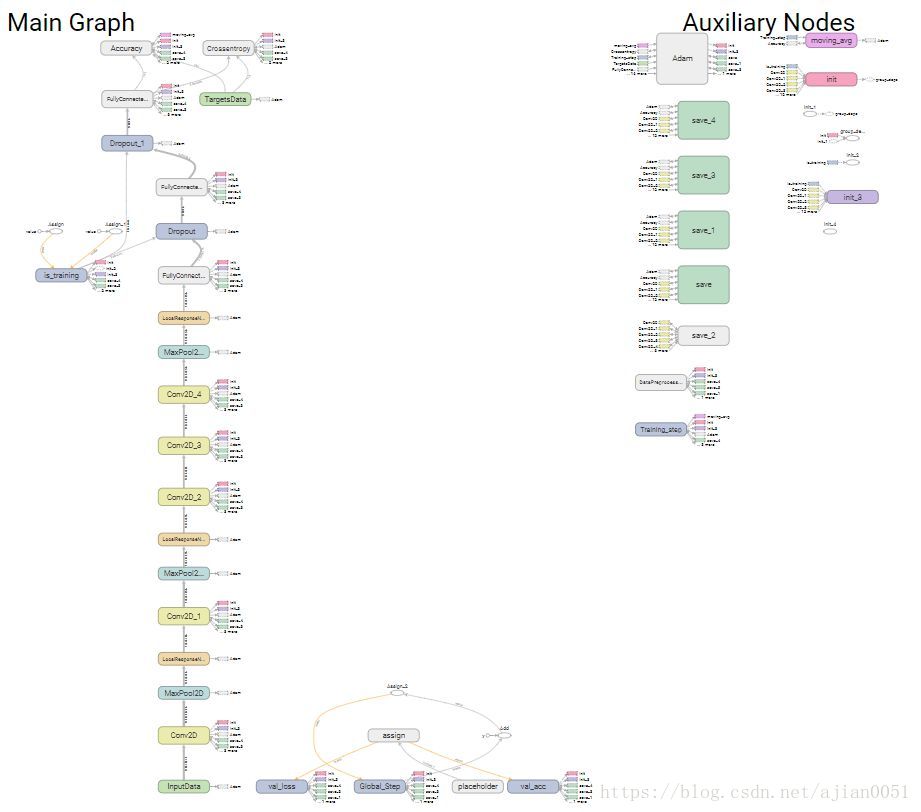
计算图:
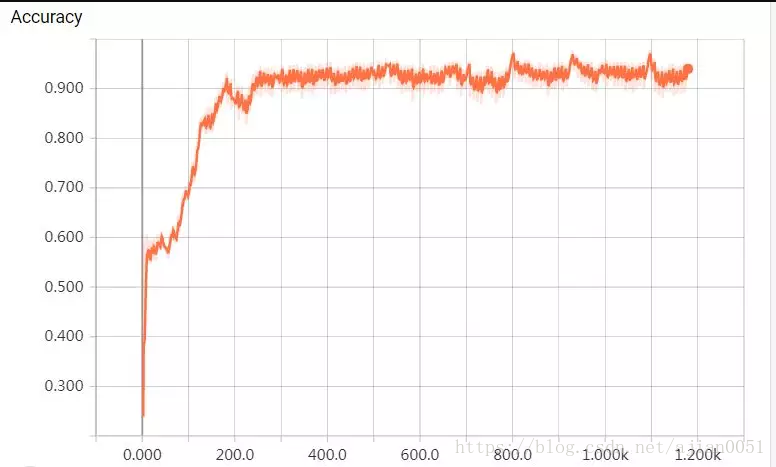
训练后期,训练准确率在93~95%之间,验证准确率约可以保持在98%左右。
代码运行结束后(或强行终止后),修改代码:
_loadModel = True
_trainModel = False
使其载入训练好的模型,对测试图片(一张)进行预测。预测结果:
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









