







L1和L2的区别
L1范数(L1 norm)是指向量中各个元素绝对值之和,也有个美称叫“稀疏规则算子”(Lasso regularization)。
比如 向量A=[1,-1,3], 那么A的L1范数为 |1|+|-1|+|3|.
简单总结一下就是:L1范数: 为x向量各个元素绝对值之和。
L2范数: 为x向量各个元素平方和的1/2次方,L2范数又称Euclidean范数或者Frobenius范数
Lp范数: 为x向量各个元素绝对值p次方和的1/p次方.
在支持向量机学习过程中,L1范数实际是一种对于成本函数求解最优的过程,因此,L1范数正则化通过向成本函数中添加L1范数,使得学习得到的结果满足稀疏化,从而方便人类提取特征。L1范数可以使权值稀疏,方便特征提取。
L2范数可以防止过拟合,提升模型的泛化能力。
@AntZ: L1和L2的差别,为什么一个让绝对值最小,一个让平方最小,会有那么大的差别呢?看导数一个是1一个是w便知, 在靠进零附近, L1以匀速下降到零, 而L2则完全停下来了. 这说明L1是将不重要的特征(或者说, 重要性不在一个数量级上)尽快剔除, L2则是把特征贡献尽量压缩最小但不至于为零. 两者一起作用, 就是把重要性在一个数量级(重要性最高的)的那些特征一起平等共事(简言之, 不养闲人也不要超人)。
L1和L2正则先验分别服从什么分布
@齐同学:面试中遇到的,L1和L2正则先验分别服从什么分布,L1是拉普拉斯分布,L2是高斯分布。
@AntZ: 先验就是优化的起跑线, 有先验的好处就是可以在较小的数据集中有良好的泛化性能,当然这是在先验分布是接近真实分布的情况下得到的了,从信息论的角度看,向系统加入了正确先验这个信息,肯定会提高系统的性能。
对参数引入高斯正态先验分布相当于L2正则化, 这个大家都熟悉:
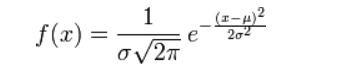

对参数引入拉普拉斯先验等价于 L1正则化, 如下图:
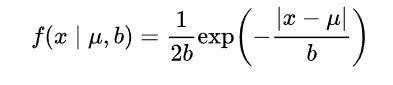

从上面两图可以看出, L2先验趋向零周围, L1先验趋向零本身。
正则化
L2正则化:目标函数中增加所有权重w参数的平方之和, 逼迫所有w尽可能趋向零但不为零. 因为过拟合的时候, 拟合函数需要顾忌每一个点, 最终形成的拟合函数波动很大, 在某些很小的区间里, 函数值的变化很剧烈, 也就是某些w非常大. 为此, L2正则化的加入就惩罚了权重变大的趋势.
L1正则化:目标函数中增加所有权重w参数的绝对值之和, 逼迫更多w为零(也就是变稀疏. L2因为其导数也趋0, 奔向零的速度不如L1给力了). 大家对稀疏规则化趋之若鹜的一个关键原因在于它能实现特征的自动选择。一般来说,xi的大部分元素(也就是特征)都是和最终的输出yi没有关系或者不提供任何信息的,在最小化目标函数的时候考虑xi这些额外的特征,虽然可以获得更小的训练误差,但在预测新的样本时,这些没用的特征权重反而会被考虑,从而干扰了对正确yi的预测。稀疏规则化算子的引入就是为了完成特征自动选择的光荣使命,它会学习地去掉这些无用的特征,也就是把这些特征对应的权重置为0。
先这么着吧,以后再补充,最近时间好紧啊。;)
参考:https://blog.csdn.net/v_JULY_v/article/details/78121924















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









