









学到了C语言中一些数据类型的数据存储原理,决定写一篇笔记加深记忆。
因C语言中,整型是以二进制存储数据的,所以学习数据存储时,记忆2的倍数是十分重要的。以下放出一个相关列表以方便查阅与记忆:
| 十进制 | 二进制 | 临界十进制 | 临界科学计数 |
| 0 | 0 | 0 | 2^0-1 |
| 1 | 1 | 1 | 2^1-1 |
| 2 | 10 | 3 | 2^2-1 |
| 3 | 11 | 7 | 2^3-1 |
| 4 | 100 | 15 | 2^4-1 |
| 5 | 101 | 31 | 2^5-1 |
| 6 | 110 | 63 | 2^6-1 |
| 7 | 111 | 127 | 2^7-1 |
| 8 | 1000(2^3) | 255 | 2^8-1 |
| 16 | 10000(2^4) | 511 | 2^9-1 |
| 32 | 100000(2^8) | 1027 | 2^10-1 |
| ...... | ...... | ...... | |
| ...... | ...... | ...... | |
| 32768 | 2^15 | 32767 | 2^15-1 |
| 65536 | 2^16 | 65535 | 2^16-1 |
注:32767,65535这两个数字十分重要,前者代表short短整型的最大取值,后者代表unsigned short无符号短整型的最大取值
对于指定位数的数据类型的取值,一个小程序便能验证:
代码:
#include <stdio.h>
#include <stdlib.h>
/*
这个程序用来验证不同位数的数据类型的取值范围(默认为有符号数据)
使用常规的二进制数转换为十进制用的方法
*/
int main()
{
int sum=0,i=1,num;//定义sum用于存储最终结果,i用于外循环,num作为指定的位数
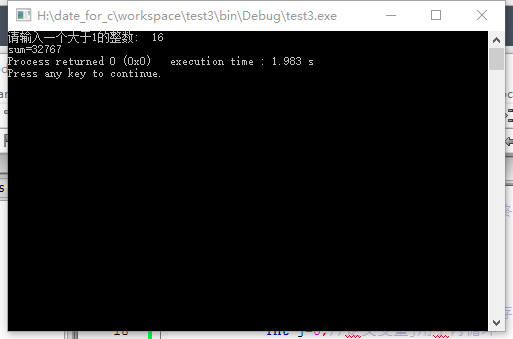
printf("请输入一个大于1的整数: ");
scanf("%d",&num);
num=num-2;//第一位用于存储符号
for(i=1;i<15;i++)
{
int temp=1;//定义变量temp用于存储内循环的结果
int j=0;//定义变量j用于内循环
for(j=0;j<i;j++)
{
temp=temp*2;//通过不断的使temp翻倍获得2的指定次方数
}
sum+=temp;//将内循环的结果存入sum
}
sum++;//将2^0存入sum
printf("sum=%d",sum);//输出结果
return 0;
}
解析:
short的字节数为2,位数为2*8=16位,当有符号时,第一位存储符号,剩下15位存储数据。因此取值为[-32768,32767] (对于为什么最大值只能达到32767而最小值却能达到-32768的问题,这位博主有详细的解释http://blog.sina.com.cn/s/blog_9f1496990100xwzo.html)
unsigned short的字节数为2,位数为2*8=16位,但因为没有符号,全部16位都能用于存储数据。因此取值为[0,65535]
当给一个数据类型赋了超过其最大数的值时,就会出现“数据溢出”。以下是验证:
代码:
#include <stdio.h>
#include <stdlib.h>
/*
这个代码用于测试数据溢出的效果
*/
int main()
{
short a,b;
a=32760;
printf("a=%d\n",a);//输出a以验证a的值
b=a+10;//a+10之后为32770,已经超出了short类型的最大值
printf("b=%d",b);//输出b以查看效果
return 0;
}
解析:
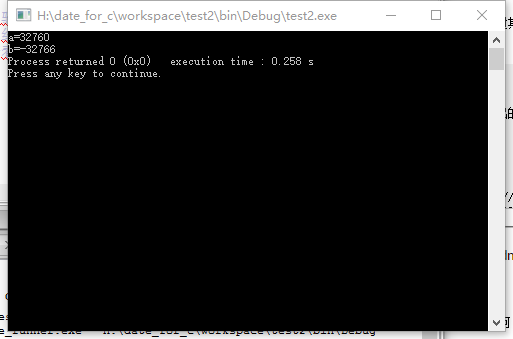
当数据存储之后,数据会向前“进位”即原用作表示符号的第一位被变成了1,所以数值变为了负数。
附:浮点数存储详解:http://blog.sina.com.cn/s/blog_814e83d80101bgcf.html (这篇博文详细解析了浮点数存储的原理和几种规则)
为了测试单精度和双精度浮点型的精度差别,写了以下测试代码:
代码:
#include <stdio.h>
#include <stdlib.h>
/*
这个代码用于测试浮点型数的精度
*/
int main()
{
double a=2.333333333333333333333333f;//加了f之后,a将被定义成单精度浮点型(float)
double b=2.333333333333333333333333;//定义一个双精度浮点型b
float c=2.333333333333333333333333;//定义一个单精度浮点型c
float d=2.333333333333333333333333f;//测试f对单精度浮点型数d的影响
/*
用四种方式输出以上的数,测试输出方式和精度的关系
*/
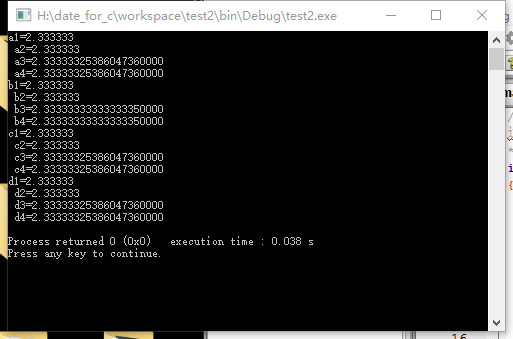
printf("a1=%f \n a2=%lf \n a3=%.20lf \n a4=%.20f \n",a,a,a,a);
printf("b1=%f \n b2=%lf \n b3=%.20lf \n b4=%.20f \n",b,b,b,b);
printf("c1=%f \n c2=%lf \n c3=%.20lf \n c4=%.20f \n",c,c,c,c);
printf("d1=%f \n d2=%lf \n d3=%.20lf \n d4=%.20f \n",d,d,d,d);
return 0;
}
输出:
解析:
1.由以上代码的测试结果可知,单精度浮点型数据的有效数字大约为7位,双精度浮点型的有效数字大约为11位。
2.当数据后面加上了f,数据类型将强制变为单精度浮点型。
3.%f和%lf都能输出浮点型数据类型,但他们都默认只输出7位有效数字(%f默认是用于输出double型数据的,而%lf默认是用于输出long double型数据的,但也可用他们来输出float型数据)。
4.通过在%f或%lf前加上输出格式参数将之变为如%0.9f或%0.9lf可人为控制输出的有效数字,但这不会改变该数据本身的精度,超出精度范围的数字将是随机的。
浮点型数据误差:
浮点型数据的存储方式是会产生误差的,这个误差是其二进制存储结构带来的,即使数据大小在精度范围之内,也完全无法避免。
我编写了以下代码来验证误差的存在以及其对程序运行造成的影响:
代码:
#include <stdio.h>
#include <stdlib.h>
/*
这个程序用来验证浮点型数的误差
*/
int main()
{
//验证单精度型浮点数的误差
double a1 = 0.6f;
double b1 = 0.65f;
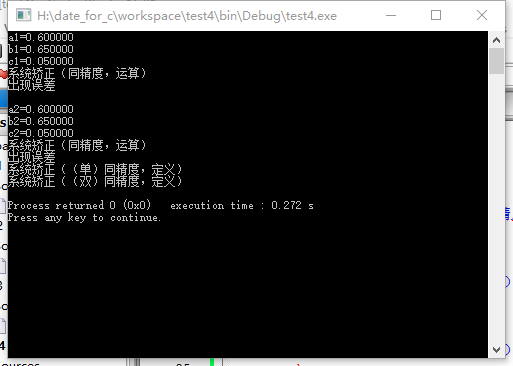
printf("a1=%f\n",a1);
printf("b1=%f\n",b1);
double c1=b1-a1;
double d1=b1-a1;
double e1=0.05f;
double f1=0.05;
printf("c1=%f\n",c1);
if(c1==0.05)
{
printf("无误差\n");
}
if(c1==d1)
{
printf("系统矫正(同精度,运算)\n");//验证系统在对比两个运算产生的浮点型数据时是否有容差机制
}
if(c1==e1)
{
printf("系统矫正(运算与定义)\n");//验证系统在对比运算产生与直接定义的浮点型数据时是否有容差机制
}
if(e1==f1)
{
printf("系统矫正(定义)\n");
}
if(c1==f1)
{
printf("系统矫正(不同精度,运算与定义)\n");//验证系统在对比不同精度的浮点数据时是否有容差机制
}
if(c1!=0.05)
{
printf("出现误差\n");
}
printf("\n");
//验证双精度型浮点数的误差
double a2 = 0.6;
double b2 = 0.65;
printf("a2=%f\n",a2);
printf("b2=%f\n",b2);
double c2=b2-a2;
double d2=b2-a2;
double e2=0.05f;
double f2=0.05;
printf("c2=%f\n",c2);
if(c2==0.05)
{
printf("无误差\n");
}
if(c2==d2)
{
printf("系统矫正(同精度,运算)\n");
}
if(c2==e2)
{
printf("系统矫正(运算与定义)\n");
}
if(e2==f2)
{
printf("系统矫正(不同精度,定义)\n");
}
if(c2==f2)
{
printf("系统矫正(不同精度,运算与定义)\n");
}
if(c2!=0.05)
{
printf("出现误差\n");
}
//剩下的杂项验证
if(c1==c2)
{
printf("系统矫正(不同精度,运算)\n");
}
if(e1==e2)
{
printf("系统矫正((单)同精度,定义)\n");
}
if(f1==f2)
{
printf("系统矫正((双)同精度,定义)\n");
}
}输出:
解析:
1.无论是何种精度的浮点型数据,在存储,运算过程中都必然会出现误差。
2.当且仅当,两个浮点型数据是相同的精度,并数据来源相同时(同为运算获得,或同为定义获得),系统才会自动的在对于他们的==判断中给予容差。
总结:
当程序需要涉及到浮点数的相等判断是,应当清楚的认识到其误差,并细致的排除其对程序的影响。(如:将a==b改成|a-b|<0.0000001或|a-b|<1*e^-8)















 547
547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









