







本篇文章是个人翻译的,如有商业用途,请通知本人谢谢.
Vanishing/Exploding Gradients Problems
正如我们在第10章中所讨论的那样,反向传播算法的工作原理是从输出层到输入层,传播错误梯度。 一旦该算法已经计算了网络中每个参数的损失函数的梯度,它就使用这些梯度来用梯度下降步骤来更新每个参数。
不幸的是,梯度往往变得越来越小,随着算法进展到下层。 结果,梯度下降更新使得低层连接权重实际上保持不变,并且训练永远不会收敛到良好的解决方案。 这被称为消失梯度问题。 在某些情况下,可能会发生相反的情况:梯度可能变得越来越大,许多分层得到疯狂的权重更新,算法发散。 这是梯度爆炸的问题,这在回归神经网络中最常见(见第14章)。 更一般地说,深度神经网络遭受不稳定的梯度; 不同的层次可能以不同的速度学习。
虽然这种不幸的行为已经经过了相当长的一段时间的实验观察(这是造成深度神经网络大部分时间都被抛弃的原因之一),但在2010年左右,人们才有了明显的进步。 Xavier Glorot和Yoshua Bengio发表的题为“Understanding the Difficulty of Training Deep Feedforward Neural Networks”的论文发现了一些疑问,包括流行的sigmoid激活函数和当时最受欢迎的权重初始化技术的组合,即随机初始化时使用平均值为0,标准偏差为1的正态分布。简而言之,他们表明,用这个激活函数和这个初始化方案,每层输出的方差远大于其输入的方差。在网络中前进,每层之后的变化持续增加,直到激活函数饱和在顶层。这实际上是因为对数函数的平均值为0.5而不是0(双曲正切函数的平均值为0,表现略好于深层网络中的逻辑函数)
看一下sigmoid激活函数(参见图11-1),可以看到当输入变大(负或正)时,函数饱和在0或1,导数非常接近0.因此,当反向传播开始时, 它几乎没有梯度通过网络传播回来,而且由于反向传播通过顶层向下传递,所以存在的小梯度不断地被稀释,因此下层确实没有任何东西可用。
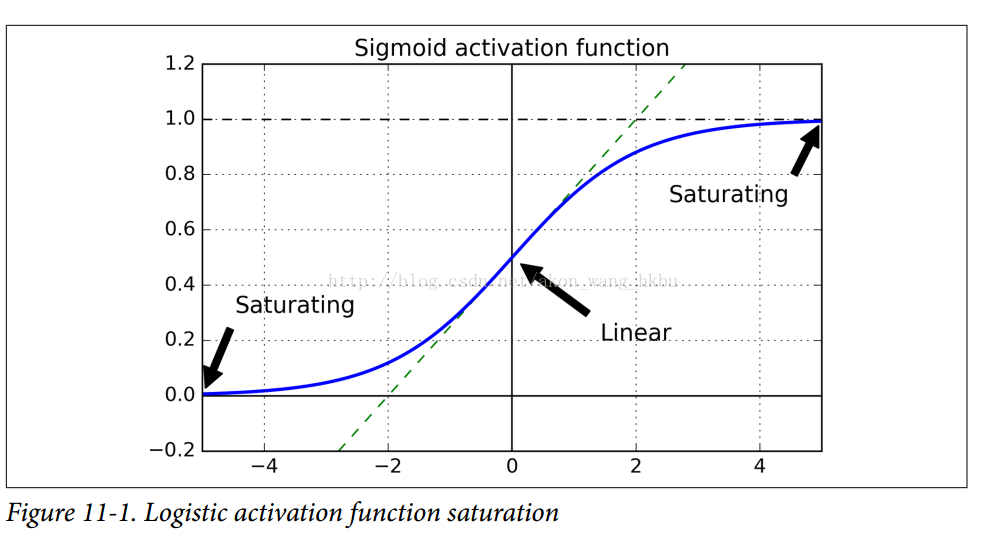
Glorot和Bengio在他们的论文中提出了一种显着缓解这个问题的方法。 我们需要信号在两个方向上正确地流动:在进行预测时是正向的,在反向传播梯度时是反向的。 我们不希望信号消失,也不希望它爆炸并饱和。 为了使信号正确流动,作者认为,我们需要每层输出的方差等于其输入的方差.(这里有一个比喻:如果将麦克风放大器的旋钮设置得太接近于零,人们听不到声音,但是如果将麦克风放大器设置得太接近麦克风,声音就会饱和,人们不会理解你在说什么。 现在想象一下这样一个放大器的链条:它们都需要正确设置,以便在链条的末端响亮而清晰地发出声音。 你的声音必须以每个放大器的振幅相同的幅度出来。)而且我们也需要梯度在相反方向上流过一层之前和之后有相同的方差(如果您对数学细节感兴趣,请查阅论文)。实际上不可能保证两者都是一样的,除非这个层具有相同数量的输入和输出连接,但是他们提出了一个很好的折衷办法,在实践中证明这个折中办法非常好:随机初始化连接权重必须如公式11-1所描述的那样.其中n_inputs和n_outputs是权重正在被初始化的层(也称为扇入和扇出)的输入和输出连接的数量。 这种初始化策略通常被称为Xavier初始化(在作者的名字之后),或者有时是Glorot初始化。

当输入连接的数量大致等于输出连接的数量时,可以得到更简单的等式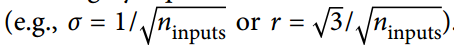
使用Xavier初始化策略可以大大加快训练速度,这是导致Deep Learning目前取得成功的技巧之一。 最近的一些论文针对不同的激活函数提供了类似的策略,如表11-1所示。 ReLU激活函数(及其变体,包括简称ELU激活)的初始化策略有时称为He初始化(在其作者的姓氏之后)。

默认情况下,fully_connected()函数(在第10章中介绍)使用Xavier初始化(具有统一的分布)。 你可以通过使用如下所示的variance_scaling_initializer()函数来将其更改为He初始化:
注意:本书使用tensorflow.contrib.layers.fully_connected()而不是tf.layers.dense()(本章编写时不存在)。 现在最好使用tf.layers.dense(),因为contrib模块中的任何内容可能会更改或删除,恕不另行通知。 dense()函数几乎与fully_connected()函数完全相同。 与本章有关的主要差异是:
几个参数被重新命名:范围变成名字,activation_fn变成激活(类似地,_fn后缀从诸如normalizer_fn之类的其他参数中移除),weights_initializer变成kernel_initializer等等。默认激活现在是None,而不是tf.nn.relu。 它不支持tensorflow.contrib.framework.arg_scope()(稍后在第11章中介绍)。 它不支持正规化的参数(稍后在第11章介绍)。
he_init = tf.contrib.layers.variance_scaling_initializer() hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu, kernel_initializer=he_init, name="hidden1")
他的初始化只考虑了扇入,而不是像Xavier初始化那样扇入和扇出之间的平均值。 这也是variance_scaling_initializer()函数的默认值,但您可以通过设置参数mode =“FAN_AVG”来更改它。
Nonsaturating Activation Functions
Glorot和Bengio在2010年的论文中的一个见解是,消失/爆炸的梯度问题部分是由于激活函数的选择不好造成的。 在那之前,大多数人都认为,如果大自然选择在生物神经元中使用sigmoid激活函数,它们必定是一个很好的选择。 但事实证明,其他激活函数在深度神经网络中表现得更好,特别是ReLU激活函数,主要是因为它对正值不会饱和(也因为这样所以计算速度很快)。
不幸的是,ReLU激活功能并不完美。 它有一个被称为死亡ReLUs的问题:在训练过程中,一些神经元有效地死亡,意味着它们停止输出0以外的任何东西。在某些情况下,你可能会发现你网络的一半神经元已经死亡,特别是如果你使用大 学习率。 在训练期间,如果神经元的权重得到更新,使得神经元输入的加权和为负,则它将开始输出0.当发生这种情况时,由于ReLU函数的梯度为0时,神经元不可能恢复生命当其输入为负。
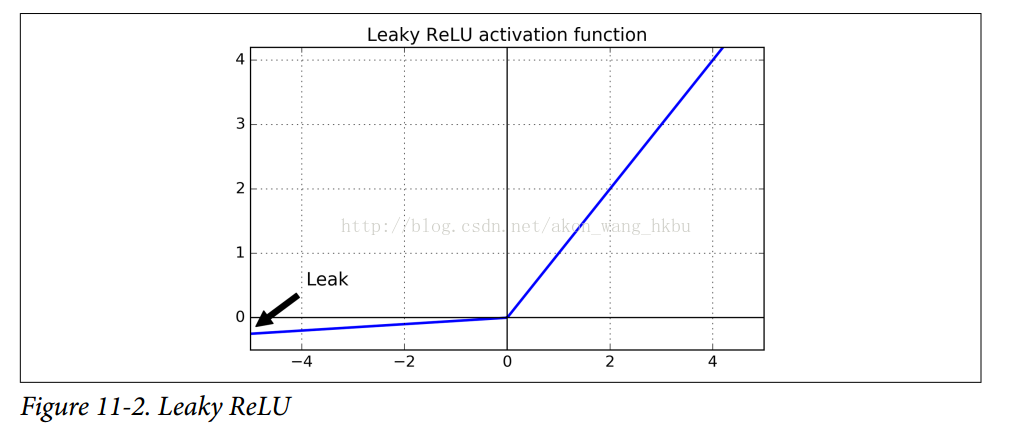
为了解决这个问题,你可能需要使用ReLU函数的一个变体,比如leaky ReLU。这个函数定义为LeakyReLUα(z)= max(αz,z)(见图11-2)。超参数α定义了函数“leaks”的程度:它是z <0的函数的斜率,通常设置为0.01。这个小斜坡确保leaky ReLUs永不死亡;他们可能会长期昏迷,但他们有机会最终醒来。最近的一篇论文比较了几种ReLU激活功能的变体,其中一个结论是leaky Relu总是优于严格的ReLU激活函数。事实上,设定α= 0.2(巨大leak)似乎导致比α= 0.01(小leak)更好的性能。他们还评估了随机leakt ReLU(RReLU),其中α在训练期间在给定范围内随机挑选,并在测试期间固定为平均值。它表现相当好,似乎是一个正规化者(减少训练集的过拟合风险)。最后,他们还评估了参数 leaky ReLU(PReLU),其中α被授权在训练期间被学习(而不是超参数,它变成可以像任何其他参数一样被反向传播修改的参数)。据报道这在大型图像数据集上的表现强于ReLU,但是对于较小的数据集,其具有过度拟合训练集的风险。
最后但并非最不重要的一点是,Djork-ArnéClevert等人在2015年的一篇论文中提出了一种称为指数线性单元 exponential linear unit (ELU)的新的激活函数,在他们的实验中表现优于所有的ReLU变体:训练时间减少,神经网络在测试集上表现的更好。 如图11-3所示,公式11-2给出了它的定义。
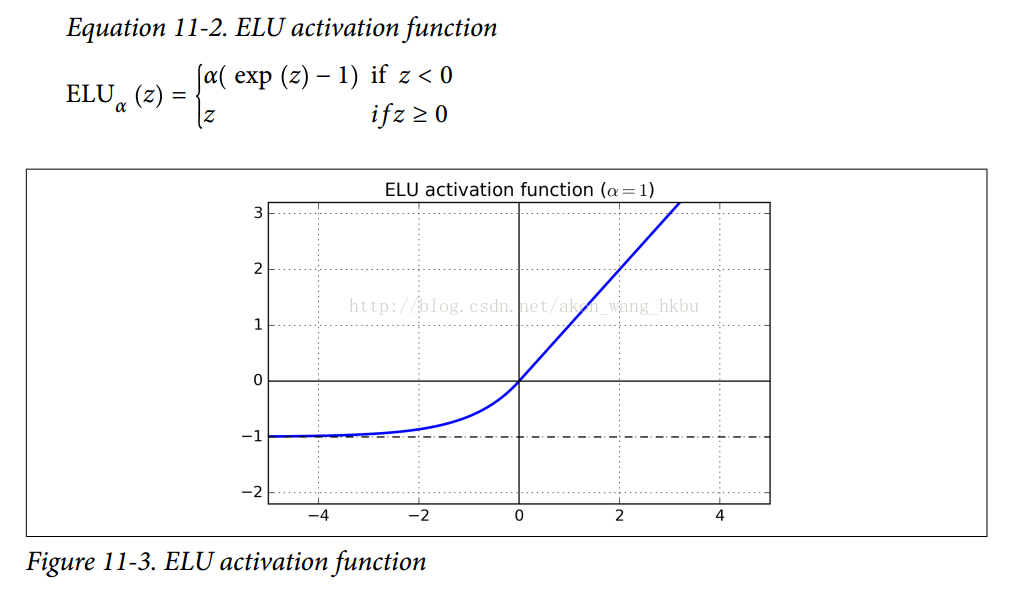
它看起来很像ReLU功能,但有一些区别,主要区别在于:
- 首先它在z <0时取负值,这使得该单元的平均输出接近于0.这有助于减轻消失梯度问题,如前所述。 超参数α定义当z是一个大的负数时,ELU函数接近的值。 它通常设置为1,但是如果你愿意,你可以像调整其他超参数一样调整它。
- 其次,它对z <0有一个非零的梯度,避免了神经元死亡的问题.
- 第三,函数在任何地方都是平滑的,包括z = 0左右,这有助于加速梯度下降,因为它不会像z = 0的左边和右边那样反弹。
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.elu, name="hidden1")TensorFlow没有针对leaky ReLU的预定义函数,但是很容易定义:
def leaky_relu(z, name=None): return tf.maximum(0.01 * z, z, name=name) hidden1 = tf.layers.dense(X, n_hidden1, activation=leaky_relu, name="hidden1")
尽管使用HE初始化和ELU(或任何ReLU变体)可以显着减少训练开始阶段的消失/爆炸梯度问题,但不保证在训练期间问题不会回来。

μB 是整个小批量B的经验均值
σB 是经验性的标准差,也是来评估整个小批量的。
mB 是小批量中的实例数量。
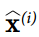
γ 是层的缩放参数。
β是层的移动参数(偏移量)
ε是一个很小的数字,以避免被零除(通常为10 ^ -3)。 这被称为平滑术语(拉布拉斯平滑Laplace Smoothing)。
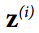
在测试时,没有小批量计算经验均值和标准差,所以您只需使用整个训练集的均值和标准差。 这些通常在训练期间使用移动平均值进行有效计算。 因此,总的来说,每个批次标准化的层次都学习了四个参数:γ(标度),β(偏移),μ(平均值)和σ(标准偏差)。
作者证明,这项技术大大改善了他们试验的所有深度神经网络。消失梯度问题大大减少了,他们可以使用饱和激活函数,如tanh甚至sigmoid激活函数。网络对权重初始化也不那么敏感。他们能够使用更大的学习速度,显着加快了学习过程。具体地,他们指出,“适用于一个国家的最先进的图像分类模型,批标准化实现了与14倍更少的训练步骤相同的精度,和以显著的优势击败了原始模型。 [...]使用批量归一化的网络集合,我们改进了ImageNet分类上的最佳公布结果:达到4.9%的前5个验证错误(和4.8%的测试错误),超出了人类评估者的准确性。批量标准化也像一个正规化者一样,减少了对其他正则化技术(如本章稍后描述的dropout).
但是,批量标准化确实增加了模型的一些复杂性(尽管它消除了对输入数据进行标准化的需要,因为如果批的标准化处理,第一个隐藏层将处理这个问题)。 此外,还存在运行时间的损失:由于每层所需的额外计算,神经网络的预测速度较慢。 所以,如果你需要预测闪电般快速,你可能想要检查普通ELU + He初始化执行之前如何执行批量规范化。
您可能会发现,训练起初相当缓慢,而渐变下降正在寻找每层的最佳尺度和偏移量,但一旦找到合理的好值,它就会加速。
Implementing Batch Normalization with TensorFlow
TensorFlow提供了一个batch_normalization()函数,它简单地对输入进行居中和标准化,但是您必须自己计算平均值和标准偏差(基于训练期间的小批量数据或测试过程中的完整数据集) 作为这个函数的参数,并且还必须处理缩放和偏移量参数的创建(并将它们传递给此函数)。 这是可行的,但不是最方便的方法。 相反,你应该使用batch_norm()函数,它为你处理所有这些。 您可以直接调用它,或者告诉fully_connected()函数使用它,如下面的代码所示:
注意:本书使用tensorflow.contrib.layers.batch_norm()而不是tf.layers.batch_normalization()(本章写作时不存在)。 现在最好使用tf.layers.batch_normalization(),因为contrib模块中的任何内容都可能会改变或被删除,恕不另行通知。 我们现在不使用batch_norm()函数作为fully_connected()函数的正则化参数,而是使用batch_normalization(),并明确地创建一个不同的层。 参数有些不同,特别是:
- decay更名为momentum
- is_training被重命名为training
- updates_collections被删除:批量标准化所需的更新操作被添加到UPDATE_OPS集合中,并且您需要在训练期间明确地运行这些操作(请参阅下面的执行阶段)
- 我们不需要指定scale = True,因为这是默认值。
import tensorflow as tf n_inputs = 28 * 28 n_hidden1 = 300 n_hidden2 = 100 n_outputs = 10 X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X") training = tf.placeholder_with_default(False, shape=(), name='training') hidden1 = tf.layers.dense(X, n_hidden1, name="hidden1") bn1 = tf.layers.batch_normalization(hidden1, training=training, momentum=0.9) bn1_act = tf.nn.elu(bn1) hidden2 = tf.layers.dense(bn1_act, n_hidden2, name="hidden2") bn2 = tf.layers.batch_normalization(hidden2, training=training, momentum=0.9) bn2_act = tf.nn.elu(bn2) logits_before_bn = tf.layers.dense(bn2_act, n_outputs, name="outputs") logits = tf.layers.batch_normalization(logits_before_bn, training=training, momentum=0.9)
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X") training = tf.placeholder_with_default(False, shape=(), name='training')为了避免一遍又一遍重复相同的参数,我们可以使用Python的partial()函数:
from functools import partial my_batch_norm_layer = partial(tf.layers.batch_normalization, training=training, momentum=0.9) hidden1 = tf.layers.dense(X, n_hidden1, name="hidden1") bn1 = my_batch_norm_layer(hidden1) bn1_act = tf.nn.elu(bn1) hidden2 = tf.layers.dense(bn1_act, n_hidden2, name="hidden2") bn2 = my_batch_norm_layer(hidden2) bn2_act = tf.nn.elu(bn2) logits_before_bn = tf.layers.dense(bn2_act, n_outputs, name="outputs") logits = my_batch_norm_layer(logits_before_bn)
from functools import partial
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
if __name__ == '__main__':
n_inputs = 28 * 28
n_hidden1 = 300
n_hidden2 = 100
n_outputs = 10
mnist = input_data.read_data_sets("/tmp/data/")
batch_norm_momentum = 0.9
learning_rate = 0.01
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name = 'X')
y = tf.placeholder(tf.int64, shape=None, name = 'y')
training = tf.placeholder_with_default(False, shape=(), name = 'training')#给Batch norm加一个placeholder
with tf.name_scope("dnn"):
he_init = tf.contrib.layers.variance_scaling_initializer()
#对权重的初始化
my_batch_norm_layer = partial(
tf.layers.batch_normalization,
training = training,
momentum = batch_norm_momentum
)
my_dense_layer = partial(
tf.layers.dense,
kernel_initializer = he_init
)
hidden1 = my_dense_layer(X ,n_hidden1 ,name = 'hidden1')
bn1 = tf.nn.elu(my_batch_norm_layer(hidden1))
hidden2 = my_dense_layer(bn1, n_hidden2, name = 'hidden2')
bn2 = tf.nn.elu(my_batch_norm_layer(hidden2))
logists_before_bn = my_dense_layer(bn2, n_outputs, name = 'outputs')
logists = my_batch_norm_layer(logists_before_bn)
with tf.name_scope('loss'):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels = y, logits= logists)
loss = tf.reduce_mean(xentropy, name = 'loss')
with tf.name_scope('train'):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logists, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
init = tf.global_variables_initializer()
saver = tf.train.Saver()
n_epoches = 20
batch_size = 200
#注意:由于我们使用的是tf.layers.batch_normalization()而不是tf.contrib.layers.batch_norm()(如本书所述),
#所以我们需要明确运行批量规范化所需的额外更新操作(sess.run([ training_op,extra_update_ops],...)。
extra_update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.Session() as sess:
init.run()
for epoch in range(n_epoches):
for iteraton in range(mnist.train.num_examples//batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run([training_op,extra_update_ops],
feed_dict={training:True, X:X_batch, y:y_batch})
accuracy_val = accuracy.eval(feed_dict= {X:mnist.test.images,
y:mnist.test.labels})
print(epoch, 'Test accuracy:', accuracy_val)
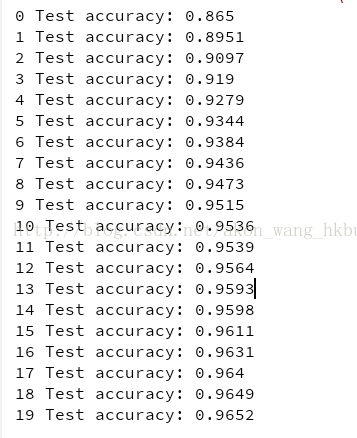
with tf.name_scope("train"): optimizer = tf.train.GradientDescentOptimizer(learning_rate) extra_update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS) with tf.control_dependencies(extra_update_ops): training_op = optimizer.minimize(loss)这样,你只需要在训练过程中评估training_op,TensorFlow也会自动运行更新操作:
sess.run(training_op, feed_dict={training: True, X: X_batch, y: y_batch})
Gradient Clipping (梯度剪裁)
减少爆炸梯度问题的一种常用技术是在反向传播过程中简单地剪切梯度,使它们不超过某个阈值(这对于递归神经网络是非常有用的;参见第14章)。 这就是所谓的渐变剪裁。一般来说,人们更喜欢批量标准化,但了解渐变剪裁以及如何实现它仍然是有用的。
在TensorFlow中,优化器的minimize()函数负责计算梯度并应用它们,所以您必须首先调用优化器的compute_gradients()方法,然后使用clip_by_value()函数创建一个剪辑梯度的操作,最后 创建一个操作来使用优化器的apply_gradients()方法应用剪切梯度:
threshold = 1.0 optimizer = tf.train.GradientDescentOptimizer(learning_rate) grads_and_vars = optimizer.compute_gradients(loss) capped_gvs = [(tf.clip_by_value(grad, -threshold, threshold), var) for grad, var in grads_and_vars] training_op = optimizer.apply_gradients(capped_gvs)像往常一样,您将在每个训练阶段运行这个training_op。 它将计算梯度,将它们夹在-1.0和1.0之间,并应用它们。 threhold是您可以调整的超参数。














 4552
4552











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









