






用STL实现DFS/BFS算法
——基于策略的类设计
在引入boost.Multi_index容器之前,我想有必要先整理一下DFS/BFS的代码。修改是出于以下几方面原因,其中之一是:近期拜读了Andrei Alexandrescu的《Modern C++ Design》,深受启发,书中的第一章讲述了基于策略的类设计,因此我也想参照这种设计方法来重写一次代码。另外的一个原因是:原来的代码中使用了queue容器和stack容器,它们会把已搜索过的结点删除掉,如果我们想要在容器内进行查重的话,就必须保留所有结点,所以不能再使用这两种容器。我想先选用一种接近于boost.Multi_index的STL容器来改写,然后再逐步过渡到真正的Multi_index容器。
我们先说换用什么容器,一开始我也想过使用vector容器,不过由于我们最终的目标是Multi_index容器,它不能象vector那样进行随机访问,它只能实现list容器的功能,为了便于向Multi_index过渡,最终我还是选择了list。不能使用vector的另一个原因是,DFS要求在容器的中间插入元素(我们很快就会看到这一点),vector不适合做这样的操作。
没有了queue和stack,我们就要用一个iterator来区分list中那些已搜索与未搜索的结点。我把已搜索和未搜索的结点分别放在list的两端,而这个iterator指向它们的分界线,即iterator之前的结点为已搜索结点,之后的结点为未搜索结点。当我们需要取出下一个结点来处理时,只要把iterator后移一下就可以了;对当前结点调用nextStep()所得到的下一层结点,则要视DFS或BFS来决定如何插入list;如果是DFS,就把新得到的结点插入到iterator的后面;如果是BFS,则把新的结点插入到list的后端;当iterator到达list的末端时,则表示搜索结束。
用一个图来表示可能会更直观一些:
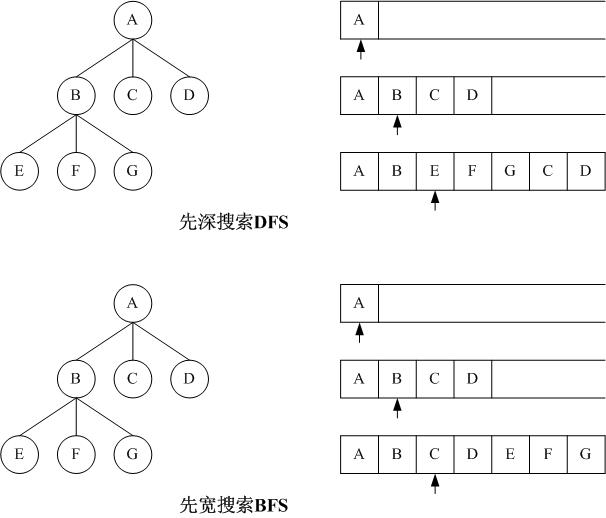
假如我们有初始问题状态A,从A可以生成下一层(或者说下一步)的状态B、C、D,同样从B可以生成下一层的状态E、F、G。对于DFS,我们的搜索顺序应该是A、B、E…,而这些状态的生成次序应该是A、B、C、D、E、F、G…,当我们用list来作为存放状态树时,我们要用一个迭代器(图中的箭头)指向当前处理的状态。我们把初始状态A放入list容器,箭头指向它,然后按以下方法进行迭代:读出箭头指向的元素(一个状态结点),根据该状态生成下一层结点(所有可能的下一步状态),逐一插入到箭头所指位置的后面 (同一层的结点插入的顺序不太要紧,为了易于表述,我们假设以D、C、B的顺序入栈);然后箭头后移一格;如此类推,读出B,生成E、F、G插入箭头的后面。这样这个list以及箭头的行为就象栈的作用一样了,箭头左边的元素为已处理完的状态结点,右边的元素为待处理的状态结点。
我们再来看看BFS,正确的搜索顺序应该是A、B、C、D、E…,这个顺序与状态的生成顺序完全相同,我们仍旧用list来作为存放状态树的容器了,不过插入新结点的位置有所不同。我们把初始状态A放入list容器,箭头指向它,然后按以下方法进行迭代:读出箭头指向的元素(一个状态结点),根据该状态生成下一层结点(所有可能的下一步状态),逐一插入到list的末端;然后箭头后移一格;如此类推,读出B,生成E、F、G插入到list的末端。这样这个list以及箭头的行为就象队列一样了,与DFS相同,箭头左边的元素为已处理完的状态结点,右边的元素为待处理的状态结点。
现在我们来看看如何对DFS/BFS搜索算法进行基于策略的设计。首先我们设计的应该是一个类模板,而不是象早前的函数模板,该类模板提供一个成员函数让使用者调用以完成搜索的工作。我给这个类模板起的名字是StateSpaceTreeSearch(状态空间树搜索),如下:
template < class State, template <class> class SearchInserter,
template <class> class CheckDup >
class StateSpaceTreeSearch
{
…
}
它被设计为接受三个模板参数,每一个分别代表解决具体问题时需采取的一种策略。第一个模板参数State是为具体问题所编写的问题状态类(如我们以前见过的SudokuState、QueenState、SokoState),它的数据成员应该用于保存表示问题状态所需的数据(如SudokuState用一个二维整数数组来表示数独游戏的状态,而QueenState则用一个一维整数数组来表示棋盘的状态等等),它的成员函数中应至少包含nextStep()和isTarget(),前者用于从一个状态推算出下一步的各种可能状态,后者用于判断当前状态是否符合解答的要求。当然为了方便起见或其它要求(如查重算法的要求),问题状态类还可能需要提供其它成员函数(如operator<<、operator>>、operator==、operator<、hash()等等)。
第二个模板参数SearchInserter是一个模板模板参数,它用于指定使用BFS还是DFS。正如我们前面分析的那样,如果采用list来存放状态结点,那么BFS和DFS的差别仅在于新结点的插入方法。我们需要针对BFS和DFS分别提供一种插入方法(这就是策略了),当使用者用不同的插入方法来实例化StateSpaceTreeSearch时,就等于选择了BFS或DFS。
第三个模板参数CheckDup也是一个模板模板参数,不错,它就是用于指定对状态进行查重的策略。我们在上一版本中已经提供了四种查重策略(不知道你还记不记得,它们分别是NoCheckDup、SequenceCheckDup、OrderCheckDup和HashCheckDup),这里我们同样使用这四种策略。不过,有一点小小的变化,是关于HashCheckDup的。
在上一个版本中,CheckDup的使用方法是由调用者选用一种合适的查重方法,实例化出一个函数对象,然后把该函数对象作为函数调用参数传递给DFS/BFS算法的函数模板。CheckDup对象的实例化代码由使用者负责,这样代码可以比较灵活,但增加了使用者的负担(使用者有可能写出错误的代码)。在重新进行基于策略的设计后,使用者只需要指定查重的策略即可,不需要再负责实例化出CheckDup对象。CheckDup对象的实例化工作由StateSpaceTreeSearch负责,这样就要求各种CheckDup策略必须要使用相同的格式来实例化。当我回过头来查看原来的四种查重策略的代码时,我发现,NoCheckDup、SequenceCheckDup和OrderCheckDup三个都是只有一个模板参数的,而HashCheckDup则有两个模板参数,虽然它的第二个模板参数有缺省值,但是这还是会引起某些编译器的编译错误。所以,我们要让HashCheckDup也只带一个模板参数,要做到这一点并不太难,大家看看以下代码就会明白了。
//
仿函式,用于不检查状态结点是否重复
template <class T>
struct NoCheckDup : std::unary_function<T, bool>
{
bool operator() (const T&) const
{
return false;
}
};
//
仿函式,用vector容器检查状态结点是否重复,线性复杂度
//
要求状态类提供operator==
template <class T>
class SequenceCheckDup : std::unary_function<T, bool>
{
typedef vector<T> Cont;
Cont states_;
public:
bool operator() (const T& s)
{
typename Cont::iterator i =
find(states_.begin(), states_.end(), s);
if (i != states_.end()) //
状态已存在,重复
{
return true;
}
states_.push_back(s); //
状态未重复,记录该状态
return false;
}
};
//
仿函式,用set容器检查状态结点是否重复,对数复杂度
//
要求状态类提供operator<
template <class T>
class OrderCheckDup : std::unary_function<T, bool>
{
typedef set<T> Cont;
Cont states_;
public:
bool operator() (const T& s)
{
typename Cont::iterator i = states_.find(s);
if (i != states_.end()) //
状态已存在,重复
{
return true;
}
states_.insert(i, s); //
状态未重复,记录该状态
return false;
}
};
//
仿函式,用hash_set容器检查状态结点是否重复
//
要求状态类提供operator==以及hash()成员函数
template <class T>
class HashCheckDup : std::unary_function<T, bool>
{
struct HashFcn
{
size_t operator()(const T& s) const { return s.hash(); }
};
typedef hash_set<T, HashFcn> Cont;
Cont states_;
public:
HashCheckDup() : states_(100, HashFcn()) {}
bool operator() (const T& s)
{
if (states_.find(s) != states_.end()) //
状态已存在,重复
{
return true;
}
states_.insert(s); //
状态未重复,记录该状态
return false;
}
};
前三个CheckDup都与旧版本一样,而最后一个HashCheckDup则有了小小的变化。新的接口是,要求状态类提供operator==以及hash()成员函数,后者是用于计算hash值的。HashCheckDup中定义了一个嵌套函数对象类HashFcn,它通过调用状态类所提供的hash()成员函数来计算hash值并返回给hash_set容器。其它部分都与旧版本一样,可见改变是很小的。现在,我们的四个查重策略都具有相同的模板参数格式了。
我们再回过头来看看BFS和DFS分别所对应的SearchInserter,它们的代码如下:
// BFS
算法对应的新结点插入策略
template <class Cont>
class BFSInserter
{
public:
BFSInserter(Cont& c) : c_(c) {}
typedef typename Cont::iterator iterator;
typedef typename Cont::value_type value_type;
void operator()(iterator it, const value_type& v) {
c_.push_back(v); //
新结点插入到列表的末端,即未搜索的结点后
}
private:
Cont& c_;
};
// DFS
算法对应的新结点插入策略
template <class Cont>
class DFSInserter
{
public:
DFSInserter(Cont& c) : c_(c) {}
typedef typename Cont::iterator iterator;
typedef typename Cont::value_type value_type;
void operator()(iterator it, const value_type& v) {
c_.insert(++it, v); //
新结点插入到未搜索的结点前
}
private:
Cont& c_;
};
BFSInserter和DFSInserter都是函数对象类模板,它们以保存状态空间树的容器为模板参数,提供一个operator()操作符,该操作符函数接受一个指向容器内的迭代器和一个要插入到容器里的值,它负责执行插入的动作。BFS和DFS分别对应于不同的插入策略。
可选的SearchInserter和CheckDup策略都已准备好了,在进入到StateSpaceTreeSearch的实现部分之前,我们再讨论一个小问题,就是关于SearchInserter和CheckDup这两个模板参数的顺序和缺省值的问题。Andrei Alexandrescu在《Modern C++ Design》中说到,我们应该把最可能被使用者显式指定的策略放在前面,同时把使用者最可能使用的某种策略作为该类策略的缺省值。
那么,第一个问题:SearchInserter和CheckDup分别应该使用什么缺省值?我觉得,很多实际问题会要求给出最少步数的解法,这时就应该使用BFS而不是DFS,所以我选择了BFSInserter作为SearchInserter的缺省值。至于CheckDup,我就选择了对性能影响最少的NoCheckDup作为缺省值。
第二个问题:对于SearchInserter和CheckDup,哪一个会更多地被显式指定?我觉得好象差不多,所以就比较随意地安排了现在这个次序。
下面准备进入StateSpaceTreeSearch。我们再来重温一次,通常解决一个具体的搜索问题,除了前面已经提到的State、SearchInserter和CheckDup以外,我们还需要什么?对了,就是一个初始状态(它应该是一个State对象)和一个关于找到解答后的回调函数(也可以看成是某种策略)。初始状态无疑应该作为函数调用的参数被传入,但是回调函数呢?它应不应该也成为StateSpaceTreeSearch的一类策略呢?
我的看法是,State、SearchInserter和CheckDup三部分已经组成了一个具体问题的解法,使用者应该用这三个组成部分来实例化出一种具体问题(如推箱子)的解法,如下:
StateSpaceTreeSearch<SokoState, BFSInserter, OrderCheckDup> sokoSearch;
而当你需要对这种问题的某个特定题目(如一道具体的推箱子题目)进行解答时,你应该执行这个解法sokoSearch,并把题目传入,等待sokoSearch返回答案,如:
sokoSearch(initState);
那么,找到解答后所执行的回调函数应该属于问题解法的范畴还是属于特定题目解答的范畴呢?我认为,把它归入到后者会更为灵活些。例如,对于同一种问题(如推箱子),我们可以用一个sokoSearch对象来解答多条特定题目,并且每条题目可以选择不同的回调函数。如:
sokoSearch(initState1, printAnswerAndContinue);
sokoSearch(initState2, printAnswerAndStop);
所以,我把StateSpaceTreeSearch设计为一个函数对象类模板,即它提供一个operator(),该操作符函数接受两个参数:一个是问题的初始状态,另一个是找到解答后的回调函数,函数的返回值为整数,表示搜索结束时找到的解答数量。StateSpaceTreeSearch的代码如下:
//
状态空间树搜索模板
// State
:问题状态类,提供nextStep()和isTarget()成员函数
// SearchInserter
:可选择BFS或DFS
// CheckDup
:状态查重算法,可选择NoCheckDup,HashCheckDup,OrderCheckDup等
template < class State, template <class> class SearchInserter = BFSInserter,
template <class> class CheckDup = NoCheckDup >
class StateSpaceTreeSearch
{
public:
typedef list<State> Cont;
typedef typename Cont::iterator iterator;
template <class Func>
int operator()(const State& initState, Func afterFindSolution) const
// initState :
初始化状态,类State应提供成员函数nextStep()和isTarget(),
// nextStep()
用vector<State>返回下一步可能的所有状态,
// isTarget()
用于判断当前状态是否符合要求的答案;
// afterFindSolution :
仿函式,在找到一个有效答案后调用之,它接受一个
// const State&
,并返回一个bool值,true表示停止搜索,
// false
表示继续搜索
// return :
找到的答案数量
{
CheckDup<State> checkDup;
Cont states;
SearchInserter<Cont> inserter(states);
states.push_back(initState);
iterator head = states.begin(); //
指向下个搜索的结点
vector<State> nextStates;
int n = 0; //
记录找到的解答数量
bool stop = false;
while (!stop && head != states.end())
{
State s = *head; //
搜索一个结点
nextStates.clear();
s.nextStep(nextStates); //
从搜索点生成下一层结点
for (typename vector<State>::iterator i = nextStates.begin();
i != nextStates.end(); ++i)
{
if (i->isTarget())
{ //
找到一个目标状态
++n;
if (stop = afterFindSolution(*i)) //
处理结果并决定是否停止
{
break;
}
} else { //
不是目标状态,判断是否放入搜索队列中
if (!checkDup(*i)) //
只将不重复的状态放入搜索队列
{
inserter(head, *i);
}
}
}
++head; //
指针移到下一个元素
}
return n;
}
};
我想,代码中的注释已经解释了许多,我只在这里简单的补充说明一下。StateSpaceTreeSearch使用list<State>作为保存状态空间树的容器,不过这个容器并不是StateSpaceTreeSearch的数据成员,而是operator()操作符函数里的局部变量。也就是说,该容器在每次执行搜索时生成,搜索结束后销毁,不会在两次搜索间保留。这样,实例化出一个StateSpaceTreeSearch类就可以多次执行搜索。具体的搜索由operator()操作符函数执行,指定策略的CheckDup和SearchInserter都在其中进行实例化和使用。operator()中的代码按照本文开始时对DFS和BFS的分析进行编写。
以推箱子游戏为例,我们将这样使用新版的DFS/BFS算法:
StateSpaceTreeSearch<SokoState, BFSInserter, OrderCheckDup> sokoSearch;
int n = sokoSearch(initState, printAnswer);
作为对比,我把旧版的代码也贴出来:
OrderCheckDup<SokoState> checkDup;
int n = BreadthFirstSearch(initState, printAnswer, checkDup);
如果你是使用者,你会觉得哪一种用法更方便呢?















 1038
1038

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









