









本文仅仅提供了实现思路,如果对算法速度有追求的请移步python构建关键词共现矩阵速度优化(在此非常感谢这位同学的优化)
非常感谢南京大学的张同学发现我代码中的bug,现文中的代码均已经更新请放心使用,并且代码放弃使用numpy进行矩阵的构建,因此可以对中文进行构建关键词共现矩阵了。同时,有很多同学对我在blog中总是提到的“import自己的代码“的代码感兴趣,现在已将代码git至GITHUB中,需要的同学请自行clone,其中包括了filewalker.py(文件夹遍历)、reader.py(txt、excel文件的读写操作)、buildfile.py(新建文件夹等),具体用法,请参考我的另一篇博文《import自己写的.py》
这篇博文中为了方便矩阵构建和变换,我使用了numpy,但是numpy不支持读取和写入中文字符,仅仅支持英文(或者拉丁文?),因此希望做中文的关键词共现实验的同学,可以使用博文最下方的代码,给大家造成不便,十分抱歉!
中科院的小伙伴Leo Wood已经用pandas实现了共现计算,传送门:Python Pandas 构建共现矩阵
共现分析在数据分析中经常使用到,这里的关键词可以指的是文献中的关键词、作者、作者机构等等。在其他领域中,如电影电视剧也可以用来研究演员共现矩阵等等。在得出共现矩阵后,可以使用UCINET、NETDRAW或者Gephi来进行共现图谱的绘制,达到数据可视化的效果。
首先看看原始数据:
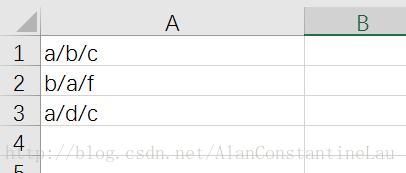
从图中可以看出,a和b共现2次,和c共现2次,其余以此类推。
*下面的代码中,存在import reader,reader是我自己写的.py文件,以方便我每次读取数据。这样就不用每次读取数据的时候都要再写一遍with open了,具体怎么使用请看我另一篇博文python中import自己写的.py
代码如下:
# -*- coding: utf-8 -*-
# @Date : 2017-04-05 09:30:04
# @Author : Alan Lau (rlalan@outlook.com)
import numpy as np
import reader
import time
from pprint import pprint as p
def log(func):
def wrapper(*args, **kwargs):
now_time = str(time.strftime('%Y-%m-%d %X', time.localtime()))
print('------------------------------------------------')
print('%s %s called' % (now_time, func.__name__))
print('Document:%s' % func.__doc__)
print('%s returns:' % func.__name__)
re = func(*args, **kwargs)
p(re)
return re
return wrapper
@log
def get_set_key(data):
'''构建一个关键词集合,用于作为共现矩阵的首行和首列'''
all_key = '/'.join(data)
key_list = all_key.split('/')
set_key_list = list(filter(lambda x: x != '', key_list))
return list(set(set_key_list))
@log
def format_data(data):
'''格式化需要计算的数据,将原始数据格式转换成二维数组'''
formated_data = []
for ech in data:
ech_line = ech.split('/')
formated_data.append(ech_line)
return formated_data
@log
def build_matirx(set_key_list):
'''建立矩阵,矩阵的高度和宽度为关键词集合的长度+1'''
edge = len(set_key_list)+1
# matrix = np.zeros((edge, edge), dtype=str)
matrix = [['' for j in range(edge)] for i in range(edge)]
return matrix
@log
def init_matrix(set_key_list, matrix):
'''初始化矩阵,将关键词集合赋值给第一列和第二列'''
matrix[0][1:] = np.array(set_key_list)
matrix = list(map(list, zip(*matrix)))
matrix[0][1:] = np.array(set_key_list)
return matrix
@log
def count_matrix(matrix, formated_data):
'''计算各个关键词共现次数'''
for row in range(1, len(matrix)):
# 遍历矩阵第一行,跳过下标为0的元素
for col in range(1, len(matrix)):
# 遍历矩阵第一列,跳过下标为0的元素
# 实际上就是为了跳过matrix中下标为[0][0]的元素,因为[0][0]为空,不为关键词
if matrix[0][row] == matrix[col][0]:
# 如果取出的行关键词和取出的列关键词相同,则其对应的共现次数为0,即矩阵对角线为0
matrix[col][row] = str(0)
else:
counter = 0
# 初始化计数器
for ech in formated_data:
# 遍历格式化后的原始数据,让取出的行关键词和取出的列关键词进行组合,
# 再放到每条原始数据中查询
if matrix[0][row] in ech and matrix[col][0] in ech:
counter += 1
else:
continue
matrix[col][row] = str(counter)
return matrix
def main():
keyword_path = r'test.xlsx'
output_path = r'2.txt'
data = reader.readxls_col(keyword_path)[0]
set_key_list = get_set_key(data)
formated_data = format_data(data)
matrix = build_matirx(set_key_list)
matrix = init_matrix(set_key_list, matrix)
result_matrix = count_matrix(matrix, formated_data)
np.savetxt(output_path, result_matrix, fmt=('%s,'*len(matrix))[:-1])
if __name__ == '__main__':
main()
为方便理解,我把每个函数返回的结果打印出来:
------------------------------------------------
2017-04-05 15:30:48 get_set_key called
Document:构建一个关键词集合,用于作为共现矩阵的首行和首列
get_set_key returns:
['f', 'd', 'c', 'a', 'b']
------------------------------------------------
2017-04-05 15:30:48 format_data called
Document:格式化需要计算的数据,将原始数据格式转换成二维数组
format_data returns:
[['a', 'b', 'c'], ['b', 'a', 'f'], ['a', 'd', 'c']]
------------------------------------------------
2017-04-05 15:30:48 build_matirx called
Document:建立矩阵,矩阵的高度和宽度为关键词集合的长度+1
build_matirx returns:
[['' '' '' '' '' '']
['' '' '' '' '' '']
['' '' '' '' '' '']
['' '' '' '' '' '']
['' '' '' '' '' '']
['' '' '' '' '' '']]
------------------------------------------------
2017-04-05 15:30:48 init_matrix called
Document:初始化矩阵,将关键词集合赋值给第一列和第二列
init_matrix returns:
[['' 'f' 'd' 'c' 'a' 'b']
['f' '' '' '' '' '']
['d' '' '' '' '' '']
['c' '' '' '' '' '']
['a' '' '' '' '' '']
['b' '' '' '' '' '']]
------------------------------------------------
2017-04-05 15:30:48 count_matrix called
Document:计算各个关键词共现次数
count_matrix returns:
[['' 'f' 'd' 'c' 'a' 'b']
['f' '0' '0' '0' '1' '1']
['d' '0' '0' '1' '1' '0']
['c' '0' '1' '0' '2' '1']
['a' '1' '1' '2' '0' '2']
['b' '1' '0' '1' '2' '0']]
***Repl Closed***输出的结果为:
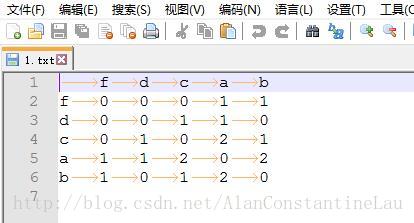
中文关键词的共现矩阵实现:
import os
import xlrd
import re
from pprint import pprint as pt
def readxls(path):
xl = xlrd.open_workbook(path)
sheet = xl.sheets()[0]
data = []
for i in range(0, sheet.ncols):
data.append(list(sheet.col_values(i)))
return (data[0])
def wryer(path, text):
with open(path, 'a', encoding='utf-8') as f:
f.write(text)
return path+' is ok!'
def buildmatrix(x, y):
return [[0 for j in range(y)] for i in range(x)]
def dic(xlspath):
keygroup = readxls(xlspath)
keytxt = '/'.join(keygroup)
keyfir = keytxt.split('/')
keylist = list(set([key for key in keytxt.split('/') if key != '']))
keydic = {}
pos = 0
for i in keylist:
pos = pos+1
keydic[pos] = str(i)
return keydic
def showmatrix(matrix):
matrixtxt = ''
count = 0
for i in range(0, len(matrix)):
for j in range(0, len(matrix)):
matrixtxt = matrixtxt+str(matrix[i][j])+'\t'
matrixtxt = matrixtxt[:-1]+'\n'
count = count+1
print('No.'+str(count)+' had been done!')
return matrixtxt
def inimatrix(matrix, dic, length):
matrix[0][0] = '+'
for i in range(1, length):
matrix[0][i] = dic[i]
for i in range(1, length):
matrix[i][0] = dic[i]
# pt(matrix)
return matrix
def countmatirx(matrix, dic, mlength, keylis):
for i in range(1, mlength):
for j in range(1, mlength):
count = 0
for k in keylis:
ech = str(k).split('/')
# print(ech)
if str(matrix[0][i]) in ech and str(matrix[j][0]) in ech and str(matrix[0][i]) != str(matrix[j][0]):
count = count+1
else:
continue
matrix[i][j] = str(count)
return matrix
def main():
xlspath = r'test.xlsx'
wrypath = r'1.txt'
keylis = (readxls(xlspath))
keydic = dic(xlspath)
length = len(keydic)+1
matrix = buildmatrix(length, length)
print('Matrix had been built successfully!')
matrix = inimatrix(matrix, keydic, length)
print('Col and row had been writen!')
matrix = countmatirx(matrix, keydic, length, keylis)
print('Matrix had been counted successfully!')
matrixtxt = showmatrix(matrix)
# pt(matrix)
print(wryer(wrypath, matrixtxt))
# print(keylis)
if __name__ == '__main__':
main()















 8533
8533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









