









词共现矩阵定义
通过统计一个事先指定大小的窗口内的word共现次数,以word周边的共现词的次数做为当前word的vector。具体来说,我们通过从大量的语料文本中构建一个共现矩阵来定义word representation。
例子
有语料如下:
I like deep learning.
I like NLP.
I enjoy flying.
则其共现矩阵如下:
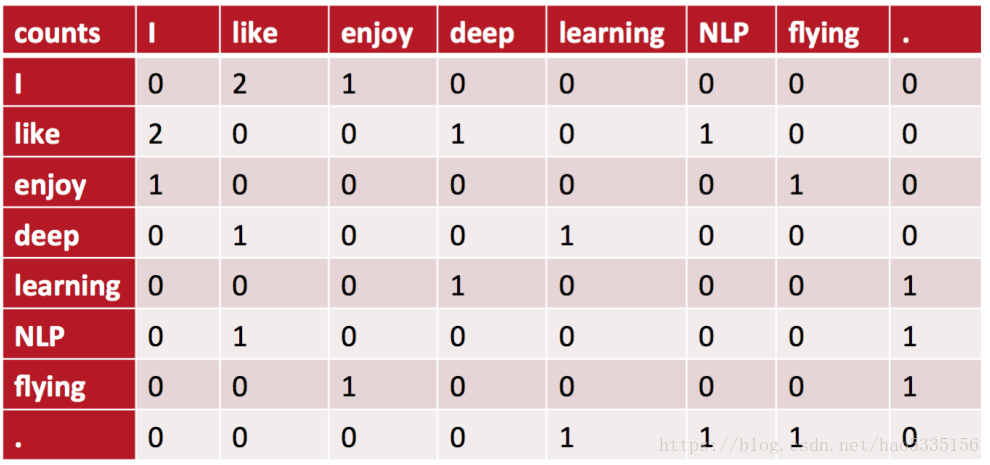
此时选的窗口大小为3,选择在该窗口内词汇的共现频率作为vector。
将共现矩阵行(列)作为词向量表示后,可以知道like,enjoy都是在I附近且统计数目大约相等,他们意思相近。
矩阵定义的词向量在一定程度上缓解了one-hot向量相似度为0的问题,但没有解决数据稀疏性和维度灾难的问题。

















 2566
2566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









