




 本文深入解析C++ STL中的std::lower_bound与std::upper_bound函数,探讨其非对称设计背后的合理性。通过实际例子对比不同实现方式,展示标准库设计的精妙之处。
本文深入解析C++ STL中的std::lower_bound与std::upper_bound函数,探讨其非对称设计背后的合理性。通过实际例子对比不同实现方式,展示标准库设计的精妙之处。
前言
问题是躲不掉的,该来的总会来,这不是代码中又遇到了 std::upper_bound() 函数,再来学习一遍好了,在我的印象中每次看到这 lower_bound 和 upper_bound 两个函数都有些别扭,凡是见到他们必须查一遍,因为我记得它们两个函数的作用不对称,这一点记得很清楚,但是它们两个函数查找的细节却记不住,这次总结一下,强化记忆,下次回忆起来应该会快一点。
函数定义
今天看到这两个函数时挠挠头又打开了搜索引擎,看到文章里写到 std::lower_bound() 是返回大于等于 value 值的位置,而 std::upper_bound() 是返回第一个大于 value 值的位置,第一反应真是瞎写,怎么俩都是大于,肯定应该是一个大于一个小于啊,这样才“合理”嘛!
但是当看到多个文章中采用相同的说法时,刚刚还“坚定”的想法开始动摇,然后开始查C++标准文档,一遍遍读着那有些拗口的文字:
std::lower_bound returns an iterator pointing to the first element in the range [first, last) that is not less than (i.e. greater or equal to) value, or last if no such element is found.
std::upper_bound returns an iterator pointing to the first element in the range [first, last) that is greater than value, or last if no such element is found.
这些标准文档上的文字印证了刚刚查询到的结果,两个函数返回的结果都是迭代器,std::lower_bound() 是在区间内找到第一个大于等于 value 的值的位置并返回,如果没找到就返回 end() 位置。而 std::upper_bound() 是找到第一个大于 value 值的位置并返回,如果找不到同样返回 end() 位置。
两个函数都提到了大于操作,而没有涉及到小于操作,这就是我前面提到的不对称,也是我感觉不合理的地方,但是当尝试使用了几次这两个函数之后,我发现这两个函数的设计的恰到好处,这样的设计很方便我们来做一些具体的操作。
实际例子
首先说明这两个函数内部使用了二分查找,所以必须用在有序的区间上,满足有序的结构中有两个常见的面孔:std::map 和 std::set,他们本身就是有序的,所以提供了 std::map::lower_bound() 和 std::set::lower_bound() 这种类似的成员函数,但是原理都是一样的,我们可以弄明白一个,另外类似的函数就都清楚了。
自己设计
如果你看了这两个函数的具体含义也和我一样不太理解为什么这样设计,可以思考一下接下来这个需求,找出数组内所有值为2和3的元素,图例如下:
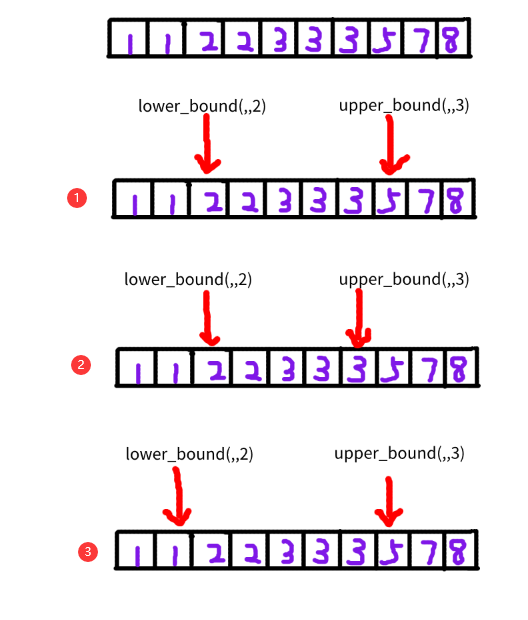
对于一个有序数组,我们在实现 lower_bound() 函数和 upper_bound() 函数时可以让它返回指定的位置来确定取值区间,第①种情况就是标准函数库的实现方式,而第②种和第③种就是我第一印象中感觉应该对称的样子,这样看起来也没什么问题,下面具体来分析下后两种设计有哪些不好的地方。
具体分析
假如我们采用第②种实现方式,那么实现打印元素2和3的代码要写成下面这样:
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main()
{
std::vector<int> v{1,1,2,2,3,3,3,5,7,8};
std::vector<int>::const_iterator itorLower = std::lower_bound(v.begin(), v.end(), 2);
std::vector<int>::const_iterator itorUpper = std::upper_bound(v.begin(), v.end(), 3);
while(true)
{
std::cout << *itorLower << std::endl;
if (itorLower == itorUpper)
break;
++itorLower;
}
return 0;
}
代码看起来还可以,打印完元素后判断到达了结尾直接跳出循环,但是如果要是数组中不包含元素2和3呢,那么也会打印出一个元素,还有可能导致程序崩溃。
如果我们采用第③种实现方式,那么实现打印元素2和3的代码要写成下面这样:
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main()
{
std::vector<int> v{1,1,2,2,3,3,3,5,7,8};
std::vector<int>::const_iterator itorLower = std::lower_bound(v.begin(), v.end(), 2);
std::vector<int>::const_iterator itorUpper = std::upper_bound(v.begin(), v.end(), 3);
for(++itorLower; itorLower != itorUpper; ++itorLower)
{
std::cout << *itorLower << std::endl;
}
return 0;
}
这代码看起来简洁了很多,但是在循环开始前需要先调用 ++itorLower,因为第一个元素并不是需要找到的元素,所以要先跳过它,这样看来确实多做了一步操作,一开始就让 itorLow 指向第一个2就好了呀。
最终版本
当你尝试几种实现方式就会发现,还是标准库提供的这种方式使用起来更加方便,虽然采取的不是对称的方式,但是统一了存在查找元素和不存在查找元素的的情况,写出的代码也比较简洁,没有多余的步骤,代码如下:
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main()
{
std::vector<int> v{1,1,2,2,3,3,3,5,7,8};
auto itorUpper = std::upper_bound(v.begin(), v.end(), 3);
for(auto itorLower = std::lower_bound(v.begin(), v.end(), 2); itorLower != itorUpper; ++itorLower)
{
std::cout << *itorLower << std::endl;
}
return 0;
}
总结
- 有些函数的实现方式和我们想象的并不一样,但是我们可以通过熟练使用来了解它为什么这样设计
- 对称结构虽然是很美的,但是非对称的结构在编程中常常出现,同样有其美丽所在
- 遇到类似的问题可以动笔画一画,列举出各种情况会有利于你做出正确的判断
有时会很焦虑,看到优秀的人比你还努力时总让人感到急迫,但是一味的忧患是无意义的,脚下迈出的每一步才是真真正正的前进,不要去忧虑可能根本就不会发生的事情,那样你会轻松许多


















 395
395







 到【灌水乐园】发言
到【灌水乐园】发言









