






介绍
近期遇到了需要从电子文档中进行内容提取的任务,具体来说就是期望从PDF文件中进行表格抽取,本文主要介绍 tabula-java 和 paddlepaddle 的 pp-structure 两种方案。
思路
本文设定原文件是 pdf 类型的文件,如果是 word 类型的文件,可以使用 documents4j 等技术将 doc/docx 类型的文件转换为 pdf ,最终采用相同的技术方案
对 pdf 进行操作的技术有很多: pdfbox、itext、Spire、Aspose 等等。
通过对比发现: 1、 itext 如果用于商业用途,需要进行授权申请;2、Spire、Aspose都有转换限制,部分收费;3、pdfbox相对宽松,可免费试用,并且有 tabula-java 版本可以进行表格提取;
另一种思路是增加机器学习/深度学习相关的模型,通过前期的技术积累,可采用 paddlepaddle 的 pp-structure 进行表格识别操作。
tabula-java
使用 tabula-java 进行 pdf 的表格提取功能,示例代码如下所示。
通过对比, tabula-java 对标准的表格提取质量最高,如果表格的线不完全(类似 三线表 这种),最终提取效率很低,极端情况下会提取不出来表格数据。
引入 JAR,并进行代码测试。
public void getTableInfo() throws IOException {
InputStream in = new FileInputStream(new File("alexgaoyh-table.pdf"));
try (PDDocument document = PDDocument.load(in)) {
SpreadsheetExtractionAlgorithm sea = new SpreadsheetExtractionAlgorithm();
PageIterator pi = new ObjectExtractor(document).extract();
while (pi.hasNext()) {
Page page = pi.next();
List<Table> tables = sea.extract(page);
// fix 相比于官网的示例,这里多了一步操作,进行了一下去重。
tables = tables.stream().distinct().collect(Collectors.toList());
for (Table table : tables) {
List<List<RectangularTextContainer>> rows = table.getRows();
for (List<RectangularTextContainer> cells : rows) {
for (RectangularTextContainer content : cells) {
System.out.print(content.getText().replace("\r", " ") + "|");
}
System.out.println();
}
}
}
}
}
pp-structure
为了解决 tabula-java 在进行表格提取的不足(类似三线表的情况,提取质量不高),对比使用 pp-structure。
请点击 环境安装
请点击 模型下载
英文文档和中文文档采用不同的模型,具体的命令行命令如下所示
python3 predict_system.py \
--image_dir=/home/alex/paddlepaddle/en_table.pdf \
--det_model_dir=/home/alex/paddlepaddle/PaddleOCR-release-2.6/ppstructure/inference/en_PP-OCRv3_det_infer \
--rec_model_dir=/home/alex/paddlepaddle/PaddleOCR-release-2.6/ppstructure/inference/en_PP-OCRv3_rec_infer \
--rec_char_dict_path=../ppocr/utils/en_dict.txt \
--table_model_dir=/home/alex/paddlepaddle/PaddleOCR-release-2.6/ppstructure/inference/en_ppstructure_mobile_v2.0_SLANet_infer \
--table_char_dict_path=../ppocr/utils/dict/table_structure_dict.txt \
--layout_model_dir=/home/alex/paddlepaddle/PaddleOCR-release-2.6/ppstructure/inference/picodet_lcnet_x1_0_fgd_layout_infer \
--layout_dict_path=../ppocr/utils/dict/layout_dict/layout_publaynet_dict.txt \
--vis_font_path=../doc/fonts/simfang.ttf \
--recovery=True \
--output=/home/alex/paddlepaddle/output/
python3 predict_system.py \
--image_dir=/home/alex/paddlepaddle/ch_table.pdf \
--det_model_dir=/home/alex/paddlepaddle/PaddleOCR-release-2.6/ppstructure/inference/ch_PP-OCRv3_det_infer \
--rec_model_dir=/home/alex/paddlepaddle/PaddleOCR-release-2.6/ppstructure/inference/ch_PP-OCRv3_rec_infer \
--rec_char_dict_path=../ppocr/utils/ppocr_keys_v1.txt \
--table_model_dir=/home/alex/paddlepaddle/PaddleOCR-release-2.6/ppstructure/inference/ch_ppstructure_mobile_v2.0_SLANet_infer \
--table_char_dict_path=../ppocr/utils/dict/table_structure_dict_ch.txt \
--layout_model_dir=/home/alex/paddlepaddle/PaddleOCR-release-2.6/ppstructure/inference/picodet_lcnet_x1_0_layout_infer \
--layout_dict_path=../ppocr/utils/dict/layout_dict/layout_publaynet_dict.txt \
--vis_font_path=../doc/fonts/simfang.ttf \
--recovery=True \
--output=/home/alex/paddlepaddle/output/
英文识别结果对照(首先是版面恢复,其次是表格识别结果): 图片无法正常查看的话, 访问

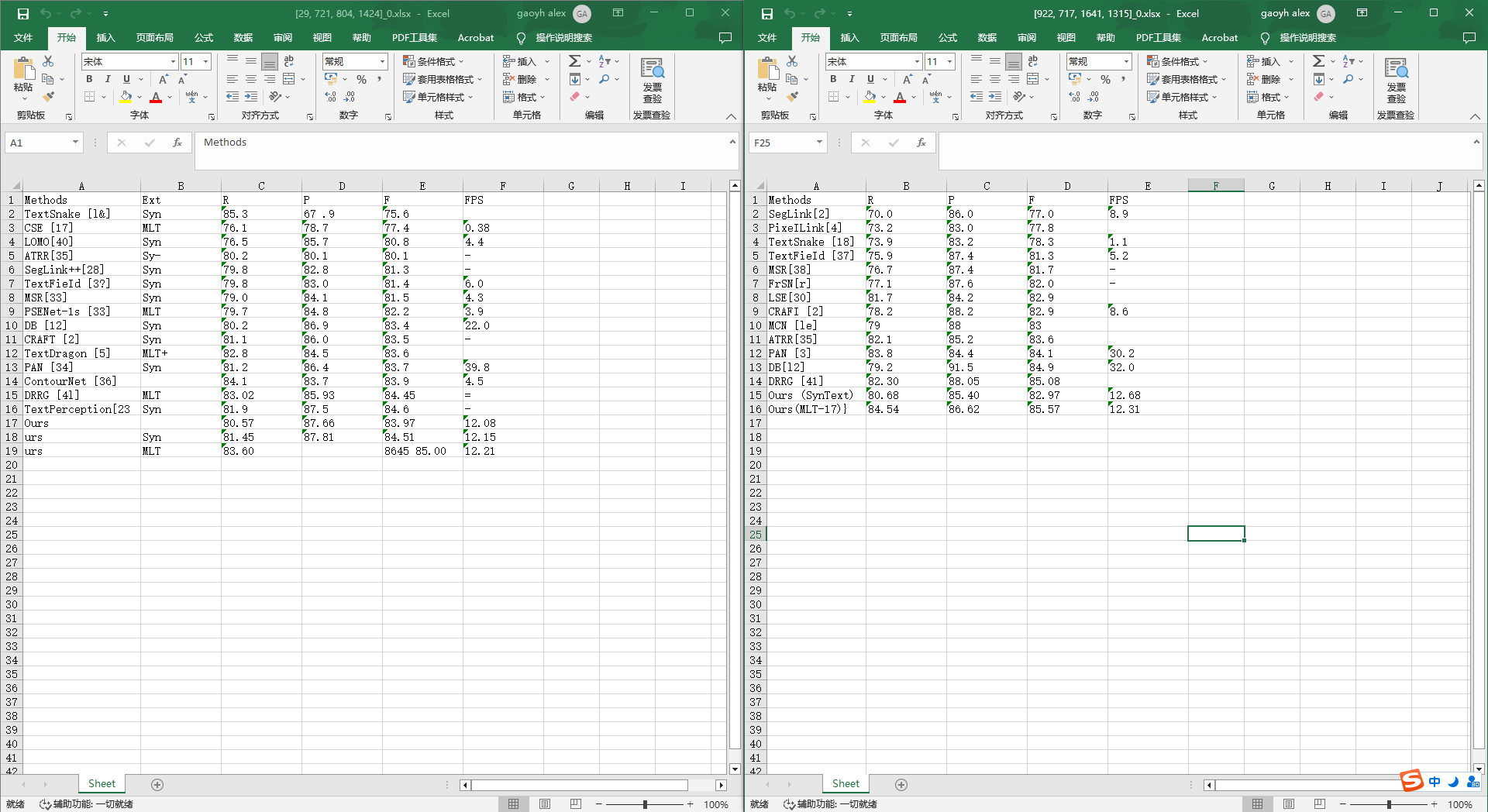
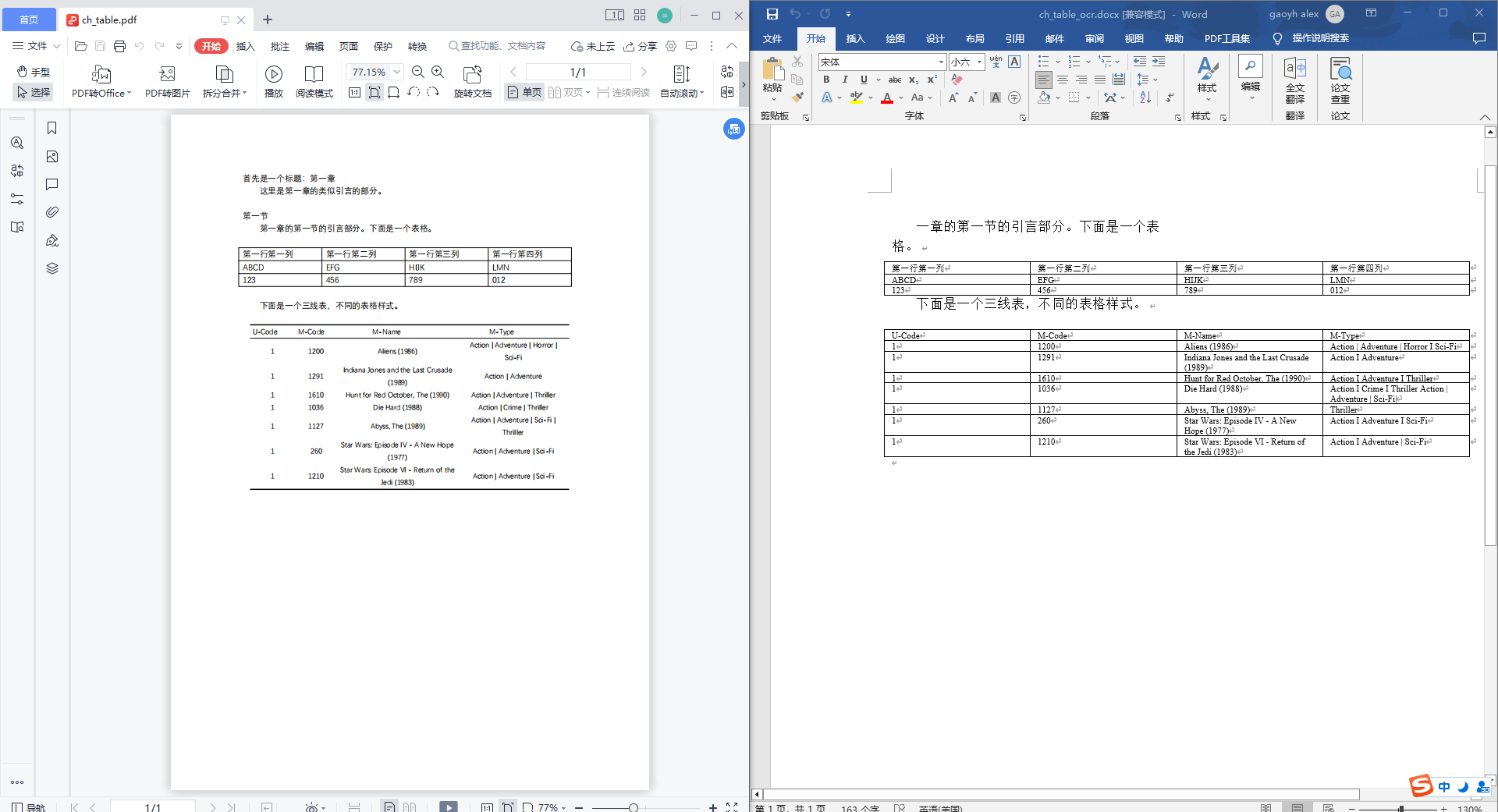
中文识别结果对照(首先是版面恢复,其次是表格识别结果): 图片无法正常查看的话, 访问
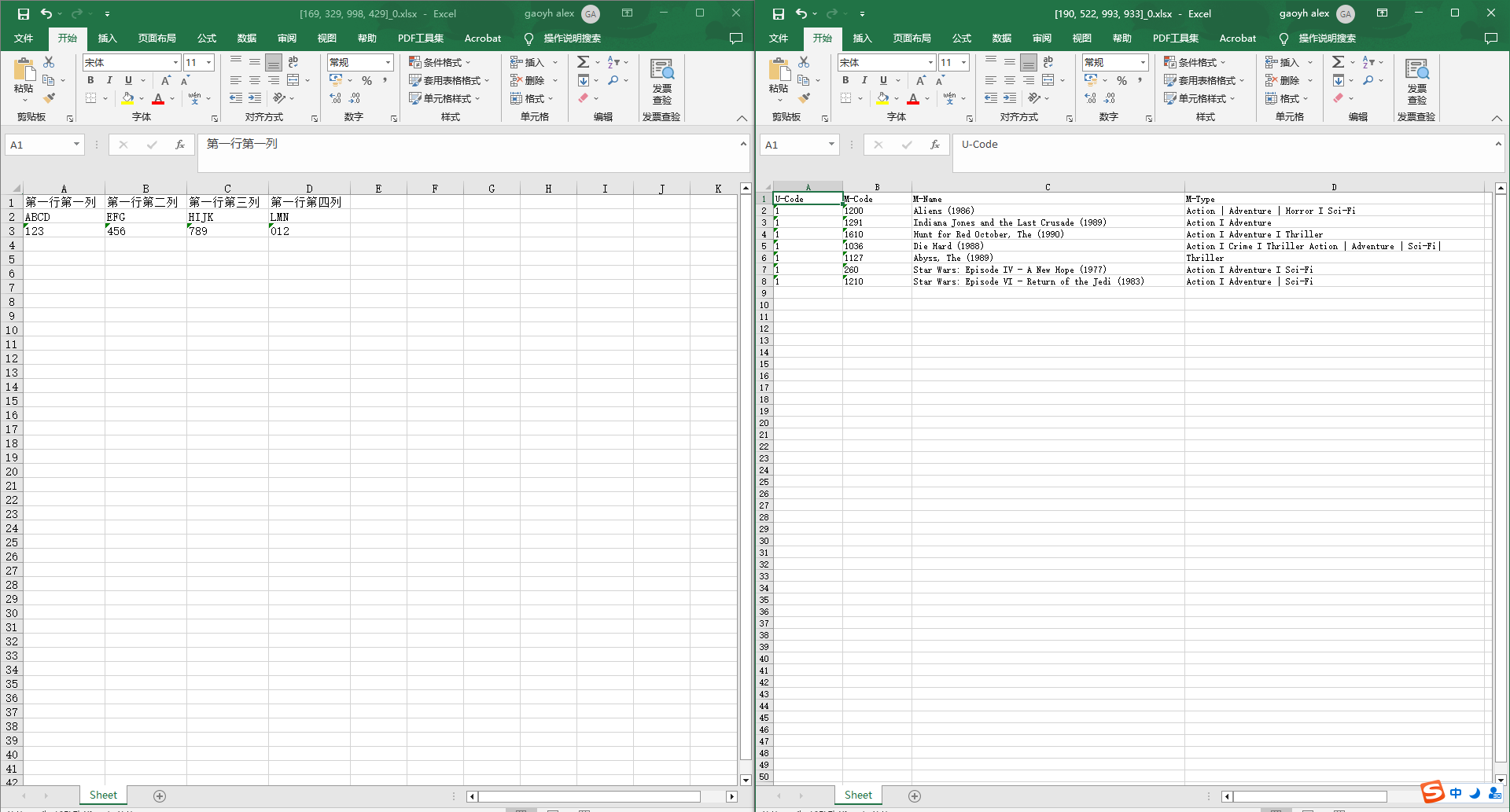
总结
采用 tabula-java 进行 pdf 中表格提取的话,对表格的形式有要求,类似三线表的提取,质量不高。
采用 paddlepaddle 的 pp-structure 进行表格提取的话,可以解决 tabula-java 的不足,产业应用的话需要再包一层外部接口。
参考
- https://aistudio.baidu.com/aistudio/modelsdetail?modelId=18
- https://github.com/tabulapdf/tabula-java
- https://gitee.com/alexgaoyh/pap-base/blob/v1/src/test/java/com/pap/base/util/pdf/TabulaPDFTable.java
- https://gitee.com/alexgaoyh/pap-docs/tree/master/md/other/pp-structure-output/structure/















 3214
3214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









