






作者:知乎—MXie
地址:https://www.zhihu.com/people/xie-ming-chen
本文来自人工智能前沿讲习
作为近来大火的图神经网络领域内的里程碑,GraphSage改变了Spectral-based GCN通过卷积训练每一个节点的embedding来表示该节点的方法,采用了通过对该节点紧邻节点进行sample&aggregate的方式表达该节点。解决了传统GCN无法对新节点预估以及必须对整个网络进行训练的两个问题,本质上实现了从transductive到inductive的进化。
01
算法

算法整体上看上去比GCN那坨负责的傅立叶变换清爽了很多,几乎不需要数学基础,很符合深度学习发展“傻大快强”的趋势。整个算法的思路就是通过一个aggregate方法学习到节点近邻的信息的综合,与自身上一步骤的信息concat变换后得到该节点新的信息。
对于aggregator来讲,由于graph是无序的,因此aggregator需要可以处理无序的输入,这一点和大部分pooling的诉求是相同的。
最简单的aggragator就mean pooling这种,这种方案最大的弊病是aggregator不是trainable的,效果比较一般。
复杂一些的可以使用lstm,但是lstm处理数据是有序的,为了改造成无序,在训练时直接输入random的node近邻,这个该找方案也是够简单粗暴的,我有一点confuse的在于node近邻本身就是random的为何还要random输入。
最后作者提到了一种trainable and symetric的aggregator,node近邻各节点独立输入到网络中后进行elementwise的max-pooling。简单的来说就是mlp外边套了一个max,mlp的作用在于学习到近邻中各个节点的信息,max的作用在于能够学习到近邻节点综合起来的信息,作者提到这个地方用mean和max的效果基本是一致的。
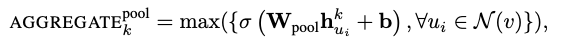
对于minibatch的训练,我们只需要先将所需要的近邻节点(up to depth k)sample出来参与计算,而不需要将图中的全部节点都参与计算,作者提到这里的sample采取的是最简单的uniform fixed-sized方法,在每一步都会重新进行sample。
损失函数采用的是graph-based loss function,看上去和word2vec的那一套还是很像的,通过random walk进行正样本采样,negative sample进行负样本采样。
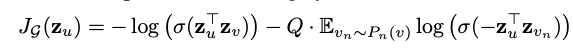
02
对比传统GCN提升的应用场景
对于工业界使用来说,比如在广告这个场景,我们通过用户行为进行组图,ad作为图中的节点,通过图网络pretrain得到每个ad的embedding加入ranking模型或者在召回阶段进行向量召回,线上预估时一定会有很多新广告是不曾出现在训练数据中的,对于传统的GCN模型来讲就只能用一个默认的embedding来表达从而大大的削弱了信息量。但是对于GraphSage来讲,我们可以通过与新ad有关联的附近ad的embedding来推算出该ad的embedding。
还有一种情况是cross graph,即在一个graph上训练embedding,但是在另外一个graph去实际应用生成embedding。
整体看下来,GraphSage的结构不是很复杂,并且很适合于工业界使用,即可以端到端的学习item embedding做向量检索,也可以对大规模数据pretrain获得item embedding concate到主模型中做二阶段训练。我个人更倾向于将这种建模思想融入到主模型中做end2end的训练,也许会有些出人意料的收获。
本文目的在于学术交流,并不代表本公众号赞同其观点或对其内容真实性负责,版权归原作者所有,如有侵权请告知删除。


















 1481
1481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









