







算法思想
作者提出一种信息传递框架:节点的(结构和特征)信息在点与点之间传递。通过聚合函数,一个节点能够聚合邻居的信息,并通过更新函数(神经网络)更新当前节点的信息,这就是一次迭代的信息传递过程。随着迭代次数的增加,一个节点就能够聚合到更高阶邻居的信息。
算法流程
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PXDFUuCS-1666418812064)(E:\论文笔记\GraphSAGEInductive Representation Learning on Large Graphs(大型图的归纳表示学习)].assets\image-20221022102301421.png)](https://img-blog.csdnimg.cn/c675b368c750472bb2c81d9b41157a63.png)
算法分为三个部分:
1)对节点进行采样;
2)对节点的邻居进行聚合;
3)根据聚合的信息,学习节点的表示
嵌入生成(前向传播)算法
嵌入生成算法(向前传播算法):假设所有需要用到的节点已经完成采样,并且聚合函数已经被训练好了,就可以用该算法生成任一节点的嵌入表示。
首先,将每个节点的紧邻节点的表征汇总为一个单一的向量 h N v k h^{k}_ {Nv} hNvk,当k=1是,输入的为节点特征X
然后,GraphSAGE将节点的当前表征
h
v
k
−
1
h^{k-1}_ {v}
hvk−1与聚合的相邻向量
h
N
v
k
h^{k}_ {Nv}
hNvk连接起来||,这个连接的向量通过一个具有非线性激活函数σ的全连接层,该层将表征转换为算法的下一步使用(即hkv, ∀v∈V)。
最后,我们把深度为K的最终表征输出表示为 z v ≡ h v K z_v≡h^K_v zv≡hvK ,∀v∈V。
算法1:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-byfjZGe7-1666418812065)(E:\论文笔记\GraphSAGEInductive Representation Learning on Large Graphs(大型图的归纳表示学习)].assets\image-20221022130506347.png)](https://img-blog.csdnimg.cn/b14591d6c5ee42268b401a35836a76e4.png)
采样算法(minibatch)
采样过程与算法1中迭代k次的过程在概念上是相反的,给定一个输入节点的集合,相当于 B k B^k Bk层节点,也就是我们最终想要生成表示的节点,采样它们的邻居节点(一阶邻居),对于一阶邻居,采样他们的邻居(二阶邻居),直到K阶邻居采样完成。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JX4OsbXl-1666418812065)(E:\论文笔记\GraphSAGEInductive Representation Learning on Large Graphs(大型图的归纳表示学习)].assets\image-20221022132033975.png)](https://img-blog.csdnimg.cn/b175b24fc31049b7ac17e45d9dabec63.png)
特别是,如果我们使用K = 2次总迭代,样本大小为S1和S2,那么这意味着我们在算法1的迭代K = 1期间对S1节点进行采样,在迭代K = 2期间对S2节点进行采样,从B中的“目标”节点(我们希望在迭代K = 2后生成表示)的角度来看,这相当于对它们的近邻采样S2,对它们的2跳邻居采样S1·S2。
算法2:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uQvjvRtA-1666418812066)(E:\论文笔记\GraphSAGEInductive Representation Learning on Large Graphs(大型图的归纳表示学习)].assets\image-20221022130232576.png)](https://img-blog.csdnimg.cn/2690fdcc07e74f7ab7df9f0564624f23.png)
学习GraphSAGE的参数
在GraphSAGE中,要学习的参数有两个:
1、权重矩阵 W k W_k Wk;
2、聚合函数的参数
对于完全无监督的情况下学习有用的预测性表征,对于输出表征Z应用基于图的损失函数
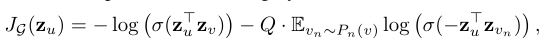
并且通过随机梯度下降调整权重矩阵和聚合函数的参数
对于监督学习,针对特定任务而选择不同的损失函数,例如交叉熵损失函数
聚合函数的选择
由于一个节点的邻居没有自然的排序;因此,算法1中的聚合器函数必须在无序的向量集上运行。理想情况下,一个聚合函数应该是对称的(即,对其输入的排列组合不变),同时仍然是可训练的,并保持高的表示能力。
聚合函数的对称性确保我们的神经网络模型可以被训练并应用于任意有序的节点邻域特征集。我们研究了三个候选聚合函数。
三种聚合函数架构:
1、Mean aggregator(平均值聚合器)
Mean 聚合近似等价 GCN 中的卷积传播操作。具体来说就是对中心节点的邻居节点的特征向量求均值,然后和中心节点特征向量拼接,中间有两次非线性变换。
2、GCN的归纳式学习版本
特别的,我们可以通过将算法1中的第4行和第5行替换为以下内容,推导出GCN方法的归纳变体:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-X3o77FOA-1666418812066)(E:\论文笔记\GraphSAGEInductive Representation Learning on Large Graphs(大型图的归纳表示学习)].assets\image-20221021193719618.png)](https://img-blog.csdnimg.cn/e7803cd9c90043c0945c6c9a9477697d.png)
3、LSTM aggregator
第二个是将中心节点的邻居节点随机打乱作为输入序列,将所得向量表示与中心节点的向量表示分别经过非线性变换后拼接,得到中心节点在该层的向量表示。LSTM 本身用于序列数据,而邻居节点没有明显的序列关系,因此输入到 LSTM 中的邻居节点需要随机打乱顺序
4、LSTM aggregator
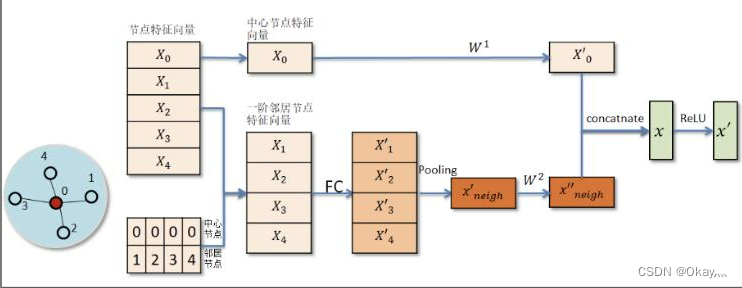
先对中心节点的邻居节点表示向量进行一次非线性变换,然后对变换后的邻居表示向量进行池化操作(mean pooling 或者 max pooling),最后将 pooling 所得结果与中心节点的特征表示分别进行非线性变换,并将所得结果进行拼接或者相加从而得到中心节点在该层的向量表示。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-egZmFfzt-1666418812066)(E:\论文笔记\GraphSAGEInductive Representation Learning on Large Graphs(大型图的归纳表示学习)].assets\image-20221021195302175.png)](https://img-blog.csdnimg.cn/ee69be13f3f74b0193a935a52a9926f9.png)
图示理解:
总结
适用场景
1、 通过对节点邻居的信息进行聚合,学习节点的表示
2、可以加上节点的属性特征,也可以不加
3、可以用于有监督学习,也可以是无监督学习(无监督模型用交叉熵做目标函数)
4、同构网络
不足和改进
1、不能对边的信息进行建模,不同的权重或者不同的关系都不能作为有效的信息被学习。
2、为了捕捉节点和节点间不同的权重,GAT提出了注意力模型
3、为了捕捉异质网络中边的关系HAN提出了基于注意力机制的异质图神经网络模型
参考博客:
https://blog.csdn.net/weixin_47879720/article/details/110953812
https://blog.csdn.net/duan_zhihua/article/details/113812642

















 1819
1819











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











