









一、GCN 图卷积神经网络:
Semi-Supervised Classification with Graph Convolutional Networks
基于频谱域的图卷积神经网络,原理是通过独立于节点embedding的图拓扑结构定义用于聚集(过滤)邻居节点的权值。
:本质仍是聚合邻居节点的信息,只不过可以通过数学变换得到如下的式子统一表示聚合邻居信息的过程。

这样可能提高了速度但固定了GCN的聚合邻居信息的方式,导致了直推式学习的弊端。
1、GCN的本质确实是利用全图进行节点的特征学习(参考:GCN(2017ICLR论文)说明)
2、在面对新的节点时确实需要重新训练
参考:GCN入门
而传统的基于空间域的GCN遵从如下的计算规则:
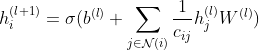
二、GAT 图注意力神经网络(从空域出发,加入了attention):
在GAT中,由于注意力机制,权值是节点embedding的函数。对图节点的分类结果表明,GAT的自适应能力使得融合节点特征和图拓扑结构的信息更加有效。
三、GraphSage 基于空域的图卷积神经网络(第一篇):
经典的应该也是目前最常见的基于空间域的图卷积神经网络,不同于GCN,GraphSAGE从两个方面对传统的GCN做了改进,
- 一是在训练时的,采样方式将GCN的全图采样优化到部分以节点为中心的邻居抽样,这使得大规模图数据的分布式训练成为可能,并且使得网络可以学习没有见过的节点,这也使得GraphSAGE可以做归纳学习(Inductive Learning)。
- 第二点是GraphSAGE研究了若干种邻居聚合的方式,并通过实验和理论分析对比了不同聚合方式的优缺点。
- 有了这样的一个公式:
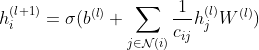
对于新的节点,可以利用上述规则计算得到它的特征表示而不需要像频域GCN一样重新计算一遍。
从而解决了从transductive到inductive的转换:

GraphSage 本质上实现了从transductive到inductive的进化
GraphSage本质的理解
核心算法:
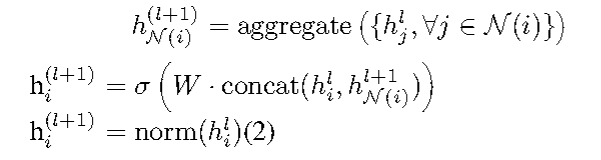
参考:
图神经网络GraphSage:远亲不如近邻
GraphSAGE详解
四、动态图上的GCN??
总结
1、频域GCN、空域GCN以及与GraphSage的区别
不论是基于频域的GCN还是基于空间域的GCN,本质都是实现聚合邻居信息得到节点的特征表示,频域GCN通过数学上的频谱卷积变换了其聚合的过程,其规则是考虑自身节点并进行度归一化地聚合邻居信息:

而基于空间域的GCN通过循环(数学不好我就暴力)更新节点特征的方式,实现了同样的目标,二者在本质上没有区别。
这样处理可以说实现了用全图的信息来获得节点的表示,但同时也引来了新的问题:每当有新的节点到来时,哪怕只引入一个新的节点,相应的 A ^ , D ^ − 1 / 2 \hat{A},\hat{D}^{-1/2} A^,D^−1/2都会发生变化,因此我们需要完全重复这样的计算。
GraphSage的引入旨在解决这个问题,通过学习一个聚合函数,从而避免重复计算图的结构信息。但其本质个人理解就是空间域的GCN+新的聚合函数+新的邻居节点抽样方法(抽样算法解决了新节点学习的问题)。
对于新的节点,可以利用上述规则计算得到它的特征表示而不需要像频域GCN一样重新计算一遍。
2、GCN如何聚合全局信息?
单次GCN(泛指,包括GCN、GraphSage等)迭代是聚合静态的邻居信息,即若是第一次迭代,只根据一跳邻居的当前信息得到节点的表示,并不会聚合全局信息。
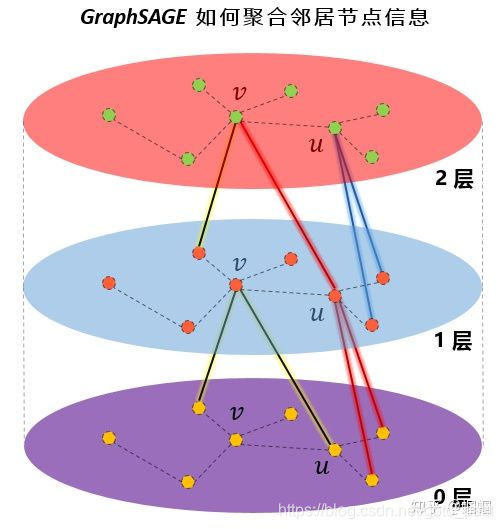
随着多次迭代,单个节点才逐渐聚合2条邻居(已经足够)、3跳邻居直至全部节点的信息。
3、 未来方向 (2019年初提出)
加深网络 深度学习的成功在于深度神经架构。例如在图像分类中,模型 ResNet 具有 152 层。但在图网络中,实证研究表明,随着网络层数增加,模型性能急剧下降 [147]。根据论文 [147],这是由于图卷积的影响,因为它本质上推动相邻节点的表示更加接近彼此,所以理论上,通过无限次卷积,所有节点的表示将收敛到一个点。这导致了一个问题:加深网络是否仍然是学习图结构数据的好策略?
感受野节点的感受野是指一组节点,包括中心节点和其近邻节点。节点的近邻(节点)数量遵循幂律分布。有些节点可能只有一个近邻,而有些节点却有数千个近邻。尽管采用了采样策略 [24], [26], [27],但如何选择节点的代表性感受野仍然有待探索。
可扩展性大部分图神经网络并不能很好地扩展到大型图上。主要原因是当堆叠一个图卷积的多层时,节点的最终状态涉及其大量近邻节点的隐藏状态,导致反向传播变得非常复杂。虽然有些方法试图通过快速采样和子图训练来提升模型效率 [24], [27],但它们仍无法扩展到大型图的深度架构上。
动态性和异质性大多数当前的图神经网络都处理静态同质图。一方面,假设图架构是固定的。另一方面,假设图的节点和边来自同一个来源。然而,这两个假设在很多情况下是不现实的。在社交网络中,一个新人可能会随时加入,而之前就存在的人也可能退出该社交网络。在推荐系统中,产品可能具有不同的类型,而其输出形式也可能不同,也许是文本,也许是图像。因此,应当开发新方法来处理动态和异质图结构。















 894
894











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









