







哎呀,要秋招了啊~
不禁感叹:How time flys~
重新出发~
后期我发现还是需要把相关文章的链接放上来的,方便大家深入理解记忆,如果你没时间就直接看文字,如果有时间记得把链接点开看看哦~都是大佬的精华~
一切为了暑期实习!!!
一切为了暑期实习!!!
一切为了暑期实习!!!
机器学习
SVM(重点)
这个文章讲的不错哟,很详细,考点也很全面!!
https://blog.csdn.net/b285795298/article/details/81977271
1. SVM原理和推导
- 原理:SVM试图寻找一个超平面使正负样本分开,并使得几何间隔最大。
⚠️(注意分清以下这三种情况)
当训练样本线性可分时,通过硬间隔最大化,学习一个线性分类器,即线性可分SVM
当训练样本近似线性可分时,引入松弛变量,通过软间隔最大化,学习一个线性分类器,即线性SVM
当训练样本线性不可分时,通过核技巧和软间隔最大化,学习一个非线性分类器,即非线性SVM
- 硬间隔SVM推导(十分重要)我自己写的,字很随意啦~

- 软间隔SVM推导
https://blog.csdn.net/Dominic_S/article/details/83002153
2. SVM为什么可以用对偶问题求解?对偶问题的解和原始问题的解的关系?这样求解的好处是?
- 首先SVM求解问题是一个凸二次规划问题(基本目标是二次函数,约束条件是线性的这种优化问题被称为凸二次优化问题),应用对偶问题求解更高效。
- 其次在满足KKT条件下,对偶问题和原始问题的解是完全等价的。
- 优点:
- 对偶问题将原始问题中的约束转为了对偶问题中的等式约束;
- 方便核函数的引入;
- 改变了问题的复杂度。由求特征向量w转化为求比例系数a,在原始问题下,求解的复杂度与样本的维度有关,即w的维度。在对偶问题下,只与样本数量有关;
- 求解更高效,因为只用求解alpha系数,而alpha系数只有支持向量才非0,其它全部为0。
3. 为什么要选择最大间隔分类器?
- 从数学上考虑:
误分类次数和几何间隔之间存在下列关系,几何间隔越大,误分类次数越少。
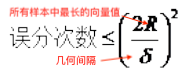
- 感知机利用误分类最小策略,求得分离超平面,不过此时解有无数个;而线性可分SVM利用间隔最大求得最优分离超平面,求得唯一解,而且此时的模型鲁棒性好,对未知样本泛化能力最强。
4. 样本失衡会对SVM的结果产生影响吗?如何解决SVM样本失衡问题?样本比例失衡时,使用什么指标评价分类器的好坏?
- 样本失衡会对结果产生影响,分类超平面会靠近样本少的类别。原因:因为使用软间隔最大化,假设对所有类别使用相同的惩罚因子,而优化目标是最小化惩罚量,所以靠近样本少的类别惩罚量少。
- 解决SVM样本失衡问题方法:
- 对不同的类别赋予不同的惩罚因子(C),训练样本越少,C越大。缺点:偏离原始样本的概率分布。
- 对样本的少的类别,基于某种策略进行采样。
- 基于核函数解决问题。
- 当样本比例不均衡时,使用ROC曲线。
5. SVM如何解决多分类问题
https://www.cnblogs.com/CheeseZH/p/5265959.html
- 直接法:直接修改目标函数,将多个分类面的参数求解合并到一个目标函数上,一次性进行求解。
- 间接法:
- One VS One:任意两个样本之间训练一个分类模型,假设有k类,则需要k(k-1)/2个模型。对未知样本进行分类时,得票最多的类别即为未知样本的类别。libsvm使用这个方法。
- One VS Rest:训练时依次将某类化为类,将其他所有类别划分为另外一类,共需要训练k个模型。训练时具有最大分类函数值的类别是未知样本的类别。
6. SVM适合处理什么样的数据?
高维、稀疏、样本少的数据。
7. SVM为什么对缺失数据敏感?(数据缺失某些特征)
- SVM没有缺失值的处理策略;
- SVM希望样本在特征空间中线性可分,特征空间的好坏影响SVM性能;
- 缺失特征数据影响训练结果。
8. sklearn.svm参数
- 栗子:
class sklearn.svm.SVC(
C=1.0,
kernel='rbf',
degree=3,
gamma='auto',
coef0=0.0,
shrinking=True,
probability=False,
tol=0.001,
cache_size=200,
class_weight=None,
verbose=False,
max_iter=-1,
decision_function_shape='ovr',
random_state=None
)
- 重要参数:(理解含义和对模型的影响)
-
C : float, optional (default=1.0)误差项的惩罚参数,一般取值为10的n次幂,如10的-5次幂,10的-4次幂…10的0次幂,10,1000,1000,在python中可以使用pow(10,n) n=-5~inf
C越大,相当于惩罚松弛变量,希望松弛变量接近0,即对误分类的惩罚增大,趋向于对训练集全分对的情况,这样会出现训练集测试时准确率很高,但泛化能力弱。
C值小,对误分类的惩罚减小,容错能力增强,泛化能力较强。 -
kernel : string, optional (default=’rbf’)
svc中指定的kernel类型。
可以是: ‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’ 或者自己指定。 默认使用‘rbf’ 。 -
degree : int, optional (default=3)
当指定kernel为 ‘poly’时,表示选择的多项式的最高次数,默认为三次多项式。
若指定kernel不是‘poly’,则忽略,即该参数只对‘poly’有作用。 -
gamma : float, optional (default=’auto’)
当kernel为‘rbf’, ‘poly’或‘sigmoid’时的kernel系数。
如果不设置,默认为 ‘auto’ ,此时,kernel系数设置为:1/n_features -
coef0 : float, optional (default=0.0)
kernel函数的常数项。
只有在 kernel为‘poly’或‘sigmoid’时有效,默认为0。
-
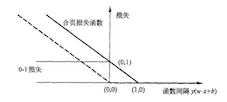
9. SVM的损失函数—Hinge Loss(合页损失函数)
https://www.jianshu.com/p/fe14cd066077
- hinge loss图像
- 表达式
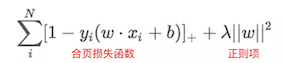
10. SMO算法实现SVM(思想、步骤、常见问题)(我这个还不熟悉,mark)
- 思想:将大的优化问题分解为多个小的优化问题,求解小的优化问题往往更简单,同时顺序求解小问题得出的结果和将他们作为整体求得的结果一致。
- 步骤:1. 选取一对需要更新的变量ai和aj(阿尔法)2. 固定除ai和aj以外的所有变量,求解对偶问题获得更新ai、aj、b。
- 常见问题—如何选取ai和aj和b?
- 选取违反KKT条件最严重的ai,在针对这个ai选择最有可能获得较大修正步长的aj;
- b一般选取支持向量求解的平均值。
11. SVM如何解决非线性问题?你所知道的核函数?
- 当样本在原始空间线性不可分时,可将样本从原始空间映射到一个更高维的特征空间,使得样本在这个特征空间内线性可分。
- 常用核函数(重点sigmoid、RBF(名字一定要记住啦:高斯径向基核函数)、要会写核函数的公式哦~)

12. 线性核与RBF核的区别?
- 训练速度:线性核只有惩罚因子一个参数,训练速度快,RBF还需要调节gamma;
- 训练结果:线性核得到的权重w能反映出特征的重要性,由此进行特征选择,RBF无法解释;
- 训练数据:线性核适合样本特征>>样本数量的,RBF核相反。(揭示了如何选择核函数)
13. SVM和LR的联系和区别
- 联系:
- 都是判别式模型
- 都是有监督的分类算法
- 如果不考虑核函数,都是线性分类算法
- 区别:
- LR可以输出概率,SVM不可以
- 损失函数不同,即分类机制不同
- SVM通过引入核函数解决非线性问题,LR则主要靠特征构造,必须组合交叉特征,特征离散化;
原因:LR里每个样本点都要参与核计算,计算复杂度太高,故LR通常不用核函数。
- SVM计算复杂,效果比LR好,适用于小数据集;LR计算快,适用于大数据集,用于在线学习
- SVM分类只与分类超平面附近的点有关,LR与所有点都有关系
- SVM是结构风险最小化,LR则是经验风险最小化
结构风险最小化就是在训练误差和模型复杂度之间寻求平衡,防止过拟合,减小泛化误差。为了达到结构风险最小化的目的,最常用的方法就是添加正则项。
14. SVM如何防止过拟合?
https://www.jianshu.com/p/9b03cac58966
通过引入松弛变量,松弛变量可以容忍异常点的存在。
15. KKT(Karysh-Kuhn-Tucker)条件有哪些,完整描述?

对应到线性可分SVM分类上其KKT条件为:

对于以上的KKT条件可以看出,对于任意的训练样本总有ai=0或者yif(xi) - 1=0即yif(xi) = 1
1)当ai=0时,代入最终的模型可得:f(x)=b,即所有的样本对模型没有贡献;
2)当ai>=0,则必有yif(xi) = 1,注意这个表达式,代表的是所对应的样本刚好位于最大间隔边界上,是一个支持向量,这就引出一个SVM的重要性质:训练完成后,大部分的训练样本都不需要保留,最终的模型仅与支持向量有关。
集成学习(重点)
1. 决策树和随机森林的区别
决策树 + Bagging + 随机选择特征 = 随机森林,随机森林可以有效防止过拟合。
2. 随机森林里面用的哪种决策树
CART 决策树或其他
3. 随机森林的原理?如何进行调参?树的深度一般如何确定,一般为多少?
- 原理:RF是一种集成算法,属于bagging类,它通过集成多个决策树模型,通过对基模型的结果采用投票法或者取平均来获得最终结果,使得最终模型有较高的准确度和泛化性能。
- 调参:
还是看刘建平老师的这篇:https://www.cnblogs.com/pinard/p/6160412.html
RF和GBDT调参过程类似,可以对比记忆:
无参数拟合–>n_estimators调参–>max_depth, min_sample_split–>min_sample_split, min_samples_leaf–>max_features
- 如何确定树的深度:当训练样本多,数据特征维度多的时候需要限制这个参数,具体取决于数据分布,一般在10-100之间。
3. Bagging 和 Boosting的区别
- 样本选择:Bagging有放回的选取训练集,并且从原始数据集中选取的各轮训练集之间相互独立;Boosting每次都使用全部数据,只是每个样例的权重不同。
- 样例权重:Bagging采用均匀采样,每个样例的权重相同&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 638
638











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









