



一句话总结:
针对单一归因机制的局限性,阿里妈妈展示广告首次提出CVR预估的多归因学习范式MAL(Multi-Attribution Learning),通过对First-Click、Linear、MTA等多维度归因标签联合建模,完成从单一目标拟合到多元价值学习的建模范式升级。
▐ 摘要
在广告系统中,系统会通过归因机制将转化结果(例如成交)归因到用户转化旅程中的各个触点上,以此评估广告投放效果并进行优化。虽然业界已提出多种归因机制(如 First-click,Last-click,Linear,MTA,etc),但考虑到实践上的简便性,目前主流广告系统中都只面向一种特定的目标归因机制进行优化(通常是 Last-Click 口径归因)。
具体来说,广告系统会基于目标归因机制产出转化 label,用于训练转化率预估模型,并将模型输出的预估值应用于广告出价及拍卖机制。
我们称这种依赖单一归因机制训练模型的范式为 SAL(Single-Attribution Learning)。虽然 SAL 范式能够保证在目标归因机制下的值准度,但是单一归因机制训练的模型无法刻画用户从产生兴趣到完成转化的意图演变,在序准度如 AUC 指标上表现较差。
为了克服单一归因瓶颈、更全面精准地刻画用户转化心智,阿里妈妈首次提出同时学习多种归因口径所产标签的多归因学习范式 MAL(Multi-Attribution Learning),实现了从拟合单一口径目标到学习多元流量价值的建模范式迁移。
考虑到 CVR 模型需要交付目标归因口径的预估值,我们将 MAL 的总体优化目标定义为:
多归因学习:利用多种归因机制提供的丰富标签作为辅助目标,最大化目标归因机制下的预估准度。
为此,我们设计了由 归因知识聚合模块 AKA 与 主目标预估头 PTP 组合成的模型架构。该架构首先由 AKA 从各归因机制产出的 CVR 标签上抽取刻画用户转化行为模式的表征,随后将抽取的表征应用于目标归因口径的预估。为了进一步丰富监督信号,我们设计了 笛卡尔积辅助训练任务 CAT,显式地建模不同归因视角下的高阶交互关系。
通过这些技术创新,我们在展示广告精排 CVR 模型上取得 离线 GAUC +0.5%、线上预算 A/B 实验 ROI +2.6% 的显著增益。尤其在用户决策路径长、转化心智较复杂的行业如大家电、珠宝中效果更显著。
MAL 建模范式适用于所有的转化预估模型,为业界 CVR 预估提供了一条新的技术路线。
论文:See Beyond a Single View: Multi-Attribution Learning Leads to Better Conversion Rate Prediction
作者:Sishuo Chen*, Zhangming Chan*, Xiang-Rong Sheng, Lei Zhang, Sheng Chen, Chenghuan Hou, Han Zhu, Jian Xu, Bo Zheng (*Equal Contribution)
链接(点击↓阅读原文↓):
https://arxiv.org/pdf/2508.15217
一、背景:转化率预估模型的单一归因瓶颈
转化率(CVR)预估模型建模用户点击后发生转化行为的概率,对系统的流量分配效率与用户体验发挥至关重要的作用。CVR建模的一个根本挑战在于其标签定义的模糊性——由于用户决策路径上存在多个触点,转化行为必须通过“归因机制”进行分配,才能最终确定正负样本。
精准的归因机制是评估触点贡献、优化广告投放,进而最大化预算效率的基石。这种对精准归因的追求,推动了计算广告界发展多种归因方法。常见的归因机制可分为以下几类:
末次点击归因 (Last-Click Attribution):注重收割价值,将转化归功于转化行为发生前的最后一次相关点击,转化路径上其余的相关点击均为负样本。
首次点击归因 (First-Click Attribution):注重种草价值,将转化归功于归因周期内的首次相关点击,转化路径上其余的相关点击均为负样本。
线性归因 (Linear Attribution):将转化功劳平分给转化路径上的各次相关点击。
数据驱动的多触点归因 (Data-Driven Multi-Touch Attribution, MTA):利用数据驱动的因果推断模型进行转化功劳分配,如阿里的CausalMTA[1] 和LinkedIn的LiDDA[2]
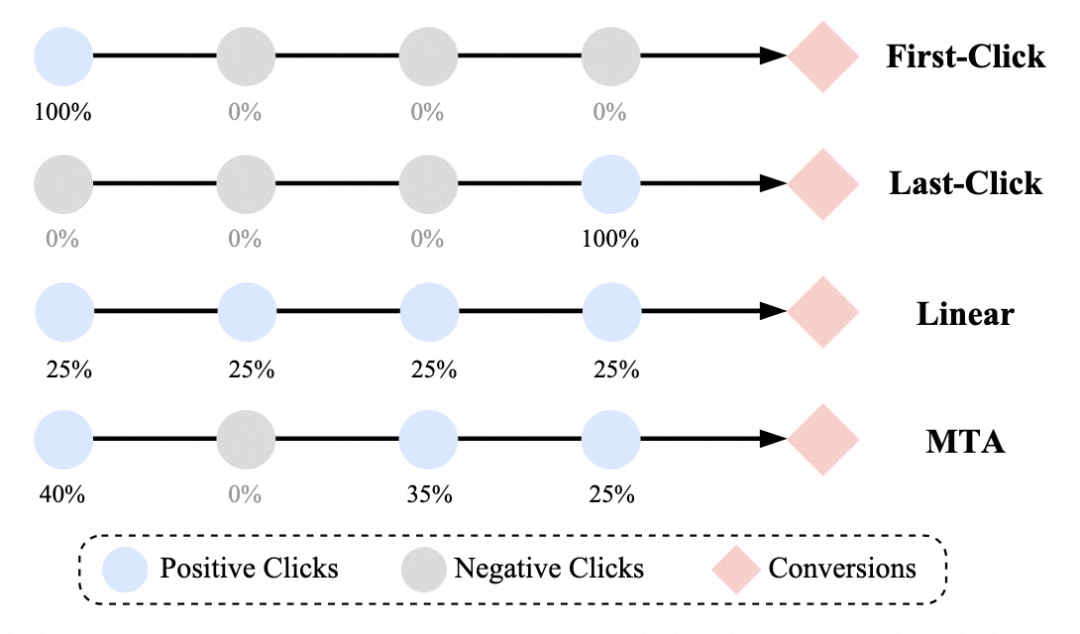
图1 不同转化归因逻辑示意图
尽管业界已发展出多元的归因机制,但现有CVR预估模型的实践中存在一个显著的局限:其训练目标仅为拟合单一归因机制产出的标签。我们称之为 “单一归因瓶颈”,它从根本上限制了模型对各触点综合价值的全面感知。该瓶颈的危害在于,无论选择何种单一归因,都会导致信息损失与认知偏差,例如:
若仅拟合末次点击归因,模型将过度关注“收割”价值,而将关键的“种草”触点错误地等同于无任何转化关联的“真负样本”,造成了触点价值衡量的偏差。
若仅拟合MTA模型给出的归因权重,则模型不仅会受限于MTA自身的预测误差累积,也无法利用首次、末次点击等明确的位置信息,其认知同样是不完整的。
为此,我们首次提出多归因学习范式 MAL,该范式下CVR模型通过拟合多种归因机制所产标签形成的多元目标,缓解单一归因瓶颈所导致的转化心智刻画偏差,从而提升预估性能。下一章将对MAL范式及其实践方案进行全面阐述。
二、方案:多归因学习范式 MAL
2.1 优化目标与总体框架
优化目标:最大化目标归因机制下的预估准度
在线广告平台通常为广告主提供多种归因口径下的效果报表,然而,参与广告排序分计算的CVR预估模型则需交付特定的目标归因机制下的转化概率预估值。我们称目标归因机制产出的转化标签为生产口径主目标,而其他归因机制提供的标签则被视为辅助目标。多归因学习(MAL)范式的优化目标在于充分利用这些辅助目标信息,以最大化目标归因机制下的预估准度,从而提高流量分配效率,增强广告主的投资回报与用户体验。
MAL实践方案总体框架
为了实现MAL范式的上述优化目标,我们设计了一套由归因知识聚合模块AKA与主目标预估头PTP组合成的模型架构(详见2.2节)。此外,在各归因机制产生的辅助目标基础上,我们创新性地提出了笛卡尔积辅助训练目标CAT(详见2.3节)。下图展示了我们MAL建模范式实践方案的整体框架。
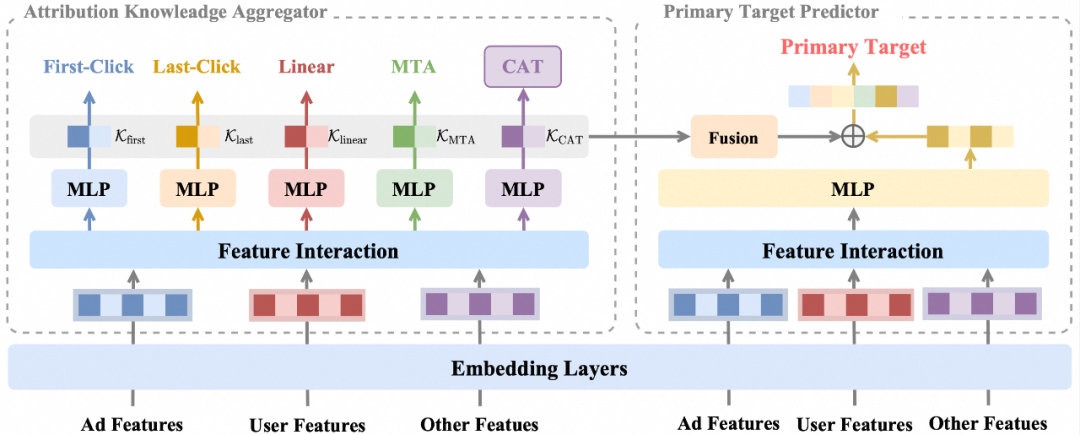
图2 MAL实践方案总体框架
2.2 模型结构巧思
与多任务学习架构的区别
由于多种归因标签的联合学习可以被视为一种多任务学习,实践者很容易想到MMoE[3]、PLE[4]等多任务学习架构作为MAL建模的基础架构。然而,如上所述,MAL建模的总体目标为最大化生产口径主目标的预估准度,而传统意义上的多任务学习则侧重于同时优化多个相关但独立的任务性能。因此,直接将这些为多任务设计的架构移植到MAL范式中,并不能有效地达成优化目标。
为此,我们设计了由归因知识聚合模块AKA与主目标预估头PTP构成的模型架构,其核心思想是为每个辅助任务(即每种归因标签的学习)设立一个独立的、包含私有参数的预估子模块,这些子模块在学习各自预估目标的同时,通过基于中间层特征注入的“知识拔插”机制,将其学到的高质量表征提供给主任务的PTP模块。这种设计高效地实现了从各辅助任务到主任务的单向知识迁移,在不干扰辅助任务学习过程的前提下,显著增强了目标归因机制下的预估准度。
下图给出了多任务学习架构与本研究所提MAL模型架构的对比,下文将详细阐述AKA与PTP模块的具体设计与功能。
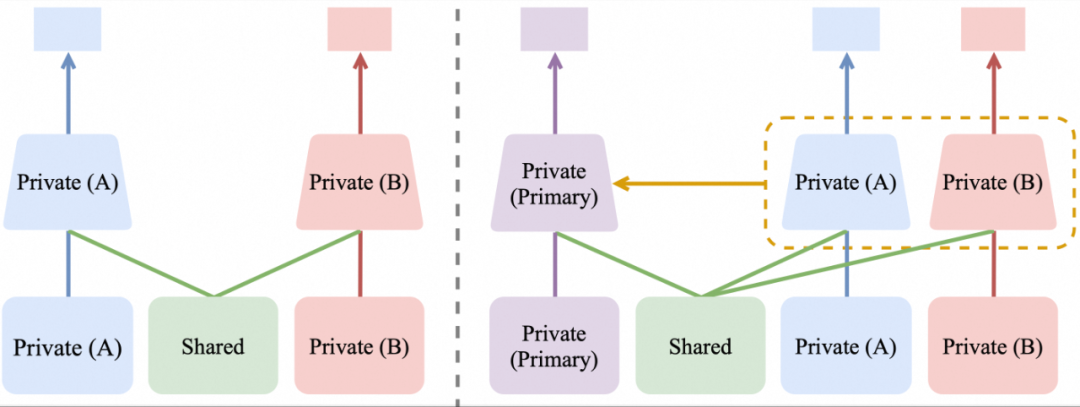
图3. 多任务学习架构(左) v.s. MAL模型架构(右)
归因知识聚合模块(AKA)
如下图所示,归因知识聚合模块(Attribution Knowledge Aggregator,简称AKA)中,每种归因口径产出的转化标签都对应一个负责预估的MLP模块,我们称之为各辅助任务预估头。设某种归因口径 产出的标签为 ,对应辅助任务预估头输出的logit为 ,训练数据集为 ,样本权重为 ,则该预估头的训练目标为最小化如下交叉熵损失,其中 为Sigmoid函数:
各辅助任务预估头共享底层的embedding参数与target attention等特征抽取结构的参数,优化目标均为上述形式,只是拟合的标签 对应的归因机制不同。 我们从各预估头的倒数第二层输出中提取特征向量 ,得到四种不同的转化知识向量: 、 、 和 。这些向量分别对应特定的归因机制(首次点击、末次点击、线性归因和多触点归因)。最终被拼接成一个统一的知识嵌入 ,作为辅助主目标预估头的多归因知识输入。具体实践中,辅助任务的个数可以视需要灵活调整。
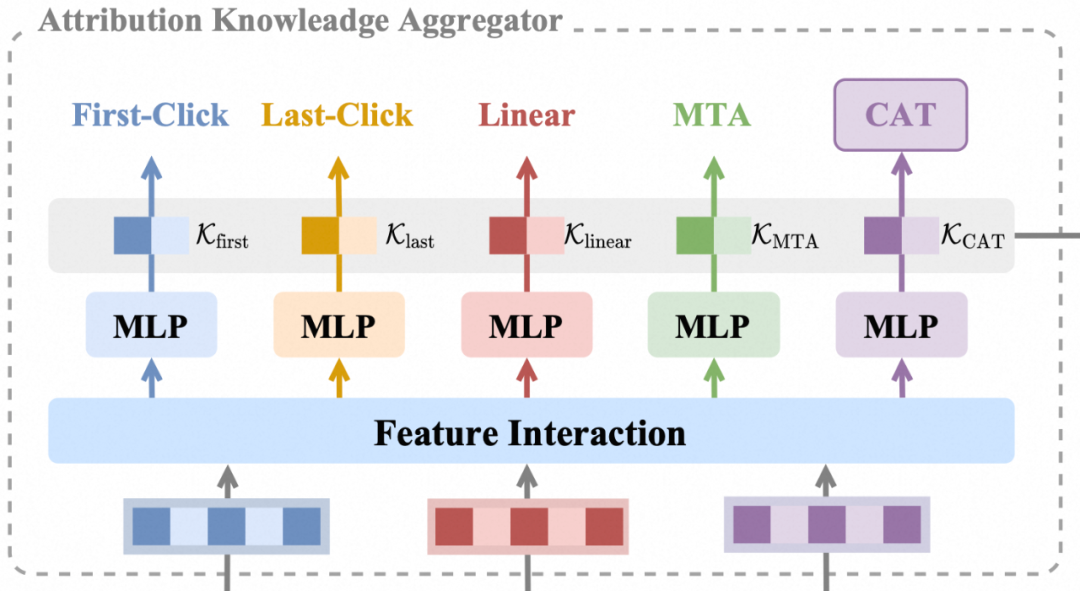
图4. 归因知识聚合模块AKA
主目标预估头PTP
主目标预估头(Primiary Target Predictor,简称PTP)负责预估生产口径主目标,即模型最终交付的目标归因机制下的转化概率预估值。PTP亦为MLP结构,与AKA模块中的各个辅助任务预估头共享底层参数,优化目标的形式也相同。和依赖单一归因训练的基线模型相比,PTP的关键创新点在于它接受从AKA模块迁移而来的转化知识向量 ,充分利用蕴含在辅助任务预估头中的知识,做出更精准的预估。
具体来说,设PTP模块的倒数第二层输出为 ,为了让AKA模块输出的转化知识向量 融入PTP的语义空间,我们参考[5] 的知识拔插思路,使用一个MLP投影模块将 转化为与 维度对齐的知识向量 ,再通过对应位置元素相加的方式融合二者,得到增强后的样本表征 ,最后将 输入二分类头得到主目标的预估值。
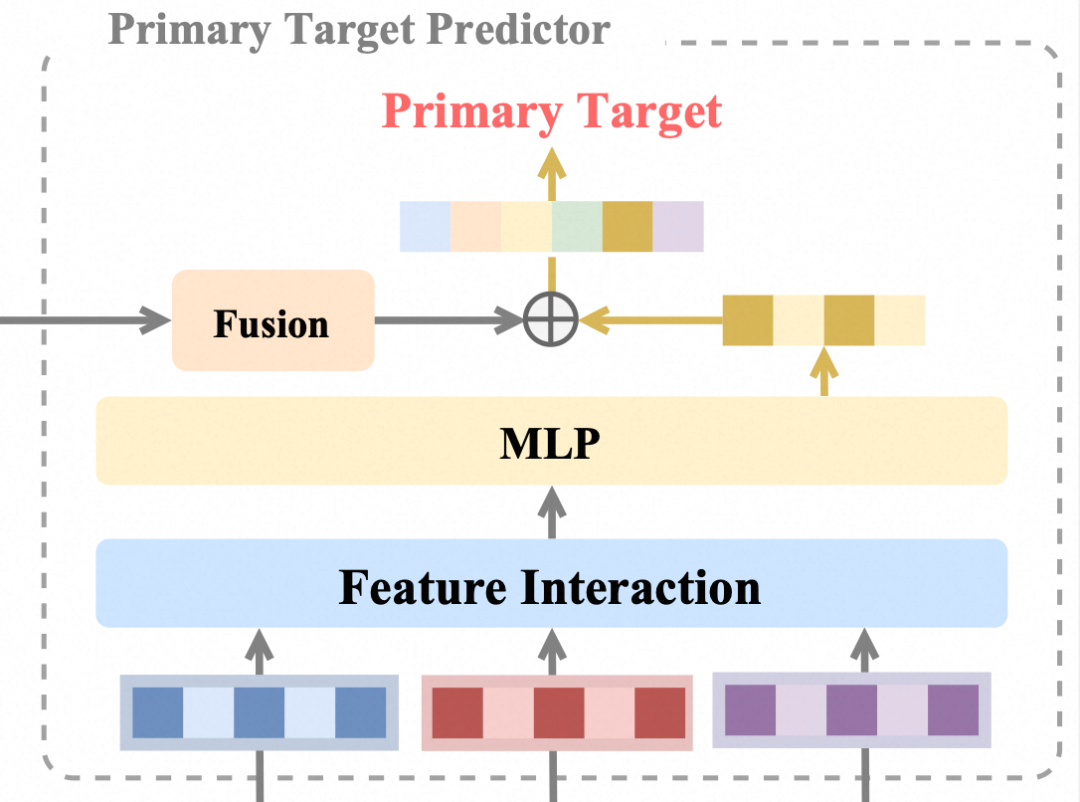
图5 主目标预估头PTP
2.3 辅助任务设计
观察:辅助目标复杂度的Scaling性质
在上述模型架构下,我们以Last-Click归因机制为目标归因机制进行实验,对比了不同归因机制所产标签作为辅助目标时对主目标预估准度的增益。如下表所示,我们得到两项关键观察:
🎈观察1:各辅助目标单独添加对主目标的预估准度都有提升,其中只关注种草价值的First-Click标签提升最小,将转化功劳相对公平地分配到各触点的MTA标签对于效果提升最大。
🎈观察2:提升辅助目标的复杂度可以带来进一步提升,First-Click、Linear、MTA标签同时作为辅助目标时提升幅度最大。
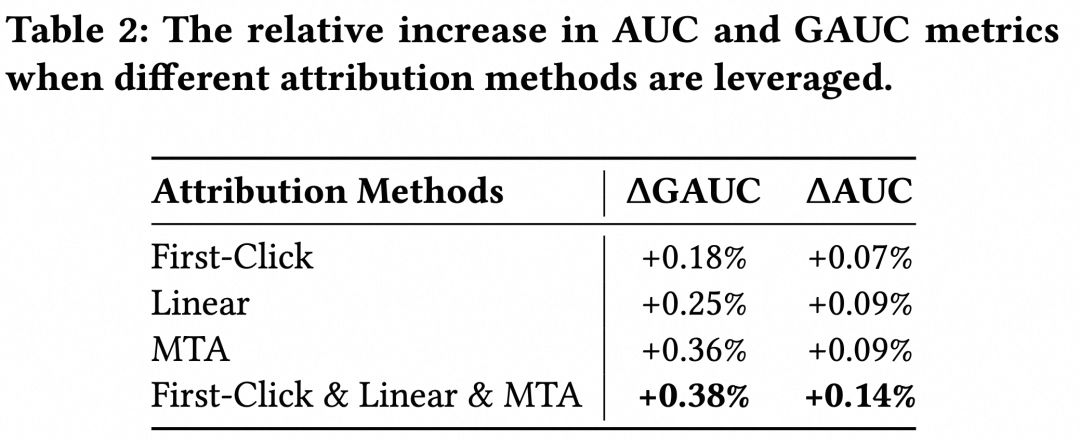
观察1启发我们,在MAL范式下,主目标准度的提升幅度可作为评估辅助归因机制分配合理性的有效指标,为缺乏量化指标指导的多触点归因(MTA)模型迭代提供更可靠的测评方式;观察2则说明,继续提升AKA模块中辅助任务目标的难度是富有潜力的改进方向。
笛卡尔积辅助任务CAT
受上述观察2启发,我们希望构造比单一归因机制所产标签更复杂的辅助目标,进一步提升模型效果。为此,我们设计了笛卡尔积辅助训练任务(Cartersian Auxilliray Training,简称CAT),作为一个难度更高的额外辅助任务加入归因知识聚合模块AKA中。如下图所示,CAT辅助任务的目标由各种归因口径产出的二元转化标签取笛卡尔积得到,当系统中存在4种归因机制时,CAT就是一个 分类任务。
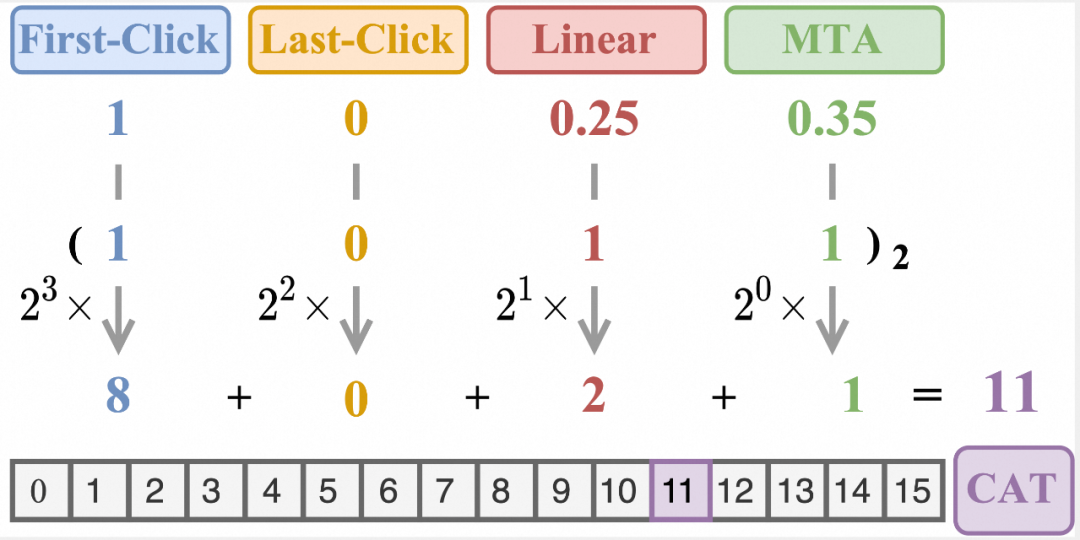
图7. CAT辅助任务目标生成过程示例
三、离在线实验效果与分析
3.1 离线收益与消融实验
我们在阿里妈妈展示广告系统的真实工业数据上进行了离线实验,使用了First-Click、Last-Click、Linear和MTA四种归因机制。在两组实验中,Last-Click和MTA归因分别作为目标归因口径,其余归因机制所产标签作为辅助目标。
总体收益
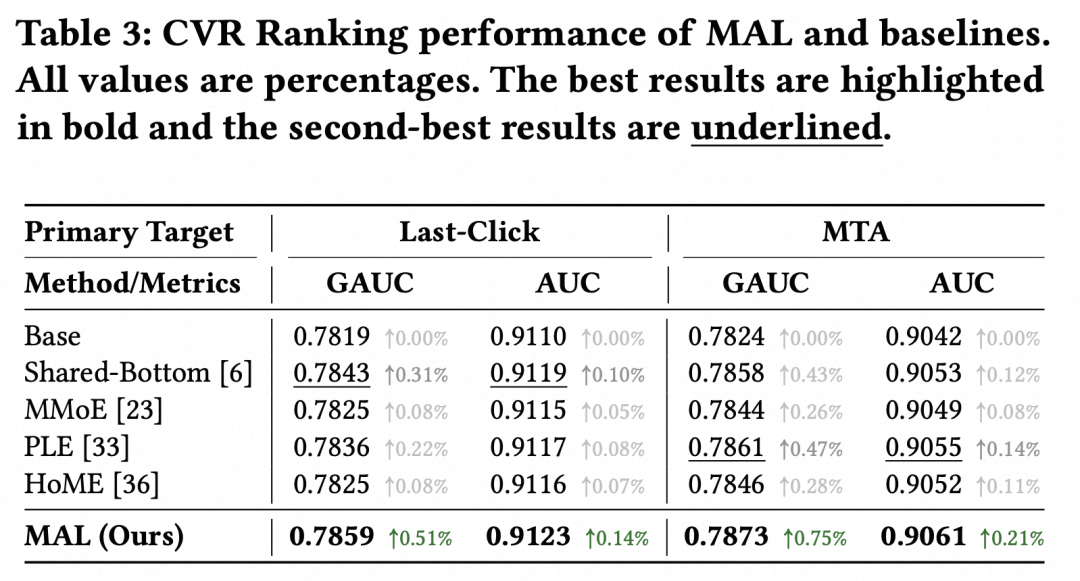
如下表所示,我们观察到MAL模型和各类引入多归因标签的多任务学习基线方法,都相对依赖单一归因机制训练的Base模型取得显著的GAUC和AUC提升,证实了多元归因机制带来的信息增量。和多任务学习基线方法相比,我们的MAL模型取得的提升更为显著,例如:
在Last-Click作为目标归因机制时,MAL模型的GAUC指标相较Base提升0.51%,而多任务学习基线中表现最佳的Shared-Bottom模型仅提升0.31%。
在MTA作为目标归因机制时,MAL模型的GAUC指标相较Base提升0.75%,而多任务学习基线中表现最佳的PLE模型仅提升0.47%。
考虑到在工业场景中0.1%的离线GAUC提升通常就能带来显著的线上收益,上述结果证明了我们精心设计的MAL模型结构与辅助目标相对传统多任务学习基线方法的优越性。
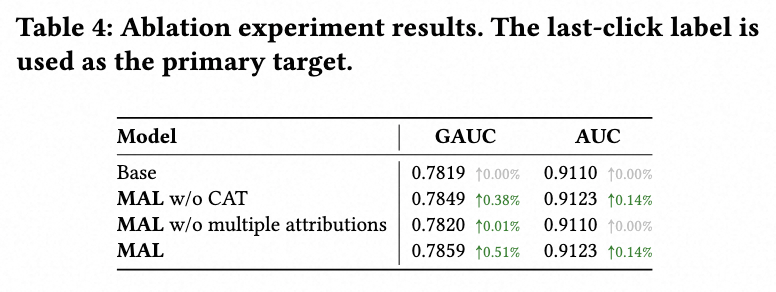
消融实验分析
在验证了MAL模型相对基线方法的显著收益后,我们进行了消融实验分析,结果如下表所示,支撑我们回答了以下两个关键问题。
Q1:笛卡尔积辅助训练目标CAT是否能带来额外提升?
A1:CAT带来相比基线模型GAUC +0.13%的额外提升,同时AUC持平,该结果验证了CAT对多元归因知识学习的增进作用。
Q2: 模型效果的提升来自参数量增长还是多元归因带来的监督信号增量?
A2: 效果提升来自于多元归因标签带来的信息增量。考虑到AKA模块中各辅助任务预估头带来了参数量的增长,除多元归因标签带来的信息增量外,参数量的增长亦有可能是模型性能提升的原因。为此,我们将AKA模块中各辅助任务预估头的监督标签置换为目标归因机制的标签(对应下表第三行),此时参数量对齐MAL模型的实验模型相比Base几乎没有提升,说明MAL模型的效果提升来自于多元归因标签带来的信息增量,而非简单的参数堆积。
用户分组分析
为了进一步理解MAL范式所带来的提升来源,我们将测试数据中的用户按照「Linear归因正样本数减去Last-Click归因正样本数」的代理指标进行分组,计算各组GAUC相对基线模型的提升幅度。正样本增量这一代理指标表示引入MAL建模范式后,各用户在预估系统中所得的监督信号增量大小。
结果如下图所示,GAUC的提升幅度与正样本增量呈显著的正相关关系。具体来看,对于正样本零增长的用户组,其GAUC提升仅为 0.19%;相比之下,对于正样本增长量>=10的用户组,其GAUC增幅则显著跃升至 1.23%。上述现象进一步支撑了“MAL效果提升来自于多元归因标签带来的信息增量”的结论。

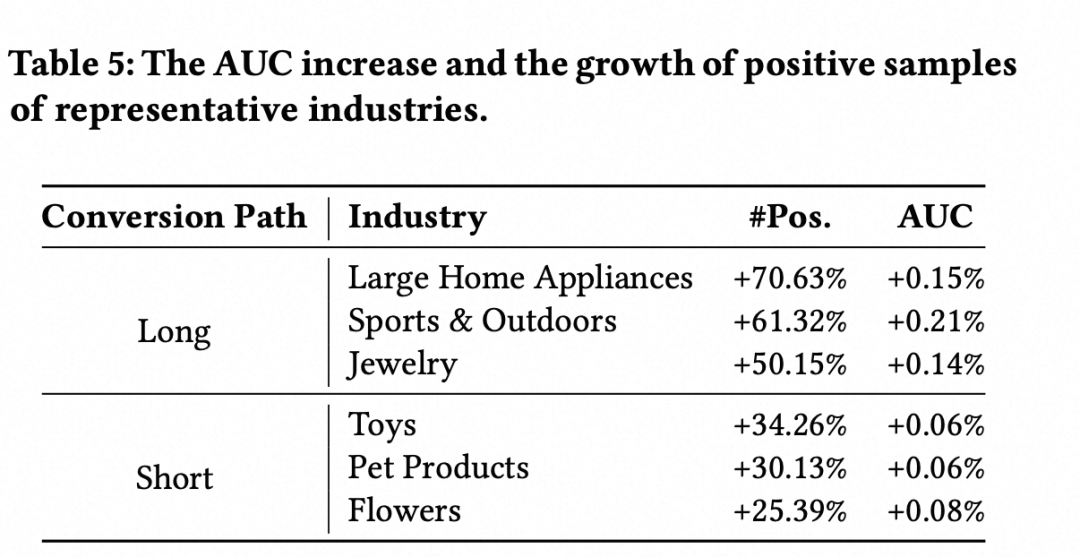
行业下钻分析
为了更深入地理解MAL范式革新对整个广告系统的影响,我们将测试样本按广告主行业进行分组,并分别计算了各行业内的AUC指标。如下图所示,所有行业的AUC均有提升,并且那些正样本数量增长更多的行业,其AUC增幅也更大。

尤其值得注意的是,如下表所列,那些转化路径较长的行业,例如大家电和珠宝,获得了最高的AUC增长;而转化路径较短的行业,例如宠物用品和玩具,其AUC增幅则显著偏低。这一结果与用户分组分析一致,充分表明MAL有效地利用了多元归因机制所提供的增量信息。
3.2 在线A/B实验结果
淘宝展示广告系统上的在线预算A/B实验结果表明,与生产基线相比,MAL模型取得了GMV+2.7%、ROI +2.6%、订单量+1.2%的显著提升。该结果证明MAL建模范式显著提升了广告推荐性能,带来了显著的业务收益。值得注意的是,我们观察高客单价行业的广告计划获益更明显。例如,大家用电器(+11.6%)和珠宝(+9.7%)的订单量增幅尤为突出。这一现象的原因在于,这些高客单价行业普遍具有较长的转化路径,因此更能从多元归因机制中获益。该观察结果与上一节离线分析相符。
四、总结与展望
现有CVR预估模型普遍受限于单一归因机制,其学习目标源于片面的转化定义,这从根本上限制了模型对用户转化心智演变的感知能力。为了克服单一归因瓶颈,本研究创新性地提出了多归因学习范式MAL,并提供了一套在阿里妈妈展示广告场景中收益显著的实践方案,实现了从拟合单一口径目标到学习多元流量价值的建模范式迁移。由于单一归因瓶颈是工业界点击后链路价值预估的共性问题,MAL建模范式及相关实践经验具备高度的可迁移性,对各类后链路预估任务(如CVR、GMV等)均有重要的应用前景。
未来,我们计划结合生成式推荐、大语言模型等前沿技术,继续在MAL范式的基础上革新后链路建模范式,包括但不限于以下方向:
1)更广阔的价值体系:在现有的购买行为之外,在MAL的框架中引入详情页互动、退款等广义转化行为,形成「多行为 x 多归因方式」的多元流量价值体系,进一步丰富模型的监督信号,提升效果天花板;
2)更强大的生成式建模:将用户触点与转化行为序列化,应用类Transformer架构进行生成式建模[6],探索后链路预估领域的scaling law;
3)更深度的认知智能(LLM4Rec):引入大语言模型的世界知识与推理能力,对用户行为与商品信息进行深度语义理解和联合推理,从而更精准地预估用户的复杂转化意图。
▐ References
[1] Yao, Di, et al. "Causalmta: Eliminating the user confounding bias for causal multi-touch attribution." Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2022.
[2] Bencina, John, et al. "LiDDA: Data Driven Attribution at LinkedIn." arXiv preprint arXiv:2505.09861 (2025).
[3] Ma, Jiaqi, et al. "Modeling task relationships in multi-task learning with multi-gate mixture-of-experts." Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 2018.
[4] Tang, Hongyan, et al. "Progressive layered extraction (ple): A novel multi-task learning (mtl) model for personalized recommendations." Proceedings of the 14th ACM conference on recommender systems. 2020.
[5] Zhang, Yujing, et al. "KEEP: An industrial pre-training framework for online recommendation via knowledge extraction and plugging." Proceedings of the 31st ACM International Conference on Information & Knowledge Management. 2022.
[6] Zhai, Jiaqi, et al. "Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations." International Conference on Machine Learning. PMLR, 2024.
END

💡 关于我们
阿里妈妈展示广告Rank团队负责广告系统核心预估算法的迭代和创新研发,致力于利用人工智能前沿技术打造超大规模体量下的创新预估解决方案。团队在用户兴趣建模及终身序列建模(DIN,DIEN,SIM)、多场景建模(STAR)、CVR预估(ESMM, DEFER, HDR)、多模态建模和推荐大模型等技术方向上持续深耕,用持续的技术突破和创新带动业务增长。近年在KDD、SIGIR、NIPS、WSDM等学术会议上发表多篇论文。欢迎感兴趣同学加入我们~
📮 投递简历邮箱:xiangrong.sxr@taobao.com
也许你还想看
WWW'25 | 大模型深度赋能搜索广告:相关性大模型多维知识蒸馏
广告深度学习计算:阿里妈妈大模型服务框架HighService
关注「阿里妈妈技术」,了解更多~


















 929
929

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









