






1. 背景
近年来,因果推断在推荐、广告、用户增长等领域得到越来越多的关注和应用。如在用户/客户增长领域的消息发送和权益分发方面,为了兼顾用户体验和平台效率,不仅需要预估用户在接受不同权益下的转化概率,还需要预估用户自然情况下未接收干预的转化概率,以计算转化概率增量实现在特定约束下最大化整体用户的转化。在营销广告领域,通过预估用户的转化增量可以使预算花在最有价值的流量上,以实现营销成本约束下的ROI最大化。
因果推断面临的核心问题是反事实样本缺失。一般情况下同一个个体只接收到一种干预,没有其他干预下的转化数据,即我们获得的数据为一种干预下的观察数据,目标是学习每个个体上的处理效应(不同干预变量下的效果)。近些年,基于解耦表征的方法是因果效应估计的主流研究方向,即把输入的协变量分解成三个潜在因子包括工具因子(Instrumental Factor,只影响干预变量的因子)、混淆因子(Confounding Factor,同时影响干预变量和干预结果的因子)和调整因子(Adjustment Factor,只影响干预结果的因子)。然而如何高效、准确学习解耦因子仍然是一个开放性的问题,这也是能够正确识别个体处理效应的必要条件。目前的研究方法未能获取独立的解耦因子,在本文中,我们提出了通过互信息最小化来帮助学习反事实推断中的解耦表征,并在学习潜在因子时利用多任务框架来共享信息,在公开数据集和用户增长方面的工业数据集的实验证明了该方法效果超过目前SOTA的方法。
该项工作是阿里妈妈客户增长算法团队在客户增长问题上的实践总结,基于该项工作整理的论文已发表在SIGIR 2022,欢迎阅读交流。
论文:Learning Disentangled Representations for Counterfactual Regression via Mutual Information Minimization
链接:https://doi.org/10.1145/3477495.3532011
2. 引言
2.1 问题概述
计算因果效应在政策制定、医疗诊断、广告、推荐和用增等诸多领域都是很重要的研究方向之一。特别地,在用户增长领域,很多公司会做营销活动如发放优惠券和推送消息内容以提高用户活跃度和留存率。这里的反事实问题可以定义为“用户接受到优惠券或消息推送后是否会变得更活跃?"。
估计因果效应的一个黄金准则是随机控制实验RCT(Randomized Controlled Trail)[21],其中干预变量是随机分配给各个个体的,但现实中这样方法往往成本昂贵、甚至伦理上不可行。因此我们通常聚焦从观察数据中去估计因果效应。在观测性研究中,干预变量通常依赖于个体的某些特征从而导致选择偏置的问题[16],因此有效识别所有的混淆变量是非常关键的,从而保证处理效应是可以识别的[21]。
2.2 相关工作
现在主流因果效应估计方法是通过倾向分加权或者通过减少处理组和控制组间不一致性的表征学习方法,如BNN[17],CFR-Net[24],但是这些方法都忽略了除混淆因子以外其他潜在因子的识别。最近,解耦表征学习方法如[19],DR-CFR[14]和TEDVAE[28]提出学习解耦因子 ,以此来更高效准确地估计因果效应,它们分别表征只影响干预变量的因子、只影响输出结果的因子和同时影响干预和输出结果的因子。虽然解耦表征方法极大程度准确识别潜在因子,但以上方法仍面临一些局限性,例如无法有效区分混淆因子与其他两种因子。除此之外,这些方法不能获得独立的解耦表征,这个是识别处理效应的必要条件。基于此认知我们提出利用互信息最小化的方法来约束因果效应估计中的解耦变量之间的独立性,该方法在domain adaption[10]、style transfer[18]等场景已经获得了很多关注和应用。特别地,我们参考[6]使用了CLUB(Contrastive Log-Ratio Upper Bound)互信息的上界来进行互信息最小化约束,该方法在很多场景已经证明了其有效性。
3. 方法
3.1 Preliminary
给定观察数据集 ,其中是数据样本数,代表输入特征数据表示个体context信息,是观察到的事实样本结果,是反事实即未观察到的样本结果,代表潜在的干预(如这里以),我们的目标是要学习到一个函数预测潜在干预结果,然后预估个体处理效应和平均处理效应:
ITE(Individual treatment effect,个体处理效应):
ATE(Average Treatment Effect,平均处理效应) :
402 Payment Required
一般地,在估计处理效应时我们假设如下基本假定成立:
1.(SUTVA,The Stable Unit Treatment Value Assumption). 要求某个个体的干预结果只依赖于该个体接受到的干预,不会受到其他个体影响。
2.(Unconfoundedness). 对特定观察样本而言,干预的分配机制与潜在结果无关,即,表示不同干预下的潜在结果不会受到样本接受何种干预影响。
3.(Positivity). 每个个体均有非零的概率接受到每种干预,。
3.2 多任务解耦表征学习
不失一般性,我们假设数据集是由潜在因子生成的。在我们的场景中,包含用户的属性、行为和上下文信息,表示是否发放优惠券或者推送消息,表示用户的登录率或者点击率。我们期望把输入特征变量通过解耦表征层来学习三种独立的解耦因子,即:
其中,,表示特征维度。DR-CFR直接使用三个独立的表征网络学习三种因子,但在实验中表明该方式不能有效区分 和 。受多任务学习启发,我们用共享底层表示的结构学习共享的特征然后用跟特定因子相关的网络学习解耦因子,并定义以下任务:
任务1:从 预估干预变量,损失函数为. 最小化该损失可以保证干预变量的信息都包含在 和 中。
任务2:从预估处理效应,损失函数定义为
402 Payment Required
. 是每个干预变量的回归或者分类网络,优化该目标我们可以确保影响潜在结果的因素都包含在 和 。任务3:限制不同干预变量下的样本分布不一致性
402 Payment Required
,这样我们可以确保与干预变量无关。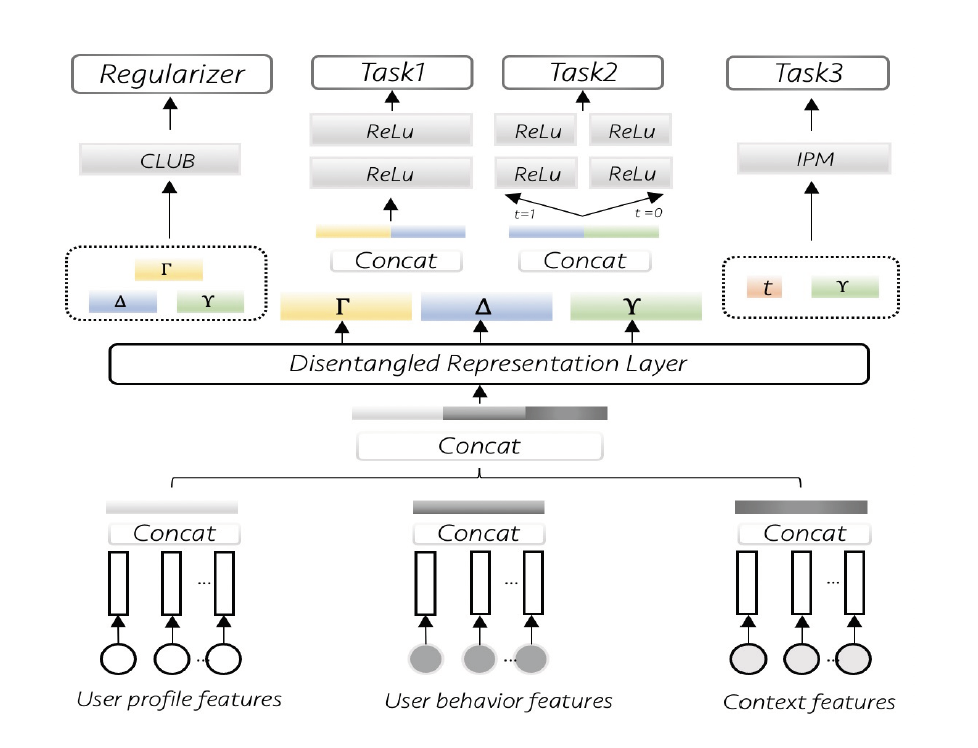
通过以下的多任务目标优化,我们期望所有混淆变量信息都包含在,影响干预变量的的因素都包含在,影响结果的因素都包含在,其中和是对应任务的权重参数。
3.3 互信息最小化正则
为了得到独立的解耦因子,我们利用互信息最小化的学习准则以保证因子间的独立性。互信息是衡量随机变量和关联性的指标,在数学上的表示为
402 Payment Required
借鉴[6],我们引入CLUB作为解耦表征互信息最小化的上界,当变量之间条件概率已知时,CLUB定义为
402 Payment Required
。然而在实际场景中 是未知的,因此我们用变分分布 近似 得到 ,可以证明当我们较好地近似 时 仍是互信息的一个上界。所以我们可以用以下的互信息最小化准则学习因果效应估计中独立的解耦表征:最终的目标函数定义为:
402 Payment Required
4. 实验
4.1 基准数据集评估
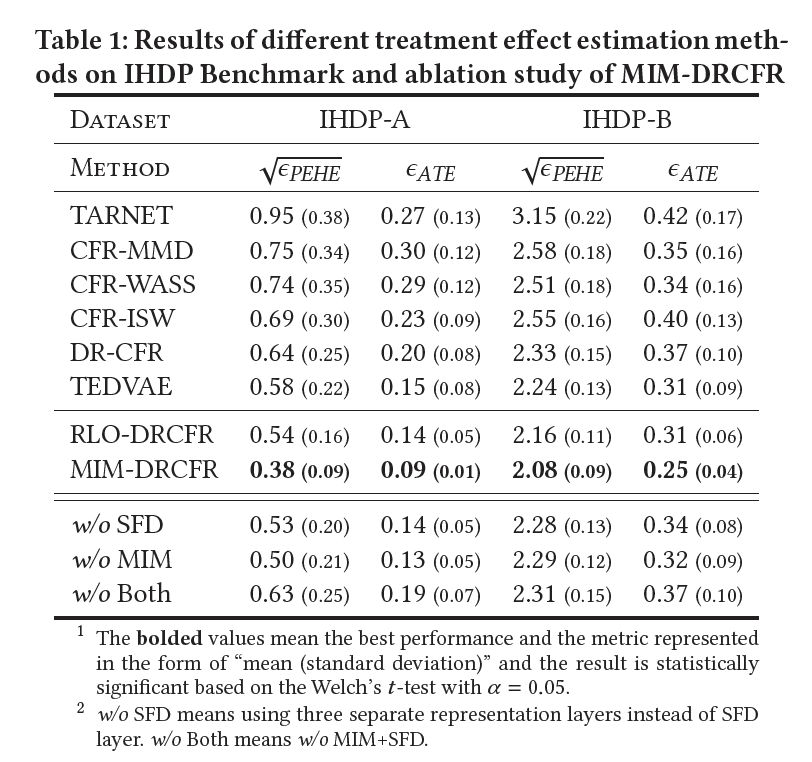
IHDP Benchmark:我们使用IHDP作为基准数据集[15]。IHDP输入的协变量来自一个研究专家家访对新生儿认知测试成绩的影响的随机实验,选择偏置是通过去除有偏的干预群体子集引入的,该数据集包含747个样本(139干预样本,608控制样本)和25个衡量婴儿和父母属性的协变量特征,我们通过仿真得到了包含线性IHDP-A和非线性IHDP-B两个不同数据集,然后分别模拟了100次用来评估模型的平均效果。
评估指标:当数据集同时包含事实和反事实的输出结果,我们可以从如下两个维度评估处理效应预估效果:
个体处理效应评估:
402 Payment Required
。其中 表示实际个体处理效应。表示估计的个体处理效应,平均处理效应评估:。其中表示实际平均处理效应, 表示预估平均处理效应。
对比方法:我们用作对比的基准方法包括: TRANET[23],CFR-WASS[23],CFR-MMD[23],CFR-ISW[13]。基于解耦表征的方法包括:DR-CFR[14],TED VAE[27],MIM-DRCFR及其变种RLO-DRCFR。在基准数据集中的实验结果也证明了我们的方法在个体处理效应预估上可以取得较好的效果。
消融实验:消融实验结果也说明了多任务解耦表征和互信息最小化两个模块都可以带来效果的提升。
4.2 离线评估
问题定义:在用户增长业务场景,我们一般会面临如下的约束问题:“在给定的红包预算约束下,给哪些用户发放红包,能够带来整体转化最大化”,该问题可以形式化定义如下:
可以证明只需要筛选高处理效应个体进行干预即可最大化整体收益。因此,我们将该预算约束下最大化整体转化问题转化成个体处理效应预估问题,通过个体处理效应预估值进行人群筛选来最大化收益。
数据集:阿里巴巴用户增长场景的红包发放和消息触达两份真实业务数据集,其中干预变量分别为“是否给用户发放红包”以及“是否给用户发送消息”,特征包含用户的属性,历史行为特征和上下文特征等,输出为用户的登录率或者点击率。
评估指标:由于在实际场景中我们无法同时观测到实际结果和反事实结果,业界通常采用Area Under the Uplift Curve (AUUC)[8,12,26]作为离线评估的指标:
其中表示按个体处理效应预估值降序排列的前个样本。表示干预组的输出, 表示中的干预组中的样本数量。下图是基于消息触达场景离线数据集绘制的Uplift Curve:
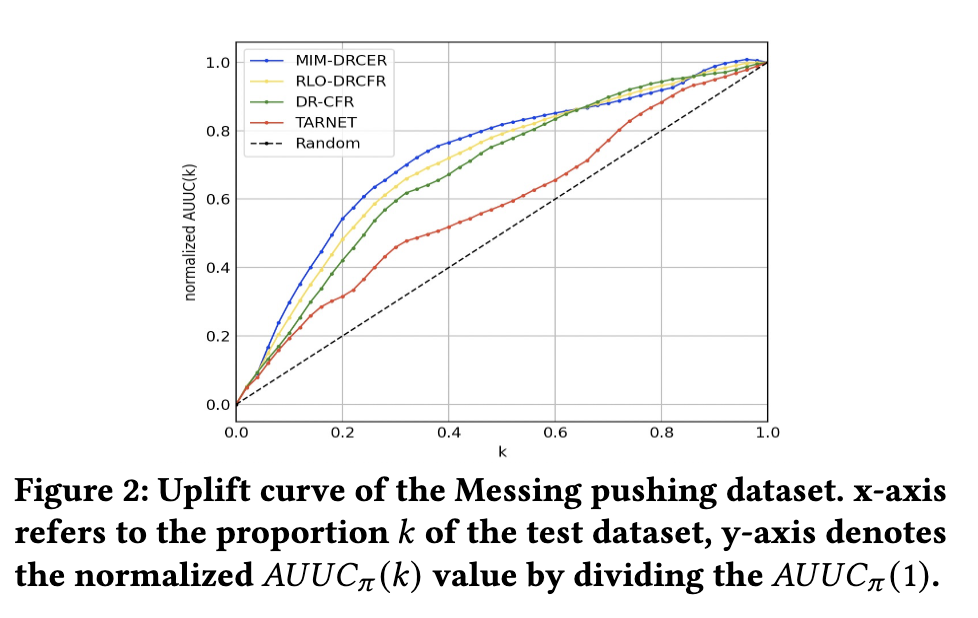 我们还可以通过对累积求和获得[8]来定量衡量离线效果的好坏。其中AUUC越大,表示基于我们预估的个体处理效应越能筛选出对干预反馈最敏感的人群。
我们还可以通过对累积求和获得[8]来定量衡量离线效果的好坏。其中AUUC越大,表示基于我们预估的个体处理效应越能筛选出对干预反馈最敏感的人群。
402 Payment Required
在红包发放和消息触达两个数据集上,我们的方法相对于基准模型在离线AUUC指标上都有一定的提升。

4.3 在线评估
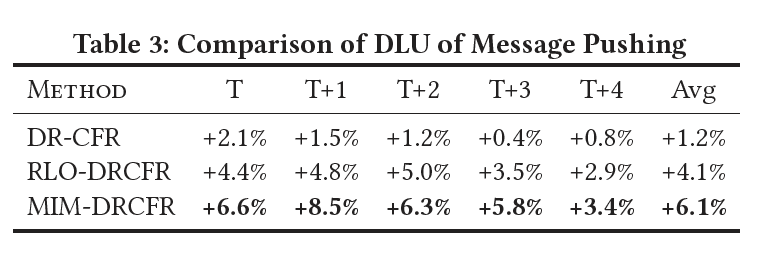
消息触达在线实验中,我们会圈选一部分用户作为整体,然后基于个体处理效应预估值选取一定比例(60%)的用户进行消息触达干预,剩余群体不作任何干预。然后评估该整体的DLU(Daily login users)来衡量效果,我们对比了三种解耦表征模型DR-CFR,RLO-DRCFR和MIM-DRCFR,其中MIM-DRCFR相对于原有策略在DLU上获提升6.1%。
5. 总结
在本文,我们聚焦在预估ITE的解耦表征学习,提出了解耦框架MIM-DRCFR,利用多任务学习方法以在解耦过程中更好共享信息和互信息最小化以更好获得潜在因子间的独立性,在公开数据集和真实业务数据集上均获得了较好的性能。未来,我们考虑探索更高效的解耦方法,并扩展到多干预变场景中。另外,如何在基于uplift建模能力帮助广告主实现更多自然流量/店铺成交撬动和消费者资产积累,以及从纯增量视角提升客户广义ROI,对进一步提升营销预算都至关重要。基于此我们也会展开更多的业务尝试和探索,欢迎感兴趣的同学加入我们!
6. 参考文献
[1] S. Athey and G. Imbens. 2016. Recursive partitioning for heterogeneous causal effects. Proceedings of the National Academy of Sciences 113 (2016), 7353 – 7360.
[2] P. Austin. 2011. An Introduction to Propensity Score Methods for Reducing the Effects of Confounding in Observational Studies. Multivariate Behavioral Research 46 (2011), 399 – 424.
[3] Artem Betlei, Eustache Diemert, and Massih-Reza Amini. 2020. Treatment Targeting by AUUC Maximization with Generalization Guarantees. arXiv:2012.09897 [cs.LG]
[4] L. Bottou, J. Peters, J. Q. Candela, D. Charles, D. M. Chickering, Elon Portugaly, Dipankar Ray, P. Simard, and Edward Snelson. 2013. Counterfactual reasoning and learning systems: the example of computational advertising. J. Mach. Learn. Res. 14 (2013), 3207–3260.
[5] T. Chen, Xuechen Li, Roger B. Grosse, and D. Duvenaud. 2018. Isolating Sources of Disentanglement in Variational Autoencoders. In NeurIPS.
[6] Pengyu Cheng, Weituo Hao, Shuyang Dai, Jiachang Liu, Zhe Gan, and L. Carin. 2020. CLUB: A Contrastive Log-ratio Upper Bound of Mutual Information. In ICML.
[7] George B. Dantzig. 1957. Discrete-Variable Extremum Problems. Operations Research 5 (1957), 266–288.
[8] E. Diemert. 2018. A Large Scale Benchmark for Uplift Modeling.
[9] Shuyang Du, James Lee, and Farzin Ghaffarizadeh. 2019. Improve User Retention with Causal Learning. In The 2019 ACM SIGKDD Workshop on Causal Discovery. PMLR, 34–49.
[10] Clive Granger and Jin-Lung Lin. 1994. Using the mutual information coefficient to identify lags in nonlinear models. Journal of time series analysis 15, 4 (1994), 371–384.
[11] Tiankai Gu, Kun Kuang, Hong Zhu, Jingjie Li, Zhenhua Dong, Wenjie Hu, Zhenguo Li, Xiuqiang He, and Yue Liu. 2021. Estimating True Post-Click Conversion via Group-stratified Counterfactual Inference.
[12] Pierre Gutierrez and Jean-Yves Gérardy. 2017. Causal inference and uplift modelling: A review of the literature. In International conference on predictive applications and APIs. PMLR, 1–13.
[13] N. Hassanpour and R. Greiner. 2019. CounterFactual Regression with Importance Sampling Weights. In IJCAI.
[14] N. Hassanpour and R. Greiner. 2020. Learning Disentangled Representations for CounterFactual Regression. In ICLR.
[15] Jennifer L. Hill. 2011. Bayesian Nonparametric Modeling for Causal Inference. Journal of Computational and Graphical Statistics 20 (2011), 217 – 240.
[16] G. Imbens and D. Rubin. 2015. Causal Inference for Statistics, Social, and Biomedical Sciences: An Introduction.
[17] Fredrik D. Johansson, U. Shalit, and D. Sontag. 2016. Learning Representations for Counterfactual Inference. ArXiv abs/1605.03661 (2016).
[18] Hadi Kazemi, Sobhan Soleymani, Fariborz Taherkhani, Seyed Iranmanesh, and Nasser Nasrabadi. 2018. Unsupervised image-to-image translation using domainspecific variational information bound. Advances in neural information processing systems 31 (2018).
[19] Kun Kuang, Peng Cui, B. Li, Meng Jiang, Shiqiang Yang, and Fei Wang. 2017. Treatment Effect Estimation with Data-Driven Variable Decomposition. In AAAI.
[20] Robert J LaLonde. 1986. Evaluating the econometric evaluations of training programs with experimental data. The American economic review (1986), 604– 620.
[21] Judea Pearl. 2009. Causality. Cambridge university press.
[22] P. Rosenbaum and D. Rubin. 1983. The central role of the propensity score in observational studies for causal effects. Biometrika 70 (1983), 41–55.
[23] U. Shalit, Fredrik D. Johansson, and D. Sontag. 2017. Estimating individual treatment effect: generalization bounds and algorithms. In ICML.
[24] W. Sun, Pengyuan Wang, Dawei Yin, Jian Yang, and Yi Chang. 2015. Causal Inference via Sparse Additive Models with Application to Online Advertising. In AAAI.
[25] Zhenlei Wang, Jingsen Zhang, Hongteng Xu, Xu Chen, Yongfeng Zhang, Wayne Xin Zhao, and Ji-Rong Wen. 2021. Counterfactual data-augmented sequential recommendation. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 347–356.
[26] Weijia Zhang, Jiuyong Li, and Lin Liu. 2021. A unified survey of treatment effect heterogeneity modelling and uplift modelling. ACM Computing Surveys (CSUR) 54, 8 (2021), 1–36.
[27] Weijia Zhang, Lin Liu, and Jiuyong Li. 2021. Treatment effect estimation with disentangled latent factors. In AAAI.
[28] Yang Zhang, Fuli Feng, Xiangnan He, Tianxin Wei, Chonggang Song, Guohui Ling, and Yongdong Zhang. 2021. Causal intervention for leveraging popularity bias in recommendation. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 11–20.
END

也许你还想看
丨SIGIR'22 | 大规模推荐系统中冷启动用户预热的融合序列建模
丨KDD'22 | CausalMTA: 基于因果推断的无偏广告多触点归因技术
丨CIKM 2021 | 基于异质图学习的搜索广告关键词推荐


喜欢要“分享”,好看要“点赞”哦ღ~
↓欢迎留言参与讨论↓
















 1051
1051











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









