



小记:
自24年开始,生成式预估模型在阿里妈妈搜索广告主场景全面落地,各有侧重的两个系列 LUM 和 FAT 分别在精排CTR预估模型上全量了两期,累计贡献大盘CTR+13%的显著收益。
▐ 序言:算力红利下的范式错位
如果将 AI 的演进看作一场由算力驱动的变革,我们正处在一个关键的分岔点:大语言模型已在千亿参数、千卡集群上实现规模化训练,效果随算力投入平滑增长,迈入高效扩展的快车道;而搜推广的预估模型,尽管运行在相同的硬件基础设施上,却长期困于低算效状态——MFU(Model FLOPS Utilization)徘徊在个位数,模型增大甚至带来收益递减。两者虽处于同一技术时代,却呈现出截然不同的发展轨迹。
问题不在于投入不足或工程能力欠缺,而在于预估模型的底层建模范式已与当前的硬件和算力环境脱节。
一、回望来路:两条算法脉络与一场硬件演进
要理解当前搜推广预估模型的瓶颈,需要回顾三条长期并行但尚未有效融合的发展主线:
一条是大模型的规模化路径,
一条是预估模型的精细化演进,
而驱动这一切的底层力量,是一场静默却彻底的硬件架构的持续演进。
它们共同指向一个核心问题:随着计算范式的转变,现有 AI 系统是否仍具备高效利用算力的能力?
1. LLM启示录:通用计算的胜利之路
大语言模型的崛起,并非偶然的技术跃迁,而是一场对智能本质的回归:真正的智能不依赖人工规则的堆砌,而诞生于简单目标在通用算力上的极致放大。
“The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin.”
— Rich Sutton, The Bitter Lesson (2019)
这一理念在三个关键阶段得到验证:
2017 架构解放:Transformer 通过自注意力机制摆脱了 RNN 的序列依赖,实现了高度并行的训练结构,不仅提升了长序列建模能力,也更好地适配了 GPU 的并行计算特性,为后续规模化奠定了基础。
2020 Scaling Law觉醒:Kaplan 等人发现,语言模型性能随参数量、数据量和计算量呈幂律增长。这意味着模型能力可通过持续投入稳定提升,模型开始具备可规划的工程属性。
2022 工程兑现:FlashAttention、DeepSpeed和Megatron-LM 等技术的成熟,构建出高效的训练栈,使 MFU 普遍超过 30%,千亿参数模型成为可复制的工业实践。
LLM 的成功可归结为三个关键特征:
统一架构:文本、代码、图像等均可通过 token 化统一处理;
生成式目标:通过自回归预测下一个 token,模型隐式学习数据的联合分布;
硬件协同设计:从算子实现到通信优化,整个系统围绕 Tensor Core 进行深度适配,显著提升计算效率。
这不仅是自然语言处理的进步,而是昭示了一个普适真理:当算法设计与硬件特性对齐时,计算才能真正奔涌。
2. 预估模型的困局:高效却受限的“人工智能”
相比之下,搜推广系统的演进,是一条高度务实却逐渐触顶的道路。
早期,FM、FFM 通过显式构造特征交叉(如“用户年龄 × 商品类目”)实现非线性建模。这一方法虽依赖人工先验,但在数据稀疏、算力有限的时代极具工程价值。
随着用户行为序列日益丰富,DIN、DIEN 引入注意力机制以刻画兴趣演化;DeepFM、DCN 则通过显式高阶交互增强特征组合能力。这些创新显著提升了 AUC 与业务指标,推动工业推荐系统进入“经验驱动的模块化堆叠时代”。
然而,这条路径的本质仍是基于先验知识的功能性模块累加:每一个新结构都为捕获特定信号而设计——无论是交叉项、注意力头还是高阶变换层。这种思路虽能快速响应业务需求,却也带来了深层代价:
模型架构日益臃肿,定制化子网络层出不穷;
特征工程与网络结构深度耦合,迭代成本持续攀升;
表达能力的增长愈发依赖“经验规则”,而非数据驱动的自动泛化。
更关键的是,每一次效果跃迁背后,往往是新模块的引入与工程调优的叠加。这种方式在边际上持续见效,却难以形成可复现的规模化增长路径——模型变得越来越复杂,但并未变得更“聪明”。
而这种复杂性不仅体现在表达层面,更直接转化为系统执行层面的高昂代价:
层出不穷的小算子导致 CUDA kernel 启动频繁,调度开销远超有效计算;
稀疏 ID 查表与分散 MLP 共同构成低算术强度的计算流,难以激活 Tensor Core;
我们并非走错了路,而是抵达了一条高度优化的局部最优路径的终点。下一步,不再是如何“修修补补”,而是是否敢于重构底层范式。
3. 硬件进化论:当摩尔定律转向张量定律
如果说算法的演进是内因,那么硬件的变革则是外因。过去八年,GPU 性能发生了根本性跃迁:
2016年 P100:FP32 算力 9.3 TFLOPS,带宽 732 GB/s;
2023年 H100:FP16/BF16 算力 989 TFLOPS ,带宽 3.35 TB/s。
峰值算力增长超 100 倍,而内存带宽仅提升约 4.6 倍,导致理论算术强度(FLOPS/Bytes)提升 23 倍。现代 GPU 已全面转向“计算密集型”设计。
在这一体系下,两类模型的表现出现分化:
LLM:以 GEMM 为主导,计算密集、访存规整,完美匹配 Tensor Core,MFU 可超 30%;
CTR 模型:以稀疏查表为主,访存密集、计算稀疏,被视为低效负载。
最终结果是:最先进的计算芯片,被用于执行高度碎片化的任务,算力潜力远未释放。
二、算力之困:搜推广为何难享规模化红利?
前文指出,大语言模型的成功不仅源于数据与参数的堆叠,更在于其算法设计与现代硬件的高度协同:统一的 token 表示、自回归生成目标、GEMM 主导的计算流,共同构成了可高效扩展的 Scaling 范式。反观搜推广系统,尽管同样运行在千卡 GPU 集群之上,却长期陷入“模型越复杂、收益越边际”的困境——算力投入与业务效果之间缺乏稳定、可复现的正向关系。
这一鸿沟的根源,并非工程能力不足,而在于底层建模范式与硬件发展趋势的系统性错配。具体表现为三大结构性瓶颈:
极低的算术强度:大量计算时间消耗在稀疏 ID 的 Embedding 查表上,后续的 MLP 或特征交叉操作计算量微弱。整体算术强度远低于 H100 所需的数百量级,导致 MFU 长期处于个位数水平。
高度碎片化的计算流:多塔结构、显式交叉模块、局部注意力加权等设计虽提升了表达能力,但也引入了数千个微小 CUDA kernel。频繁的 kernel 启动和非连续内存访问成为主要开销,并行计算潜力难以有效利用。
缺乏可预测的规模化收益:在现有架构下,增加模型容量或计算复杂度往往难以带来稳定的效果提升,且易受延迟与资源约束限制,导致算力投入与业务收益之间缺乏可复现的 Scaling 关系。
要破解这一困局,关键在于重构预估模型的整体架构,我们由此构建了一个分层协同的生成式预估模型架构(如下图所示):
底层以 LUM 为通用用户基座,通过自回归预训练,结合用户终身行为序列和世界知识,学习协同模式与兴趣演化规律,训练过程以高吞吐张量运算为主,MFU 超 40%;
上层以 FAT 为稠密计算结构,通过统一架构融合基座输出与实时特征,推理过程高度规整,MFU 达 20% 以上,且随规模扩展持续提效。
二者通过PreTrain-PostTrain-Application的三阶段范式,共同形成一条从离线学习到在线服务的端到端算力友好链路。接下来两章,我们将分别展开这一新架构的两个支柱:如何构建通用用户基座,以及如何实现高效稠密计算。
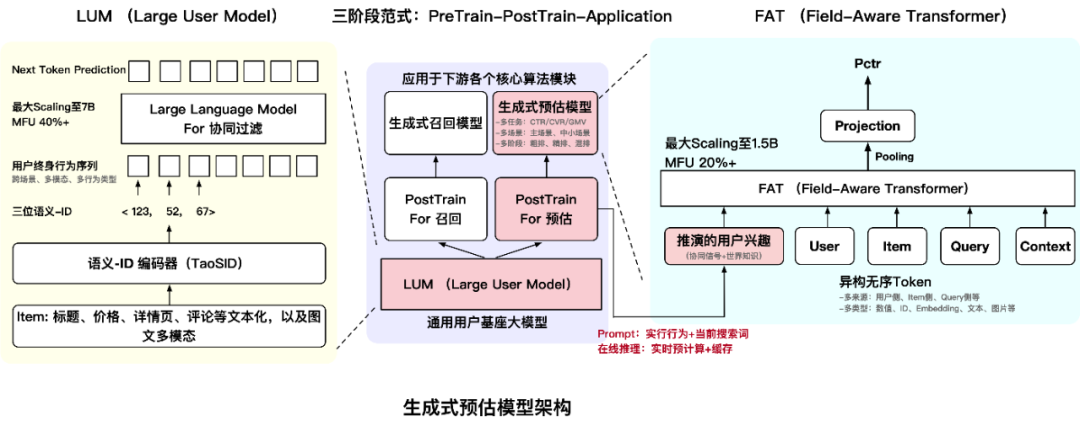
三、LUM:构建面向算力红利的通用用户基座大模型
当前搜推广系统,用户长周期、多场景、多模态、多类型的行为序列已成为最具潜力的信息源。然而,传统建模范式难以充分释放其价值——受限于短视的目标函数与碎片化的计算结构,模型即便不断增大,也往往陷入“算力投入高、能力增长慢”的困境,无法实现稳定可预期的效果扩展。
要释放这一数据潜力,关键在于构建一个高信息密度、高计算效率、可多任务复用的用户建模范式。为此,我们提出 Large User Model (LUM) ——一一个面向工业场景的通用用户基座大模型,通过自监督预训练从终身行为序列中自动学习用户兴趣的深层结构,并为召回、预估等下游任务提供基础的用户理解支持。
LUM 以 Next Token Prediction 为预训练目标,其核心建模思想在于通过结构化解耦,实现语义信号与协同信号的高效融合:
语义信号由语义 ID 编码器承载:原始 Item(如商品、内容)通过语义 ID 编码器(TaoSID)映射为万级规模的紧凑语义 ID。该编码器融合商品属性、类目体系、多模态特征等静态先验,将亿级稀疏空间压缩为高内聚、低冗余的语义词表,显著缩短序列长度并提升表征质量;
协同信号由上层 Transformer 挖掘:在语义 ID 序列上, Transformer 通过自注意力机制建模 Token 间的共现、转移与演化模式,自动发现用户兴趣的动态结构。
这一设计不仅提升了建模能力,更从根本上优化了计算效率:
计算高度稠密:基于 Transformer 的长序列建模以 GEMM 为主,MFU 超 40%,真正匹配 H100 等现代硬件的张量计算特性;
具备清晰的 Scaling 行为:随着参数量与数据规模增长,其行为预测能力(如 Recall@K)持续提升,并可有效迁移到下游任务。
更重要的是,LUM 并非孤立模型,而是搜推广系统的通用认知基座。通过“PreTrain–PostTrain–Application”三阶段范式——既可用于生成式召回模型,也可于生成式预估模型。这种“一个底座、多处复用”的架构,极大提升了算力投资的边际效益。
LUM 的实践表明:搜推广的 Scaling 路径,不在于盲目模仿 LLM 的形式,而在于构建与自身数据特性、业务目标和硬件环境对齐的生成式认知范式。
相关工作:
【LUM】Unlocking Scaling Law in Industrial Recommendation Systems with a Three-step Paradigm based Large User Model,WSDM 26(https://arxiv.org/abs/2502.08309)
【UQABench】UQABench: Evaluating User Embedding for Prompting LLMs in Personalized Question Answering,KDD 25(https://arxiv.org/abs/2502.19178)
【RecIS】RecIS: Sparse to Dense, A Unified Training Framework for Recommendation Models(https://arxiv.org/abs/2509.20883)
四、FAT:构建面向张量计算的统一稠密结构
当前工业级预估模型虽结构日益复杂,但效果收益逐渐触顶,根本瓶颈已从表达能力转向计算效率:多塔分支、显式交叉模块、局部注意力等设计催生数千个微小 CUDA kernel;频繁的 kernel 启动、非连续内存访问与极低算术强度,导致 MFU 长期徘徊在个位数。
我们追问:能否摒弃碎片化的子网络拼接,构建一条端到端的规整计算流?
Transformer 因其高度并行、GEMM 主导的特性,成为理想选型。然而,通用 Transformer 与搜推广数据存在根本错配:预估模型输入是由数十个高基数、无序、异构字段(如 user_id、item_id、item_price、query_text)组成的集合,而非语言那样的有序 token 序列。直接套用标准 Attention 会导致:
噪声泛滥:注意力在高维稀疏 Embedding 空间中广泛分散,低频 ID 与无关字段引入大量干扰;
语义盲区:模型无法区分字段角色(如用户侧 vs. 商品侧),交互缺乏方向性与可解释性;
泛化受限:海量稀疏 ID 占据模型容量,极易过拟合。
换言之,语言依赖“顺序语法”,而表格数据依赖“组合语义”。用建模句子的方式建模表格,注定事倍功半。
为此,我们提出 Field-Aware Transformer(FAT)——在保留 Transformer 稠密计算优势的同时,注入搜推广特有的结构先验,构建一个高效、规整、可扩展的统一计算骨架:
场内感知投影:为每个字段分配独立的 Query/Key/Value 映射,天然区分语义角色;
场间调制路由:通过轻量标量权重动态调控跨字段信息流,实现细粒度、可解释的交互;
参数高效生成:采用超网络动态生成字段专属参数,支持灵活扩展,且推理时可预计算,无额外开销。
整个前向过程仅依赖规整的矩阵运算,可被高度融合,显著减少 kernel 数量与调度开销。实测 MFU 达 20% 以上,约为传统精排模型的 4–5 倍。更重要的是,在扩展至 1.5B 参数时,AUC 仍持续稳定提升,在工业级场景中展现出接近 Scaling Law 的增长行为。
FAT 的本质,是一次面向现代硬件的计算范式升级:它证明,即使面对高度异构的表格数据,只要架构设计与硬件的高吞吐、高算术强度特性对齐,并融入必要的领域约束,就能打通“算力投入 → 模型效果”的高效转化路径。
相关工作:
【FAT】From Scaling to Structured Expressivity: Rethinking Transformers for CTR Prediction(https://arxiv.org/abs/2511.12081)
【RecIS】RecIS: Sparse to Dense, A Unified Training Framework for Recommendation Models(https://arxiv.org/abs/2509.20883)
结语:从范式错位到协同进化
结语:从范式错位到协同进化
我们曾不止一次遇到这样的情况:一个模型AUC提升了0.2%,却发现MFU从8%降到了3%。这让我们意识到,单纯追求指标提升而忽视计算效率,实际上是在用昂贵的GPU执行低效任务,长期来看将制约模型的演进空间。
如今,我们有机会系统性地改变这一局面。大模型的意义,远不止于参数规模的扩张,而在于它揭示了一条普适规律:当算法、数据与硬件协同演进时,智能才能随算力投入稳定增长。
LUM 与 FAT 的实践,正是对这一协同逻辑的落地验证。它们共同构成了一个分层协同的生成式预估模型架构,打通了一条端到端的算力友好链路——底层释放学习容量,上层兑现执行效率,最终实现算力投入向业务价值的可预测转化。
通往未来的路径可能不止一条,但方向是明确的: 让每一次算力投入都可衡量,并切实转化为模型能力的提升。 这正是搜推广进入“大模型时代”的关键所在。
🏷 关于我们
阿里妈妈搜索广告预估团队专注于广告系统核心预估算法的研发与创新,致力于在超大规模场景下,运用人工智能前沿技术打造高效、精准、智能的广告预估解决方案。团队在CTR/CVR预估、序列建模、特征交叉、多模态融合及预估大模型等方向持续深耕,成果丰硕,近年来已在 NeurIPS、KDD、WWW、SIGIR等国际学术会议发表多篇论文。同时真诚欢迎对广告算法与AI技术充满热情的同学加入!
📮 简历投递邮箱:bencheng.ybc@taobao.com
END

也许你还想看
视觉感知与认知跃迁:电商多模态表征建模新范式 | 搜索广告AI大模型创新实践
阿里妈妈LMA2新进展:集成大语言模型与电商知识的通用召回大模型URM


















 963
963

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









