







背景知识
__CABAC, 是Context-Based Adaptive Binary Algorithm Coding的缩写, 意思是基于上下文的自适应算术二进制编码,是一种熵编码方法。
熵编码的概念来源于信息论。熵即信息熵,是信源平均不确定性的描述,具体物理含义有三个方面:
(1) 信息熵H(X)表示信源X每发一个符号所提供的平均信息量。
(2) 信息熵H(X)表示信源X每发一个符号前,收信者对X存在的平均不确定性。
(3) 用信息熵H(X)来表示随机变量X的随机性。
由此可见,熵编码是一种基于概率信息的信源编码方法。
编码旨在用较小的代价传递较多的信息,可用信息传输率R来衡量信源编码有效性的高低,单位是比特/码符号,其计算公式为
R
=
H
(
S
)
n
‾
R= \frac{H(S)}{\overline{n}}
R=nH(S)
其中的H(S)为信源熵,单位是比特/信源符号,其计算公式为
H
(
S
)
=
∑
i
=
1
n
P
(
a
i
)
l
o
g
1
P
(
a
i
)
=
−
∑
i
=
1
r
P
(
a
i
)
l
o
g
P
(
a
i
)
H(S) = \sum_{i=1}^{n}P(a_{i})log\frac{1}{P(a_{i})}=-\sum_{i=1}^{r}P(a_{i})logP(a_{i})
H(S)=∑i=1nP(ai)logP(ai)1=−∑i=1rP(ai)logP(ai)
其中的
n
‾
\overline{n}
n为平均码长,单位是码符号/信源符号,其计算公式为
n
‾
=
∑
i
=
1
q
p
(
s
i
)
n
i
\overline{n} = \sum_{i=1}^{q}p(s_{i})n_{i}
n=∑i=1qp(si)ni
对于给定的信源,熵值H(S)是给定的,则信息传输率R只与平均码长
n
‾
\overline{n}
n有关。平均码长越大,R越小;平均码长越小,信息传输率R越大。为了使平均码长尽可能小,需要合理搭配码字长度
n
i
n_{i}
ni和先验概率
p
(
s
i
)
p(s_{i})
p(si),即用较小的码长表示较大的概率,用较大的码长表示较小的概率。合理搭配的先验概率在CABAC中具体表现为不同语法元素基于上下文采用的不同概率模型。
算术编码
__算术编码没有采用传统的单符号映射编码方式,而是将输入的所有符号依据概率映射到[0,1]内的一个小区间上,并从中取一个小数作为编码输出。
以算术二进制编码为例说明:假设信源的先验概率为P(“0”) = 0.7,P(“1”) = 0.3,且概率值不变,则比特串”0110“的编码输出是什么?
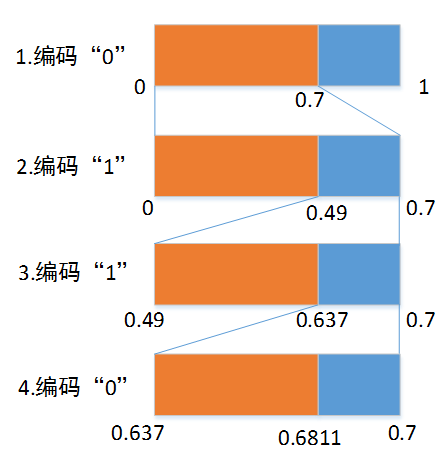
__如图所示,橙色块表示P(“0”) = 0.7,蓝色块表示P(“1”) = 0.3,分别对应MPS(大概率符号)和LPS(小概率符号)。每个步骤中,橙色块的左边界值表示Low,橙色块和蓝色块的宽度范围表示Range。每两步之间的范围缩放表示归一化过程。编码输出通常是Low值,此例中是0.637。初始Low为0,初始Range为1。
算术编码是单义可译码,从码流中可解得唯一的结果。解码过程如下:
(1) 初始化:Low为0,Range为1;
(2) 逆归一化(先减去Low,再除以Range,下同):(0.637-0)/1 = 0.637,由于0.637在[0, 0.7)之间,则解码的第一个比特为”0“,Low仍为0,Range更新为0.7;
(3) 逆归一化:(0.637-0)/0.7 = 0.91, 由于0.91在[0.7, 1)之间,则解码的第二个比特为”1“,Low更新为0+0.70.7=0.49,Range更新为0.70.3=0.21;
(4) 逆归一化:(0.637-0.70.7)/0.21 = 0.7,由于0.7在[0.7, 1)之间,则解码的第三个比特为”1“,Low更新为0.49+0.210.7=0.637,Range更新为0.21*0.3=0.063;
(5) 逆归一化:(0.637-0.637)/0.063 = 0, 由于0在[0, 0.7)之间,则解码的第四个比特为”0“。
解码中,
逆归一化公式:Bit_range = (output – Low_old) / Range_old
Low的更新公式(仅在LPS出现时):Low_new = Low_old + Range_old * P(MPS)
Range的更新公式:Range_new = Range_old * P(current_symbol)
二值化
熵编码之指数哥伦布编码
https://blog.csdn.net/SoaringLee_fighting/article/details/78178405
CABAC
ctx模型及相关函数
__类ContextSetCfg里定义了所有的语法元素以及获取ctx模型的函数。
类CtxSet可用于存放ctx模型的偏移值(相对于整个ctx表)和个数。
函数addCtxSet将ctx模型的配置值赋给语法元素,有428个ctx模型( unsigned 8bit)。
函数getInitTable初始化整个ctx表,根据sliceType,初始化B帧、P帧、I帧的ctx模型,以及多假设概率模型的WinSize。
ctx模型初始化
函数 BinProbModel_Std()
m_state[0] = 1<<14
m_state[1] = 1<<14
m_rate = 8
函数 BinProbModel_Std::init()
功能:获得m_state[0]和m_state[1]
输入:qp,initId(B/P/I帧的ctx模型,无符号8bit)
处理过程:
slope = initId>>4 * 5 – 45 (取initId的高4bit,乘以5再减45或表述为减9再乘以5)
offset = (initId & 15) << 3 -16 (取initId的低4bit,乘以8再减16或表述为减2再乘以8)
inistate = (slope * qp) >> 4 + offset (这几步计算和h.264的相似)
p1 = m_inistateToCount[inistate] (inistate的取值限制在[0,127]范围内)
m_state[0] = p1 & MASK_0 (MASK_0=32736,二进制为(11 11 11 11 11 00 00 0))
m_state[1] = p1 & MASK_1 (MASK_0=32766,二进制为(11 11 11 11 11 11 11 0))
(h.266采用的是多概率假设模型,以上为其初始化过程)
函数setLog2WindowSize
功能:获得m_rate(8bit)
输入:log2WindowSize(每个ctx固有的WinSize, 4bit数)
处理过程:
rate0 = 2 + (log2WindowSize >> 2) & 3) //取高2bit计算,值在2~5之间
rate1 = 3 + rate0 + (log2WindowSize & 3) //取低2bit计算,值在5~9之间
m_rate = 16 * rate0 + rate1
异常条件:
rate1 > 9,则报错第二个窗口尺寸过大。WinSize的值小于等于13。
使用rate0和rate1时,根据m_rate得到:
rate0 = m_rate >> 4, rate1 = m_rate & 15
编码引擎初始化
函数 BinEncoderBase::start()
m_Low = 0; //左端点初始化为0
m_Range= 510; //区间初始化为510 (9bit)
m_bufferedByte= 0xff; //缓存low值高位待输出的单个字节,逢进位需加1再输出
m_numBufferedBytes= 0; //表示low值高位待输出的字节数
m_bitsLeft = 23; //表示low值中空着待用的bit长度,初始值为23
//m_Low的bit长度加上m_bitsLeft的值为32
BinCounter::reset(); //NumBinsCtx、NumBinsEP、NumBinsTrm均置零
m_BinStore. reset(); //binBuffer清零
函数 BinEncoderBase::restart()
m_Low = 0;
m_Range = 510;
m_bufferedByte = 0xff;
m_numBufferedBytes = 0;
m_bitsLeft = 23;
CABAC内核
普通编码:函数encodeBin()
__功能:编码单个regular bin,常规bin
输入:bin值,ctxId(ctx表中的位置索引,得到相应的m_state0, m_state1, m_rate)
bin值可能是概率模型的LPS或MPS,下面分情况讨论(涉及到的函数在后面说明)
计算LPS的range,调用函数getLPS()得到;
计算MPS的range,等于m_Range减去LPS的range;
(1) bin值等于LPS
计算LPS的range重归一化的bit数numBits,调用getRenormBitsLPS()得到(返回m_RenormTable_32[LPS>>3],table表见附录);
更新m_bitsLeft,等于原值减去numBits;
更新m_Low,等于原值加上MPS的range,再左移numBits;
更新m_Range,等于LPS的range左移numBits;
输出判断,若m_bitsLeft小于12,调用函数writeOut()输出。
(2) bin值等于MPS
如果m_Range大于256:
m_bitsLeft不需要更新;
m_Low不需要更新;
m_Range即计算得到的MPS的range。
如果m_Range小于256:
计算range重归一化的bit数numBits,调用getRenormBitsRange()得到(返回值为1);
更新m_bitsLeft,等于原值减去numBits;
更新m_Low,等于原值左移numBits;
更新m_Range,等于原值左移numBits;
输出判断,若m_bitsLeft小于12,调用函数writeOut()输出。
(3) 更新ctx模型
调用函数update()。
旁路编码:函数encodeBinEP()
__功能:编码单个bypass bin,旁路bin
输入:bin值
更新m_Low,将原值左移一位,若bin值为1,则m_Low等于移位后的值加上m_range;
更新m_bitsLeft,将原值减1;
输出判断,若m_bitsLeft小于12,调用函数writeOut()输出。
旁路编码:函数encodeBinsEP()
__功能:编码多个bypass bins,旁路bin
输入:多个bin值,bin的个数(以下简称bin数)
若m_Range等于256,调用函数encodeAlignedBinsEP()编码,并结束;
当bin数大于8时:
更新m_Low,先将m_Low左移8位,再加上m_Range乘以bins的高8位;
更新m_bitsLeft,将原值减8;
更新bins,将bins的高8位去掉;
更新bin数,将原值减8;
判断输出,若m_bitsLeft小于12,调用函数writeOut()输出;
不满足条件时,跳出该循环。
更新m_Low,先将m_Low左移bin数位,再加上m_Range乘以bins;
更新m_bitsLeft,将原值减去bin数;
输出判断,若m_bitsLeft小于12,调用函数writeOut()输出。
旁路编码:函数encodeAlignedBinsEP()
__功能:在m_Range等于256时,编码多个bypass bins
输入:多个bin值,bin的个数(以下简称bin数)
实现过程与encodeBinsEp()类似,只是已知m_Range等于256,所以m_Low的更新不需要通过m_Range乘以bins计算,直接用bins左移8位即可表示。
本函数实际上是对encodeBinsEp()的代码优化,由于移位比乘法运算复杂度低,可以减少软件运行时间。
Terminate编码:函数BinEncoderBase::encoderBinTrm
__功能:Terminal bin,在1个CTU结束后编码单个“0”,在1个slice结束后编码单个“1”(类似H.264中的final编码和terminate编码)
输入:单个bin值
计算MPS的range,LPS的range固定为2,故MPS的range为m_Range减2;
若bin值为1:
更新m_Low,将原值加上MPS的range,再左移7位;
更新m_Range,等于2左移7位;
更新m_bitsLeft,将原值减7。
若bin值为0:
若m_Range大于等于256,结束;
否则:
更新m_Low,将原值左移1位;
更新m_Range,将原值左移1位;
更新m_bitsLeft,将原值减1.
输出判断,若m_bitsLeft小于12,调用函数writeOut()输出。
结束编码:函数BinEncoderBase::finish()
__功能:一个slice结束后需调用此函数收尾。
如果有进位:
调用write()输出m_bufferedbyte+1;
当m_numBufferedBytes大于1时,调用函数write()输出0x00,m_numBufferedBytes减1,直到条件不满足,跳出循环;
更新m_Low,将原值减去其左移(32减m_bitsLeft)后的值;
否则(无进位):
若m_numBufferedBytes大于0,调用函数write()输出m_bufferedbyte;
当m_numBufferedBytes大于1时,调用函数write()输出0xff, m_numBufferedBytes减1,直到条件不满足,跳出循环;
调用函数write(),将(m_Low右移8位)和(24减m_bitsLeft)作为输入参数。
函数getLPS()
__功能:计算LPS的range。
输入:range, state[0], state[1] //ctx模型的内容不通过函数接口传入,是全局变量
q = (m_state[0] + m_state[1]) >> 8 //m_state取值范围为15bit,故q的值小于255
若q的值大于等于128,则q = q ^ 0xff(相当于将q按位取反,且取值在127内)。
返回值等于 ( ( q >> 2 ) * ( range >> 5 ) >> 1 + 4
q为7bit,range为9bit,则返回值为一个8bit数加上4,是否会超出8bit待查。
函数write()
__功能:输出函数,调用一次最多输出32bit,且每次以8bit为单位输出。
输入:bins,bin数
将输入bins与之前尚未输出的剩余bins拼接到一起。若拼接后的bin数大于8个,则按照从左到右的顺序以8bit为单位输出,否则不输出。然后用全局变量记录不足8bit的bins及其个数,用于下一次地输出。
函数writeout()
__功能:将CABAC编码结果写入码流。
输入:全局变量m_Low, m_bitsLeft, m_bufferedByte和m_numBufferedBytes
得到leadByte,将m_Low的高8bit(或9bit)赋给leadByte;
更新m_Low,等于原值除去高8bit(或9bit)的剩余值;
如果:
leadByte等于0xff,则m_numBufferedBytes加1,暂不输出;
否则:
如果m_numBufferedBytes大于零,则:
计算carry(进位)值,将leadByte右移8位,将该值赋给carry;
计算临时变量byte并输出到码流,等于m_bufferedByte(缓存了上一个leadByte的值)加carry;
当m_numBufferedBytes满足大于1的条件时:
carry为1的话,输出1字节的0x00,;否则,输出1字节的0xff;
m_numBufferedBytes的值减1;
条件不满足时跳出循环。
(进位可能导致前面连续若干个byte的0xff的值变为0)
否则:
m_numBufferedBytes等于1;
m_bufferedByte等于leadByte。
函数update()
__功能:更新ctx模型。
输入:bin值,m_rate
rate0 = m_rate >> 4
rate1 = m_rate & 15
m_state[0] = m_state[0] – ( (m_state[0] >> rate0) & MASK_0)
m_state[1] = m_state[1] – ( (m_state[1] >> rate1) & MASK_1)
如果bin值等于1
m_state[0] = m_state[0] + ( (0x7fffu >> rate0) & MASK_0)
m_state[1] = m_state[1] + ( (0x7fffu >> rate1) & MASK_1)
附录
数组m_inistateToCount
const uint16_t ProbModelTables::m_inistateToCount[128] = {
614,647,681,718,756,797,839,884,
932,982,1034,1089,1148,1209,1274,1342,
1414,1490,1569,1653,1742,1835,1933,2037,
2146,2261,2382,2509,2643,2785,2934,3091,
3256,3430,3614,3807,4011,4225,4452,4690,
4941,5205,5483,5777,6086,6412,6755,7116,
7497,7898,8320,8766,9235,9729,10249,10798,
11375,11984,12625,13300,14012,14762,15551, 16384,
16384,17216,18005,18755,19467,20142,20783,21392,
21969,22518,23038,23532,24001,24447, 24869,25270,
25651,26012,26355,26681,26990,27284,27562,27826,
28077,28315,28542,28756,28960,29153, 29337,29511,
29676,29833,29982,30124,30258,30385,30506,30621,
30730,30834,30932,31025,31114,31198, 31277,31353,
31425,31493,31558,31619,31678,31733,31785,31835,
31883,31928,31970,32011,32049,32086, 32120,32153
};
ctx初始表
const CtxSet ContextSetCfg::SplitFlag = ContextSetCfg::addCtxSet
({
// |-------- do split ctx -------------------|
{ 122, 124, 141, 108, 125, 156, 138, 126, 143, }, // B帧
{ 93, 139, 171, 124, 125, 141, 139, 141, 158, }, // P帧
{ 138, 154, 172, 124, 140, 142, 154, 127, 175, }, // I帧
{ 9, 13, 8, 8, 13, 12, 5, 10, 12, }, // WinSize
});
LPS重归一化表
const uint8_t ProbModelTables::m_RenormTable_32[32] =
{
6, 5, 4, 4,
3, 3, 3, 3,
2, 2, 2, 2,
2, 2, 2, 2,
1, 1, 1, 1,
1, 1, 1, 1,
1, 1, 1, 1,
1, 1, 1, 1
};
小结:6(1),5(1),4(2),3(4),2(8),1(16),括号内为前面数值在表中的个数。















 1245
1245











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









