






使用旷世的cvpods框架,环境部署在云端,然后在本地的pycharm下进行debug。
目录
2. cvpods/engine/launch.py --- (对分布式训练进行初始化设置)
6. cvpods/data/datasets/coco.py
7 . cvpods/data/base_dataset.py
2) filter_images_with_only_crowd_annotations
3) print_instances_class_histogram
10. cvpods/modeling/backbone/resnet.py
11. cvpods/modeling/backbone/fpn.py
1. 传入参数的设定 argparse.ArgumentParser:
1) resnet backbone的创建 ------ 来源于cvpods库
一、 前提准备
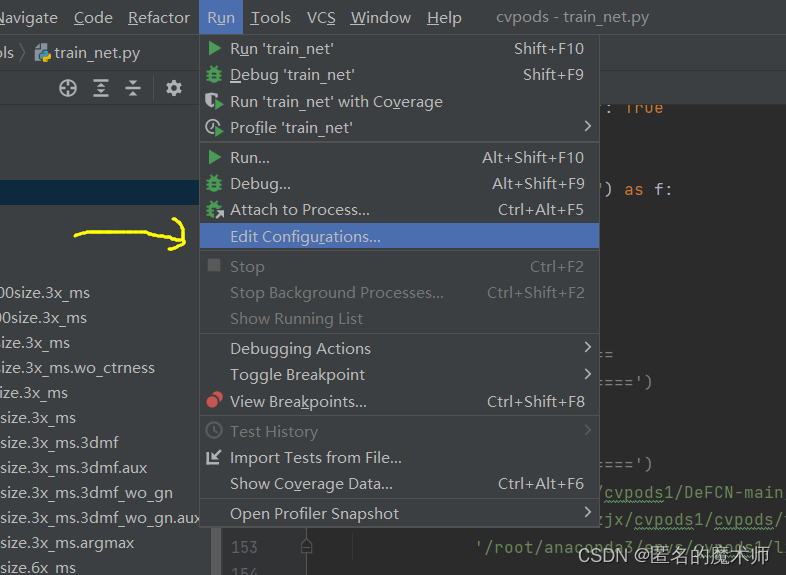
在终端直接运行训练时是在DeFCN下对应实验的config文件下,直接运行的,如下:
pods_train --num-gpus 1 --dir ~/data/zjx/cvpods1/DeFCN-main/playground/detection/coco/poto.res50.fpn.coco.800size.3x_ms.3dmf要想在本地pychram下直接debug需要设置一下。配置一下config,就是输入的参数 --dir
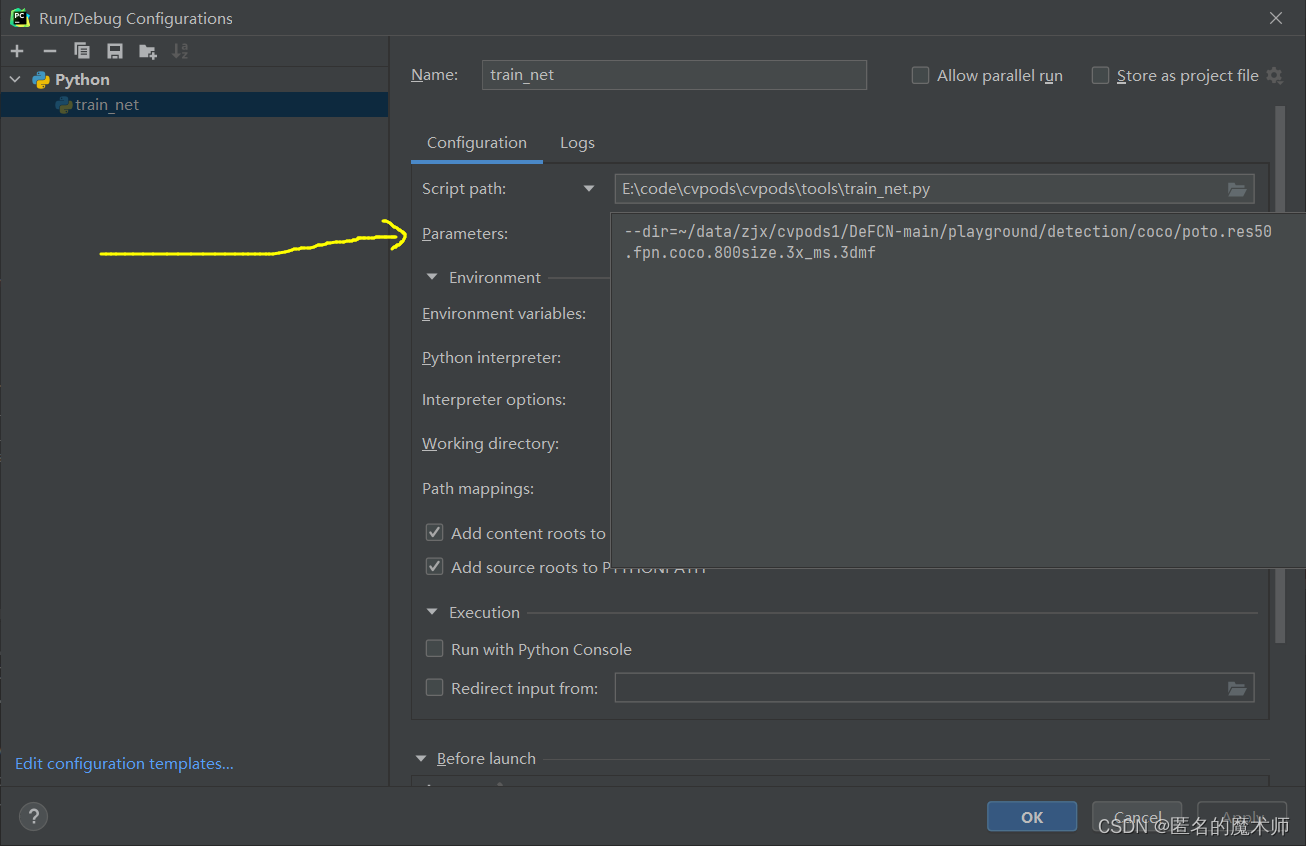
添加环境变量 PYTHONPATH = '路径--之前的DeFCN的config文件路径'
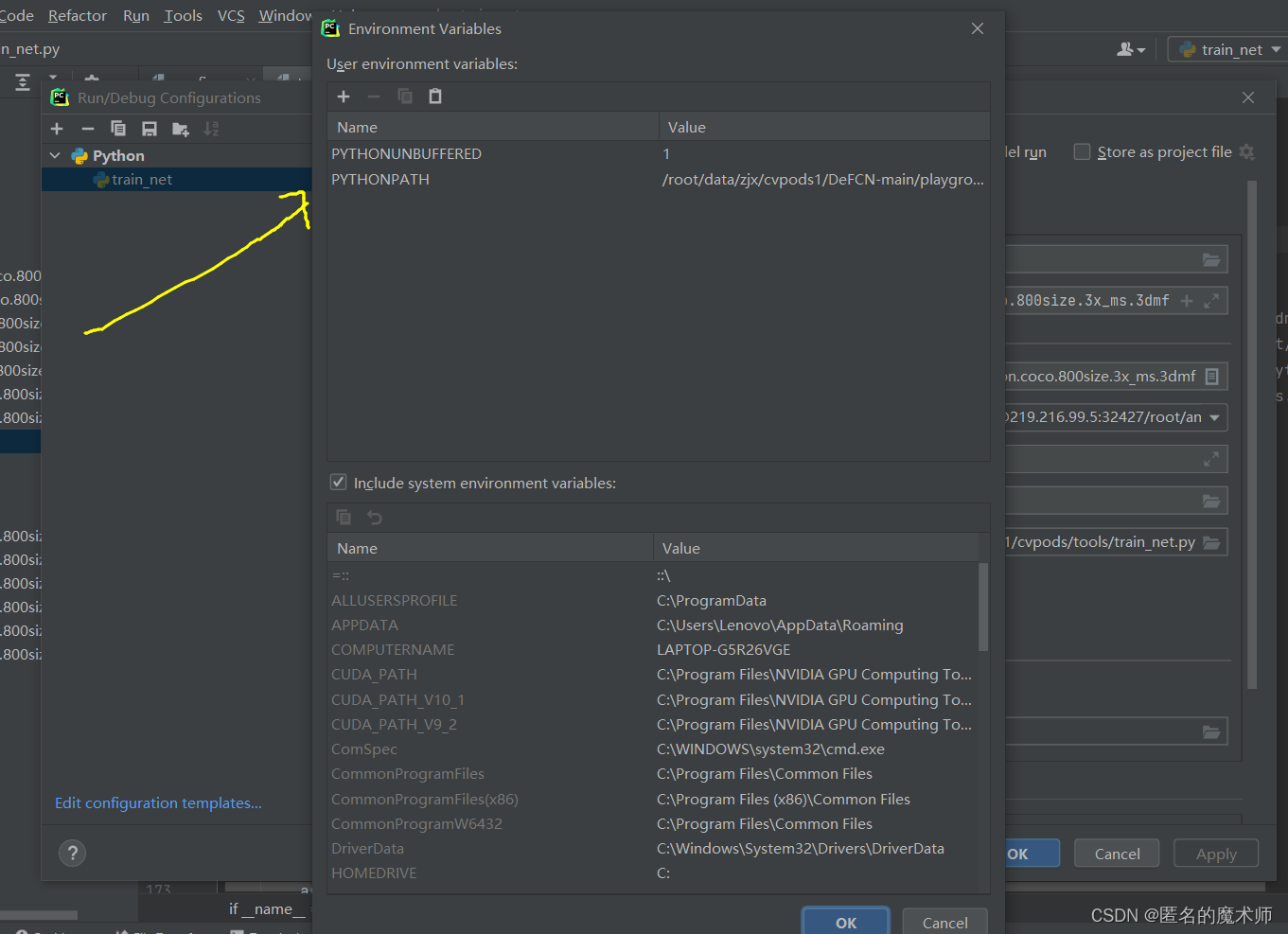
ok,完成。
中间遇到的问题
pydev debugger: warning: trying to add breakpoint to file that does not existdebug过程中卡顿
二、 Debug记录
1. train_net.py
args

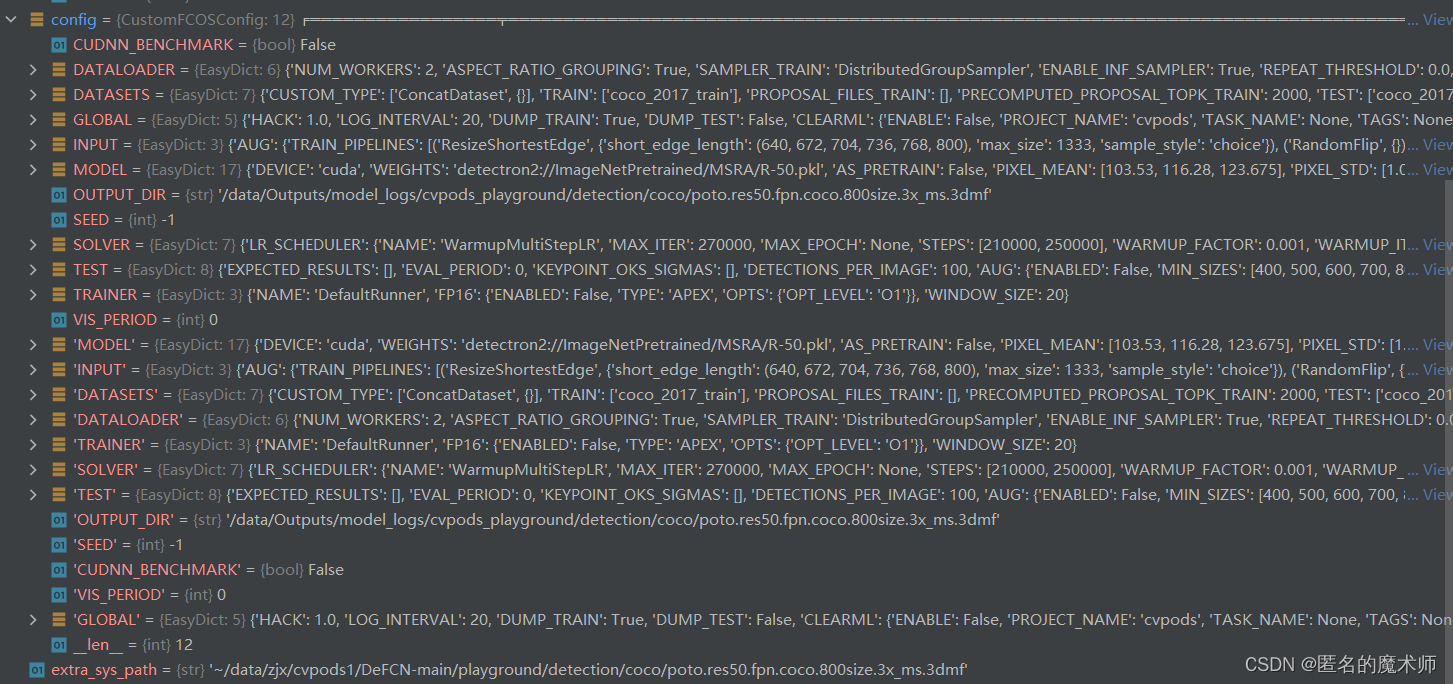
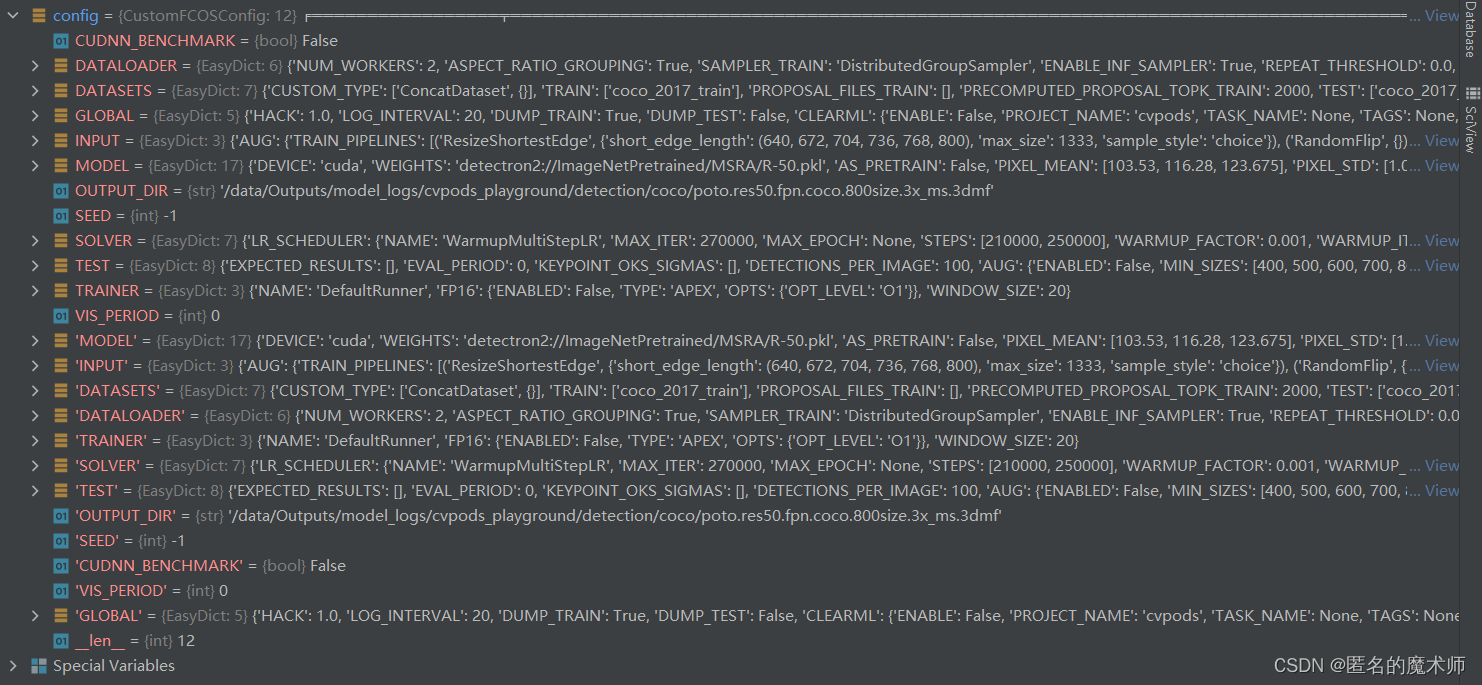
config
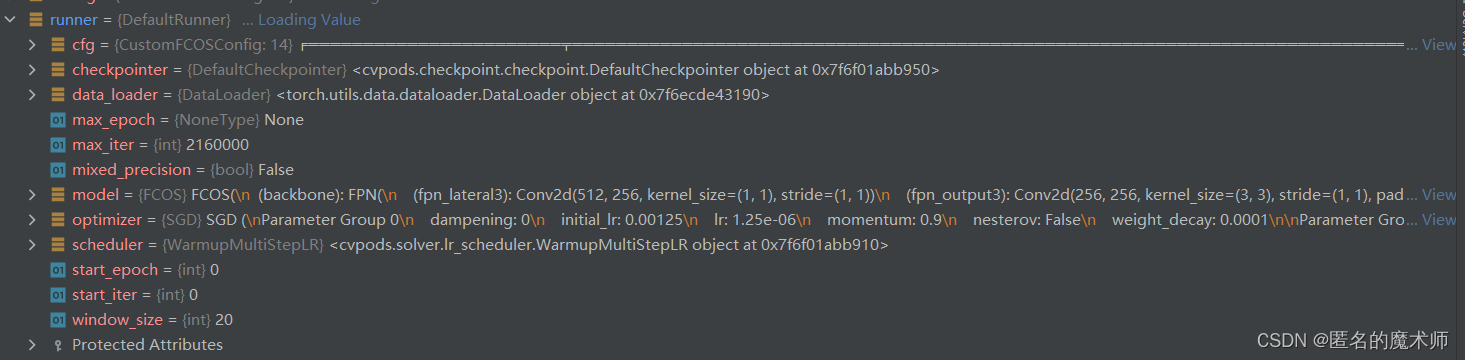
runner
2. cvpods/engine/launch.py --- (对分布式训练进行初始化设置)
args


1) main
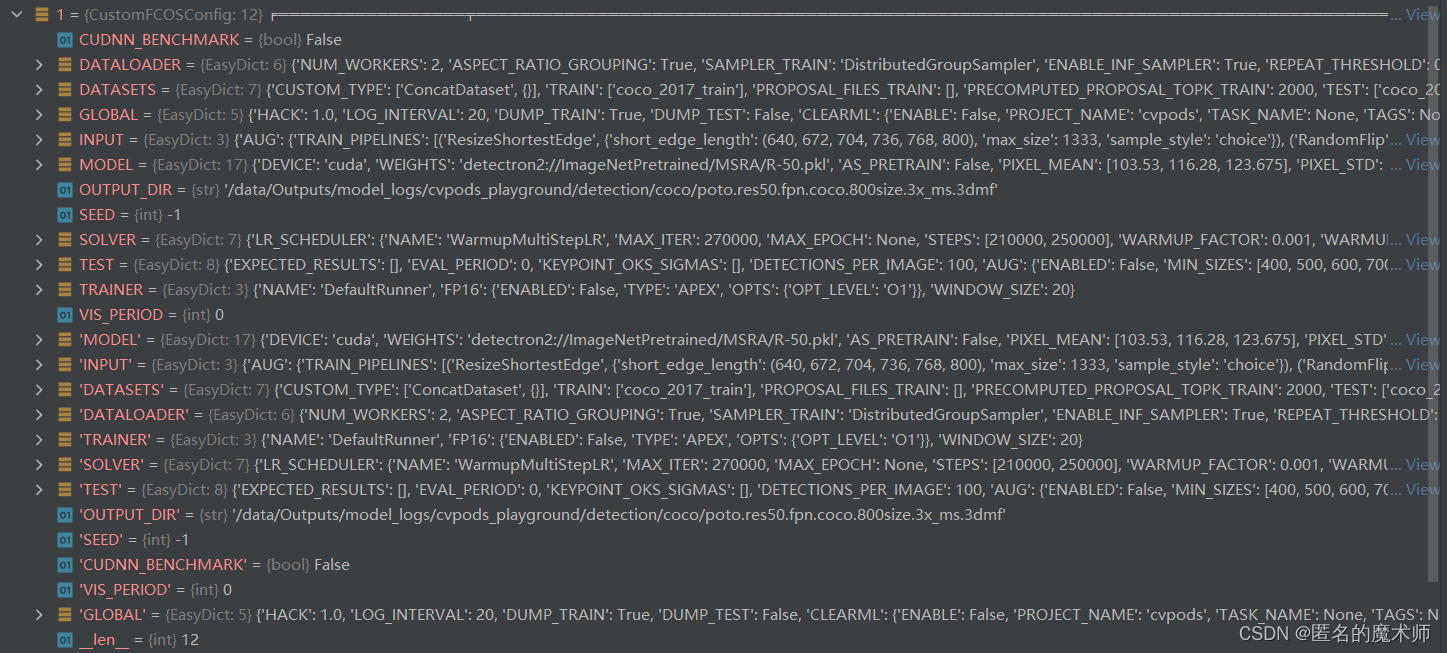
config

3. cvpods/engine/setup.py
1)default_setup
args

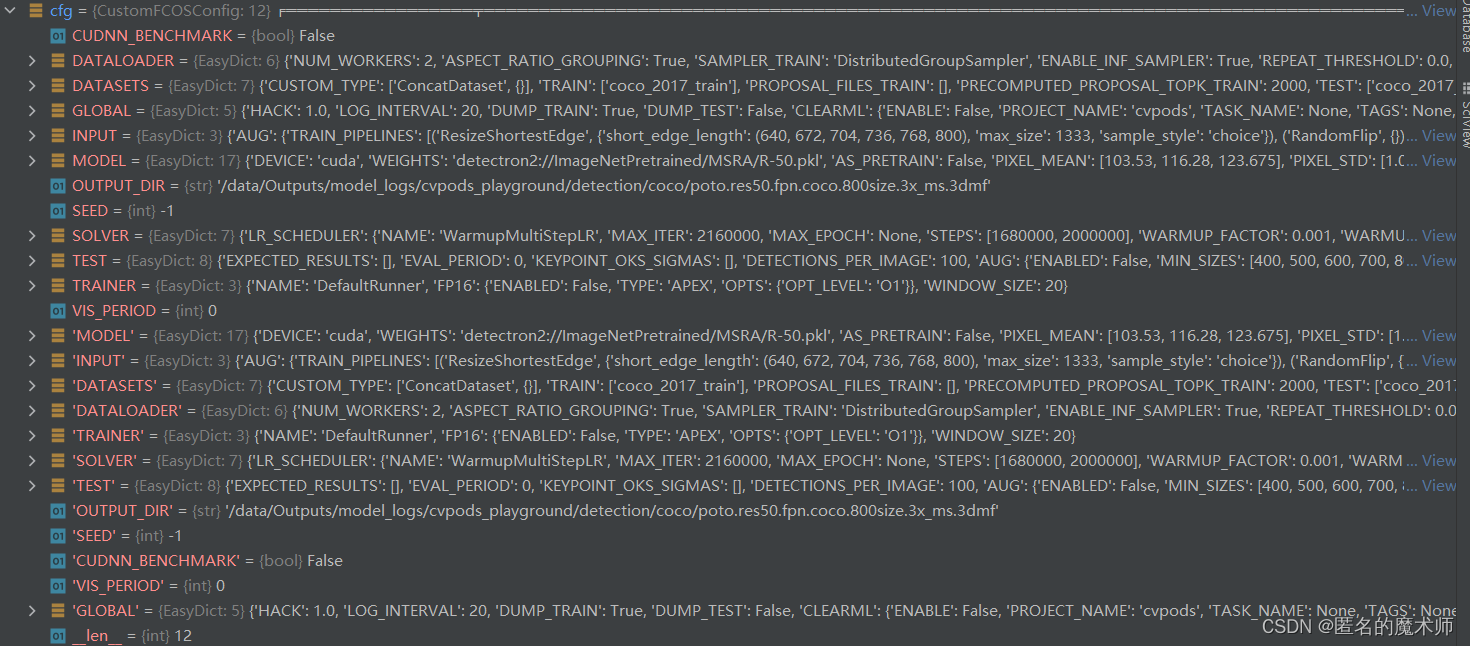
进行config调整后 cfg
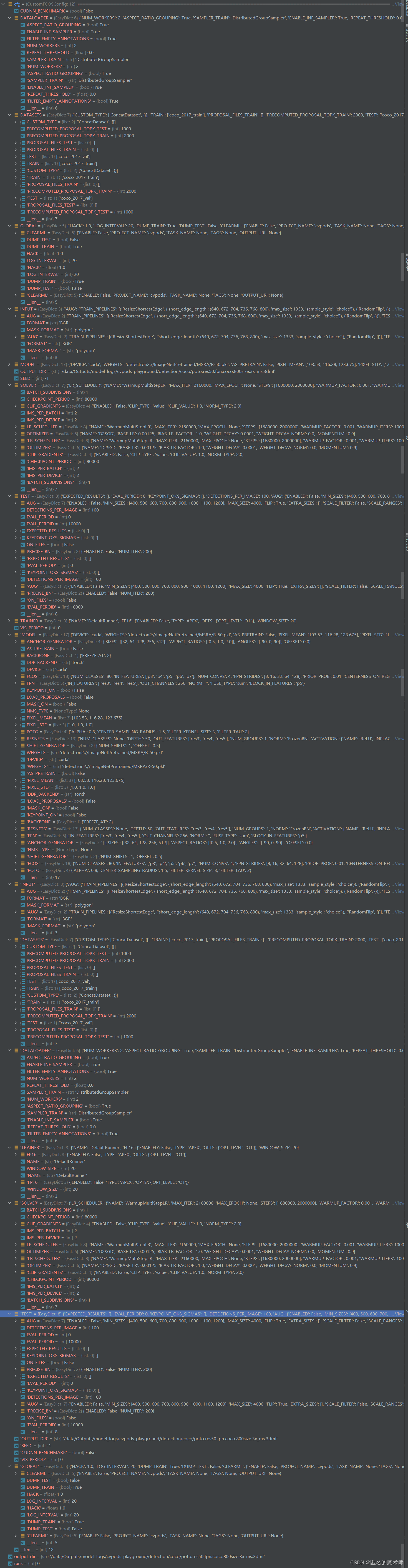
4. cvpods/engine/runner.py
1) __init__
self

2)
5. cvpods/data/build.py
1) build_transform_gens
tfm_gens

2) build_dataset
dataset--(_build_single_dataset返回的)
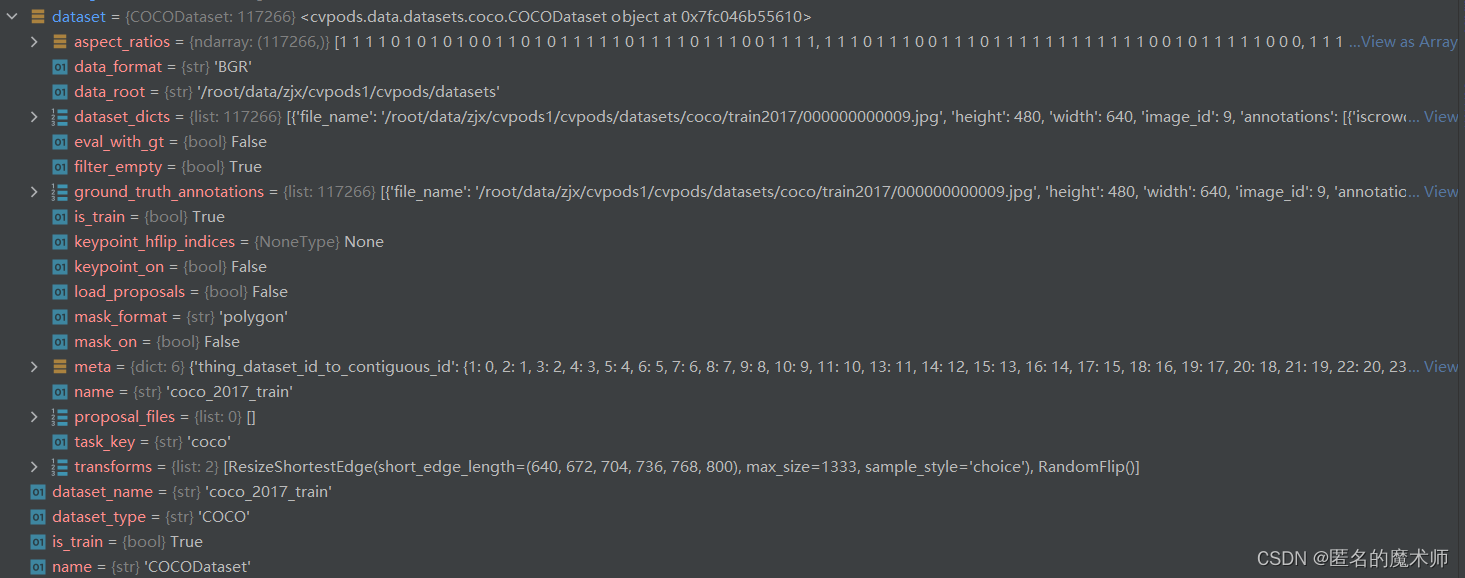
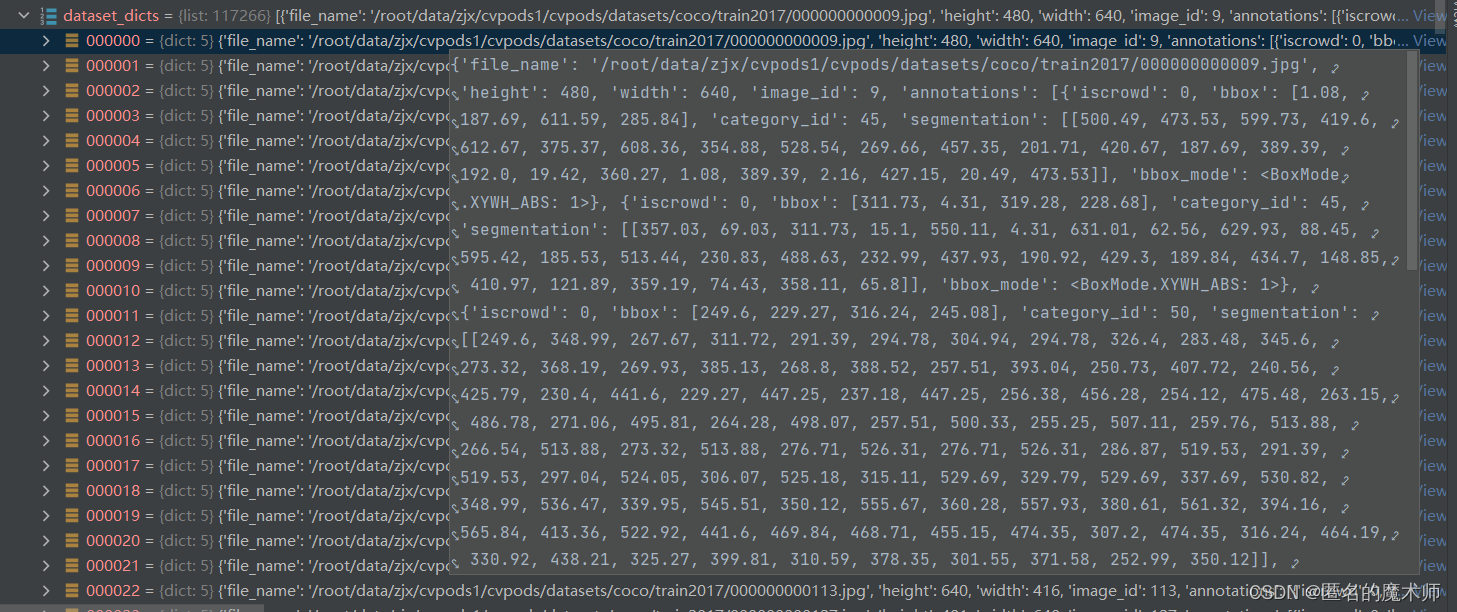
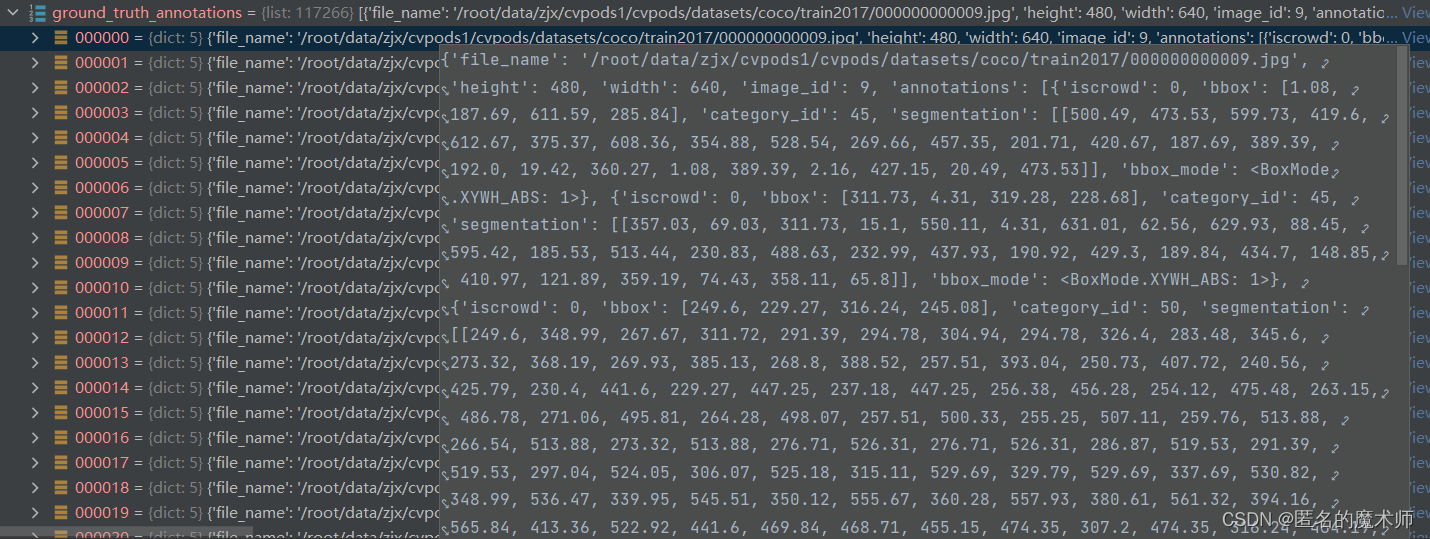
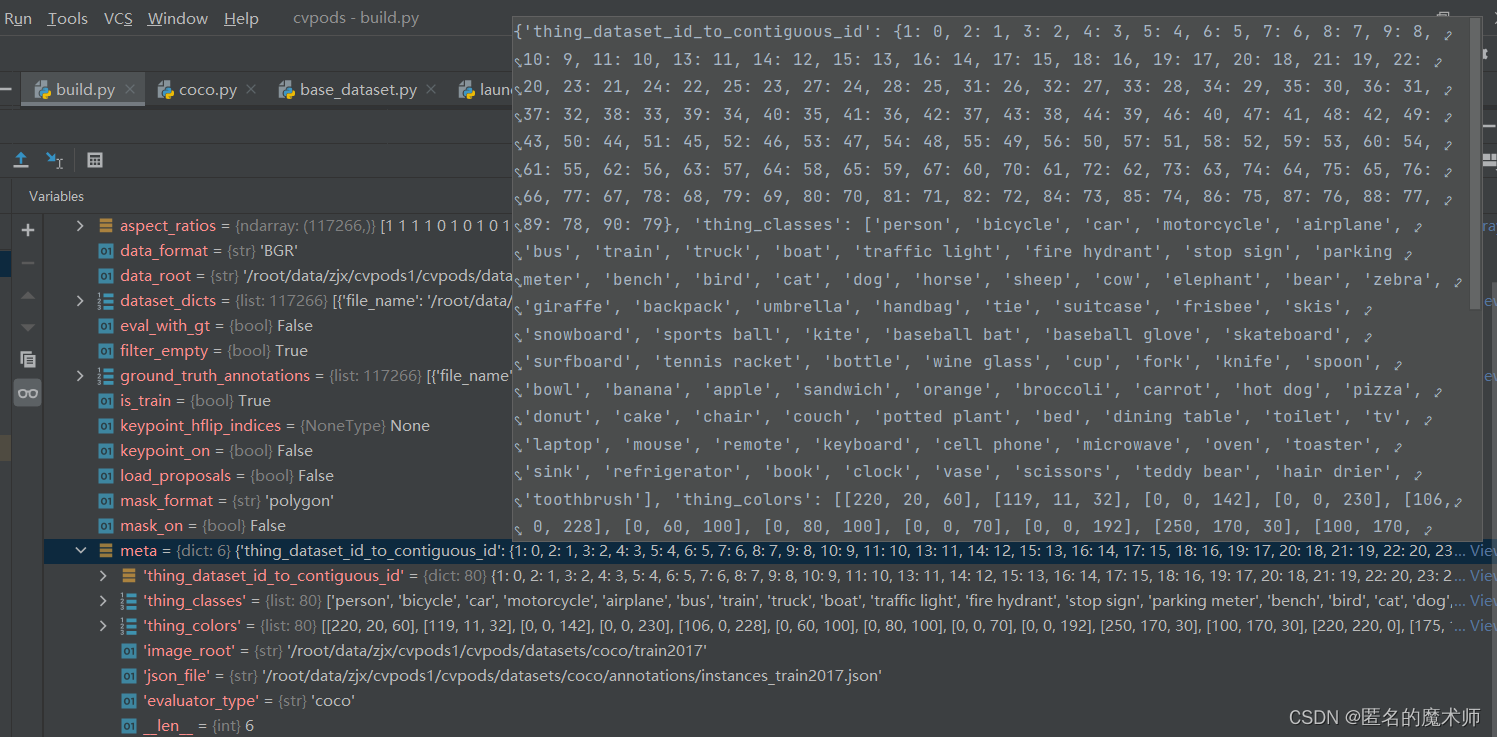
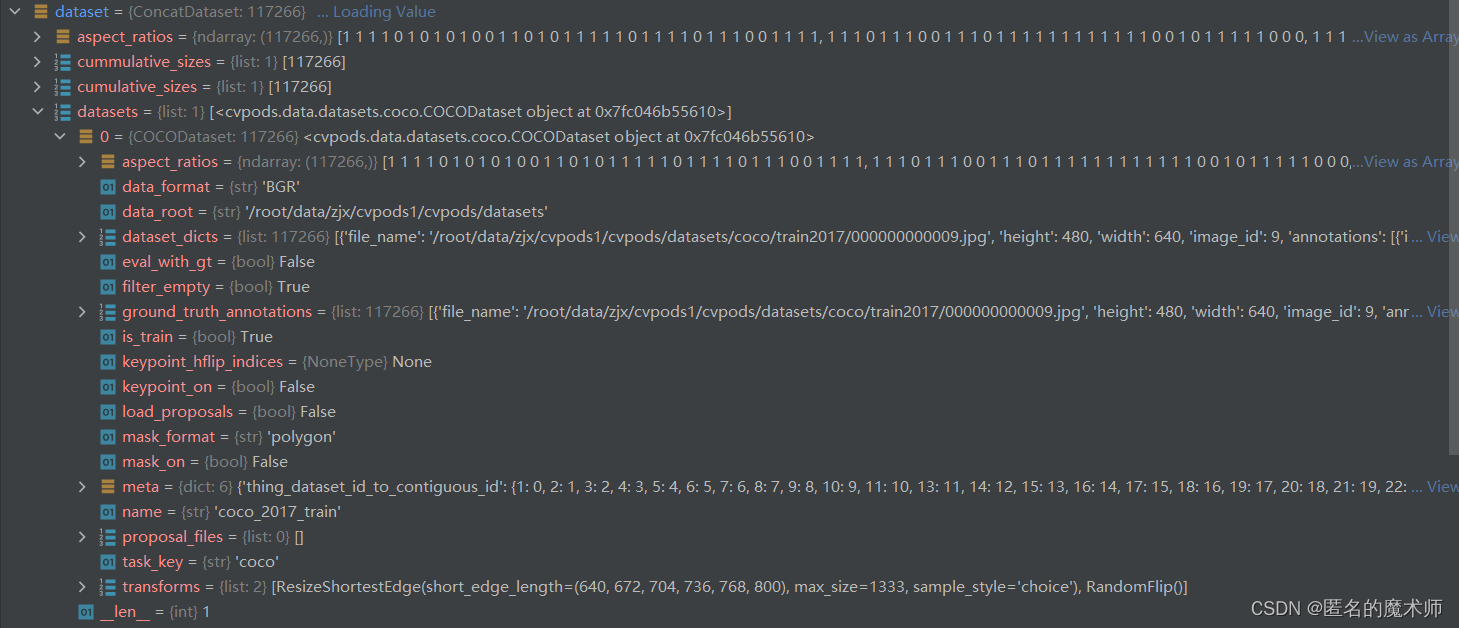
dataset ---(最终返回的)

3) build_train_loader
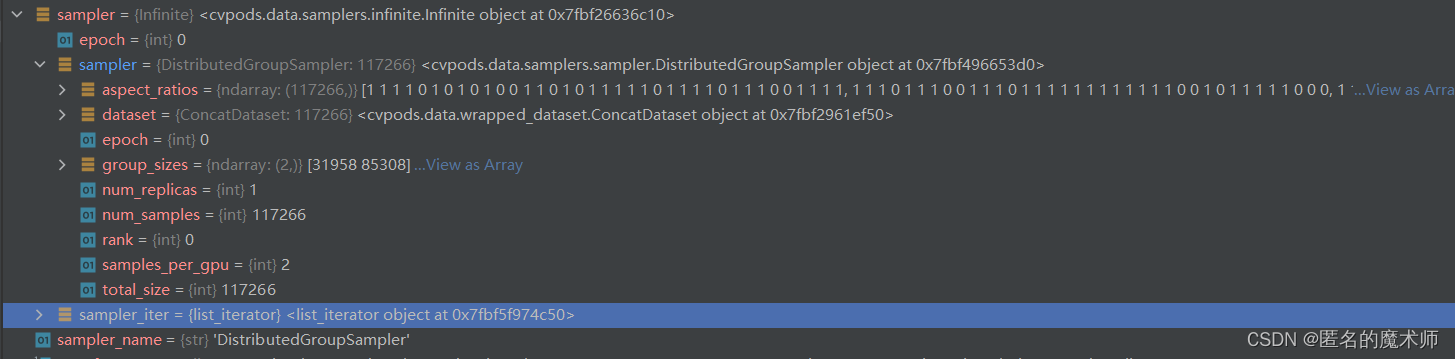
sampler (经过DDP)

sampler (经过包装器)
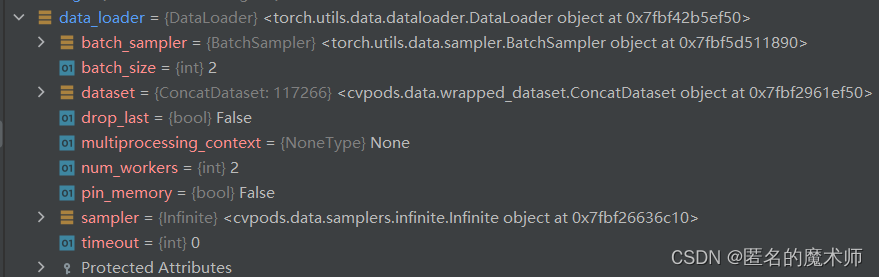
data_loader
6. cvpods/data/datasets/coco.py
1) _get_coco_instance_meta
thing_ids


thing_color

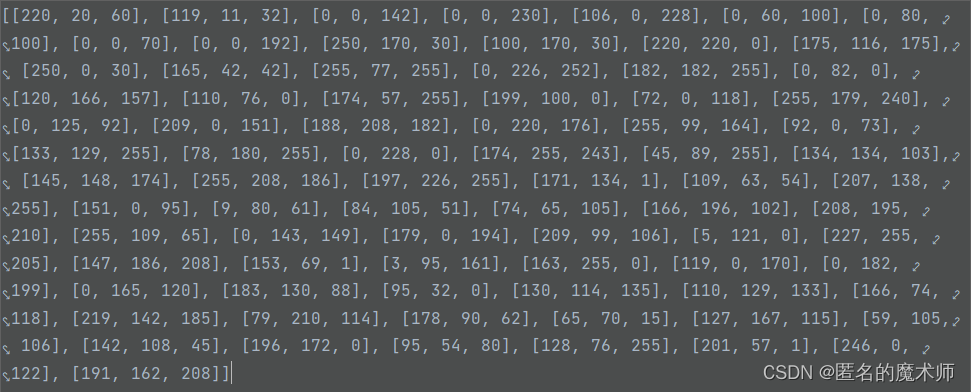
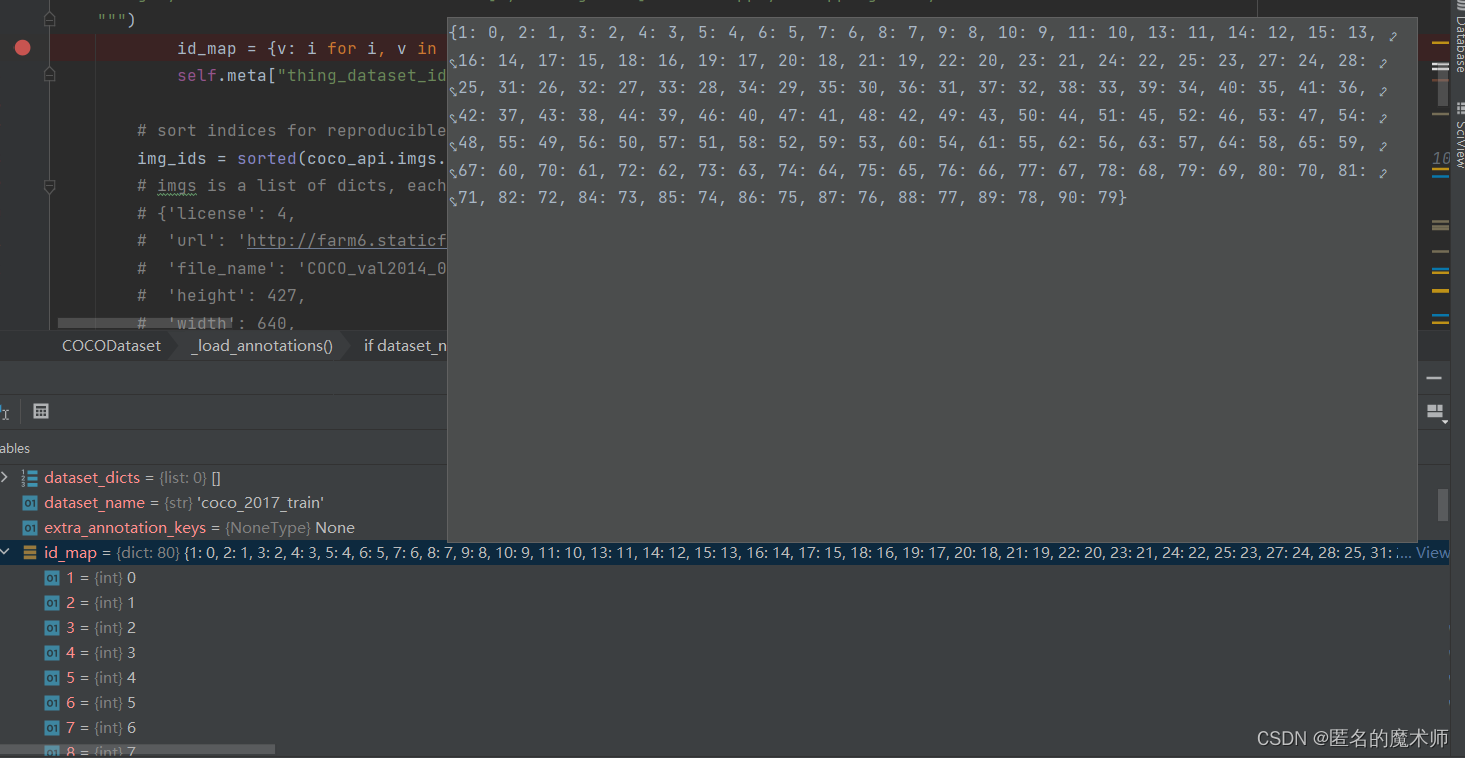
thing_dataset_id_to_contiguous_id

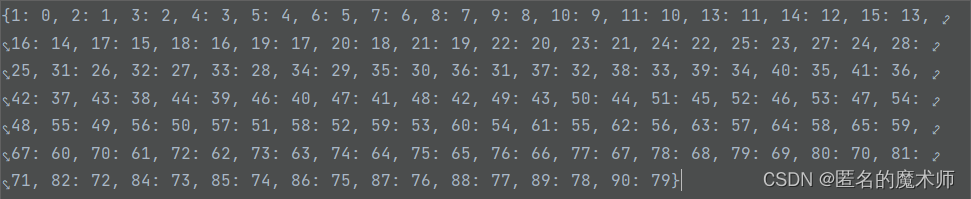
thing_classes

2) _get_metadata
meta (具体见其来源函数的内部,及上面 1) 这部分)

写入一些路径后

3) _load_annotations
coco_api

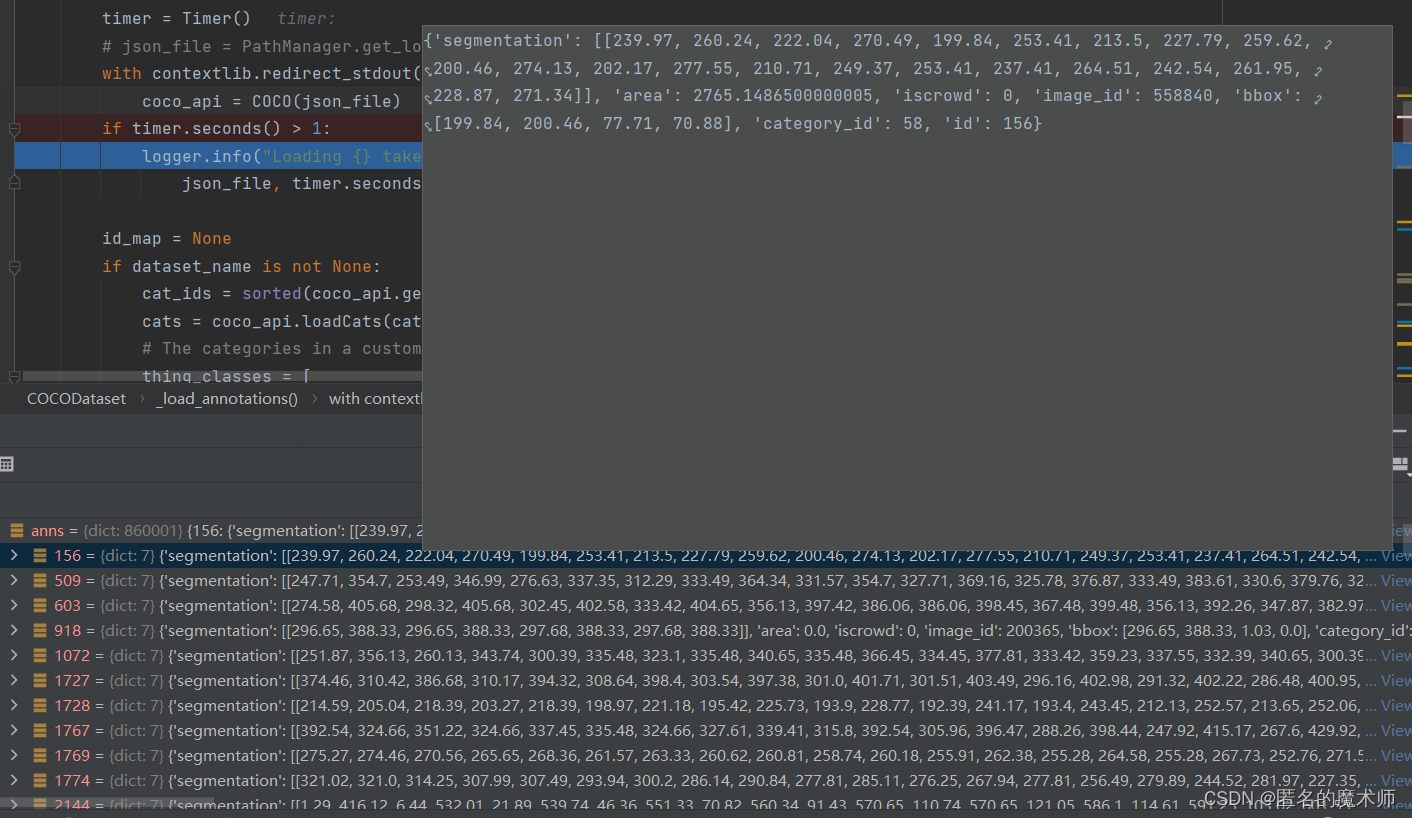



cat_ids
cats
thing_classes
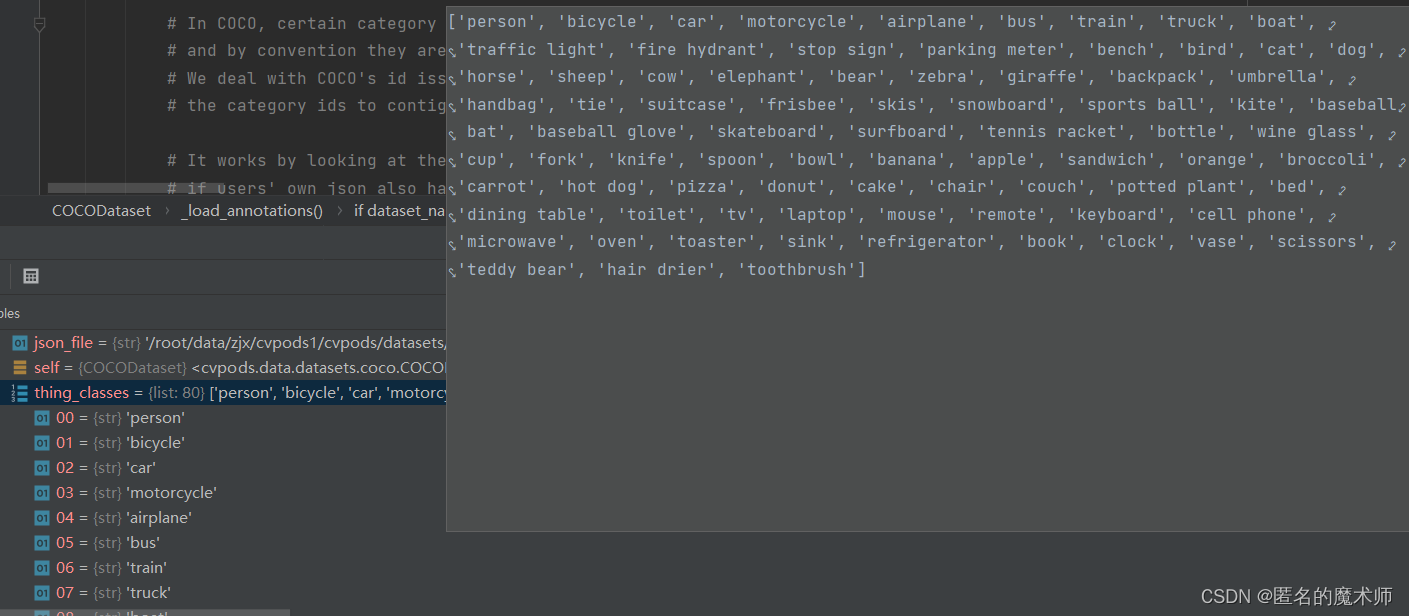
id_map
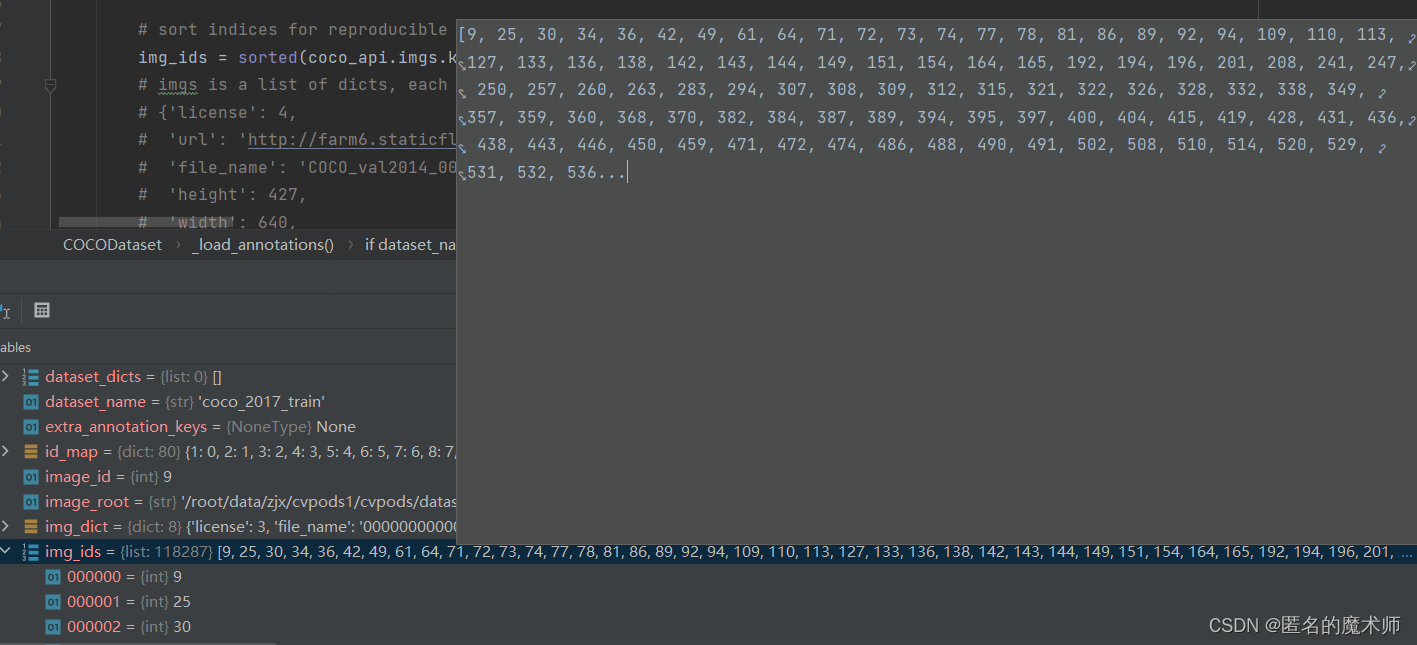
img_ids
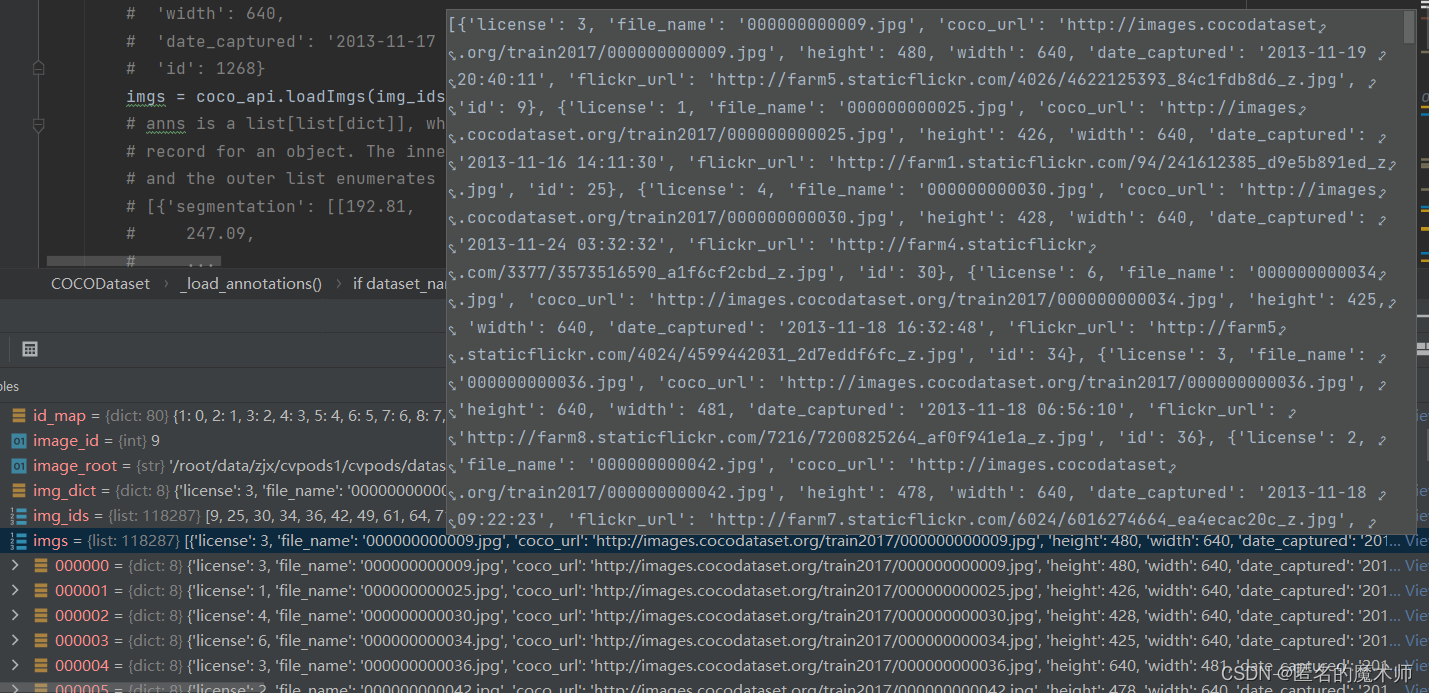
imgs
anns
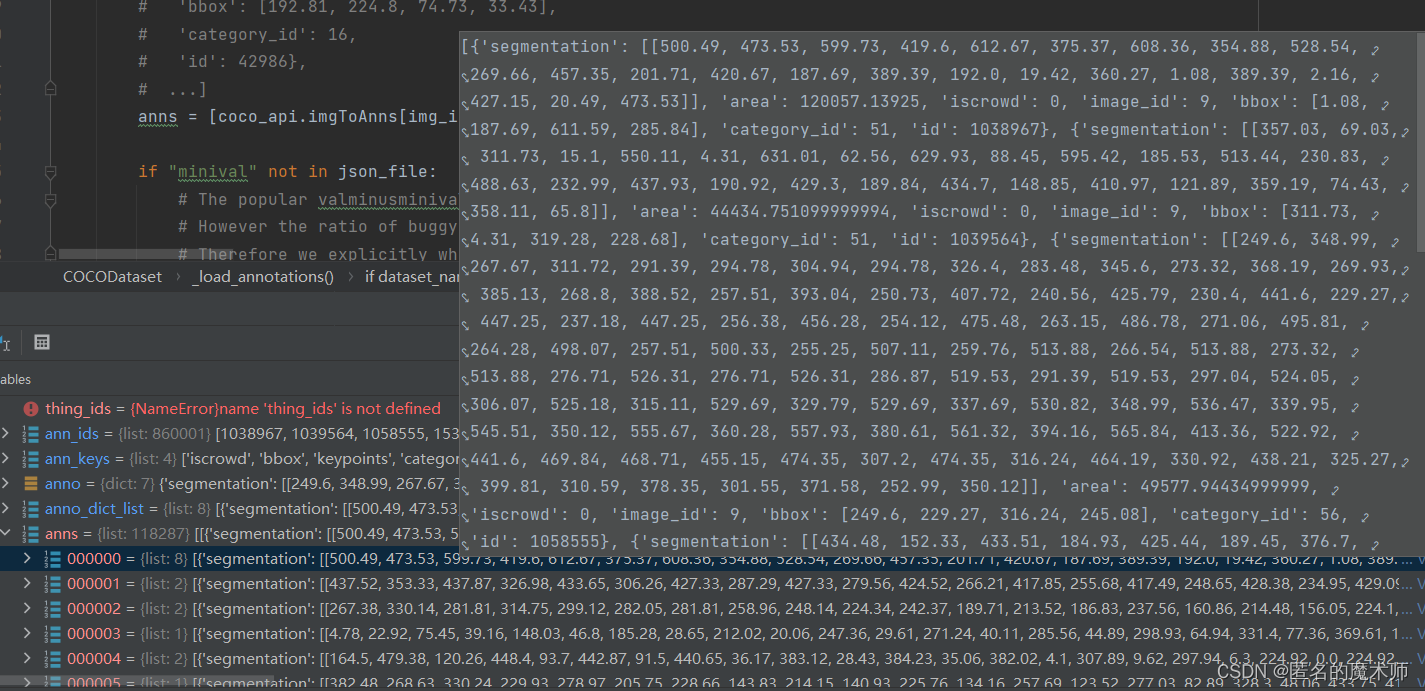
ann_ids
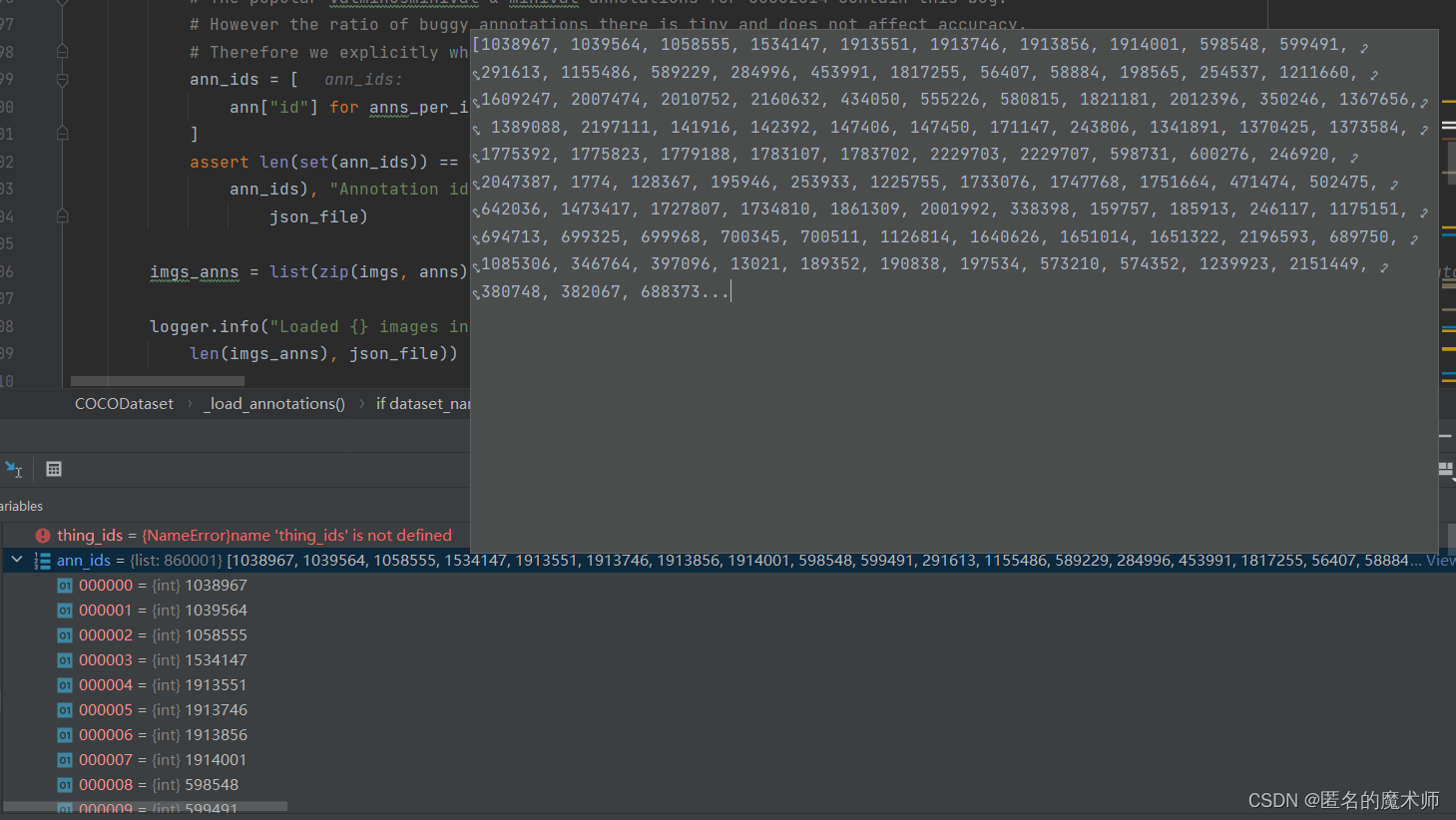
img_anns

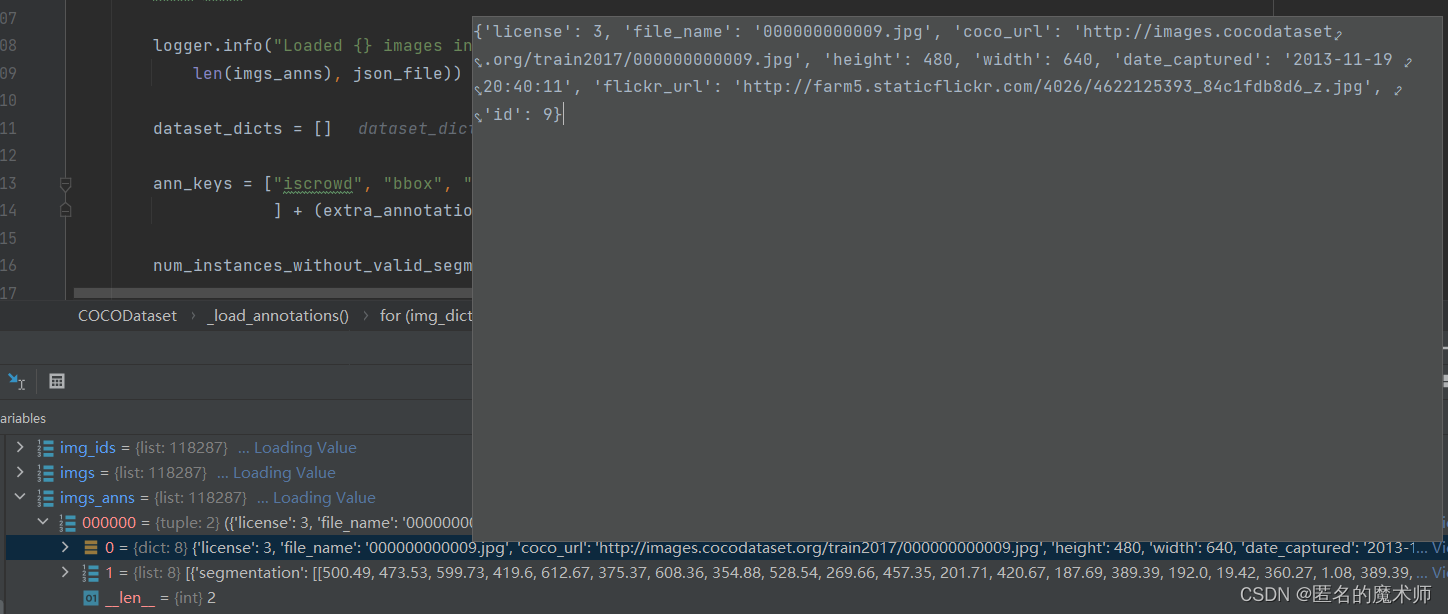
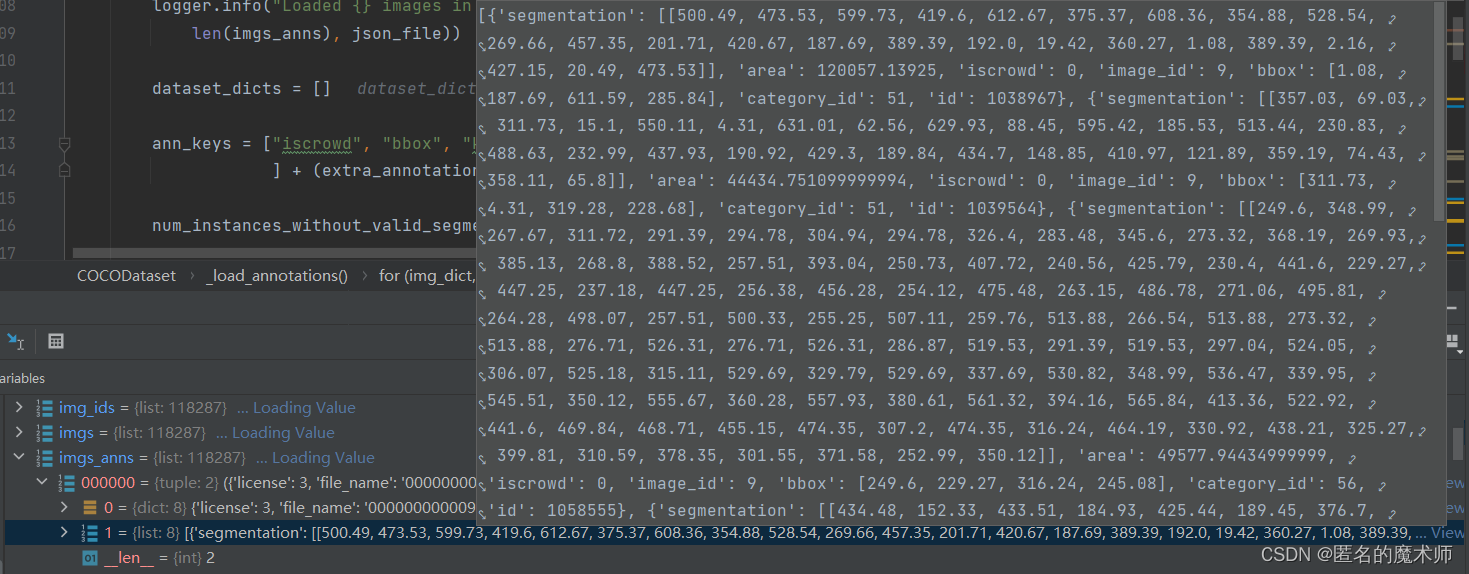
img_dict
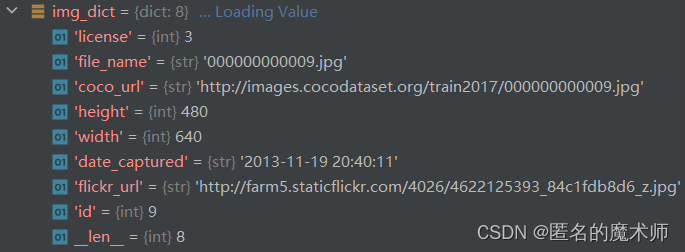
anno_dict_list

objs(第一次循环后的)
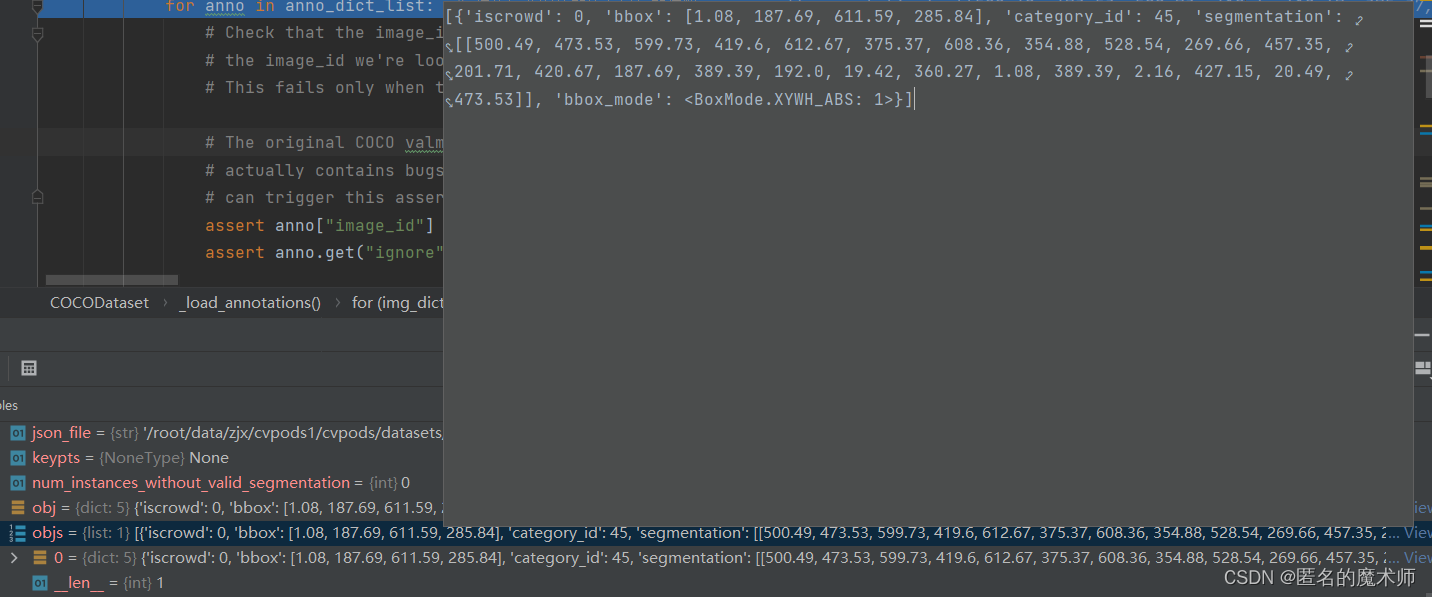
obj

segm

4) _init__
self (最终的)
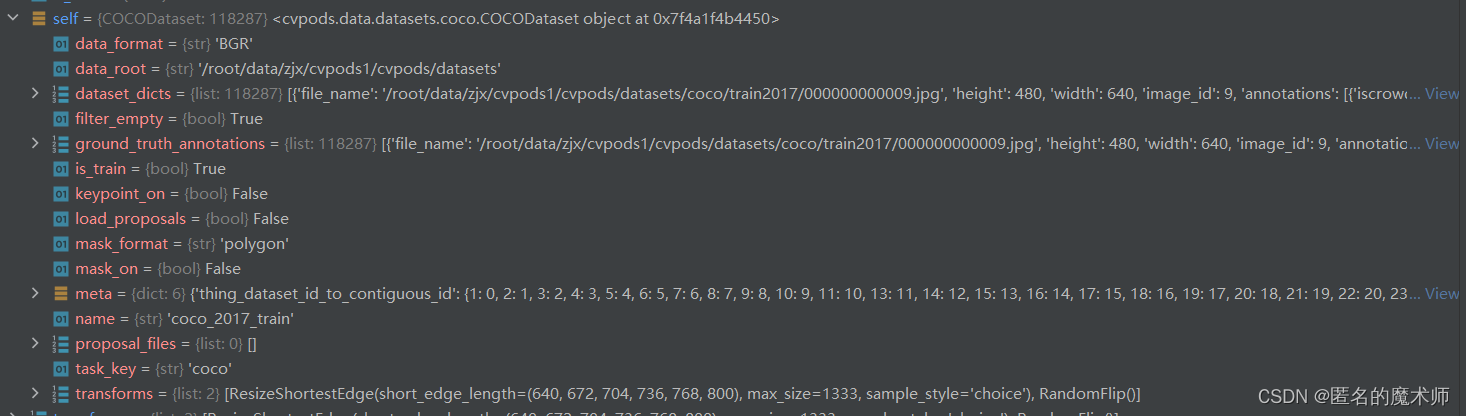
7 . cvpods/data/base_dataset.py
1) __init__
self
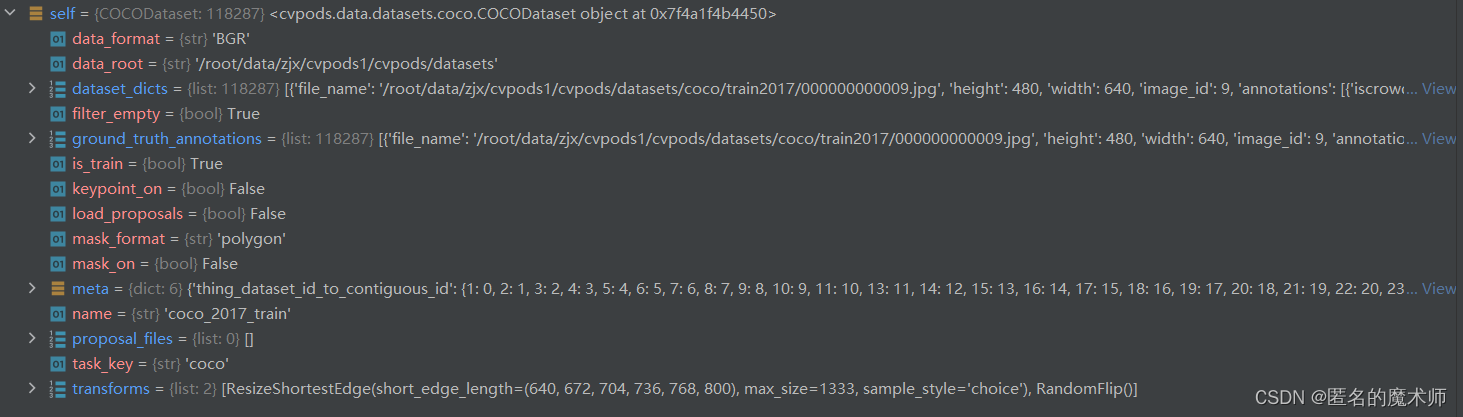
2) filter_images_with_only_crowd_annotations
dataset_dicts
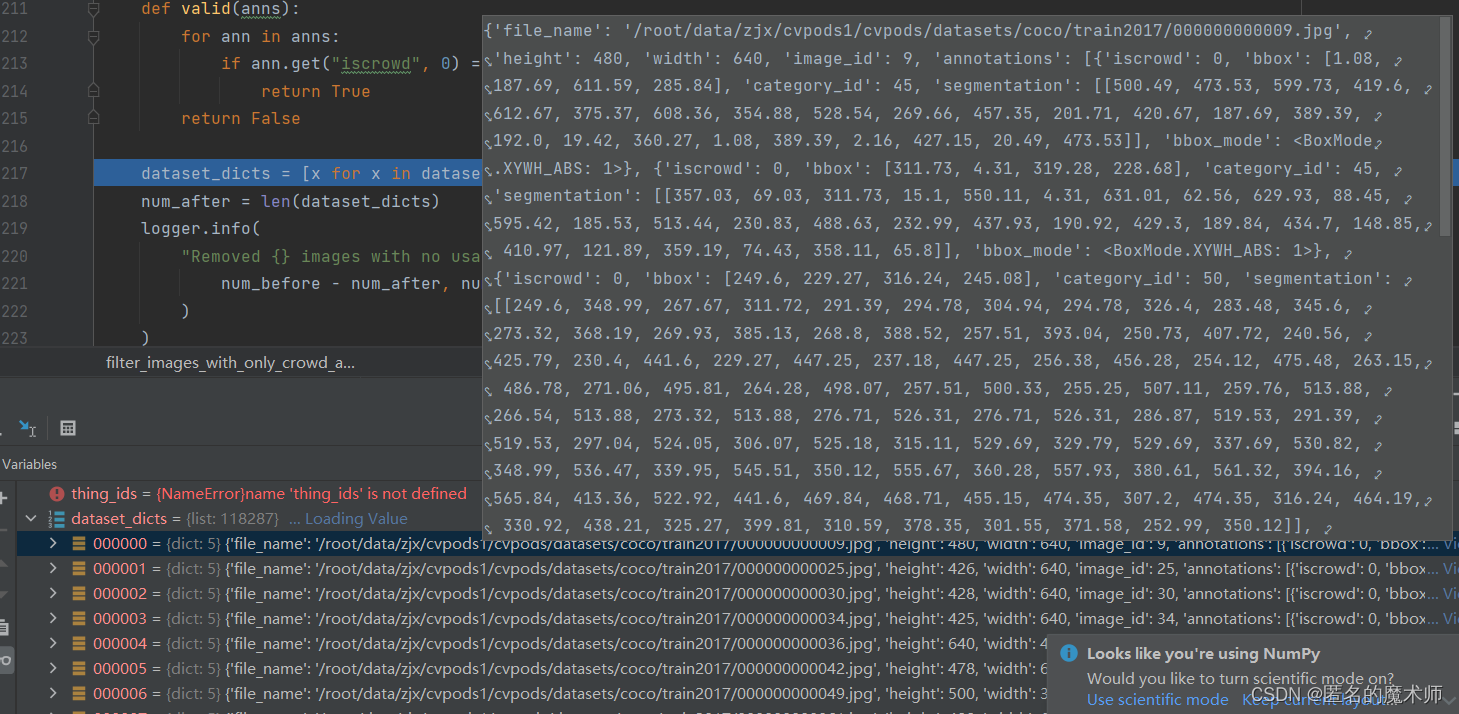
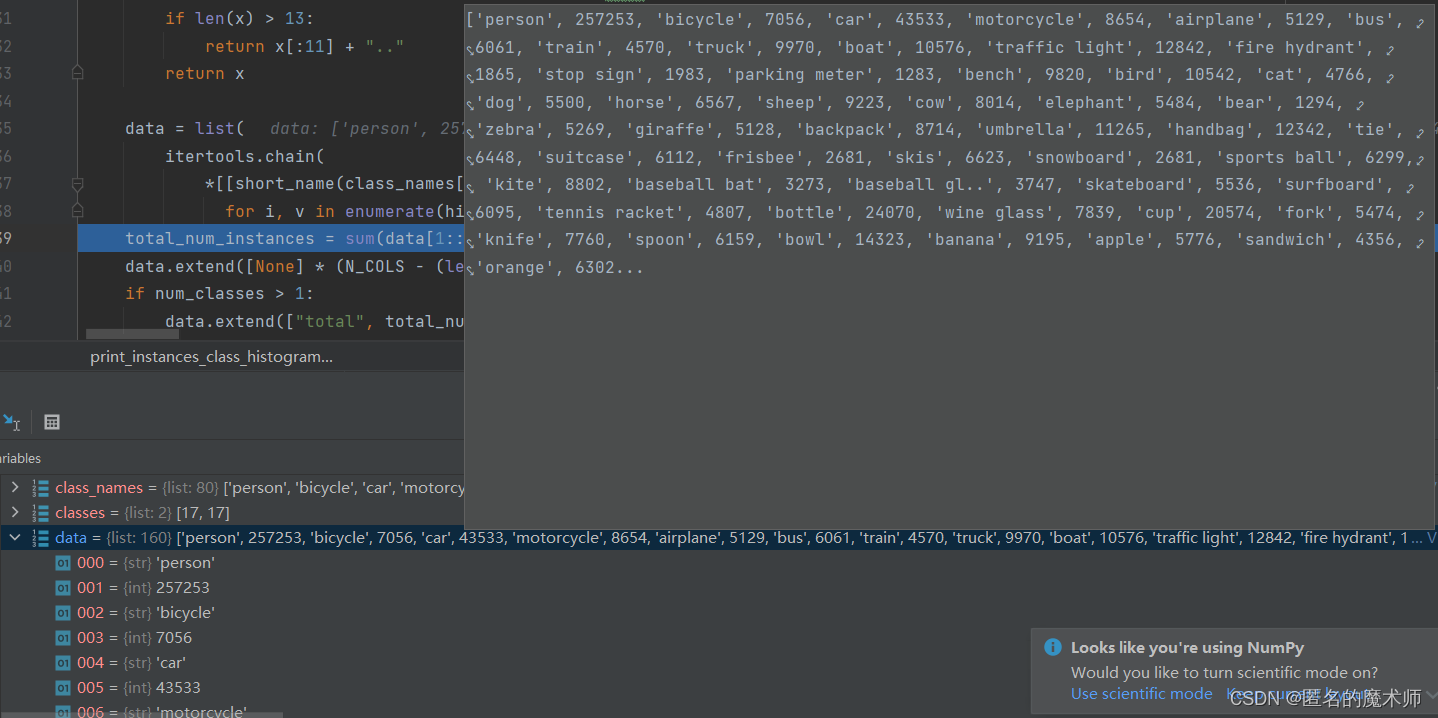
3) print_instances_class_histogram
entry

data
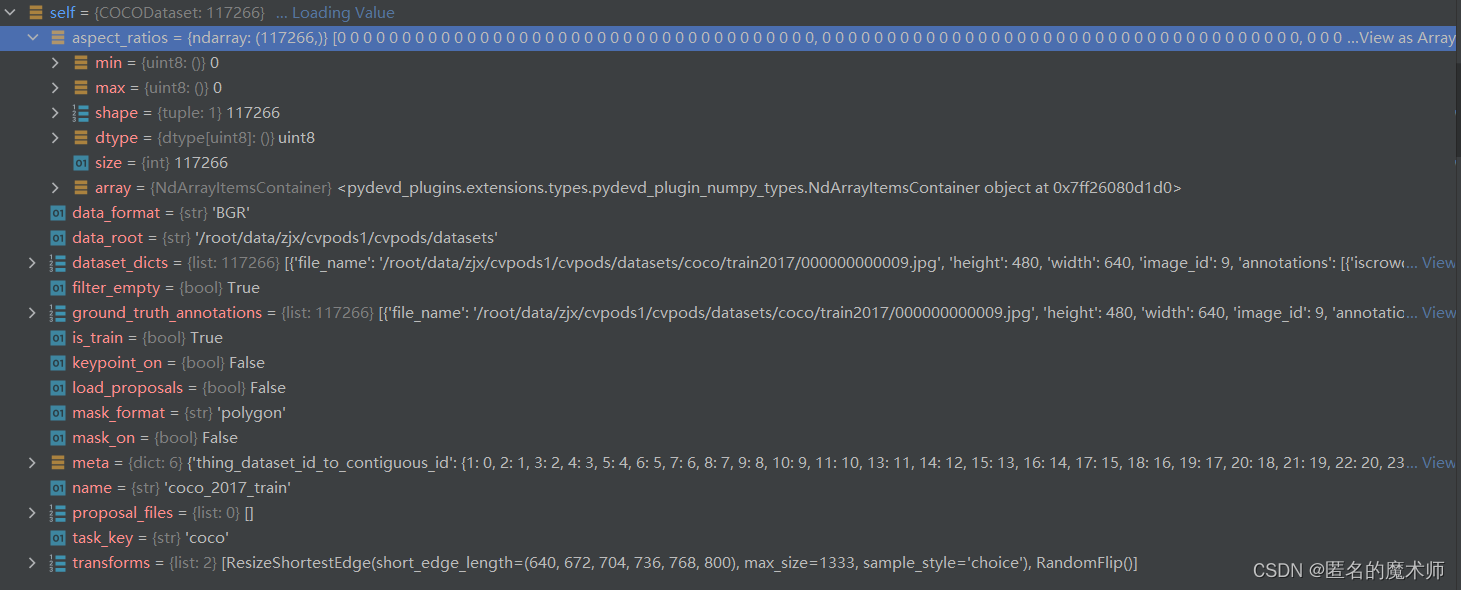
4)_set_group_flag
self
dataset_dict

8. net.py
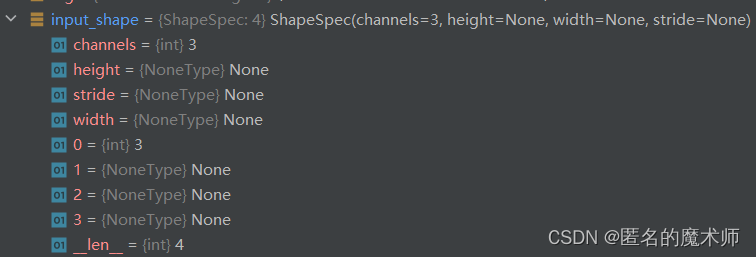
1) build_backbone
input_shape
9. fcos.py
cfg
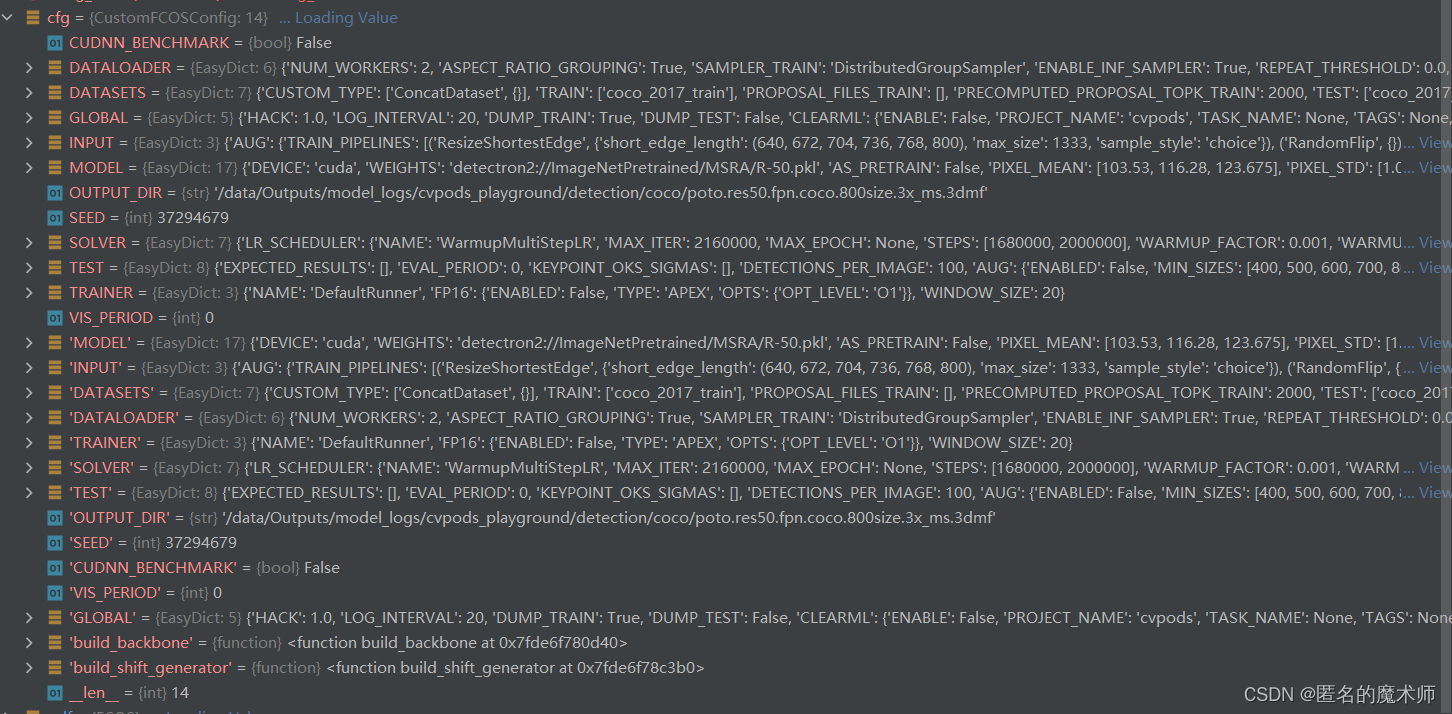
backbone_shape
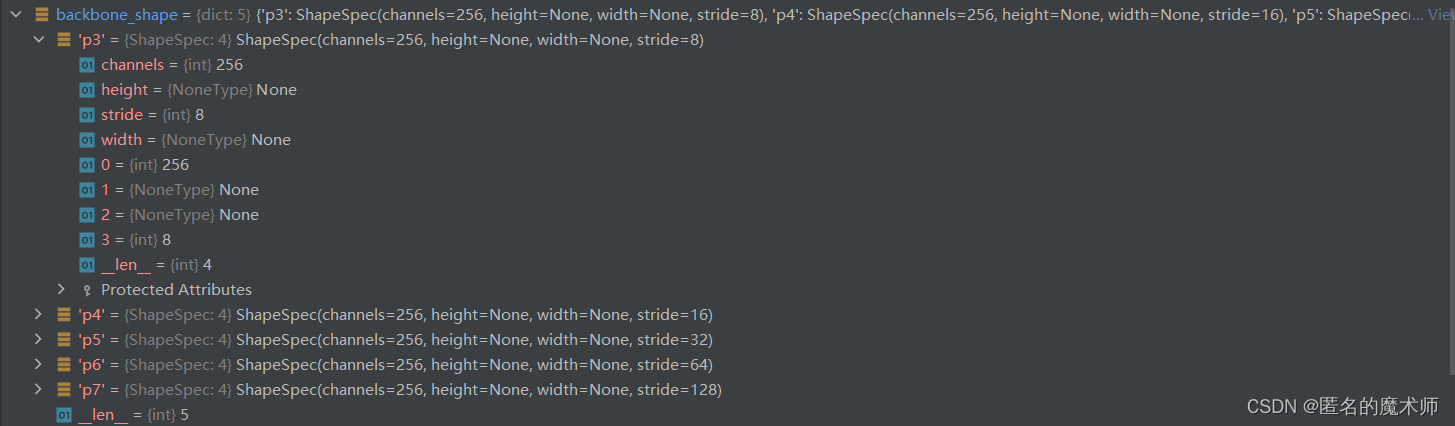
self.shift_generator
10. cvpods/modeling/backbone/resnet.py
1) build_resnet_backbone
stem

p
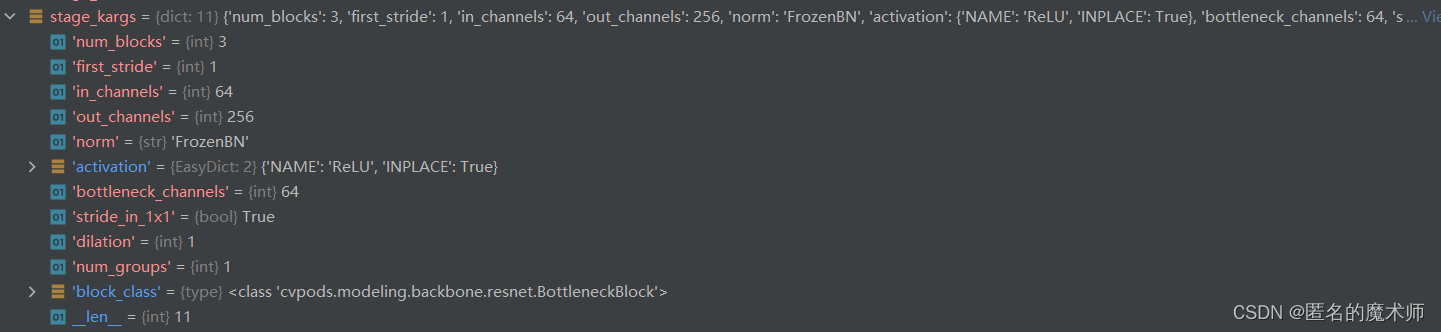
stage_kargs 循环 stage_idx=2,3,4,5
11. cvpods/modeling/backbone/fpn.py
1) FPN
input_shapes
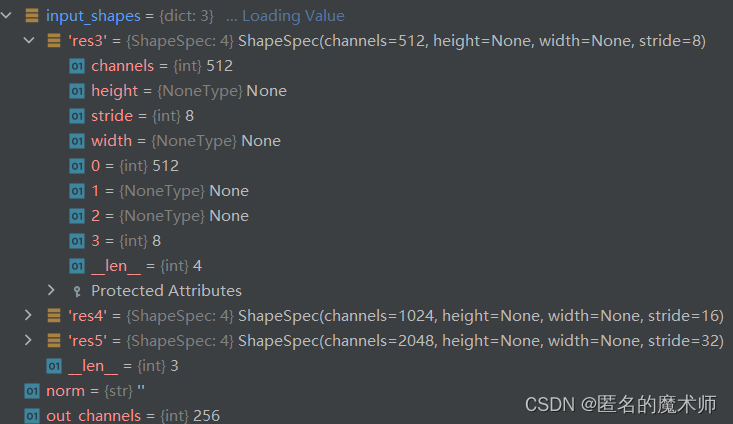
三、一些设定的入口
1. 传入参数的设定 argparse.ArgumentParser:
train_net.py -----71
parser = default_argument_parser()cvpods/engine/setup.py -----27
参数解读
--dir config和net所在的路径,默认为当前工作路径,后面配合相当于增添环境变量PYTHONPATH为该路径
--resume 是否需要从checkpoint directory 恢复训练,应该是断点续训
--eval-only 只进行评估
--num-gpus 定义使用的GPU的总数
--num-machine 默认1
--machine-rank 默认0 定义主机
opts 修改config的选择
2. 打印输出日志的地方
train_net.py -----169
logger.info("Create soft link to {}".format(config.OUTPUT_DIR))cvpods/engine/setup.py ----- 135
setup_logger(output_dir, distributed_rank=rank)这里主要是 setup_logger函数里会有相应的日志输出打印设置。
cvpods/engine/setup.py -----137
logger.info("Rank of current process: {}. World size: {}".format(
rank, comm.get_world_size()))
logger.info("Environment info:\n" + collect_env_info())
logger.info("Command line arguments: " + str(args))cvpods/data/build.py -----127
logger.info(f"TransformGens used: {transform_gens} in training")coco库中打印的
print('loading annotations into memory...')
print('Done (t={:0.2f}s)'.format(time.time()- tic))
print('creating index...')cvpods/data/datasets/coco.py -----238
logger.info("Loading {} takes {:.2f} seconds.".format(
json_file, timer.seconds()))cvpods/data/datasets/coco.py -----308
logger.info("Loaded {} images in COCO format from {}".format(
len(imgs_anns), json_file))cvpods/data/base_dataset.py -----219
logger.info(
"Removed {} images with no usable annotations. {} images left.".format(
num_before - num_after, num_after
)
)cvpods/data/base_dataset.py -----170
print_instances_class_histogram(dataset_dicts, class_names)train_net.py -----104 106
logger.info("Running with full config:\n{}".format(cfg))
logger.info("different config with base class:\n{}".format(cfg.diff(base_config)))runner.py ----- 281
logger.info("Starting training from iteration {}".format(self.start_iter))以表格的形式打印输出
cvpods/data/base_dataset.py ------344
利用 tabulate库来实现,
table = tabulate(
data,
headers=["category", "#instances"] * (N_COLS // 2),
tablefmt="pipe",
numalign="left",
stralign="center",
) # 以优雅的表格形式打印输出
log_first_n(
"INFO",
"Distribution of instances among all {} categories:\n".format(
num_classes) + colored(table, "cyan"),
key="message",
)cvpods/data/build.py -----133 147
logger.info("Using training sampler {}".format(sampler_name))
logger.info("Wrap sampler with infinite warpper...")net.py -----37
logger = logging.getLogger(__name__)
logger.info("Model:\n{}".format(model))cvpods/utils/compat_wrapper.py -----14
logger.warning("{} will be deprecated. {}".format(func.__name__, extra_info))cvpods/engine/runner.py -----90 ------(打印整个模型的结构)
logger.info(f"Model: \n{self.model}")hooks.py ---- 201
logger.info(
"Overall training speed: {} iterations in {} ({:.4f} s / it)".format(
num_iter,
str(datetime.timedelta(seconds=int(total_time_minus_hooks))),
total_time_minus_hooks / num_iter,
)
)
logger.info(
"Total training time: {} ({} on hooks)".format(
str(datetime.timedelta(seconds=int(total_time))),
str(datetime.timedelta(seconds=int(hook_time))),
)
)3. 传入模型的入口
首先需要定义好模型的网络架构,以及模型参数的设置。然后把模型的网络架构和设置config文件传入进来
train_net.py ----- 171
launch(
main,
args.num_gpus,
num_machines=args.num_machines,
machine_rank=args.machine_rank,
dist_url=args.dist_url,
args=(args, config, build_model),
)这个launch函数首先对分布式训练进行了一些初始化设置,然后再执行模型的训练,这里执行模型的训练的关键就是 传入的 main 函数,其在
train_net.py ----- 81
4. runner 执行评估或者测试
train_net.py ----89
runner = runner_decrator(RUNNERS.get(cfg.TRAINER.NAME))(cfg, build_model)这里的训练流程 包含它们的一些模型 ,如果想要跑自己的需要用SimpleRunner或者重写训练环。
最后他会转到cvpods/engine/runner.py 开始执行训练
5. 对数据集处理的入口
若修改数据集,则在config文件中的DATASET.TRAIN 进行修改,并且需要相应的参考一下是否需要更改cvpods/data/datasets/paths_route.py中的内容,举例如下
_PREDEFINED_SPLITS_COCO["coco"] = {
"coco_2014_train":
("coco/train2014", "coco/annotations/instances_train2014.json"),
"coco_2014_val":
("coco/val2014", "coco/annotations/instances_val2014.json"),
"coco_2014_minival":
("coco/val2014", "coco/annotations/instances_minival2014.json"),
"coco_2014_minival_100":
("coco/val2014", "coco/annotations/instances_minival2014_100.json"),
"coco_2014_valminusminival": (
"coco/val2014",
"coco/annotations/instances_valminusminival2014.json",
),
"coco_2017_train": ("coco/train2017",
"coco/annotations/instances_train2017.json"),
"coco_2017_val": ("coco/val2017",
"coco/annotations/instances_val2017.json"),
"coco_2017_test": ("coco/test2017",
"coco/annotations/image_info_test2017.json"),
"coco_2017_test-dev": ("coco/test2017",
"coco/annotations/image_info_test-dev2017.json"),
"coco_2017_val_100": ("coco/val2017",
"coco/annotations/instances_val2017_100.json"),
}这个导入数据集的路径设置会在cvpods/data/datasets/coco.py -----381
image_root, json_file = _PREDEFINED_SPLITS_COCO[self.task_key][self.name]根据config文件中设置的 数据集的名称 等 到相应的字典中拿出 数据集的路径。
cvpods/data/datasets/coco.py -----236
coco_api = COCO(json_file)这个地方会加载json文件的注释,使用了pycocotools.coco库,其里面实现的功能和之前的coco数据处理时的一样(参考用于目标跟踪的COCO数据集的预处理过程的API,以及对训练数据的数据增强操作)
但这里并没有进行图片的裁剪,而是只加载了json文件中的注释。
cvpods/data/base_dataset.py ----161
dataset_dicts = filter_images_with_only_crowd_annotations(dataset_dicts)它会过滤掉 注释信息 "iscrowd“ 值不等于0的image,即只保留包含密集拥挤目标的图片。
cvpods/data/build.py -----102
def build_train_loader(cfg):cvpods/data/build.py -----128
dataset = build_dataset(
cfg, cfg.DATASETS.TRAIN, transforms=transform_gens, is_train=True
)data_loader 的创建
cvpods/data/build.py -----149 <---- runner.py ------322 < ----- runner.py-----86
data_loader = torch.utils.data.DataLoader(
dataset,
batch_size=images_per_minibatch,
sampler=sampler,
num_workers=cfg.DATALOADER.NUM_WORKERS,
collate_fn=trivial_batch_collator,
worker_init_fn=worker_init_reset_seed,
)6.分布式训练 DDP的设定
cvpods/data/build.py -----142
sampler = SAMPLERS.get(sampler_name)(
dataset, images_per_minibatch, num_devices, rank)7. 模型的创建
cvpods/engine/runner.py -----88
model = build_model(cfg)然后,根据这个接口,程序会转到 自定义的相应的 config文件下的net.py中 ,但创建的过程中依然会用到cvpods库,比如骨干网络和fpn的创建,
net.py -----31
def build_model(cfg):
cfg.build_backbone = build_backbone
cfg.build_shift_generator = build_shift_generator
model = FCOS(cfg)
logger = logging.getLogger(__name__)
logger.info("Model:\n{}".format(model))
return model可以看到,首先在cfg中新加入两个参数,build_backbone和build_shift_generator,这两都是函数,它们的作用将会在FCOS(cfg)中来实现。
1) resnet backbone的创建 ------ 来源于cvpods库
在FCOS类中,如下所示
self.backbone = cfg.build_backbone(
cfg, input_shape=ShapeSpec(channels=len(cfg.MODEL.PIXEL_MEAN)))这里的 ShapeSpec只是返回一个相应的元组元素类
namedtuple("_ShapeSpec", ["channels", "height", "width", "stride"])
![]()
然后程序进入 net.py中的build_backbone函数中,在这里
backbone = build_retinanet_resnet_fpn_p5_backbone(cfg, input_shape)接着调用 cvpods/modeling/backbone/fpn.py 中的
def build_retinanet_resnet_fpn_p5_backbone(cfg, input_shape: ShapeSpec):
return build_retinanet_resnet_fpn_backbone(cfg, input_shape)
def build_retinanet_resnet_fpn_backbone(cfg, input_shape: ShapeSpec):
return build_retinanet_fpn_backbone(cfg, input_shape)最终在 该放fpn.py文件下的build_retinanet_fpn_backbone中实现,这个函数里可选的结构有
"resnet","shufflev2","mobilev2","timm"
本次选用的是resnet。
if backbone_name == "resnet":
bottom_up = build_resnet_backbone(cfg, input_shape)进入cvpods/modeling/backbone/resnet.py 中的build_resnet_backbone函数中。其中网络的设置,包括选型(本次所选resnet-50)都由传入的cfg文件进行设置的。
depth = cfg.MODEL.RESNETS.DEPTH # 50
num_blocks_per_stage = {
18: [2, 2, 2, 2],
34: [3, 4, 6, 3],
50: [3, 4, 6, 3],
101: [3, 4, 23, 3],
152: [3, 8, 36, 3],
200: [3, 24, 36, 3],
269: [3, 30, 48, 8],
}[depth] # [] 相应的 表示每层的 block的个数对于stem的创建,由类BasicStem完成
class BasicStem(nn.Module):而且 这里会有一个设定,根据
freeze_at = cfg.MODEL.BACKBONE.FREEZE_AT # 2
if freeze_at >= 1:
for p in stem.parameters(): # <c>
p.requires_grad = False
stem = FrozenBatchNorm2d.convert_frozen_batchnorm(stem)当freeze_at>1时,会使得stem部分的网络参数不更新,而且接着对其初始化的值也进行了设置。
而resnet基本模块的创建是由该文件resnet.py文件下的类BottleneckBlock完成的
class BottleneckBlock(ResNetBlockBase):由下面程序调用
blocks = make_stage(**stage_kargs)
def make_stage(block_class, num_blocks, first_stride, **kwargs):
blocks = []
for i in range(num_blocks):
blocks.append(block_class(stride=first_stride if i == 0 else 1, **kwargs))
kwargs["in_channels"] = kwargs["out_channels"]
return blocks其中 stage_kargs是个字典,其包含内容举例如下
其传入到BottleneckBlock类的一些参数如下所示
第一层的 1
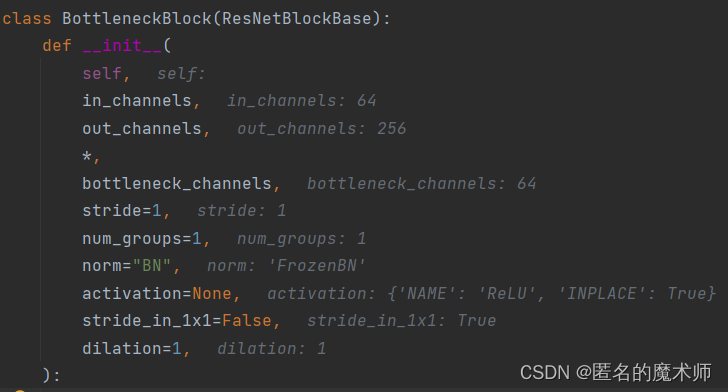

第一层的2
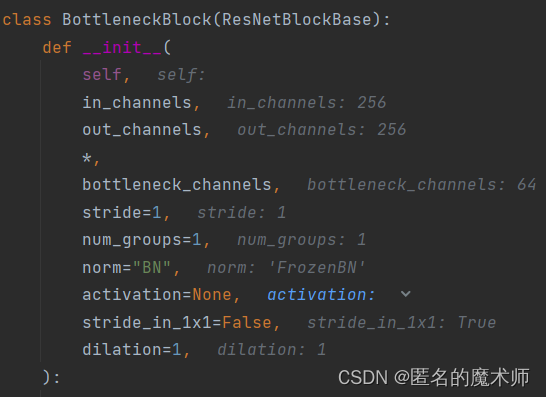
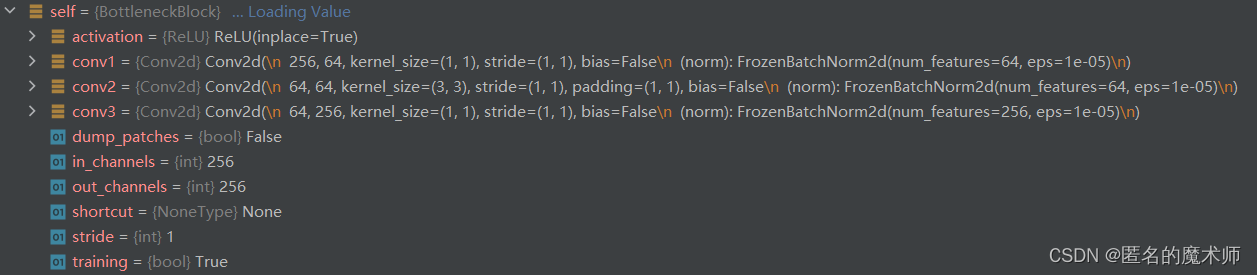
第一层的3
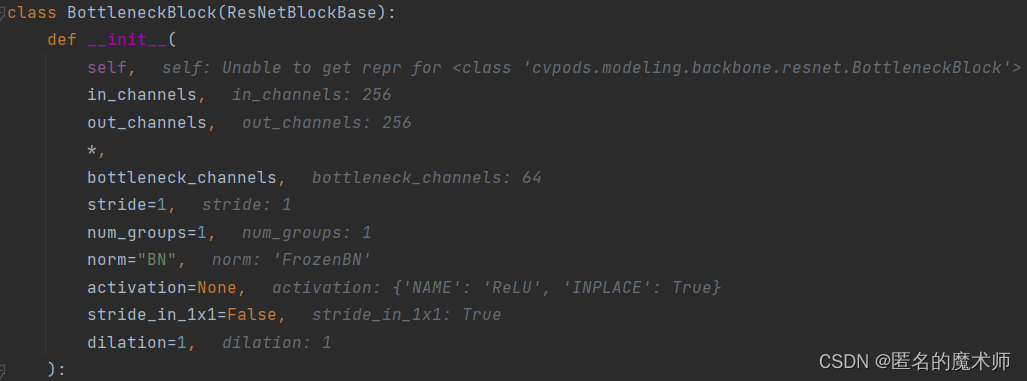

当一个层创建完成后,下一层的输入通道数会变成当前层的输出通道,下一层的输出通道数等于当前层输出通道乘以2,依此来改变下一层的输入输出通道数的设计
in_channels = out_channels
out_channels *= 2
bottleneck_channels *= 2然后对layer2层的参数进行了冻结
if freeze_at >= stage_idx: # 冻结前两层,即冻结了layer2层
for block in blocks:
block.freeze()接下来循环执行,依此创建其他层。最后通过ResNet类将这些层连接到一起。这个ResNet类
class ResNet(Backbone):继承了Backbone父类,它被定义在同文件夹下的backbone.py文件中,它又继承了nn.Model父类
class Backbone(nn.Module, metaclass=ABCMeta):
所以ResNet中会有
self.add_module
等操作,其来源于pytorch库中的nn.Model父类。最终的resnet backbone结构如下所示
ResNet(
(stem): BasicStem(
(conv1): Conv2d(
3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(activation): ReLU(inplace=True)
(max_pool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
)
(res2): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(activation): ReLU(inplace=True)
(conv1): Conv2d(
64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
(1): BottleneckBlock(
(activation): ReLU(inplace=True)
(conv1): Conv2d(
256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
(2): BottleneckBlock(
(activation): ReLU(inplace=True)
(conv1): Conv2d(
256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
)
(res3): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(activation): ReLU(inplace=True)
(conv1): Conv2d(
256, 128, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(1): BottleneckBlock(
(activation): ReLU(inplace=True)
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(2): BottleneckBlock(
(activation): ReLU(inplace=True)
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(3): BottleneckBlock(
(activation): ReLU(inplace=True)
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
)
(res4): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
(activation): ReLU(inplace=True)
(conv1): Conv2d(
512, 256, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(1): BottleneckBlock(
(activation): ReLU(inplace=True)
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(2): BottleneckBlock(
(activation): ReLU(inplace=True)
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(3): BottleneckBlock(
(activation): ReLU(inplace=True)
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(4): BottleneckBlock(
(activation): ReLU(inplace=True)
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(5): BottleneckBlock(
(activation): ReLU(inplace=True)
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
)
(res5): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
(activation): ReLU(inplace=True)
(conv1): Conv2d(
1024, 512, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
(1): BottleneckBlock(
(activation): ReLU(inplace=True)
(conv1): Conv2d(
2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
(2): BottleneckBlock(
(activation): ReLU(inplace=True)
(conv1): Conv2d(
2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
)
)2) FPN 的 创建 ------来源于cvpods库
首先会创建P6P7两层,
top_block=LastLevelP6P7(in_channels_p6p7, out_channels, in_feature=block_in_feature),然后由FPN类来完成,
backbone = FPN(
bottom_up=bottom_up,
in_features=in_features,
out_channels=out_channels,
norm=cfg.MODEL.FPN.NORM,
top_block=LastLevelP6P7(in_channels_p6p7, out_channels, in_feature=block_in_feature),
fuse_type=cfg.MODEL.FPN.FUSE_TYPE,
)而且最终的得到的backbone是包括Resnet backbone 和 fpn 结构的。如下所示
FPN(
(fpn_lateral3): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
(fpn_output3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(fpn_lateral4): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(fpn_output4): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(fpn_lateral5): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1))
(fpn_output5): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(top_block): LastLevelP6P7(
(p6): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(p7): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
)
(bottom_up): ResNet(
(stem): BasicStem(
(conv1): Conv2d(
3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(activation): ReLU(inplace=True)
(max_pool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
)
(res2): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(activation): ReLU(inplace=True)
(conv1): Conv2d(
64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
(1): BottleneckBlock(
(activation): ReLU(inplace=True)
(conv1): Conv2d(
256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
(2): BottleneckBlock(
(activation): ReLU(inplace=True)
(conv1): Conv2d(
256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
)
(res3): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(activation): ReLU(inplace=True)
(conv1): Conv2d(
256, 128, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(1): BottleneckBlock(
(activation): ReLU(inplace=True)
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(2): BottleneckBlock(
(activation): ReLU(inplace=True)
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(3): BottleneckBlock(
(activation): ReLU(inplace=True)
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
)
(res4): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
(activation): ReLU(inplace=True)
(conv1): Conv2d(
512, 256, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(1): BottleneckBlock(
(activation): ReLU(inplace=True)
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(2): BottleneckBlock(
(activation): ReLU(inplace=True)
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(3): BottleneckBlock(
(activation): ReLU(inplace=True)
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(4): BottleneckBlock(
(activation): ReLU(inplace=True)
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(5): BottleneckBlock(
(activation): ReLU(inplace=True)
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
)
(res5): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
(activation): ReLU(inplace=True)
(conv1): Conv2d(
1024, 512, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
(1): BottleneckBlock(
(activation): ReLU(inplace=True)
(conv1): Conv2d(
2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
(2): BottleneckBlock(
(activation): ReLU(inplace=True)
(conv1): Conv2d(
2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
)
)
)至此,backbone 创建完成,回到最初的地方,即fcos.py-----78
self.backbone = cfg.build_backbone(
cfg, input_shape=ShapeSpec(channels=len(cfg.MODEL.PIXEL_MEAN)))3) FCOSHead的创建 ------ 来源于自定义
head的部分需要根据自己的方法来定义,本次由 类 FCOSHead来完成,定义的结构如下
FCOSHead(
(cls_subnet): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): GroupNorm(32, 256, eps=1e-05, affine=True)
(2): ReLU()
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): GroupNorm(32, 256, eps=1e-05, affine=True)
(5): ReLU()
(6): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): GroupNorm(32, 256, eps=1e-05, affine=True)
(8): ReLU()
(9): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(10): GroupNorm(32, 256, eps=1e-05, affine=True)
(11): ReLU()
)
(bbox_subnet): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): GroupNorm(32, 256, eps=1e-05, affine=True)
(2): ReLU()
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): GroupNorm(32, 256, eps=1e-05, affine=True)
(5): ReLU()
(6): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): GroupNorm(32, 256, eps=1e-05, affine=True)
(8): ReLU()
(9): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(10): GroupNorm(32, 256, eps=1e-05, affine=True)
(11): ReLU()
)
(cls_score): Conv2d(256, 80, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bbox_pred): Conv2d(256, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(max3d): MaxFiltering(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(norm): GroupNorm(32, 256, eps=1e-05, affine=True)
(nonlinear): ReLU()
(max_pool): MaxPool3d(kernel_size=(3, 3, 3), stride=1, padding=(1, 1, 1), dilation=1, ceil_mode=False)
)
(filter): Conv2d(256, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(scales): ModuleList(
(0): Scale()
(1): Scale()
(2): Scale()
(3): Scale()
(4): Scale()
)
)至此,model差不多定义完成,回到net.py
model = FCOS(cfg)总的内容如下所示
最后回到最初的 cvpods/engine/runner.py -----88
model = build_model(cfg)至此,model创建部分结束。
8. 3D Maxfilter定义处
fcos.py -----509
与 Head 部分一起定义的
self.max3d = MaxFiltering(in_channels,
kernel_size=cfg.MODEL.POTO.FILTER_KERNEL_SIZE,
tau=cfg.MODEL.POTO.FILTER_TAU)
self.filter = nn.Conv2d(in_channels,
num_shifts * 1,
kernel_size=3,
stride=1,
padding=1)MaxFiltering(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(norm): GroupNorm(32, 256, eps=1e-05, affine=True)
(nonlinear): ReLU()
(max_pool): MaxPool3d(kernel_size=(3, 3, 3), stride=1, padding=(1, 1, 1), dilation=1, ceil_mode=False)
)![]()
9. optimizer定义
runner.py ----- 93
self.optimizer = self.build_optimizer(cfg, self.model)根据cfg设置的优化器的类型采用相应的优化器,具体在cvpods/solver/optimizer_builder.py中实现
本次采用的是SGD。如下所示

SGD (
Parameter Group 0
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 1
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 2
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 3
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 4
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 5
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 6
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 7
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 8
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 9
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 10
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 11
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 12
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 13
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 14
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 15
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 16
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 17
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 18
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 19
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 20
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 21
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 22
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 23
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 24
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 25
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 26
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 27
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 28
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 29
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 30
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 31
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 32
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 33
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 34
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 35
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 36
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 37
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 38
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 39
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 40
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 41
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 42
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 43
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 44
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 45
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 46
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 47
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 48
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 49
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 50
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 51
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 52
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 53
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 54
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 55
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 56
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 57
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 58
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 59
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 60
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0
Parameter Group 61
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0
Parameter Group 62
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 63
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 64
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0
Parameter Group 65
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0
Parameter Group 66
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 67
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 68
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0
Parameter Group 69
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0
Parameter Group 70
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 71
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 72
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0
Parameter Group 73
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0
Parameter Group 74
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 75
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 76
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0
Parameter Group 77
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0
Parameter Group 78
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 79
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 80
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0
Parameter Group 81
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0
Parameter Group 82
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 83
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 84
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0
Parameter Group 85
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0
Parameter Group 86
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 87
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 88
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0
Parameter Group 89
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0
Parameter Group 90
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 91
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 92
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 93
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 94
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 95
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 96
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0
Parameter Group 97
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0
Parameter Group 98
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 99
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 100
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 101
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 102
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 103
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
Parameter Group 104
dampening: 0
lr: 0.00125
momentum: 0.9
nesterov: False
weight_decay: 0.0001
)10. lr-scheduler的定义
runner.py ----- 134

11. 训练过程
1) 入口
train_net.py ----- 108
runner.train()-----> runner.py -----273 train函数中
super().train(self.start_iter, self.start_epoch, self.max_iter)-----> base_runner.py -----66 train函数中
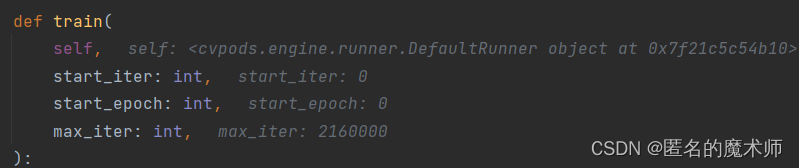
在这里定义了训练的loop,上面的参数可以看到一共循环的次数,循环如下
self.before_train()
for self.iter in range(start_iter, max_iter):
self.inner_iter = 0
self.before_step()
# by default, a step contains data_loading and model forward,
# loss backward is executed in after_step for better expansibility
self.run_step()
self.after_step()需要通过挂hooks来实现。 流程为
before_train() --> before_step()--------> run_step()----->after_step()-->after_train()
|--------------- < 循环 <-------------|
def before_train(self):
for h in self._hooks:
h.before_train()
def after_train(self):
self.storage._iter = self.iter
for h in self._hooks:
h.after_train()
def before_step(self):
# Maintain the invariant that storage.iter == runner.iter
# for the entire execution of each step
self.storage._iter = self.iter
for h in self._hooks:
h.before_step()
def after_step(self):
for h in self._hooks:
h.after_step()2) 实现流程
上面的循环流程都和 hook挂钩, 以此来实现各部分的功能。挂hook 的地方在runner.py -----153
self.register_hooks(self.build_hooks())build_hooks() 函数主要返回包含各种hook的下面的ret列表
ret = [
hooks.OptimizationHook(
accumulate_grad_steps=cfg.SOLVER.BATCH_SUBDIVISIONS,
grad_clipper=None,
mixed_precision=cfg.TRAINER.FP16.ENABLED
),
hooks.LRScheduler(self.optimizer, self.scheduler),
hooks.IterationTimer(),
hooks.PreciseBN(
# Run at the same freq as (but before) evaluation.
cfg.TEST.EVAL_PERIOD,
self.model,
# Build a new data loader to not affect training
self.build_train_loader(cfg),
cfg.TEST.PRECISE_BN.NUM_ITER,
)
if cfg.TEST.PRECISE_BN.ENABLED and get_bn_modules(self.model)
else None,
]self.register_hooks 将 hoos 注册,可以通过注册启动相应的hook,其在base_ruuner.py ----48
hooks如下所示 ,

这些hooks 都在 hooks.py中以类 实现的,而且都是继承了 HookBase父类。
class HookBase:
def before_train(self):
"""
Called before the first iteration.
"""
pass
def after_train(self):
"""
Called after the last iteration.
"""
pass
def before_step(self):
"""
Called before each iteration.
"""
pass
def after_step(self):
"""
Called after each iteration.
"""
pass可以看到 若子类需要启动对应的功能,则需要重写这些方法,若不需要则不重写,这样会直接pass。
在训练过程中,如果执行到hooks模块的相应功能(见下面的第12部分),该模块不包含或者没重写父类的该功能,则相应的跳过不执行,说明不对这个模块做任何行动。
12 .训练过程中通过挂 hooks 的实现细节
1)OptimizationHook
class OptimizationHook(HookBase):
def __init__(self, accumulate_grad_steps=1, grad_clipper=None, mixed_precision=False):
self.accumulate_grad_steps = accumulate_grad_steps
self.grad_clipper = grad_clipper
self.mixed_precision = mixed_precision
def before_step(self):
self.trainer.optimizer.zero_grad()
def after_step(self):
losses = self.trainer.step_outputs["loss_for_backward"]
losses /= self.accumulate_grad_steps
if self.mixed_precision:
from apex import amp
with amp.scale_loss(losses, self.trainer.optimizer) as scaled_loss:
scaled_loss.backward()
else:
losses.backward()
if self.trainer.inner_iter == self.accumulate_grad_steps:
if self.grad_clipper is not None:
self.grad_clipper(self.tariner.model.paramters())
self.trainer.optimizer.step()
self.trainer.optimizer.zero_grad()可以看出重写了父类中的 def before_step(self): 和 def after_step(self): 方法,分别用来实现 优化器的梯度清零 ;实现反向传播计算梯度,然后 更新优化器参数;依此循环
2) IterationTimer
class IterationTimer(HookBase):
def __init__(self, warmup_iter=3):
"""
Args:
warmup_iter (int): the number of iterations at the beginning to exclude
from timing.
"""
self._warmup_iter = warmup_iter
self._step_timer = Timer()
def before_train(self):
self._start_time = time.perf_counter()
self._total_timer = Timer()
self._total_timer.pause()
def after_train(self):
total_time = time.perf_counter() - self._start_time
total_time_minus_hooks = self._total_timer.seconds()
hook_time = total_time - total_time_minus_hooks
num_iter = self.trainer.iter + 1 - self.trainer.start_iter - self._warmup_iter
if num_iter > 0 and total_time_minus_hooks > 0:
# Speed is meaningful only after warmup
# NOTE this format is parsed by grep in some scripts
logger.info(
"Overall training speed: {} iterations in {} ({:.4f} s / it)".format(
num_iter,
str(datetime.timedelta(seconds=int(total_time_minus_hooks))),
total_time_minus_hooks / num_iter,
)
)
logger.info(
"Total training time: {} ({} on hooks)".format(
str(datetime.timedelta(seconds=int(total_time))),
str(datetime.timedelta(seconds=int(hook_time))),
)
)
def before_step(self):
self._step_timer.reset()
self._total_timer.resume()
def after_step(self):
# +1 because we're in after_step
iter_done = self.trainer.iter - self.trainer.start_iter + 1
if iter_done >= self._warmup_iter:
sec = self._step_timer.seconds()
self.trainer.storage.put_scalars(time=sec)
else:
self._start_time = time.perf_counter()
self._total_timer.reset()
self._total_timer.pause()可以看出重写了父类的所有方法。
before_train : 在训练开始之前记录开始时间
before_step: 重置时间
after_step: 计算当前的迭代的次数,计算时间
after_train: 计算总速度 总时间
3) LRScheduler
class LRScheduler(HookBase):
"""
A hook which executes a torch builtin LR scheduler and summarizes the LR.
It is executed after every iteration.
"""
def __init__(self, optimizer, scheduler):
"""
Args:
optimizer (torch.optim.Optimizer):
scheduler (torch.optim._LRScheduler)
"""
self._optimizer = optimizer
self._scheduler = scheduler
# NOTE: some heuristics on what LR to summarize
# summarize the param group with most parameters
largest_group = max(len(g["params"]) for g in optimizer.param_groups)
if largest_group == 1:
# If all groups have one parameter,
# then find the most common initial LR, and use it for summary
lr_count = Counter([g["lr"] for g in optimizer.param_groups])
lr = lr_count.most_common()[0][0]
for i, g in enumerate(optimizer.param_groups):
if g["lr"] == lr:
self._best_param_group_id = i
break
else:
for i, g in enumerate(optimizer.param_groups):
if len(g["params"]) == largest_group:
self._best_param_group_id = i
break
def after_step(self):
lr = self._optimizer.param_groups[self._best_param_group_id]["lr"]
self.trainer.storage.put_scalar("lr", lr, smoothing_hint=False)
self._scheduler.step()只重写了 after_step方法, 用于不同迭代次数时改变学习率的数值
4) PeriodicCheckpointer
class PeriodicCheckpointer(_PeriodicCheckpointer, HookBase):
"""
Same as :class:`cvpods.checkpoint.PeriodicCheckpointer`, but as a hook.
Note that when used as a hook,
it is unable to save additional data other than what's defined
by the given `checkpointer`.
It is executed every ``period`` iterations and after the last iteration.
"""
def before_train(self):
# `self.max_iter` and `self.max_epoch` will be initialized in __init__
pass
def after_step(self):
# No way to use **kwargs
self.step(self.trainer.iter)父类中的step函数如下
def step(self, iteration: int, **kwargs: Any):
"""
Perform the appropriate action at the given iteration.
Args:
iteration (int): the current iteration, ranged in [0, max_iter-1].
kwargs (Any): extra data to save, same as in
:meth:`Checkpointer.save`.
"""
iteration = int(iteration)
additional_state = {"iteration": iteration}
additional_state.update(kwargs)
if self.period < 0:
return
if self.period > 0 and (iteration + 1) % self.period == 0:
if self.max_epoch is not None:
epoch_iters = self.max_iter // self.max_epoch
curr_epoch = (iteration + 1) // epoch_iters
ckpt_name = "model_epoch_{:04d}".format(curr_epoch)
else:
ckpt_name = "model_iter_{:07d}".format(iteration + 1)
self.checkpointer.save(ckpt_name, **additional_state)
if iteration >= self.max_iter - 1:
self.checkpointer.save("model_final", **additional_state)重写了 after_step方法,用于每轮迭代后保存模型数据
5) EvalHook
""" Run an evaluation function periodically, and at the end of training. It is executed every ``eval_period`` iterations and after the last iteration. """
6) PeriodicWriter
用于写 tensorboard
13. 执行 data 送入 model 的入口
base_runner.py -----87
self.run_step()14. 建议更改的一些设定
1) config.OUTPUT_DIR
输出日志文件的路径,如果不存在,创建它的地方在。这里会有个默认值,最好手动改一下你想让他出现的地方
cvpods/engine/setup.py -----131 的 ensure_dir函数,后面会配合
cvpods/utils/dump/logger.py ---- 53 来定义输出日志文件的路径(log.txt)
















 1548
1548











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











