






目录
一、Image-Text Retrieval (ITR , 图像文本检索)
二、Visual Question Answering (VQA , 视觉问答)
五、Natural Language for Visual Reasoning(NLVR2, 自然语言视觉推理)
一、Image-Text Retrieval (ITR , 图像文本检索)
任务目的:
检索与给定文本最匹配的图像,或者给定图像最匹配的文本。
跨模态图像-文本检索(ITR)是根据用户给定的一种模态中的表达,从另一模态中检索出相关样本,通常包括两个子任务:图像-文本(i2t)和文本-图像(t2i)检索。
数据集格式
以 filter8k数据集为例。官网🤠
其 caption target 的格式为
1000268201_693b08cb0e.jpg,A child in a pink dress is climbing up a set of stairs in an entry way . 1000268201_693b08cb0e.jpg,A girl going into a wooden building . 1000268201_693b08cb0e.jpg,A little girl climbing into a wooden playhouse . 1000268201_693b08cb0e.jpg,A little girl climbing the stairs to her playhouse . 1000268201_693b08cb0e.jpg,A little girl in a pink dress going into a wooden cabin . 1001773457_577c3a7d70.jpg,A black dog and a spotted dog are fighting 1001773457_577c3a7d70.jpg,A black dog and a tri-colored dog playing with each other on the road . 1001773457_577c3a7d70.jpg,A black dog and a white dog with brown spots are staring at each other in the street . 1001773457_577c3a7d70.jpg,Two dogs of different breeds looking at each other on the road . 1001773457_577c3a7d70.jpg,Two dogs on pavement moving toward each other .可以看到,每张图片配有五个不同的标题。图片和标题实况举例
image:
caption:
A child in a pink dress is climbing up a set of stairs in an entry way . # 一个穿着粉红色连衣裙的孩子正在爬入口处的一组楼梯。 A girl going into a wooden building . # 一个女孩走进一栋木屋。 A little girl climbing into a wooden playhouse . # 一个小女孩爬进了一个木制的剧场。 A little girl climbing the stairs to her playhouse . # 一个小女孩爬楼梯去她的游戏屋。 A little girl in a pink dress going into a wooden cabin . # 一个穿着粉红色连衣裙的小女孩走进一间木屋。

在训练时,image会经过数据增强,caption对一些噪声符号进行去除,然后每条注释格式会进行配对,(image,caption, idx)。其中idx是图像的索引。(idx用来索引图像,作为文本检索图像时模型的预测目标)
注意:这里 虽然是 单个图像与单个文本配对儿, 实际上每个图像对应五条文本,只不过不是一次性的训练,即 一图像与五条文本配对,而是分开的一对一作为样本对儿。
训练流程
1、 caption text 进行量化,text token送入 text encoder, image 送入 image encoder。
2、 计算ITC损失。 过程中利用idx构造真实图像文本匹配的one hot target。 可以参考这里 🐼 ,
3、 文本表征与图像表征送入多模态Encoder,进行融合前向处理。
计算 ITM损失。 可以参考这里 👿
evaluation流程
1、text token 送入text Encoder, image 送入 image Encoder
2、计算相似性矩阵。例如
sims_matrix = image_embeds @ text_embeds.t()主要目的是拿出image space 和 text space中最对齐的特征送入多模态Encoder中去。计算分数。
这个过程重复两次,一次是 i2t ,一次是t2i
最终返回的是匹配分数矩阵。
3、 进行评估。
评估细节用 工具 API实现的,因此这里不做详述。
实际使用推测猜想
本次没有做实际使用demo的相关代码阅读。不过根据evaluate,在实际使用的时候,不管是图像-文本,还是文本-图像,最终的检索结果只能包含于使用的训练数据集中。因为它是根据 索引去 选择预测的结果,而不是生成式的去生成结果。
因此,实际使用中,是需要有这样的一个包含 图像-文本 对儿的数据库去检索的,你输入的单一模态的数据可以不来源数据集,但是它会去数据集中匹配最佳的结果。而不是说像GPT那样你描述一个场景,它去给你生成。当然,GPT等可能也融合了这种检索任务,你描述的场景如果存在,就去检索,不存在则去生成。我感觉那种网上的搜索任务,比如根据问题描述去找解决办法,可以靠这种检索去实现。有的根据描述问题让GPT去编写代码,很大可能都是靠检索去完成的(利用一个很大的代码库,比如github上的,leetcode上的)。实际靠语言模型去回归预测代码的编写感觉不太靠谱。(只限于目前自己的联想,因为学习也是循序渐进的,视野也是逐渐走向开阔的,不可能保证一开始的认知就是正确的,哈哈。如有错误,请求指正。)
二、Visual Question Answering (VQA , 视觉问答)
任务目的
VQA的任务是通过理解图像中的内容并结合问题的文本描述,生成合适的答案 。
回答有关图像的问题。大多数研究人员将其视为一项分类任务,即从答案库中选择正确的答案。
通过给定一个图像和一段关于图像的自然语言,这个任务将提供一个精确的自然语言答案。这个任务可以映射到现实生活的场景中:比如说帮助视障人士,问题和答案都是开放性的。
数据集格式
以VQA 数据集为例,官网🤠
这个数据集的配置分成了四个部分:注释(即答案)、问题、图像、互补对其列表。
1、注释示例
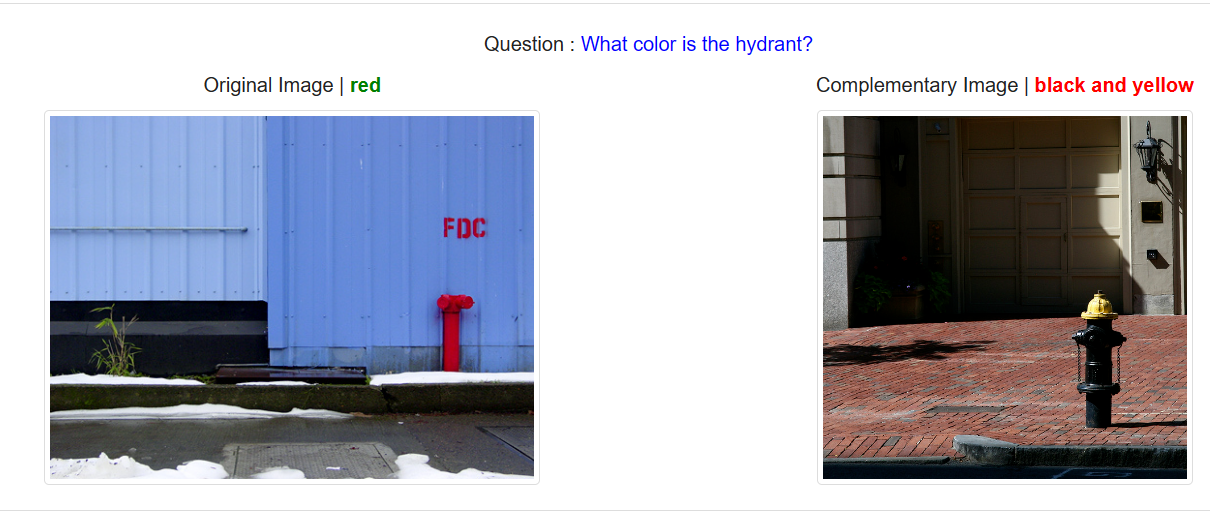
{"question_type": "what is this", "multiple_choice_answer": "net", "answers": [{"answer": "net", "answer_confidence": "maybe", "answer_id": 1}, {"answer": "net", "answer_confidence": "yes", "answer_id": 2}, {"answer": "net", "answer_confidence": "yes", "answer_id": 3}, {"answer": "netting", "answer_confidence": "yes", "answer_id": 4}, {"answer": "net", "answer_confidence": "yes", "answer_id": 5}, {"answer": "net", "answer_confidence": "yes", "answer_id": 6}, {"answer": "mesh", "answer_confidence": "maybe", "answer_id": 7}, {"answer": "net", "answer_confidence": "yes", "answer_id": 8}, {"answer": "net", "answer_confidence": "yes", "answer_id": 9}, {"answer": "net", "answer_confidence": "yes", "answer_id": 10}], "image_id": 458752, "answer_type": "other", "question_id": 458752000} ============= {"question_type": "what", "multiple_choice_answer": "pitcher", "answers": [{"answer": "pitcher", "answer_confidence": "yes", "answer_id": 1}, {"answer": "catcher", "answer_confidence": "no", "answer_id": 2}, {"answer": "pitcher", "answer_confidence": "yes", "answer_id": 3}, {"answer": "pitcher", "answer_confidence": "yes", "answer_id": 4}, {"answer": "pitcher", "answer_confidence": "yes", "answer_id": 5}, {"answer": "pitcher", "answer_confidence": "yes", "answer_id": 6}, {"answer": "pitcher", "answer_confidence": "yes", "answer_id": 7}, {"answer": "pitcher", "answer_confidence": "yes", "answer_id": 8}, {"answer": "pitcher", "answer_confidence": "yes", "answer_id": 9}, {"answer": "pitcher", "answer_confidence": "yes", "answer_id": 10}], "image_id": 458752, "answer_type": "other", "question_id": 458752001},举了两个例子。可以看到一问题有10个答案。这里只列举了两个,其实看那个 image id,一个图片大概可以有五个问题,那么综合起来,每个图片有 5*10=50 个问答场景。
2、问题示例
{"image_id": 458752, "question": "What is this photo taken looking through?", "question_id": 458752000}, {"image_id": 458752, "question": "What position is this man playing?", "question_id": 458752001}, {"image_id": 458752, "question": "What color is the players shirt?", "question_id": 458752002}, {"image_id": 458752, "question": "Is this man a professional baseball player?", "question_id": 458752003},图像id, 问题caption, 以及 问题id。
3、 图像示例
{"file_name": "abstract_v002_train2015_000000011779.png", "image_id": 11779, "height": 400, "url": "http://visualqa.org/data/abstract_v002/scene_img/img/11779.png", "width": 700}, {"file_name": "abstract_v002_train2015_000000005536.png", "image_id": 5536, "height": 400, "url": "http://visualqa.org/data/abstract_v002/scene_img/img/5536.png", "width": 700}, {"file_name": "abstract_v002_train2015_000000016949.png", "image_id": 16949, "height": 400, "url": "http://visualqa.org/data/abstract_v002/scene_img/img/16949.png", "width": 700}, {"file_name": "abstract_v002_train2015_000000019949.png", "image_id": 19949, "height": 400, "url": "http://visualqa.org/data/abstract_v002/scene_img/img/19949.png", "width": 700},图像文件的name, 图像id, 图像的地址url,以及长和宽等信息
4、互补对齐列表示例
[158307014, 254204008], [158307013, 89462005], [472405000, 79224002]两个问题的id。这个是由于存在 当两个不同的图片伴相同的问题, 但是有着不同的答案的场景。
具体地示例展示

训练流程
以ALBEF算法中VQA流程的为例
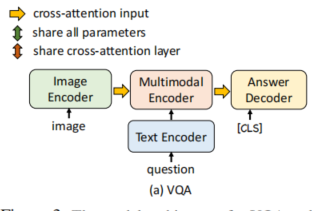
1、image 送入 encoder, 然后与 question token(量化后的) 一起送入Multimodal Encoder(这里 text encoder也一起包含其中了,区分就是Bert的前6层与后6层,以及多模态使用cross attention 层)
2、将 answer 的 token ,上面得到的question state 送入decoder,跟据Bert的流程去计算损失。
ABLEF文中所述采用 condition language-model loss
BERT在第一句前会加一个[CLS]标志,最后一层该位对应向量可以作为整句话的语义表示(即句子embedding),从而用于下游的分类任务等。与文本中已有的其它词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个词的语义信息,从而更好的表示整句话的语义。
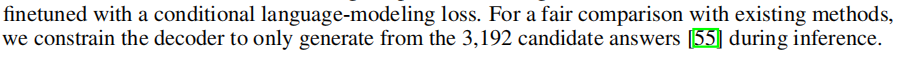
demo以及评估流程
1、将 question 的token 和 image token 送入 多模态Encoder,
2、 然后将answer 的 token, 上面的、得到的question states 送入decoder,采用 cls token对应的序列作为预测输出
(这里暂时有个疑问)
输入包含了answer,text decoder 被用了两次,第一次是与answer id 相关,第二次是通过第一选出来的(根据其topk的索引) input ids 相关。最终将第一次与第二次的输出一起拼接起来做选择。
文中所述,说明在评估或者使用时需要使用 候选的答案的。
且其是生成式的,而不是预测分类索引。
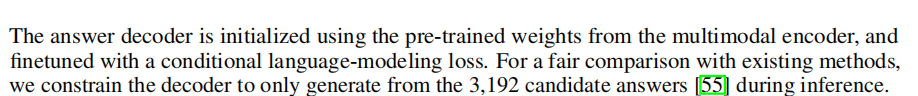

综上,VQA可以是预测answer的索引(相当于one hot 编码),即分类任务。也可以采用语言模型的自回归方式去生成answer的索引,算是回归式任务(回归的目标就是answer词库中被量化的索引,最终回归单词相当于反量化)。但无论哪种,和语言模型一样,answer都有着其事先的“词库”,所以归根结底这还是一个NLP领域的任务,图片只是作为了一种独特的语言描述参与其中。
三、Visual Entailm (VE, 视觉蕴含)
任务目的
给定一个假设,看是否能推理出前提。如果能推理出来则说明是蕴含entailment的关系,推不出来contradictory,无法判断neutral。所以可以说是一个三分类问题。
用来预测图像和文本之间的关系是隐含的、中性的还是矛盾的。
数据集格式
以SNLI-VE 数据集为例,官网👹
下面图片来源于官网


训练流程
1、数据预处理。将 图片, 句子(也就是hypothesis,)和注释labels(也就是标签的类别)组成一个样本对儿。
2、sentence 量化,image送入Image Encoder, 然后与sentence一起送入多模态Encoder中。
3、2中的输出 送入一个分类head, 输出三分类的预测prediction(最终只要 cls token维度的)。
4、用prediction和labels计算损失,损失采用交叉熵。
评估及demo流程
将上述最终的prediction直接取分数最大的维度,做为其预测输出的类别。至于评估指标,为分类准确率。
综上所述,这个任务感觉是 图像-文本匹配任务的进阶版。不同的是由于图像-文本匹配(ITM)只有二分类,其衡量的指标是相似度的大小,嵌合对比学习,所以其更加适配MoCo算法那样去做为预设任务来训练部分模型的表征能力 。而三分类的VE是一个分类任务,其可以做为下游任务,我感觉其也可以像图像分类那样做为迁移学习的预训练任务来训练模型的骨干网络,进而训练一个整体的骨干网络的表征能力。
四、Visual Grounding (VG, 视觉定位)
任务目的
视觉定位(Visual grounding) 是一种在计算机视觉和自然语言处理领域中的概念,指的是将自然语言描述与图像中的特定视觉内容相匹配的过程。听上去和目标检测非常类似,区别在于输入多了语言信息,在对物体进行定位时,要先对语言模态的输入进行理解,并且和视觉模态的信息进行融合,最后利用得到的特征表示进行定位预测。
数据集格式
以MSCOCO数据集为例,官网🧐
下面图片来源于官网
可以看到,每张图片包含了5个描述,以及object segmentation,应该还包括bounding box的信息。举例:
caption:
a surprised looking black cat by a bookcase a black cat sitting next to a bookshelf. a black cat in front of a wooden bookshelf. a black cat staring into the light in front of a bookshelf. black cat sitting in front of a bookshelf. # 书架旁一只一脸惊讶的黑猫 一只黑猫坐在书架旁边。 木制书架前的一只黑猫。 一只黑猫盯着书架前的灯光。 黑猫坐在书架前。


训练流程
ALBEF文中所述
因此其训练流程与 一中 的 文本检索一样。

demo流程
ALBEF中是以 grad CAM 热力图的方式体现出 模型所关注图片中文本所描绘的地方。实际这个领域应该需要去根据文本的描述去定位目标对象,可以以bbox的形式或者分割的形式体现模型的预测输出结果。因此语言描述做为辅助信息,这个任务隶属于CV领域的任务占比更大 。ALBEF的做法只是不同的体现,它可视化了ITR任务中,模型对句子中的成分所关注的图片区域。
五、Natural Language for Visual Reasoning(NLVR2, 自然语言视觉推理)
任务目的
要求模型判断关于图像对地语句是否正确,可将其视为一个二分类任务。视觉推理的自然语言(NLVR2 [19])要求模型预测文本是否描述了一对图像。
数据集格式
NLVR2数据集, 官网 🤓
训练过程
模型需要输入一对儿图片,因此,Image Encoder 和 Multimodal block 被用两次。
ALBEF中
其做了扩展,看作了三分类问题,也就是分类文本匹配第一图像、匹配第二个图像还是都不匹配。
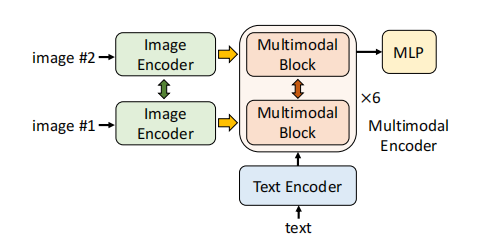

感觉这个和视觉蕴含(VE)任务很想。视觉蕴含是一个图像去判断句子的匹配度,换另一个视觉,一个图像对三种类别的句子有着不同的匹配程度,属于单一图像 对 三个句子的可能性范畴(自己瞎起的)。而这个NLVR任务是判断描述是否匹配了一对儿图像 ,ALBEF做了扩展,使其有三种可能,换个角度看,一个描述语句对三种类别(两个图像外加一个空类别)的图像有着不同的匹配程度,属于单一句子 对 三个图像的可能性范畴。
















 309
309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











