






什么是视觉蕴含:
视觉蕴涵是最近提出的多模态推理任务,其目标是预测一段文本与一幅图像的逻辑关系,是来自 Visual Entailment Task for Visually-Groundwd Language Learning 这篇论文,将图像作为验证假设的前提,来验证预测的准确性。
Xieet等人提出了 Visual Entailment (VE) 任务。 (2019),前提是真实的世界图像Pimage,假设为文本Htext,给定一个样本(Pimage,Htext),VE任务的目标是确定根据信息Pimage能否可以得出结论Htext。根据以下协议,样品的标签被分配为
1.Entailment(蕴含),如果Pimage有足够的证据证明Htext是正确的。
2.Contradiction(矛盾),如果PimagePimage有足够的证据证明Htext是错误的。
3.Neutral(中立的),如果PimagePimage有没有足够的证据来得出Htext的结论。
Baseline:
UpDn(Anderson et al., 2018)视觉问答模型, AReg(Ramakrishnan et al., 2018), RUBi(Cadene et al., 2019)捕捉单模态偏见, LMH(Clark et al., 2019)采用集成方法来减少语言先验(通过惩罚可以在不使用图像内容的情况下回答的样本来减少问答对之间的所有偏差。), RankVQA(Qiao et al., 2020), SSL(Zhu et al., 2020)(首先自动生成一组平衡的问题图像对,然后引入辅助自监督任务来使用平衡数据), CSS(Chen et al., 2020a)(通过添加更多互补样本来平衡数据,这些样本是由图像中的掩码或问题中的一些关键字生成的。), CL(Liang et al., 2020)(强制模型利用互补样本和原始样本之间的关系) and LXMERT(Tan and Bansal, 2019).
论文而提出的背景(针对怎样的问题提出了该方法):
原有的一些方法,主要分为两类:一个是基于集成的方法Designing Specific Debiasing Models to Reduce Biases,一个是仔细构建更平衡的数据集Data Augmentationto Reduce Biases,例如:LMH,SSL(专为解决语言先验而设计的模型)存在不考虑或检查答案的真实性,都是根据最佳输出预测正确答案,并且这些方法并没有很好的利用答案间的语义信息来帮助缓解语言先验。
论文框架:
基于原先已有的答案重排的方法,本文提出了一种基于Visual Entailment的select-and-rerank (SAR) 渐进式框架。具体来说就是先选择与问题或图像相关的候选答案,然后通过视觉蕴含任务对候选答案进行重新排序,从而验证图像在语义上是否包含问题和每个候选答案的综合陈述,提供给模型再次选择答案的机会。
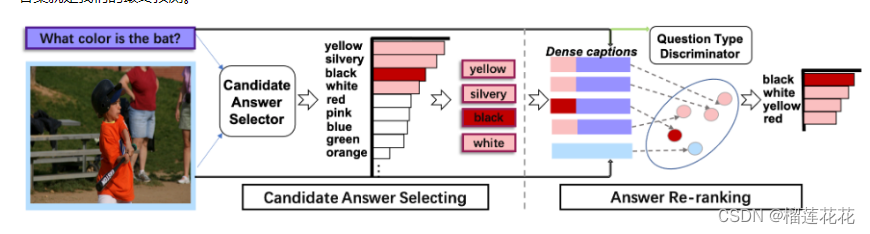
该框架由候选答案选择模块和答案重新排序模块组成,在候选答案模块,给定一个图像和一个问题,我们首先使用已有的VQA模型获得前top-N个答案组成的候选答案集,从而过滤掉很多的无关的答案(因为一般的正确答案都是出现在前N个答案中),然后将VQA设计为Answer Re-ranking 模块中的 VE (the image is premise and the synthetic dense caption,is hypothesis.)任务,使用LXMERT作为VE评分器来计算相关(图像字幕对的蕴含)分数,从而得分最高的作为最终答案
CAS:
候选答案选择器,从所有的可能答案中选择几个作为候选答案,缩小预测空间,CAS根据输入的图像Ii和输入的问题Qi,将会给出回归分数:P(A|Qi,Ii),最后候选答案选择其从A中选出top-N个分数最高的答案作为候选答案:
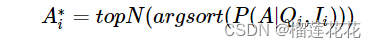
其中N为超参数,候选答案和每个数据队列将形成包含M*N个数据的新的数据集:
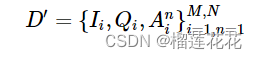
在该篇论文中主要使用SSL 作为CAS。
论文的创新点:
先用已有的减少语言先验的模型来获得候选答案将预测空间缩小,然后通过基于VE任务来完成SAR得出最终答案(相当于再给模型一次选择答案的机会).
问题答案组合策略:
R:replace question category prefix with answer (问题类别前缀替换成答案)
C:Concatenate question and answer directly(直接串联问题和答案)
R->C:在训练时使用R策略防止过度关注问题类别和答案之间的共现关系,在测试时使用C策略,引入更多信息进行推理
损失函数:

其中Trm()表示经过LXMERT之后的一维输出,ti^n表示第n个答案的mult-label soft loss.

调整后的损失函数为:

论文结果及数据分析 :
在两个基准 VQA-CP-v2 和 VQA-v2 上的性能如下图所示。分别报告了 SAR、SAR+SSL 和 SAR+LMH 在 3 个问答组合策略中的最佳结果。 “TopN-”表示候选答案(由 CAS 选择)输入 Answer Re-ranking 模块进行训练。 我们的方法是用 N(12 和 20) 的两种设置进行评估的。




论文提出的未来发展方向:
如何提高该模型的通用性进一步将语言优先性与回答问题之间的权衡转化为双赢的结果是未来一个很有前途的研究方向。















 958
958











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









