






这篇文章算是个小备忘录,未来大模型想要继续增加智力的核心在于如何找到“算力”投入点。
怎么理解下标红部分的意思。大家应该都知道,当前决定大模型效果的主要是数据量(质量),参数规模等。为什么是算力呢?
智力通常是难以衡量的,而算力则可以定量分析的。这也是为什么我们需要将算力和智力进行关联。我们先来看看,如何计算算力的投入。算力并不是自然而然存在的,是其他因数决定的,也就是前面的数据量,参数规模等。
通常消耗的算力(C)是由模型参数(P)、推理输出长度(L)以及其他因素(如数据量D 等)决定的情况。
我们先定义算力
C 是参数P、推理长度L 和数据量D 的函数。例如,算力是这三个因素的乘积或某种加权组合,公式可以写为:
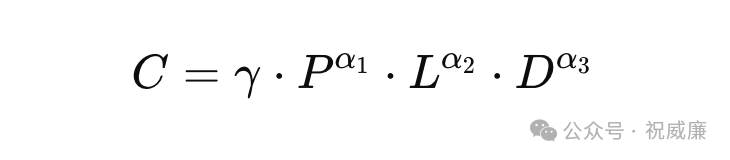
解释:
C 是算力,表示模型计算所需的资源。
P 代表模型参数的规模或复杂度。
L 代表推理的输出长度。
D 代表数据量。
γ 是一个常数,用于调节算力的基础水平。
α1,α2,α3 是不同因素对算力影响的权重,反映了每个因素的重要性。
2. 智能公式:
智能(I)可以是算力和其他不可见因素的模糊函数,表示通过算力提升可能带来的智能增长。由于智能难以定量分析,我们可以用一个非线性函数来表示智能随算力的提升关系(也可能是线性的,how knows):
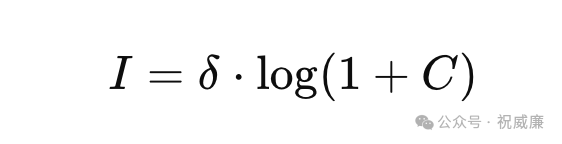
解释:
I 是智能,表示模型表现出的智能水平。
C 是前面算力的结果。
δ 是一个调节智能增长的常数。
log(1+C) 表示智能随算力非线性增长,尤其在算力较小的时候,智能的增长速度较快,而当算力达到一定水平后,智能的提升趋缓(类似于边际效应递减)。
综合公式:
将算力和智能的公式结合起来,我们可以得到一个完整的描述模型:
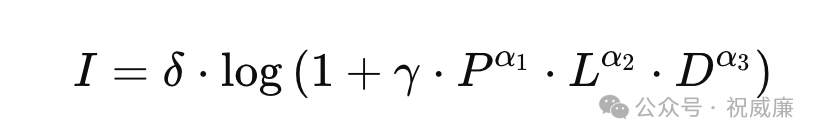
但这其实不是我们想要的,我们更关心第一个公式:
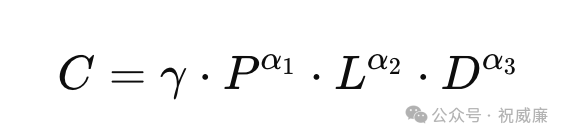
如果想让 C 更加大,就需要
找到新的使用算力的因子,我们还可以怎么使用算力,除了 P,L,D ?
能否在 P,L,D 不变的情况,增大各自的a1, a2, a3 指数?比如更好的数据清洗,更好的模型结构,从而极大了算力的使用。
或者提高 γ , 如何提升γ? 算力精度的提升?我们知道在深度学习中对数字精度相对来说没有那么敏感,但是我们为了性能,往往妥协了精度。
最后,如何支撑 C 的扩大导致的能源消耗,则是另外一个问题。
但我相信:
随着时间发展,整个AI产业芯片一定是白菜价
如何支撑C 的扩大核心还是能源


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









