







为什么是英文标题呢,因为这个算法还没有正式的翻译,为2015年的Science上发表的一个算法。非常好,在我的论文里涉及到了这个算法的使用。这里记录一下这个算法。
如果要英文原文的,就去谷歌搜索这个标题就好了。至于能不能免费看,要看有没有人提供或者购买。
聚类算法
本身聚类算法大家应该非常熟悉,聚类算法应用领域非常广泛,甚至从天文学到生物学都有很多应用。其中最熟悉的一些包括:K-means和K-medoids算法,根据到中心的距离来进行聚类。
这些聚类算法的缺点
这种基于距离的聚类算法都有一个通病,就是距离中心近就可以要,不进就分到其他中心,那么有个问题,就是这种聚类一定是聚类圆形数据的,到中心一定距离,出来的就是一个圆形区域。那么有个问题!
如果是一个不规则形状的高密度的区域,聚类就会出现点分配出问题的情况
其实还有包括受异常值影响比较大等缺点。
基于密度的聚类
所以这个文章是基于密度的聚类算法,这个方法和K-medioids比较像,它只要有基本的数据点之间的距离就可以。就像DBSCAN( 维基百科 )方法,它可以检测非圆形的聚类(clusters),并且可以自动的修正聚类的数目。
该算法是基于这样的假设:类簇中心被具有较低局部密度的邻居点包围,且与具有更高密度的任何点有相对较大的距离。
所以需要计算的,对于每个数据点i, 计算两个变量:一个是数据点i所在位置的密度 P_i 和到更高密度局部点的距离. 这两个数据取决于数据点之间的距离d_ij. 公式如下:
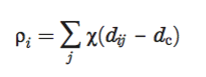
下面贴一下原文:

意思就是说这X(x)的是一个隔断值,只能为0或者1. 大于d_c就是1,小于就是1.因为这个算法是仅仅是相对点的密度明暗,所以在应用中,大数据的情况,鲁棒性非常高,不会由于d_c的细微选择误差造成整体的性能变差。
上面是密度下面要计算数据点i到密度更大的局部点的距离:
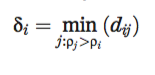
然后找到最大的那个密度的点。聚类的中心就是那个值特别大的。
下面上下论文里的样例:
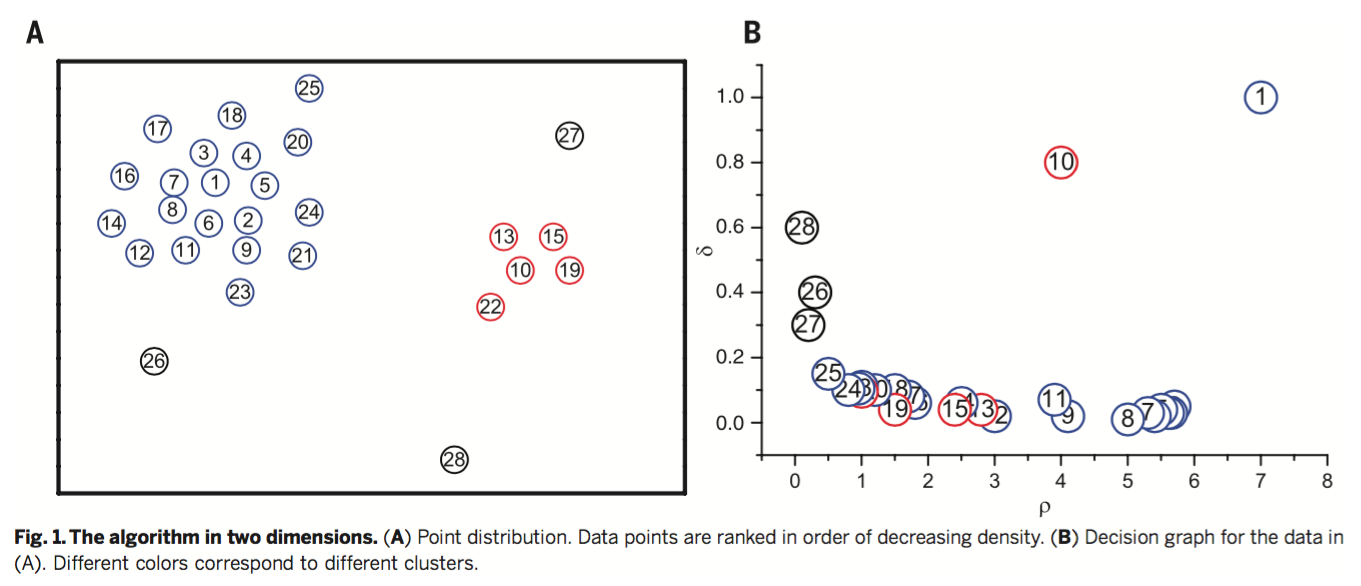
看到这里面密度最大的是1 和 10 ,其中28、26、27属于异常数据,可以去除。
算法限制
这个算法的一个限制就是数据集必须是定义在坐标上的并且计算代价比较高的。
总结
以上是整个算法的流程,虽然整个算法比较简单,但是整个算法的效果是非常好的。此算法发表于2014年上的Science上。















 297
297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









