







机器学习主要分为三大类,有监督学习、无监督学习和增强学习,其中前两大类大家已经很熟悉了,第三类增强学习是指如何在得到临时性的反馈下学习,bandit问题就是增强学习领域一个热门的研究方向。而我目前就在做这部分的研究,所以先从这个问题讲起。
我们一般考虑的bandit(强盗)带有K个arm,每个回合拨动一个arm,得到一个奖励,bandit问题就是研究如何使这些奖励最大化。但由于通常回合数是不固定的,因此我们无法得到一个固定的目标函数,从而求取它的极值。bandit问题是一个online问题,我们只能对比算法与最优arm之间的差别,称之为regret。假设arm i在第t个时刻得到的奖励为Xi,t,算法在第t个时刻选取了arm It,则regret有下式
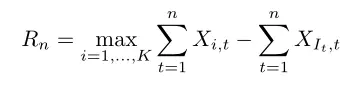
一般来说,Xi,t和It都是有一定的随机性,所以我们经常会考虑regret的期望,而max的期望有时不太好算,因此也会考虑pseudo-regret,即
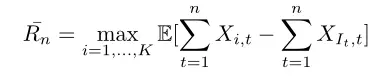
根据得到的奖励与arm之间的关系,可以将bandit问题分为三大类。
Stochastic
假设每拨动arm i得到的奖励服从一个[0,1]上的分布P_i。
已知arm的个数K,与回合数n>K。对每个回合t=1,2,...
(1)玩家选取arm It
(2)给定It,环境从分布P_i中取出一个reward X_{It,t}
由于每个arm得到的reward服从分布,则在stochastic情况下考虑pseudo-regret更合适。设分布P_i的均值为ui,ui的最大值为u*,即为优化
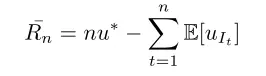
Adversarial
已知arm的个数K,与回合数n>K。对每个回合t=1,2,...
(1)玩家选取arm It
(2)同时,环境选取奖励向量R_t=(R_1t,R_2t,...,R_Kt)
(3)同时选取完之后,玩家获得他对应的奖励R_It,t
从过程中可以看出,针对此问题设计的算法必须是randomized,否则无论什么样的算法都会有可能持续碰到特别差的奖励,也就使得问题没有提升的可能。R_t可以与玩家过去的选取有关,也可以无关,分别对应于nonoblivious和oblivious的情形。
Markov
每个arm i都对应了一个状态空间Si,Si包含了arm i可能服从的分布。当t时刻玩家选取了arm i,则玩家得到服从当前分布的reward,同时状态由变换矩阵更新为新的状态,其他没动的arm的状态不变。
最近,由于数据量过大或者我们希望设计的算法可以根据实际情况自我调整,于是我们开始考虑online的优化问题,而不仅仅是过去的offline。在offline的情况下,需要最优化的目标函数是固定的,于是我们可以考虑它的极值。但在online框架下,没有一个固定的目标函数,很多过去求极值的方法不能解决新的问题,于是发展了一套online凸优化的技巧。而bandit问题就是online问题的一个重要的实例,它的主要问题是上述的三大类,当然也有很多小的变型,同时也有组合bandit问题出现,即每次拨动一个arm的组合,以后有机会可以写写这些。















 1106
1106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









