







tips
锁解决相关
show OPEN TABLES where In_use > 0
show status like 'table%';
show engine innodb status\G
show processlist;
开启慢日志
mysqldump 导出问题
Unknown table 'column_statistics' in information_schema (1109)
添加参数–column-statistics=0
清空缓存
reset query cache; --清空缓存
查看sql各阶段执行时间
set profiling=1;
show profiles;
show profile for query 3;
当前数据库进程
show full processlist;
mysql地位
什么都不说,先看张图
https://db-engines.com/en/rankin
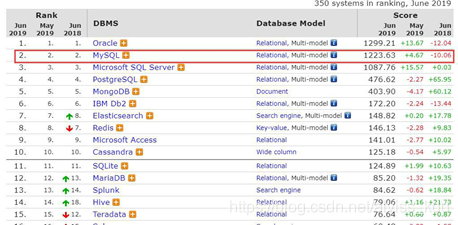
在所有数据库中,MySql 排在第二,而 nosql 中 mongodb 排在第一,你可能在想是不是有必要把 Oracle 也学习下,别着急,再看张图
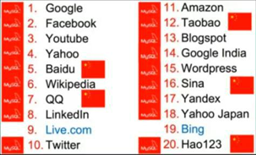
全球访问量最大的 20 家网站,他们分别使用了什么数据库呢,绝大多数使用 mysql,有两个完整 live.com 和 bing 使用的是 mssql,并不是他们使用不了 mysql,而是他要支持自己的数据库。
在国外可能挺多使用 mssql 或者 oracle 的,但是在过能,在去 IOE 的大背景下,包括银行在内的很多传统公司慢慢都在像 mysql 转型,不过其中有个老大不掉的公司,中国电力,依然使用 oracle,在十年的时间仅仅在 oracle 的使用上,中国电力就支出 390 几个亿,平均一年30,40个亿,它有钱,如果你所在公司随随便便也能拿个几百个亿,那你也用 oracle 吧
mysql 安装
准备工作
Linux 使用的版本是 centos 7,为方便起见,先把防火墙关闭,配置好网络,在安装部分,会分成两部分讲,首先讲单实例安装,也就是一台服务器上就装一个 mysql,接下来就多实例安装,在一个服务器上安装 2 个甚至多个 mysql.
单实例安装
set global show_compatibility_56=on
cp /soft/mysql-5.7.9-linux-glibc2.5-x86_64.tar.gz /usr/local/
解压mysql 到/usr/local 目录
解压:
tar -zxvf mysql-5.7.9-linux-glibc2.5-x86_64.tar.gz
安装需要的依赖
yum install -y libaio
具体安装
shell> groupadd mysql
shell> useradd -r -g mysql mysql
shell> cd /usr/local
shell> tar zxvf /path/to/mysql-VERSION-OS.tar.gz
shell> ln -s full-path-to-mysql-VERSION-OS mysql
shell> cd mysql
shell> mkdir mysql-files
shell> chmod 770 mysql-files
shell> chown -R mysql .
shell> chgrp -R mysql .
shell> bin/mysqld --initialize --user=mysql # MySQL 5.7.6 and up
shell> bin/mysql_ssl_rsa_setup # MySQL 5.7.6 and up
shell> chown -R root .
shell> chown -R mysql data mysql-files
shell> bin/mysqld_safe --user=mysql &
# Next command is optional
shell> cp support-files/mysql.server /etc/init.d/mysql.server
配置环境变量:
export PATH=/usr/local/mysql/bin:$PATH
配置开启启动
chkconfig mysql.server on
chkconfig --list
登陆,修改密码
set password = 'root1234%';
允许远程登陆
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root1234%' WITH GRANT OPTION;
flush privileges;
启动的时候可能会报错
这是因为 mysql 启动的时候需要配置文件,而在安装 centos 的时候,哪怕是 mini 版本都会有个默认的配置在/etc 目录中
/usr/local/mysql/bin/mysqld --verbose --help |grep -A 1 'Default options'
Default options are read from the following files in the given order: /etc/my.cnf /etc/mysql/my.cnf /usr/local/mysql/etc/my.cnf ~/.my.cnf
Mysql 启动的时候会以上面所述的顺序加载配置文件
如果报错,先重命名 my.cnf 文件
多实例安装
以前一些很 low 的方法是,解压两个 mysql,分别放到不同文件夹,其实在 mysql 中已经考虑到了多实例安装的情况。也有相应的脚本命令的支持。
现在要求装两个 mysql 一个 3307,3308
新建 /etc/my.cnf 配置如下
[mysqld]
sql_mode = "STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION,NO_ZERO_DATE,NO_ZERO_IN_DATE,ERROR _FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER"
[mysqld_multi]
mysqld = /usr/local/mysql/bin/mysqld_safe
mysqladmin = /usr/local/mysql/bin/mysqladmin
log = /var/log/mysqld_multi.log
[mysqld1]
server-id = 11
socket = /tmp/mysql.sock1
port = 3307
datadir = /data1
user = mysql
performance_schema = off
innodb_buffer_pool_size = 32M
skip_name_resolve = 1
log_error = error.log
pid-file = /data1/mysql.pid1
[mysqld2]
server-id = 12
socket = /tmp/mysql.sock2
port = 3308
datadir = /data2
user = mysql
performance_schema = off
innodb_buffer pool_size = 32M
skip_name_resolve = 1
log_error = error.log
pid-file = /data2/mysql.pid2
创建 2 个数据目录
mkdir /data{1..2}
chown mysql.mysql /data{1..2}
mysqld --initialize --user=mysql --datadir=/data1
mysqld --initialize --user=mysql --datadir=/data2
cp /usr/local/mysql/support-files/mysqld_multi.server /etc/init.d/mysqld_multid
配置开机启动
chkconfig mysqld_multid on
查看状态 mysqld_multi report

这个时候发现还需要 perl 的环境,安装 yum -y install perl perl-devel
在运行,发现已经有实例了mysqld_multi report
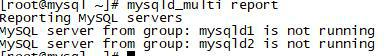
mysqld_multi start启动,分别修改密码,允许远程连接
mysql -u root -S /tmp/mysql.sock1 -p -P3307
mysql -u root -S /tmp/mysql.sock2 -p -P3308
set password = 'root1234%';
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root1234%';
flush privileges;
Mysql 权限
最简单的 MySql 权限
最简单也是最高效的,如何解决新手们删库跑路的问题其实也是很简单的,对于正式库只给一个增删改查的权限,或者只给一个查询权限(是不是就解决了删库的可能性?)
以下内容如果看官是大牛,请稍安勿躁,我讲内容的方式是从简单到入门,从入门到进阶,从进阶到实战,从实战到。。。(包你满意)
使用 root 用户,执行
grant SELECT on mall.* TO 'dev'@'192.168.244.%' IDENTIFIED BY '123' WITH GRANT OPTION;
很简单的一句 sql,创建了一个 dev 的用户,密码为 123,仅仅运行在网段为 192.168.0.*的网段进行查询操作。
再执行一条命令
show grants for 'dev'@'192.168.244.%'

不错,可以链接,也可以执行 select,这个时候还想删库?做梦吧~
深入研究下 MySQL 权限
用户标识是什么
上面一句简单的 SQL 堪称完美的解决了程序员新手的删库跑路的问题,高兴吧,你学到了新姿势,但是如果想面试给面试管留下好映像,上面的知识好像还不够,有必要好好深入研究下 MySql 的权限了。
这里有个小的知识点需要先具备,在 mysql 中的权限不是单纯的赋予给用户的,而是赋予给”用户+IP”的。
比如 dev 用户是否能登陆,用什么密码登陆,并且能访问什么数据库等都需要加上 IP,这样才算一个完整的用户标识,换句话说 ‘dev’@‘192.168.0.168’ 、 ‘dev’@‘127.0.0.1’ 与 ‘dev’@‘localhost’ 这 3 个是完全不同的用户标识(哪怕你本机的 ip 就是 192.168.0.168)。
用户权限涉及的表
有了用户标识的概念接下来就可以看权限涉及的表了,这也是面试的时候加分项哦。
有几张表你可以好好的记记的,mysql.user,mysql.db,mysql.table_priv,mysql.column_priv
你可以熟悉其中的 user 表,甚至手动的改过里面的数据(不合规范哦!)
那这些表有什么用,和权限又有什么关系呢?
- User 的一行记录代表一个用户标识
- db 的一行记录代表对数据库的权限
- table_priv 的一行记录代表对表的权限
- column_priv 的一行记录代表对某一列的权限
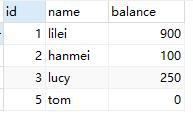
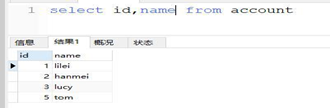
新建一个表 account
DROP TABLE IF EXISTS `account`;
CREATE TABLE `account` (
`id` int(11) NOT NULL,
`name` varchar(50) DEFAULT NULL, `balance` int(255) DEFAULT NULL, PRIMARY KEY (`id`),
KEY `idx_balance` (`balance`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `account` VALUES ('1', 'lilei', '900');
INSERT INTO `account` VALUES ('2', 'hanmei', '100');
INSERT INTO `account` VALUES ('3', 'lucy', '250');
INSERT INTO `account` VALUES ('5', 'tom', '0');

很诧异吧,mysql 其实权限并不事特别 low,权限的粒度甚至到了某一列上,举例来说,有个表 account 表
。
对于前面创建的 dev 用户我不想让他访问 balance 列,但是 id 和 name 列是可以访问的,这样的需求在工作中不是没有。
grant select(id,name) on mall.account to 'dev'@'192.168.244.%';
查看权限

REVOKE SELECT on mall.* from 'dev'@'192.168.244.%'
你使用 dev 登陆查询试试

你再要查询所有记录?不好意思不让查
而你查询 id,name 查询又是可以了。
Mysql 的角色
准备工作
MySql 基于 ” 用户 +IP” 的这种授权模式其实还是挺好用的,但如果你使用 Oracle 、PostgreSQL、SqlServer 你可能会发牢骚。
这样对于每个用户都要赋权的方式是不是太麻烦了,如果我用户多呢?有没有角色或者用户组这样的功能呢?
好吧,你搓中了 mysql 的软肋,很痛,在 mysql5.7 开始才正式支持这个功能,而且连 mysql 官方把它叫做“Role Like”(不是角色,长得比较像而已,额~~~)?
好咧,那在 5.7 中怎么玩这个不像角色的角色呢?
show variables like "%proxy%"
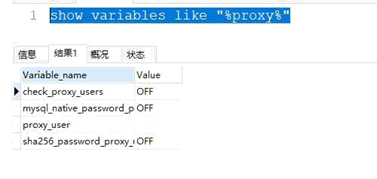
你得先把 check_proxy_users,mysql_native_password_proxy_users 这两个变量设置成 true才行
set GLOBAL check_proxy_users =1;
set GLOBAL mysql_native_password_proxy_users = 1;
当然,你也可以把这两个配置设置到 my.cnf 中
创建一个角色
create USER 'dev_role'
可能被你发现了,我这里创建得是个 user,为了稍微像角色一点点,我给这 user 取名叫dev_role,而且为了方便也没用使用密码了。
创建 2 个开发人员账号
create USER 'deer'
create USER 'enjoy'
这两个用户我也没设置密码
把两个用户加到组里面
grant proxy on 'dev_role' to 'deer'
grant proxy on 'dev_role' to 'enjoy'
可以看下其中一个用户的权限
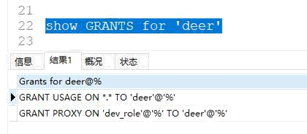
这里有个小的地方需要注意:如果你是远程链接,你可能会收获一个大大的错误,你没有权限做这一步,这个时候你需要再服务器上执行一条
GRANT PROXY ON ''@'' TO 'root'@'%' WITH GRANT OPTION;
给角色 dev_role 应该有的权限
有了用户了,这用户也归属到了 dev_role 这角色下面,那接下来要做的就很简单了,根据业务需求给这角色设置权限就好了
grant select(id,name) on mall.account to 'dev_role'
测试
好咧,大功告成,现在使用’deer’用户登陆系统试试
select id ,name from mall.account
学到了吧,涨到姿势了吧,你可能又会问,这种角色的权限是存哪的呢?给你看表
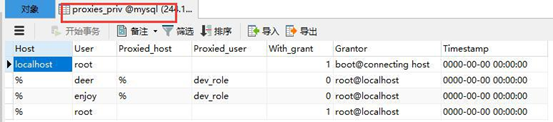
MySql数据类型
int类型
| 类型 | 字节 | signed | unsigned |
|---|---|---|---|
| tinyint | 1 | -128 127 | 0 255 |
| smallint | 2 | -32768 32767 | 0 65535 |
| mediumint | 3 | ||
| int | 4 | ||
| bigint | 8 |
有无符号
在项目中使用 BIGINT,而且是有符号的。
涉及到计算的所有列不能使用unsigned,出现负数时报错。
演示
create table test_unsigned(a int unsigned, b int unsigned);
insert into test_unsigned values(1, 2);
select b - a from test_unsigned;正常执行
select a - b from test_unsigned;–运行出错

INT(N)是什么?
演示
create table test_int_n(a int(4) zerofill);
insert into test_int_n values(1);
insert into test_int_n values(123456);
- int(N)中的 N 是显示宽度, 不表示 存储的数字的 长度 的上限。
- zerofill 表示当存储的数字 长度 < N 时,用 数字 0 填充左边,直至补满长度 N
- 当存储数字的长度 超过 N 时 ,按照 实际存储 的数字显示
自动增长的面试题
这列语法有错误吗?
create table test_auto_increment(a int auto_increment);
create table test_auto_increment(a int auto_increment primary key);

一个表只能用一个自增列,且必须为建值。
以下结果是什么?
insert into test_auto_increment values(NULL);
insert into test_auto_increment values(0);
insert into test_auto_increment values(-1);
insert into test_auto_increment values(null),(100),(null),(10),(null);
自增列,可以插入负值,不插入值会默认按着当前AUTO_INCREMENT值插入
CREATE TABLE `test_auto_increment` (
`a` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`a`)
) ENGINE=InnoDB AUTO_INCREMENT=104 DEFAULT CHARSET=utf8mb4
字符类型
| 类型 | 说明 | N的含义 | 是否有字符集 | 最大长度 |
|---|---|---|---|---|
| char(N) | 定长字符 | 字符 | 是 | 255 |
| varchar(N) | 变长字符 | 字符 | 是 | 16384 |
| BINARY(N) | 定长二进制字节 | 字节 | 否 | 255 |
| VARBINARY(N) | 变长二进制字节 | 字节 | 否 | 16384 |
| TINYBLOB(N) | 二进制大对象 | 字节 | 否 | 256 |
| BLOB(N) | 二进制大对象 | 字节 | 否 | 16K |
| MEDIUMBLOB(N) | 二进制大对象 | 字节 | 否 | 16M |
| LONGBLOB(N) | 二进制大对象 | 字节 | 否 | 4G |
| TINYTEXT(N) | 大对象 | 字节 | 是 | 256 |
| TEXT(N) | 大对象 | 字节 | 是 | 16K |
| MEDIUMTEXT(N) | 大对象 | 字节 | 是 | 16M |
| LONGTEXT(N) | 大对象 | 字节 | 是 | 4G |
排序规则
select 'a' = 'A';
create table test_ci (a varchar(10), key(a));
insert into test_ci values('a');
insert into test_ci values('A');
select * from test_ci where a = 'a';
–结果是什么?
出现两行数据。
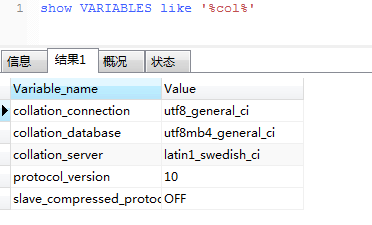
set names utf8mb4 collate utf8mb4_bin
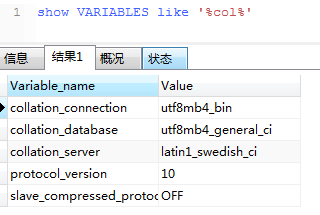
老子没看出区别,说是校验规则cs,没看到
时间类型
| 日期类型 | 占用空间 | 表示范围 |
|---|---|---|
| DATETIME | 8 | 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59 |
| DATE | 3 | 1000-01-01 ~ 9999-12-31 |
| TIMESTAMP | 4 | 1970-01-01 00:00:00UTC ~ 2038-01-19 03:14:07UTC |
| YEAR | 1 | YEAR(2):1970-2070, YEAR(4):1901-2155 |
| TIME | 3 | -838:59:59 ~ 838:59:59 |
datatime 与 timestamp 区别
这里的timestamp不是oracle时间戳,只是带有时区的时间。
create table test_time(a timestamp, b datetime);
insert into test_time values (now(), now());
select * from test_time;
select @@time_zone;
set time_zone='+00:00';
select * from test_time;
json类型
后面整理。有这功夫,为什么不用MongoDB。。。
MySQL架构
体系架构图
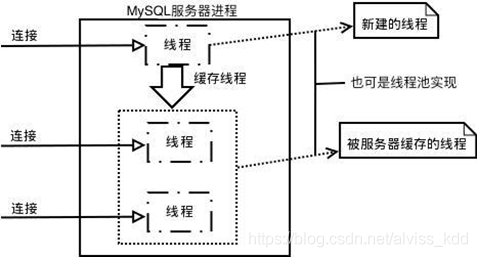
连接层
当 MySQL 启动(MySQL 服务器就是一个进程),等待客户端连接,每一个客户端连接请求,服务器都会新建一个线程处理(如果是线程池的话,则是分配一个空的线程),每个线程独立,拥有各自的内存处理空间
show VARIABLES like ‘%max_connections%’
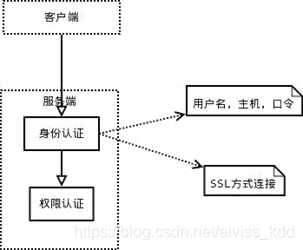
连接到服务器,服务器需要对其进行验证,也就是用户名、IP、密码验证,一旦连接成功,还要验证是否具有执行某个特定查询的权限(例如,是否允许客户端对某个数据库某个表的某个操作)
SQL处理层

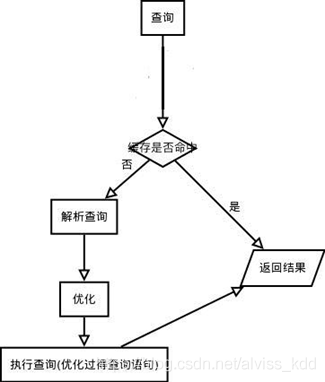
这一层主要功能有:SQL 语句的解析、优化,缓存的查询,MySQL 内置函数的实现,跨存储引擎功能(所谓跨存储引擎就是说每个引擎都需提供的功能(引擎需对外提供接口)),例如:存储过程、触发器、视图等。
1.如果是查询语句(select 语句),首先会查询缓存是否已有相应结果,有则返回结果,无则进行下一步(如果不是查询语句,同样调到下一步)
2.解析查询,创建一个内部数据结构(解析树),这个解析树主要用来 SQL 语句的语义与语法解析;
3.优化:优化 SQL 语句,例如重写查询,决定表的读取顺序,以及选择需要的索引等。这一阶段用户是可以查询的,查询服务器优化器是如何进行优化的,便于用户重构查询和修改相关配置,达到最优化。这一阶段还涉及到存储引擎,优化器会询问存储引擎,比如某个操作的开销信息、是否对特定索引有查询优化等。
查询缓存
show variables like '%query_cache_type%' -- 默认不开启
show variables like '%query_cache_size%' --默认值 1M
SET GLOBAL query_cache_type = 1; --会报错,这些缓存的东西都是启动分配的
query_cache_type 只能配置在 my.cnf 文件中,这大大限制了 qc 的作用。
在生产环境建议不开启,除非经常有 sql 完全一模一样的查询。
QC 严格要求 2 次 SQL 请求要完全一样,包括 SQL 语句,连接的数据库、协议版本、字符集等因素都会影响
解析查询顺序

优化
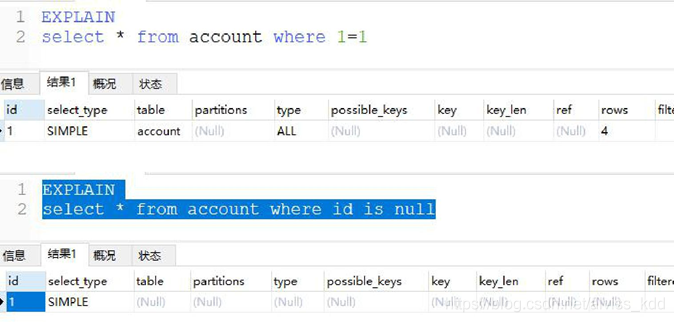

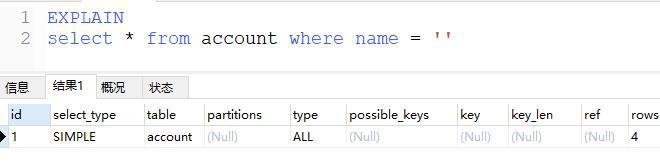
通过上面的 sql 大概就能看出,虽然现在还没学执行计划,但通过这个已经看出一个 sql 并不一定会去查询物理数据,sql 解析器会通过优化器来优化程序员写的 sql,因为啥,因为id是自增住建啊。
下面一个自动优化的SQL
explain select * from account t where t.id in (select t2.id from account t2);
show warnings;
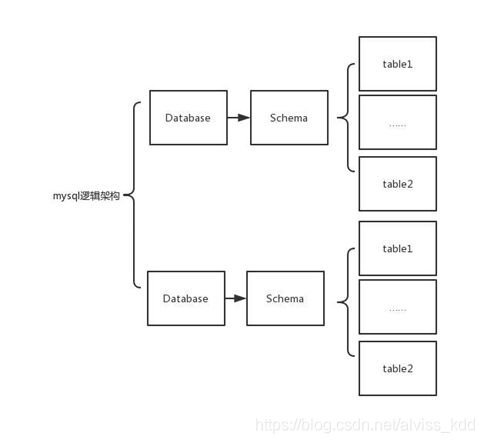
逻辑架构
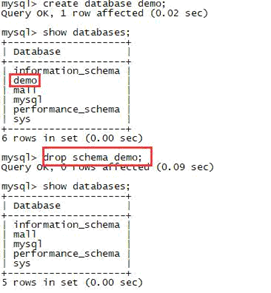
在 mysql 中其实还有个 schema 的概念,这概念没什么太多作用,只是为了兼容其他数据库,所以也提出了这个。
在 mysql 中 database 和 schema 是等价的。在很多数据库钟,比如oracle中,只有一个数据库,存在多个schema。
create database demo;
show databases;
drop schema demo;
show databases;

物理存储结构
数据目录(DataDir)
mysql 安装的时候都要指定 datadir,其查看方式为:
show VARIABLES like 'datadir'
其规定所有建立的数据库存放位置
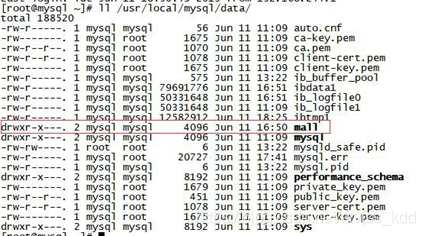
数据库目录
创建了一个数据库后,会在上面的 datadir 目录新建一个子文件夹,每个库单独存在
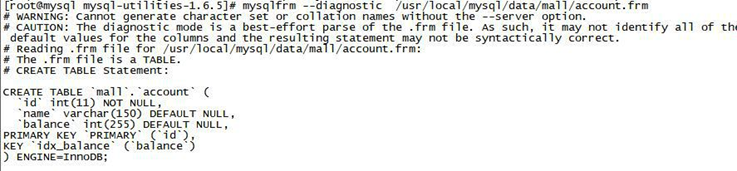
表文件
创建了一个数据库后,会在上面的 datadir 目录新建一个子文件夹
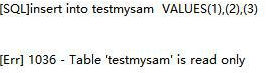
用户建立的表都会在上面的目录中,它和具体的存储引擎相关,但有个共同的就是都有个 frm 文件,它存放的是表的数据格式即表结构。
Linux直接查看表结构,我也不懂有啥用
mysqlfrm --diagnostic /usr/local/mysql/data/mall/account.frm
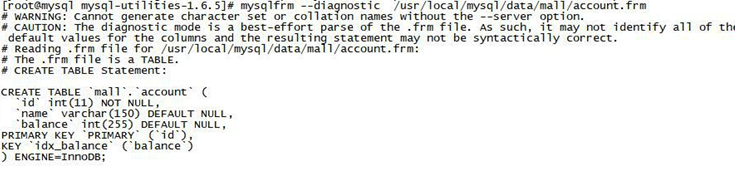
mysql 管理工具 utilities 安装
我也没用过
tar -zxvf mysql-utilities-1.6.5.tar.gz
cd mysql-utilities-1.6.5
python ./setup.py build
python ./setup.py install
存储引擎
看你的 mysql 现在已提供什么存储引擎:
mysql> show engines;
看你的 mysql 当前默认的存储引擎:
mysql> show variables like '%storage_engine%';
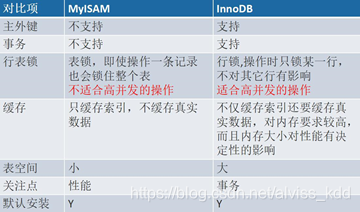
MyISAM
MySql 5.5 之前默认的存储引擎
MyISAM 存储引擎由 MYD 和 MYI文件 组成
CREATE TABLE testmysam (id INT PRIMARY KEY) ENGINE = myisam
insert into testmysam VALUES(1),(2),(3)
压缩功能
myisampack -b -f /usr/local/mysql/data/mall/testmysam.MYI
压缩后再往表里面新增数据就新增不了
insert into testmysam VALUES(1),(2),(3)

压缩后,需要
myisamchk -r -f /usr/local/mysql/data/mall/testmysam.MYI
适用场景
- 非事务型应用(数据仓库,报表,日志数据)
- 只读类应用
- 空间类应用(空间函数,坐标)
由于现在 innodb 越来越强大,myisam 已经停止维护
绝大多数场景都不适合
Innodb
基本特征
- Innodb 是一种事务性存储引擎
- 完全支持事务得 ACID 特性
- Redo Log 和 Undo Log
- Innodb 支持行级锁(并发程度更高)

日志log_buffer大小
show VARIABLES like 'innodb_log_buffer_size'
csv
- 以 csv 格式进行数据存储
- 所有列都不能为 null 的
- 不支持索引(不适合大表,不适合在线处理)
- 可以对数据文件直接编辑(保存文本文件内容)
create table mycsv(id int not null,c1 VARCHAR(10) not null,c2 char(10) not null) engine=csv;
insert into mycsv values(1,'aaa','bbb'),(2,'cccc','dddd');
vi /usr/local/mysql/data/mall/mycsv.CSV 修改文本数据
flush TABLES;
select * from mycsv
create index idx_id on mycsv(id)
Archive
- 组成
以zlib对表数据进行压缩,磁盘I/O更少数据存储在ARZ为后缀的文件中
- 特点:
只支持insert和select操作只允许在自增ID列上加索引
create table myarchive(id int auto_increment not null,c1 VARCHAR(10),c2 char(10), key(id)) engine = archive;
create index idx_c1 on myarchive(c1)
INSERT into myarchive(c1,c2) value('aa','bb'),('cc','dd');
delete from myarchive where id = 1;
update myarchive set c1='aaa' where id = 1;
Memory
- 文件系统存储特点也称 HEAP 存储引擎,所以数据保存在内存中
- 支持 HASH 索引和 BTree 索引
- 所有字段都是固定长度 varchar(10) = char(10)
- 不支持 Blog 和 Text 等大字段
- Memory 存储引擎使用表级锁
- 最大大小由 max_heap_table_size 参数决定
show VARIABLES like 'max_heap_table_size'
create table mymemory(id int,c1 varchar(10),c2 char(10),c3 text) engine = memory;
create table mymemory(id int,c1 varchar(10),c2 char(10)) engine = memory;
create index idx_c1 on mymemory(c1);
create index idx_c2 using btree on mymemory(c2);
show index from mymemory
show TABLE status LIKE "mymemory"
与临时表区别
适用场景
- hash 索引用于查找或者是映射表(邮编和地区的对应表)
- 用于保存数据分析中产生的中间表
- 用于缓存周期性聚合数据的结果表
Ferderated
- 提供了访问远程 MySQL 服务器上表的方法
- 本地不存储数据,数据全部放到远程服务器上
- 本地需要保存表结构和远程服务器的连接信息
适用场景
偶尔的统计分析及手工查询(某些游戏行业),统计分析用的,类似于oracle外部表
默认禁止,启用需要再启动时增加 federated 参数
show ENGINES;
create database local;
create database remote;
create table remote_fed(id int auto_increment not null,c1 varchar(10) not null default '',c2 char(10) not null default '',primary key(id)) engine = INNODB;
INSERT into remote_fed(c1,c2) values('aaa','bbb'),('ccc','ddd'),('eee','fff');
CREATE TABLE `local_fed` (`id` int(11) NOT NULL AUTO_INCREMENT, `c1` varchar(10) NOT NULL DEFAULT '', `c2` char(10) NOT NULL DEFAULT '', PRIMARY KEY (`id`)) ENGINE=federated CONNECTION ='mysql://root:root1234%@127.0.0.1:3306/remote/remote_fed'
select * from local_fed
delete from local_fed where id = 2 select * from remote.remote_fed
以上是实验,证明可以通过外部表修改数据。
锁
锁的简介
为什么需要锁
到淘宝上买一件商品,商品只有一件库存,这个时候如果还有另一个人买,那么如何解决是你买到还是另一个人买到的问题?
锁的概念
- 锁是计算机协调多个进程或线程并发访问某一资源的机制。
- 在数据库中,数据也是一种供许多用户共享的资源。如何保证数据并发访问的一致性、有效性是所有数据库必须解决的一个问题,锁冲突也是影响数据库并发访问性能的一个重要因素。
- 锁对数据库而言显得尤其重要,也更加复杂。
MySQL 中的锁
- 表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
- 行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
- 页面锁(gap 锁,间隙锁):开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
在这个部分只讲表级锁、行级锁,gap 锁放到事务中讲
表锁与行锁的使用场景
表级锁更适合于以查询为主,只有少量按索引条件更新数据的应用,如 OLAP 系统
行级锁则更适合于有大量按索引条件并发更新少量不同数据,同时又有并发查询的应用,如一些在线事务处理(OLTP)系统。
很难笼统地说哪种锁更好,只能就具体应用的特点来说哪种锁更合适
MyISAM 锁
MySQL 的表级锁有两种模式:表共享读锁(Table Read Lock)表独占写锁(Table Write Lock)

共享读锁
语法:lock table 表名 read
1. lock table testmysam READ
启动另外一个 session
select * from testmysam 可以查询
2. insert into testmysam value(2);
update testmysam set id=2 where id=1;
报错
3.在另外一个 session 中
insert into testmysam value(2); 等待
4.在同一个 session 中
insert into account value(4,'aa',123); 报错
select * from account ; 报错
5.在另外一个 session 中
insert into account value(4,'aa',123); 成功
6.同一个 session 中使用别名加锁
select s.* from testmysam s 报错
lock table 表名 as 别名 read;
一个session只能加锁一张表,锁定后只能查询该表,无法查看其他表,修改更别想了。加锁后不能用别名,认为是别的表
独占写锁(排它锁)
语法:lock table table_name WRITE或for update
1.lock table testmysam WRITE
在同一个 session 中
insert testmysam value(3);
delete from testmysam where id = 3
select * from testmysam
2.对不同的表操作(报错)
select s.* from testmysam s
insert into account value(4,'aa',123);
3.在其他 session 中 (等待)
select * from testmysam
本session只能查看修改当前表,其他会话不能查看修改,因为无法获取共享锁啊。。
基本原则是谁锁谁负责,别搞一半搞其他的
总结
- 读锁,对 MyISAM 表的读操作,不会阻塞其他用户对同一表的读请求,但会阻塞对同一表的写请求
- 读锁,对 MyISAM 表的读操作,不会阻塞当前 session 对表读,当对表进行修改会报错
- 读锁,一个 session 使用 LOCK TABLE 命令给表 f 加了读锁,这个 session 可以查询锁定表中的记录,但更新或访问其他表都会提示错误;
- 写锁,对 MyISAM 表的写操作,则会阻塞其他用户对同一表的读和写操作;
- 写锁,对 MyISAM 表的写操作,当前 session 可以对本表做 CRUD,但对其他表进行操作会报错
表锁的这些东西对innodb同样适用。
表锁一旦执行显示lock锁定,没有执行unlock tables ,show processlist 会有一堆东西,没有具体表信息,只能杀sleep进程了
InnoDB锁
本章本想叫行锁,为了对应就这么写了。本章讲的就是行锁。切记切记。。。
在 mysql 的 InnoDB 引擎支持行锁
共享锁又称:读锁。当一个事务对某几行上读锁时,允许其他事务对这几行进行读操作,但不允许其进行写操作,也不允许其他事务给这几行上排它锁,但允许上读锁。
排它锁又称:写锁。当一个事务对某几个上写锁时,不允许其他事务写,但允许读。更不允许其他事务给这几行上任何锁。包括写锁。
语法
上共享锁的写法:lock in share mode
例如:select * from 表 where 条件 lock in share mode;
上排它锁的写法:for update
例如:select * from 表 where 条件 for update;
注意
- 两个事务不能锁同一个索引。
- insert ,delete , update 在事务中都会自动默认加上排它锁。
- 行锁必须有索引才能实现,否则会自动锁全表,那么就不是行锁了。
下面实验
CREATE TABLE testdemo (
`id` int(255) NOT NULL ,
`c1` varchar(300) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL ,
`c2` int(50) NULL DEFAULT NULL ,
PRIMARY KEY (`id`),
INDEX `idx_c2` (`c2`) USING BTREE
) ENGINE=InnoDB;
insert into testdemo VALUES(1,'1',1),(2,'2',2);
BEGIN
select * from testdemo where id =1 for update
在另外一个 session 中
update testdemo set c1 = '1' where id = 2 成功
update testdemo set c1 = '1' where id = 1 等待
BEGIN
update testdemo set c1 = '1' where id = 1
在另外一个 session 中
update testdemo set c1 = '1' where id = 1 等待
BEGIN
update testdemo set c1 = '1' where c1 = '1'
在另外一个 session 中
update testdemo set c1 = '2' where c1 = '2' 等待
第一个 session 中 select * from testdemo where id =1 for update
第二个 session
select * from testdemo where id =1 lock in share mode
回到第一个 session UNLOCK TABLES 并不会解锁使用 commit 或者 begin 或者 ROLLBACK 才会解锁
再来看下表锁 lock table testdemo WRITE
使用 commit,ROLLBACK 并不会解锁使用 UNLOCK TABLES 或者 begin 会解锁
锁的等待问题
好了,掌握了上面这些,你对锁的了解已经超过了很多同学,那么现在来说一个实际的问题,在工作中经常一个数据被锁住,导致另外的操作完全进行不下去。
你肯定碰到过这问题,有些程序员在 debug 程序的时候,经常会锁住一部分数据库的数据,而这个时候你也要调试这部分功能,却发现代码总是运行超时,你是否碰到过这问题了,其实这问题的根源我相信你也知道了。
举例来说,有两个会话。
程序员甲,正直调试代码
BEGIN
SELECT * FROM testdemo WHERE id = 1 FOR UPDATE
你正直完成的功能也要经过那部分的代码,你得上个读锁
BEGIN
SELECT * FROM testdemo WHERE id = 1 lock in share mode
这个时候很不幸,你并不知道发生了什么问题,在你调试得过程中永远就是一个超时得异常,而这种问题不管在开发中还是在实际项目运行中都可能会碰到,那么怎么排查这个问题呢?这其实也是有小技巧的。
select * from information_schema.INNODB_LOCKS;
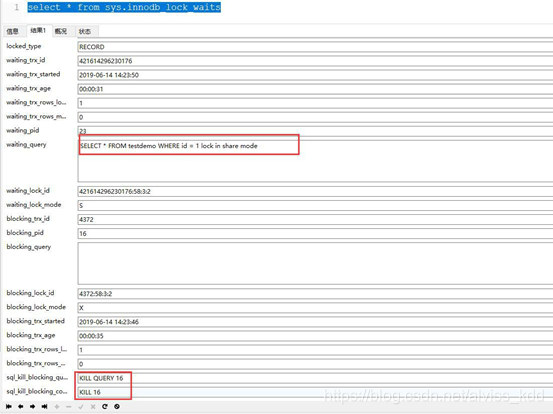
真好,我通过这个 sql 语句起码发现在同一张表里面得同一个数据有了 2 个锁其中一个是 X (写锁),另外一个是 S(读锁),我可以跳过这一条数据,使用其他数据做调试
可能如果我就是绕不过,一定就是要用这条数据呢?吼一嗓子吧(哪个缺德的在 debug 这个表,请不要锁这不动),好吧,这是个玩笑,其实还有更好的方式来看
select * from sys.innodb_lock_waits

我现在执行的这个 sql 语句有了,另外看下最下面,kill 命令,你在工作中完全可以通过 kill 把阻塞了的 sql 语句给干掉,你就可以继续运行了,不过这命令也要注意使用过,如果某同事正在做比较重要的调试,你 kill,被他发现可能会被暴打一顿
上面的解决方案不错,但如果你的 MySQL 不是 5.7 的版本呢?是 5.6 呢,你根本就没有 sys 库,这个时候就难办了,不过也是有办法的。
SELECT
r.trx_id waiting_trx_id,
r.trx_mysql_thread_id waiting_thread, r.trx_query waiting_query,
b.trx_id blocking_trx_id, b.trx_mysql_thread_id blocking_thread
FROM information_schema.innodb_lock_waits w
INNER JOIN
information_schema.innodb_trx b ON b.trx_id = w.blocking_trx_id
INNER JOIN
information_schema.innodb_trx r ON r.trx_id = w.requesting_trx_id;

看到没有,接下来你是否也可以执行 kill 29 这样的大招了。
事务
为什么需要事务
现在的很多软件都是多用户,多程序,多线程的,对同一个表可能同时有很多人在用,为保持数据的一致性,所以提出了事务的概念。
A 给 B 要划钱,A 的账户-1000 元, B 的账户就要+1000 元,这两个 update 语句必须作为一个整体来执行,不然 A 扣钱了,B 没有加钱这种情况很难处理。
什么存储引擎支持事务
1.查看数据库下面是否支持事务(InnoDB 支持)?
show engines;
2.查看 mysql 当前默认的存储引擎?
show variables like '%storage_engine%';
3.查看某张表的存储引擎?
show create table 表名 ;
4.对于表的存储结构的修改?
建立 InnoDB 表:
Create table .... type=InnoDB;
Alter table table_name type=InnoDB;
事务特性
事务应该具有 4 个属性:原子性、一致性、隔离性、持久性。这四个属性通常称为 ACID 特性。
- 原子性(atomicity)
- 一致性(consistency)
- 隔离性(isolation)
- 持久性(durability)
原子性(atomicity)
一个事务必须被视为一个不可分割的最小单元,整个事务中的所有操作要么全部提交成功,要么全部失败,对于一个事务来说,不可能只执行其中的一部分操作
老婆大人给 al发生活费
- 老婆大人工资卡扣除 500 元
- al工资卡增加 500
整个事务要么全部成功,要么全部失败
一致性(consistency)
一致性是指事务将数据库从一种一致性转换到另外一种一致性状态,在事务开始之前和事务结束之后数据库中数据的完整性没有被破坏
老婆大人给al发生活费
- 老婆大人工资卡扣除 500 元
- al工资卡增加 500
- al工资卡不能增加 1000
扣除的钱(-500) 与增加的钱(500) 相加应该为 0
持久性(durability)
一旦事务提交,则其所做的修改就会永久保存到数据库中。此时即使系统崩溃,已经提交的修改数据也不会丢失
并不是数据库的角度完全能解决
隔离性(isolation)
一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
(对数据库的并行执行,应该像串行执行一样)
- 未提交读(READ UNCOMMITED)脏读
- 已提交读 (READ COMMITED)不可重复读
- 可重复读(REPEATABLE READ)
- 可串行化(SERIALIZABLE)
mysql 默认的事务隔离级别为 repeatable-read
show variables like '%tx_isolation%';
事务并发问题
- 脏读:事务 A 读取了事务 B 更新的数据,然后 B 回滚操作,那么 A 读取到的数据是脏数据
- 不可重复读 事务 A 多次读取同一数据,事务 B 在事务 A 多次读取的过程中,对数据作了更新并提交,导致事务 A 多次读取同一数据时,结果不一致。
- 幻读:系统管理员 A 将数据库中所有学生的成绩从具体分数改为 ABCDE 等级,但是系统管理员 B 就在这个时候插入了一条具体分数的记录,当系统管理员 A 改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。
不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表
下面是实验
未提交读(READ UNCOMMITED)脏读
show variables like '%tx_isolation%';
set SESSION TRANSACTION ISOLATION LEVEL read UNCOMMITTED;
一个 session 中 start TRANSACTION
update account set balance = balance -50 where id = 1
另外一个 session 中查询 select * from account
回到第一个 session 中 回滚事务
ROLLBACK
在第二个 session 中 select * from account
在另外一个 session 中读取到了为提交的数据,这部分的数据为脏数据
已提交读 (READ COMMITED)不可重复读
show variables like '%tx_isolation%';
set SESSION TRANSACTION ISOLATION LEVEL read committed;
一个 session 中 start TRANSACTION
update account set balance = balance -50 where id = 1
另外一个 session 中查询 (数据并没改变) select * from account
回到第一个 session 中 回滚事务
commit
在第二个 session 中 select * from account (数据已经改变)
可重复读(REPEATABLE READ)
show variables like '%tx_isolation%';
set SESSION TRANSACTION ISOLATION LEVEL repeatable read;
一个 session 中 start TRANSACTION
update account set balance = balance -50 where id = 1
另外一个 session 中查询 (数据并没改变) select * from account
回到第一个 session 中 回滚事务 commit
在第二个 session 中 select * from account (数据并未改变)
可串行化(SERIALIZABLE)
show variables like '%tx_isolation%';
set SESSION TRANSACTION ISOLATION LEVEL serializable;
1.开启一个事务
begin
select * from account 发现 3 条记录
2.开启另外一个事务
begin
select * from account 发现 3 条记录 也是 3 条记录
insert into account VALUES(4,'deer',500) 发现根本就不让插入
3. 回到第一个事务 commit
总结
事务隔离性中的4种隔离级别,就是为了解决对应的并发问题。
- READ UNCOMMITED 导致 脏读,不可重复读,幻读
- READ COMMITED 解决脏读,存在不可重复读,幻读
- REPEATABLE READ 解决脏读,不可重复读,存在幻读
- SERIALIZABLE 解决所有问题,然后就慢好了
间隙锁(gap 锁)
其实在 mysql 中,可重复读已经解决了幻读问题,借助的就是间隙锁。
这位仁兄说的可信吗?事务里加上排它锁解决的幻读,和间隙锁有啥关系。

实验 1:
session 1
select @@tx_isolation;
create table t_lock 1 (a int primary key);
insert into t lock_1 values(10),(11),(13),(20),(40);
begin
select * from t_lock_1 where a <= 13 for update;
session 2
insert into t_lock_1 values(21) 成功
insert into t_lock_1 values(19) 阻塞
在 rr 隔离级别中者个会扫描到当前值(13)的下一个值(20),并把这些数据全部加锁
实验:2
create table t_lock_2 (a int primary key,b int, key (b));
insert into t_lock_2 values(1,1),(3,1),(5,3),(8,6),(10,8);
session 1
BEGIN
select * from t_lock_2 where b=3 for update;
1 3 5 8 10
1 1 3 6 8
session 2
select * from t_lock_2 where a = 5 lock in share mode; -- 不可执行,因为 a=5 上有一把记录锁
insert into t_lock_2 values(4, 2); -- 不可以执行,因为 b=2 在(1, 3]内
insert into t_lock_2 values(6, 5); -- 不可以执行,因为 b=5 在(3, 6)内
insert into t_lock_2 values(2, 0); -- 可以执行,(2, 0)均不在锁住的范围内
insert into t_lock_2 values(6, 7); -- 可以执行,(6, 7)均不在锁住的范围内
insert into t_lock_2 values(9, 6); -- 可以执行
insert into t_lock_2 values(7, 6); -- 不可以执行
二级索引锁住的范围是 (1, 3],(3, 6)
主键索引只锁住了 a=5 的这条记录 [5]
事务语法
开启事务
1、begin
2、START TRANSACTION(推荐)
3、begin work
事务回滚
rollback
事务提交
commit
还原点,使用还原点需要关闭自动提交
savepoint
show variables like '%autocommit%'; 自动提交事务默认是开启的
set autocommit=0;
insert into testdemo values(5,5,5);
savepoint s1;
insert into testdemo values(6,6,6);
savepoint s2;
insert into testdemo values(7,7,7);
savepoint s3;
select * from testdemo rollback to savepoint s2
rollback
业务设计
逻辑设计
范式定义
三大范式,加NF范式,其实还有第四范式,自己看看数据库原理书吧。。
第一范式
数据库表中的所有字段都只具有单一属性
单一属性的列是由基本数据类型所构成的
设计出来的表都是简单的二维表
name-age 列具有两个属性,一个 name,一个 age 不符合第一范式,把它拆分成两列

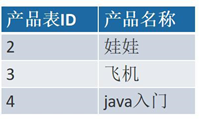
第二范式
要求表中只具有一个业务主键,也就是说符合第二范式的表不能存在非主键列只对部分主键的依赖关系
有两张表:订单表,产品表
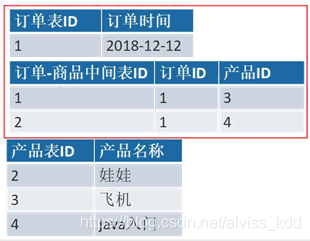
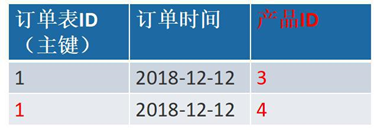
一个订单有多个产品,所以订单的主键为【订单 ID】和【产品 ID】组成的联合主键,这样 2 个组件不符合第二范式,而且产品 ID 和订单 ID 没有强关联,故,把订单表进行拆分为订单表与订单与商品的中间表
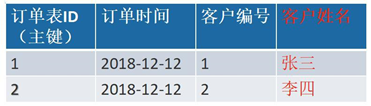
第三范式
指每一个非非主属性既不部分依赖于也不传递依赖于业务主键,也就是在第二范式的基础上相处了非主键对主键的传递依赖

其中
客户编号 和订单编号管理 关联客户姓名 和订单编号管理 关联客户编号 和 客户姓名 关联
如果客户编号发生改变,用户姓名也会改变,这样不符合第三大范式,应该把客户姓名这一列删除
范式设计实战(会的自动略过)
按要求设计一个电子商务网站的数据库结构
- 本网站只销售图书类产品
- 需要具备以下功能
用户登陆 商品展示 供应商管理
用户管理 商品管理 订单销售
用户登陆及用户管理

只有一个业务主键,一定是符合第二范式
没有属性和业务主键存在传递依赖的关系,符合第三范式
商品信息

一个商品可以属于多个分类,故,商品名称和分类应该是组合主键,会有大量冗余,不符合第二范式。应该把分类信息单独存放

另外再建立一个中间表把分类信息和商品信息进行关联

最后的三张表如下

供应商管理功能

符合三大范式,不需要修改,但假如增加新的一列【银行支行】,这样随着银行账户的变化,银行支行也会编号,不符合第三大范式

在线销售功能

有多个业务主键,不符合第二范式订单商品单价。订单数量,订单金额 存在传递依赖关系,不符合第三范式
拆分的结果如下

这时候,【订单商品分类】与【订单商品名】有依赖关联,故合并如下
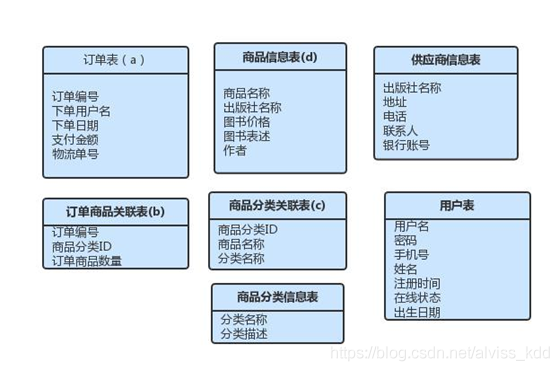
表汇总

查询练习(顺道来下)
编写 SQL 查询出每一个用户的订单总金额(用户名,订单总金额)

编写 SQL 查询出下单用户和订单详情(订单编号,用户名,手机号,商品名称,商品数量,商品价格)

反范式化设计
本不想分类了…
什么叫反范式化设计
- 反范式化是针对范式化而言得,在前面介绍了数据库设计得范式
- 所谓得反范式化就是为了性能和读取效率得考虑而适当得对数据库设计范式得要求进行违反
- 允许存在少量得冗余,换句话来说反范式化就是使用空间来换取时间
商品信息反范式设计
下面是范式设计的商品信息表

商品信息和分类信息经常一起查询,所以把分类信息也放到商品表里面,冗余存放
在线销售功能反范式

首先来看订单表
- 查询订单信息要关联查询到用户表,但用户表的电话是可能改变的,而且查询订单的时候经常查询到用户的电话
- 查询订单经常会查询到订单金额,所以把订单金额也冗余进来
新设计的订单表如下

再来看订单关联表
- 和商品信息反范式设计一样,查询订单的时候经常查询商品分类,所以把商品分类和订单名冗余进来
- 商品的单价可能会编号,如果关联查询查询只能查询到最新的商品价格,而查询不到下订单时候的价格,并且商品单价经常会查询。 所以把订单单价也冗余进来
新设计的商品关联表如下

查询练习
来吧
编写 SQL 查询出每一个用户的订单总金额

编写 SQL 查询出下单用户和订单详情
总结
不能完全按照范式得要求进行设计
考虑以后如何使用表,一切以需求为主。
范式化设计优缺点
优点:
- 可以尽量得减少数据冗余范式化的更新操作比反范式化更快
- 范式化的表通常比反范式化的表更小
缺点:对于查询需要对多个表进行关联更难进行索引优化
反范式化设计优缺点
优点:可以减少表的关联可以更好的进行索引优化
缺点:存在数据冗余及数据维护异常对数据的修改需要更多的成本
其实就一句话,牺牲空间置换业务效率。
物理设计
命名规范
数据库、表、字段的命名要遵守可读性原则
使用大小写来格式化的库对象名字以获得良好的可读性
例如:使用 custAddress 而不是 custaddress 来提高可读性。
大部分都是cust_address
数据库、表、字段的命名要遵守表意性原则
对象的名字应该能够描述它所表示的对象
例如:
对于表,表的名称应该能够体现表中存储的数据内容;
对于存储过程存储过程应该能够体现存储过程的功能。
数据库、表、字段的命名要遵守长名原则
尽可能少使用或者不使用缩写
存储引擎选择

数据类型选择
当一个列可以选择多种数据类型时
- 优先考虑数字类型
- 其次是日期、时间类型
- 最后是字符类型
- 对于相同级别的数据类型,应该优先选择占用空间小的数据类型
浮点类型

注意 float 和 double 是非精度类型,如果是和金额相关尽量用 decimal
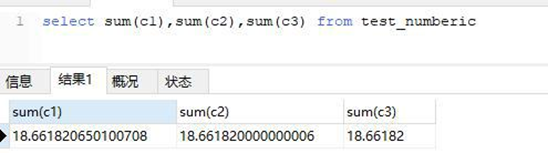
select sum(c1),sum(c2),sum(c3) from test_numberic
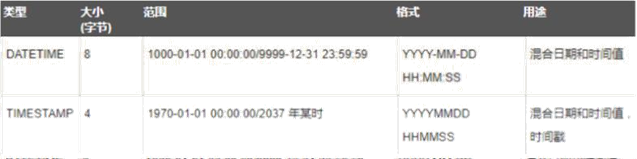
日期类型
面试经常问道 timestamp 类型 与 datetime 区别
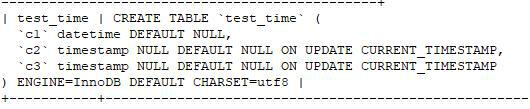
- datetime 类型在 5.6 中字段长度是 5 个字节 datetime 类型在 5.5 中字段长度是 8 个字节
- timestamp 和时区有关,而 datetime 无关
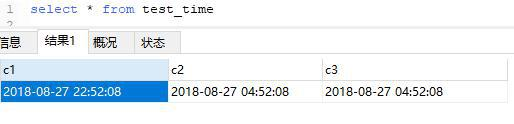
insert into test_time VALUES(NOW(),NOW(),NOW());
set time_zone="-10:00"

timestamp不是时间戳,不是时间戳,不是时间戳…
目前timestamp能用到2037年,后面不能用了。。
慢查询
什么是慢查询
慢查询日志,顾名思义,就是查询慢的日志,是指 mysql 记录所有执行超过 long_query_time 参数设定的时间阈值的 SQL 语句的日志。该日志能为 SQL 语句的优化带来很好的帮助。默认情况下,慢查询日志是关闭的,要使用慢查询日志功能,首先要开启慢查询日志功能。
慢查询配置
慢查询基本配置
slow_query_log启动停止技术慢查询日志slow_query_log_file指定慢查询日志得存储路径及文件(默认和数据文件放一起)long_query_time指定记录慢查询日志 SQL 执行时间得伐值(单位:秒,默认 10 秒)log_queries_not_using_indexes是否记录未使用索引的 SQLlog_output日志存放的地方【TABLE】【FILE】【FILE,TABLE】
配置了慢查询后,它会记录符合条件的 SQL 包括:
- 查询语句
- 数据修改语句
- 已经回滚的SQL
实操:
通过下面命令查看下上面的配置:
show VARIABLES like '%slow_query_log%';
show VARIABLES like '%slow_query_log_file%' ;
show VARIABLES like '%long_query_time%';
show VARIABLES like '%log_queries_not_using_indexes%'
show VARIABLES like 'log_output'
set global long_query_time=0; ---默认 10 秒,这里为了演示方便设置为 0
set GLOBAL slow_query_log = 1; --开启慢查询日志
set global log_output='FILE,TABLE' --项目开发中日志只能记录在日志文件中,不能记表中
设置完成后,查询一些列表可以发现慢查询的日志文件里面有数据了。
cat /usr/local/mysql/data/mysql-slow.log
慢查询解读(没用)
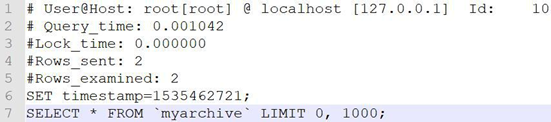
从慢查询日志里面摘选一条慢查询日志,数据组成如下
慢查询格式显示
第一行:用户名 、用户的 IP 信息、线程 ID号
第二行:执行花费的时间【单位:毫秒】
第三行:执行获得锁的时间
第四行:获得的结果行数
第五行:扫描的数据行数
第六行:这 SQL 执行的具体时间
第七行:具体的 SQL 语句
慢查询分析
慢查询的日志记录非常多,要从里面找寻一条查询慢的日志并不是很容易的事情,一般来说都需要一些工具辅助才能快速定位到需要优化的 SQL 语句,下面介绍两个慢查询辅助工具
Mysqldumpslow
常用的慢查询日志分析工具,汇总除查询条件外其他完全相同的 SQL,并将分析结果按照参数中所指定的顺序输出。
语法:
mysqldumpslow -s r -t 10 slow-mysql.log -s order (c,t,l,r,at,al,ar)
c:总次数
t:总时间
l:锁的时间
r:总数据行
at,al,ar:t,l,r 平均数 【例如:at = 总时间/总次数】
-t top 指定取前面几天作为结果输出
mysqldumpslow -s t -t 10 /usr/local/mysql/data/mysql-slow.log
pt_query_digest
是用 于分析 mysql 慢查询的一个工具,与 mysqldumpshow 工具相比, py-query_digest 工具的分析结果更具体,更完善。
有时因为某些原因如权限不足等,无法在服务器上查询记录。这样的限制我们也常常碰到。
首先来看下一个命令
Yum -y install 'perl(Data::Dumper)'; yum -y install perl-Digest-MD5
yum -y install perl-DBI
yum -y install perl-DBD-MySQL
perl ./pt-query-digest --explain h=127.0.0.1,u=root,p=root1234% /usr/local/mysql/data/mysql-slow.log
汇总的信息【总的查询时间】、【总的锁定时间】、【总的获取数据量】、【扫描的数据量】、【查询大小】
Response: 总的响应时间。
time: 该查询在本次分析中总的时间占比。
calls: 执行次数,即本次分析总共有多少条这种类型的查询语句。
R/Call: 平均每次执行的响应时间。
Item : 查询对象
pt-query-digest详细介绍
语法及重要选项
pt-query-digest [OPTIONS] [FILES] [DSN]
--create-review-table 当使用--review 参数把分析结果输出到表中时,如果没有表就自动创建。
--create-history-table 当使用--history 参数把分析结果输出到表中时,如果没有表就自动创建。
--filter 对输入的慢查询按指定的字符串进行匹配过滤后再进行分析
--limit 限制输出结果百分比或数量,默认值是 20,即将最慢的 20 条语句输出,如果是50%则按总响应时间占比从大到小排序,输出到总和达到 50%位置截止。
--host mysql 服务器地址
--user mysql 用户名
--password mysql 用户密码
--history 将分析结果保存到表中,分析结果比较详细,下次再使用--history 时,如果存在相同的语句,且查询所在的时间区间和历史表中的不同,则会记录到数据表中,可以通过查询同一 CHECKSUM 来比较某类型查询的历史变化。
--review 将分析结果保存到表中,这个分析只是对查询条件进行参数化,一个类型的查询一条记录,比较简单。当下次使用--review 时,如果存在相同的语句分析,就不会记录到数据表中。
--output 分析结果输出类型,值可以是 report(标准分析报告)、slowlog(Mysql slow log)、json、json-anon,一般使用 report,以便于阅读。
--since 从什么时间开始分析,值为字符串,可以是指定的某个”yyyy-mm-dd [hh:mm:ss]”
格式的时间点,也可以是简单的一个时间值:s(秒)、h(小时)、m(分钟)、d(天),如 12h 就表示从 12 小时前开始统计。
--until 截止时间,配合—since 可以分析一段时间内的慢查询。
分析 pt-query-digest 输出结果
第一部分:总体统计结果
Overall:总共有多少条查询
Time range:查询执行的时间范围
unique:唯一查询数量,即对查询条件进行参数化以后,总共有多少个不同的查询
total:总计 min:最小 max:最大 avg:平均
95%:把所有值从小到大排列,位置位于 95%的那个数,这个数一般最具有参考价值
median:中位数,把所有值从小到大排列,位置位于中间那个数
# 该工具执行日志分析的用户时间,系统时间,物理内存占用大小,虚拟内存占用大小
# 340ms user time, 140ms system time, 23.99M rss, 203.11M vsz
# 工具执行时间
# Current date: Fri Nov 25 02:37:18 2016
# 运行分析工具的主机名
# Hostname: localhost.localdomain
# 被分析的文件名
# Files: slow.log
# 语句总数量,唯一的语句数量,QPS,并发数
# Overall: 2 total, 2 unique, 0.01 QPS, 0.01x concurrency
# 日志记录的时间范围
# Time range: 2016-11-22 06:06:18 to 06:11:40
# 属性 总计 最小 最大 平均 95% 标准 中等
# Attribute total min max avg 95% stddev median
# ============ ======= ======= ======= ======= ======= ======= =======
# 语句执行时间
# Exec time 3s 640ms 2s 1s 2s 999ms 1s
# 锁占用时间
# Lock time 1ms 0 1ms 723us 1ms 1ms 723us
# 发送到客户端的行数
# Rows sent 5 1 4 2.50 4 2.12 2.50
# select 语句扫描行数
# Rows examine 186.17k 0 186.17k 93.09k 186.17k 131.64k 93.09k
# 查询的字符数
# Query size 455 15 440 227.50 440 300.52 227.50
第二部分:查询分组统计结果
Rank:所有语句的排名,默认按查询时间降序排列,通过--order-by 指定
Query ID:语句的 ID,(去掉多余空格和文本字符,计算 hash 值)
Response:总的响应时间
time:该查询在本次分析中总的时间占比
calls:执行次数,即本次分析总共有多少条这种类型的查询语句
R/Call:平均每次执行的响应时间
V/M:响应时间 Variance-to-mean 的比率
Item:查询对象
# Profile
# Rank Query ID Response time Calls R/Call V/M Item
# ==== ================== ============= ===== ====== ===== ===============
# 1 0xF9A57DD5A41825CA 2.0529 76.2% 1 2.0529 0.00 SELECT
# 2 0x4194D8F83F4F9365 0.6401 23.8% 1 0.6401 0.00 SELECT wx_member_base
第三部分:每一种查询的详细统计结果
由下面查询的详细统计结果,最上面的表格列出了执行次数、最大、最小、平均、95%等各项目的统计。
ID:查询的 ID 号,和上图的 Query ID 对应
Databases:数据库名
Users:各个用户执行的次数(占比)
Query_time distribution :查询时间分布, 长短体现区间占比,本例中 1s-10s 之间查询数量是 10s 以上的两倍。
Tables:查询中涉及到的表
Explain:SQL 语句
# Query 1: 0 QPS, 0x concurrency, ID 0xF9A57DD5A41825CA at byte 802
# This item is included in the report because it matches --limit.
# Scores: V/M = 0.00
# Time range: all events occurred at 2016-11-22 06:11:40
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 50 1
# Exec time 76 2s 2s 2s 2s 2s 0 2s
# Lock time 0 0 0 0 0 0 0 0
# Rows sent 20 1 1 1 1 1 0 1
# Rows examine 0 0 0 0 0 0 0 0
# Query size 3 15 15 15 15 15 0 15
# String:
# Databases test
# Hosts 192.168.8.1
# Users mysql
# Query_time distribution
# 1us
# 10us
# 100us
# 1ms
# 10ms
# 100ms
# 1s ################################################################
# 10s+
# EXPLAIN /*!50100 PARTITIONS*/
select sleep(2)\G
索引与执行计划
索引入门
什么是索引
MySQL 官方对索引的定义为:索引(Index)是帮助 MySQL 高效获取数据的数据结构。可以得到索引的本质:索引是数据结构。
生活中的索引(书本目录)
上面的理解比较抽象,举一个例子,平时看任何一本书,首先看到的都是目录,通过目录去查询书籍里面的内容会非常的迅速。

上图就是一本金瓶梅的书,书籍的目录是按顺序放置的,有第一节,第二节它本身就是一种顺序存放的数据结构,是一种顺序结构。
另外通过目录(索引),可以快速查询到目录里面的内容,它能高效获取数据,通过这个简单的案例可以理解所以就是高效获取数据的数据结构
再来看一个复杂的情况,我们要去图书馆找一本书,这图书馆的书肯定不是线性存放的,它对不同的书籍内容进行了分类存放,整索引由于一个个节点组成,根节点有中间节点,中间节点下面又由子节点,最后一层是叶子节点,
可见,整个索引结构是一棵倒挂着的树,其实它就是一种数据结构,这种数据结构比前面讲到的线性目录更好的增加了查询的速度。
MySql 中的索引
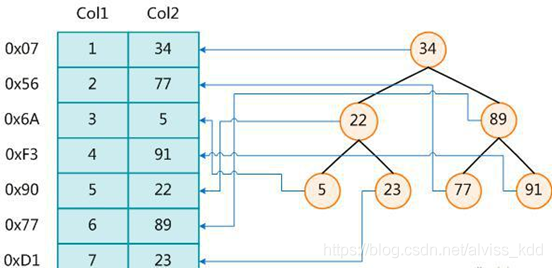
MySql 中的索引其实也是这么一回事,我们可以在数据库中建立一系列的索引,比如创建主键的时候默认会创建主键索引,上图是一种 BTREE 的索引。每一个节点都是主键的 ID
当我们通过 ID 来查询内容的时候,首先去查索引库,在到索引库后能快速的定位索引的具体位置。
浅谈B+tree
B+TREE 说白了还是 Tree,但谈这些之前还要从基础开始讲起
涉及的算法
二分查找法(binary search) 也称为折半查找法,用来查找一组有序的记录数组中的某一记录。
其基本思想是:将记录按有序化(递增或递减)排列,在查找过程中采用跳跃式方式查找,即先以有序数列的中点位置作为比较对象,如果要找的元素值小于该中点元素,则将待查序列缩小为左半部分,否则为右半部分。通过一次比较,将查找区间缩小一半。
给出一个例子,注意该例子已经是升序排序的,且查找数字 48
数据:5, 10, 19, 21, 31, 37, 42, 48, 50, 52
下标:0, 1, 2, 3, 4, 5, 6, 7, 8, 9
- 步骤一:设 low 为下标最小值 0 , high 为下标最大值 9 ;
- 步骤二:通过 low 和 high 得到 mid ,mid=(low + high) / 2,初始时 mid 为下标 4 (也可以=5,看具体算法实现);
- 步骤三 : mid=4 对应的数据值是 31,31 < 48(我们要找的数字);
- 步骤四:通过二分查找的思路,将 low 设置为 31 对应的下标 4 , high 保持不变为 9 ,此时 mid 为 6 ;
- 步骤五 : mid=6 对应的数据值是 42,42 < 48(我们要找的数字);
- 步骤六:通过二分查找的思路,将 low 设置为 42 对应的下标 6 , high 保持不变为 9 ,此时 mid 为 7 ;
- 步骤七 : mid=7 对应的数据值是 48,48 == 48(我们要找的数字),查找结束;
通过 3 次 二分查找 就找到了我们所要的数字,而顺序查找需 8
二叉树(Binary Tree)
每个节点至多只有二棵子树;
- 二叉树的子树有左右之分,次序不能颠倒;
- 一棵深度为 k,且有 个节点,称为满二叉树(Full Tree);
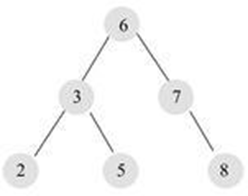
- 一棵深度为 k,且 root 到 k-1 层的节点树都达到最大,第 k 层的所有节点都 连续集中在最左边,此时为完全二叉树(Complete Tree)
平衡二叉树(AVL-树)
- 左子树和右子树都是平衡二叉树;
- 左子树和右子树的高度差绝对值不超过 1;
平衡二叉树
非平衡二叉树
平衡二叉树的遍历
- 前序 :6 ,3, 2, 5,7, 8(ROOT 节点在开头, 中 -左-右 顺序)
- 中序 :2, 3, 5, 6,7, 8(中序遍历即为升序,左- 中 -右 顺序)
- 后序 :2, 5, 3, 8,7, 6 (ROOT 节点在结尾,左-右- 中 顺序)
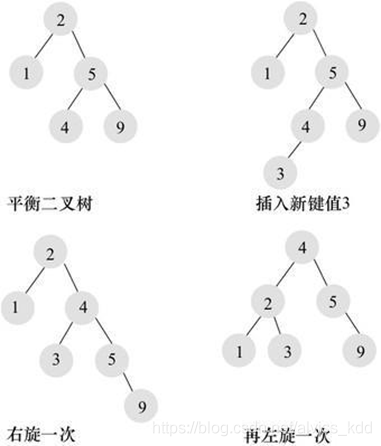
平衡二叉树的旋转
需要通过旋转(左旋,右旋)来维护平衡二叉树的平衡,在添加和删除的时候需要有额外的开销
B+树
B+树的定义
- 数据只存储在叶子节点上,非叶子节点只保存索引信息;
- 非叶子节点(索引节点)存储的只是一个 Flag,不保存实际数据记录;
- 索引节点指示该节点的左子树比这个 Flag 小,而右子树大于等于这个 Flag
- 叶子节点本身按照数据的升序排序进行链接(串联起来);
- 叶子节点中的数据在 物理存储上是无序 的,仅仅是在 逻辑上有序 (通过指针串在一起);
B+树的作用
- 在块设备上,通过 B+树可以有效的存储数据;
- 所有记录都存储在叶子节点上,非叶子(non-leaf)存储索引(keys)信息;
- B+树含有非常高的扇出(fanout),通常超过 100,在查找一个记录时,可以有效的减少 IO 操作;
下面说一下扇出
B+树的扇出(fan out)
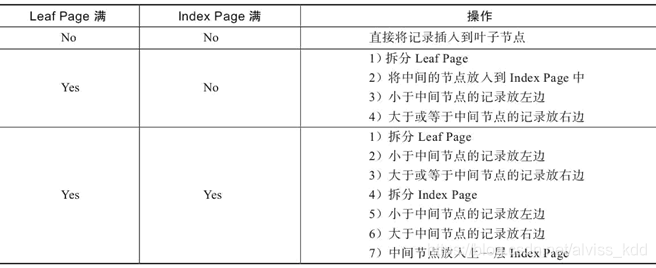
- 该 B+ 树高度为 2
- 每叶子页(LeafPage)4 条记录
- 扇出数为 5
- 叶子节点(LeafPage)由小到大(有序)串联在一起
扇出 是每个索引节点(Non-LeafPage)指向每个叶子节点(LeafPage)的指针
扇出数 = 索引节点(Non-LeafPage)可存储的最大关键字个数 + 1
图例中的索引节点(Non-LeafPage)最大可以存放 4 个关键字,但实际使用了 3 个;
B+树的插入操作
B+树的插入
B+树的插入必须保证插入后叶子节点中的记录依然排序。
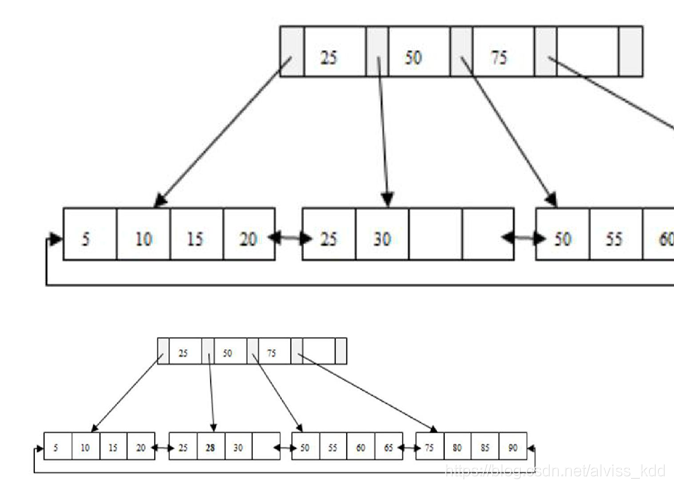
问题:1 插入 28
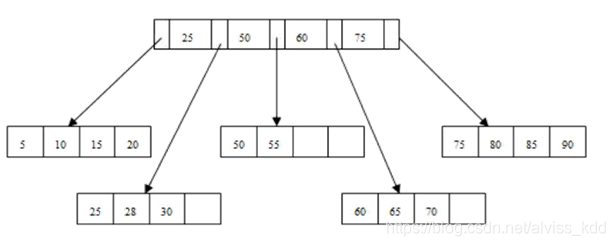
问题 2:插入 70
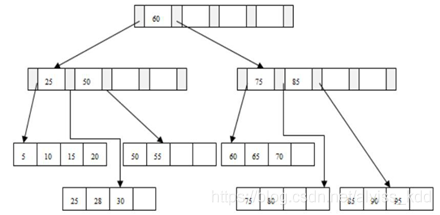
问题 2:插入 95

https://blog.csdn.net/shenchaohao12321/article/details/83243314
索引的分类
普通索引:即一个索引只包含单个列,一个表可以有多个单列索引
唯一索引:索引列的值必须唯一,但允许有空值
复合索引:即一个索引包含多个列
聚簇索引(聚集索引):并不是一种单独的索引类型,而是一种数据存储方式。具体细节取决于不同的实现,InnoDB 的聚簇索引其实就是在同一个结构中保存了 B-Tree 索引(技术上来说是 B+Tree)和数据行。
非聚簇索引:不是聚簇索引,就是非聚簇索引
基本语法
查看索引
SHOW INDEX FROM table_name\G
创建索引
CREATE [UNIQUE ] INDEX indexName ON mytable(columnname(length));
ALTER TABLE 表名 ADD [UNIQUE ] INDEX [indexName] ON (columnname(length));
删除索引
DROP INDEX [indexName] ON mytable;
alter table table_name drop index index_name;
执行计划
什么是执行计划
使用 EXPLAIN 关键字可以模拟优化器执行 SQL 查询语句,从而知道 MySQL 是如何处理你的 SQL 语句的。分析你的查询语句或是表结构的性能瓶颈
执行计划的内容
- 表的读取顺序
- 数据读取操作的操作类型
- 哪些索引可以使用
- 哪些索引被实际使用
- 表之间的引用
- 每张表有多少行被优化器查询
以上的这些作用会在执行计划详解里面介绍到,在这里不做解释。
执行计划的语法
执行计划的语法其实非常简单: 在 SQL 查询的前面加上 EXPLAIN 关键字就行。
比如:EXPLAIN select * from table1
重点的就是 EXPLAIN 后面你要分析的 SQL 语句
执行计划详解
通过 EXPLAIN 关键分析的结果由以下列组成,接下来挨个分析每一个列

ID列
ID 列:描述 select 查询的序列号,包含一组数字,表示查询中执行 select 子句或操作表的顺序
根据 ID 的数值结果可以分成一下三种情况
- id 相同:执行顺序由上至下
- id 不同:如果是子查询,id 的序号会递增,id 值越大优先级越高,越先被执行
- id 相同不同:同时存在
分别举例来看
Id 相同
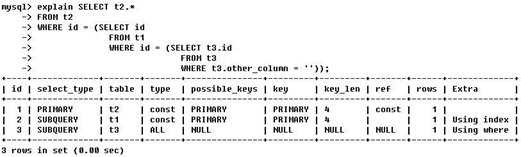
如上图所示,ID 列的值全为 1,代表执行的允许从 t1 开始加载,依次为 t3 与 t2
Id 不同

如果是子查询,id 的序号会递增,id 值越大优先级越高,越先被执行
Id 相同又不同

id相同,从上往下顺序执行;
select_type 列(没啥用)
Select_type:查询的类型,
要是用于区别:普通查询、联合查询、子查询等的复杂查询
类型如下
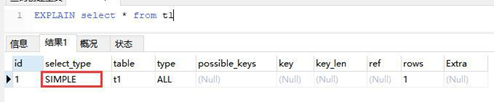
SIMPLE
简单的 select 查询,查询中不包含子查询或者 UNION
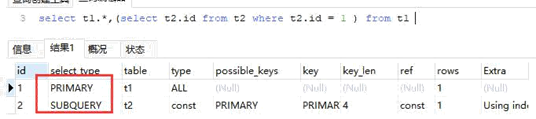
PRIMARY 与 SUBQUERY
PRIMARY:查询中若包含任何复杂的子部分,最外层查询则被标记为PRIMARY
SUBQUERY:在 SELECT 或 WHERE 列表中包含了子查询
EXPLAIN select t1.*,(select t2.id from t2 where t2.id = 1 ) from t1
1
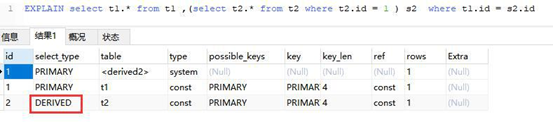
DERIVED
在 FROM 列表中包含的子查询被标记为 DERIVED(衍生) MySQL 会递归执行这些子查询, 把结果放在临时表里。
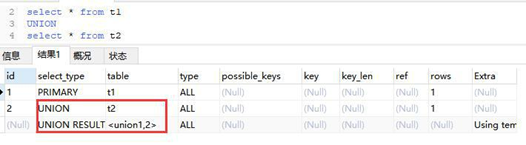
UNION RESULT 与 UNION
UNION:若第二个 SELECT 出现在 UNION 之后,则被标记为 UNION;
UNION RESULT 从 UNION 表获取结果的 SELECT
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xWDhJNgC-1602490777351)(0641C546C4204CECAF45B893F89859F3)]](https://i-blog.csdnimg.cn/blog_migrate/b596f6f9052f392bc8664c17d7e1906a.png)
table 列
显示这一行的数据是关于哪张表的
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aa377foI-1602490777353)(7BDD27F87CC5456889F1044D47DA0729)]](https://i-blog.csdnimg.cn/blog_migrate/d6dfe8831294ec8bd9b72e6182896101.png)
Type 列
type 显示的是访问类型,是较为重要的一个指标,结果值从最好到最坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
需要记忆的
system>const>eq_ref>ref>range>index>ALL
一般来说,得保证查询至少达到 range 级别,最好能达到 ref。
这他喵扯犊子。。。
下面是详细介绍
System 与 const
System:表只有一行记录(等于系统表),这是 const 类型的特列,平时不会出现,这个也可以忽略不计
Const:表示通过索引一次就找到了 const 用于比较 primary key 或者 unique 索引。因为只匹配一行数据,所以很快
如将主键置于 where 列表中,MySQL 就能将该查询转换为一个常量
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6mnoB3vd-1602490777355)(611EAFB0D59945508282B8692760B6C8)]](https://i-blog.csdnimg.cn/blog_migrate/f03482cca725077e9abd0fbad4c127df.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GNuekZw8-1602490777357)(558F5D60BA8A4D3A86694C56F75FF132)]](https://i-blog.csdnimg.cn/blog_migrate/4d349cfd9de33ea6166dd465929c9259.png)
eq_ref
唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或唯一索引扫描
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-juwQ7ri2-1602490777358)(D02D698F1519465AA37224BF2A75B508)]](https://i-blog.csdnimg.cn/blog_migrate/825179f5a5780acf74bc064f0f368759.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mh1yvZzd-1602490777360)(8734F5276B1744E7B6CCDABF5675833F)]](https://i-blog.csdnimg.cn/blog_migrate/871aa45fbabb2659fc629066a4c403c4.png)
Ref
非唯一性索引扫描,返回匹配某个单独值的所有行.
本质上也是一种索引访问,它返回所有匹配某个单独值的行,然而,它可能会找到多个符合条件的行,所以他应该属于查找和扫描的混合体
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DOrljMys-1602490777362)(5B7074076B2C470780F0C73D3364DC38)]](https://i-blog.csdnimg.cn/blog_migrate/544ba260ab89011bee001cb2f93aa946.png)
Range
只检索给定范围的行,使用一个索引来选择行。key 列显示使用了哪个索引一般就是在你的 where 语句中出现了 between、<、>、in 等的查询
这种范围扫描索引扫描比全表扫描要好,因为它只需要开始于索引的某一点,而结束语另一点,不用扫描全部索引。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-34OjPcvU-1602490777364)(37F24504076B401FB5635FC7299C4053)]](https://i-blog.csdnimg.cn/blog_migrate/a4081b9ec15c36ba3441fa5e5a727624.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EebdOqA4-1602490777366)(A1CED60821B04759954EBB8C6142853E)]](https://i-blog.csdnimg.cn/blog_migrate/797ec3ca0ca859836ccd0d734e30d310.png)
Index
当查询的结果全为索引列的时候,虽然也是全部扫描,但是只查询的索引库,而没有去查询数据。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SReKqQFh-1602490777368)(854E6D409703444FAA6E958C0B4D89A8)]](https://i-blog.csdnimg.cn/blog_migrate/120aa0f9246bcd656a7047d9295ad975.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GzI9K0Su-1602490777370)(234D95809A9A48F8826BE630F1E5AB1A)]](https://i-blog.csdnimg.cn/blog_migrate/d515df3e2b99f38523ade17436b4dab6.png)
All
Full Table Scan,将遍历全表以找到匹配的行
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tK4vUCgv-1602490777371)(3E66C0A9E46D45FF817FE13D0E2AF6F9)]](https://i-blog.csdnimg.cn/blog_migrate/c0be1638c636cfa75dc99dcc62ee9a3b.png)
possible_keys 与 Key
possible_keys:可能使用的 key
Key:实际使用的索引。如果为 NULL,则没有使用索引
查询中若使用了覆盖索引,则该索引和查询的 select 字段重叠
这里的覆盖索引非常重要,后面会单独的来讲
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fadKkKjO-1602490777373)(7623C57778844E3FA019A1709A147940)]](https://i-blog.csdnimg.cn/blog_migrate/6bde3f97b0ef9ffac14c53156f3a6579.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gAjoZLn9-1602490777375)(39FA6DC996F84AA182EEF9DC844AD69C)]](https://i-blog.csdnimg.cn/blog_migrate/5939a4f6877694fc09fa9a4401a35f30.png)
key_len
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eJVEFVeE-1602490777377)(9A91958AD199456F8D1F9F5FB06FDE50)]](https://i-blog.csdnimg.cn/blog_migrate/716fcdb208a70b6ec195c193fb13a81a.png)
Key_len 表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。在不损失精确性的情况下,长度越短越好
key_len 显示的值为索引字段的最大可能长度,并非实际使用长度,即 key_len 是根据表定义计算而得,不是通过表内检索出的
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cgeBlCiU-1602490777379)(D8D36F2D6EB0430CA99E455A80609FA7)]](https://i-blog.csdnimg.cn/blog_migrate/294e2ac53461ef5f512408f4c095dc64.png)
- key_len 表示索引使用的字节数
- 根据这个值,就可以判断索引使用情况,特别是在组合索引的时候,判断所有的索引字段是否都被查询用到
- char 和 varchar 跟字符编码也有密切的联系
- latin1 占用 1 个字节,gbk 占用 2 个字节,utf8 占用 3 个字节。(不同字符编码占用的存储空间不同) 啥就是1个字节了,汉字?
字符类型会影响key_len长度,下面介绍一下key_len计算
字符类型计算
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-o23ig9aC-1602490777380)(7E3D53C99C6D44C599CD7E3E0FF73624)]](https://i-blog.csdnimg.cn/blog_migrate/8cc5eb22c48d1937cf73e375ab5be303.png)
以上这个表列出了所有字符类型,但真正建所有的类型常用情况只是 CHAR、VARCHAR
当索引字段为 char not null
CREATE TABLE `s1` (
`id` int(11) NOT NULL AUTO_INCREMENT, `name` char(10) NOT NULL,
`addr` varchar(20) DEFAULT NULL, PRIMARY KEY (`id`),
KEY `name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
explain select * from s1 where name='enjoy';
1234567
name 这一列为 char(10),字符集为 utf-8 占用 3 个字节
Keylen=10*3
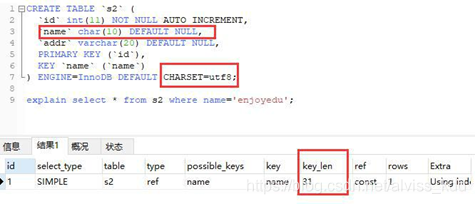
**当索引字段为 char **
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BMOhaNhx-1602490777385)(067F3B54087248958654CE3BB4BE8AF9)]](https://i-blog.csdnimg.cn/blog_migrate/89d6a1945ca13ccc2054f96d0a35caf5.png)
CREATE TABLE `s2` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` char(10) DEFAULT NULL, `addr` varchar(20) DEFAULT NULL, PRIMARY KEY (`id`),
KEY `name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
explain select * from s2 where name='enjoyedu';
1234567
name 这一列为 char(10),字符集为 utf-8 占用 3 个字节,外加需要存入一个 null 值
Keylen=10*3+1(null) 结果为 31
**当索引字段为 varchar not null **
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6NjbHXzX-1602490777386)(5609EE16449B4C5F93B45CDA488C44EB)]](https://i-blog.csdnimg.cn/blog_migrate/7c5d095ae073eae7f7ec430e9318d386.png)
CREATE TABLE `s3` (
`id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(10) NOT NULL,
`addr` varchar(20) DEFAULT NULL, PRIMARY KEY (`id`),
KEY `name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
explain select * from s3 where name='enjoyeud';
123456
Keylen=varchar(n)变长字段+不允许 Null=n*(utf8=3,gbk=2,latin1=1)+2
**当索引字段为 varchar **
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GACT7o0t-1602490777388)(75561AEEE9CD41EFBF5319B322486C12)]](https://i-blog.csdnimg.cn/blog_migrate/afb1a4519dbbad384b41e1235d78f1e8.png)
Keylen=varchar(n)变长字段+允许 Null=n*(utf8=3,gbk=2,latin1=1)+1(NULL)+2
搞那么复杂,其实就是可变长需要2byte控制,允许null需要1byte控制
数值类型计算
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aR49D2ee-1602490777390)(6C181C93104F4EB1B5DC81402BE85063)]](https://i-blog.csdnimg.cn/blog_migrate/2243c1b51422d46d6782d6b14531c785.png)
CREATE TABLE `numberKeyLen ` (
`c0` INT (255) NOT NULL,
`c1` TINYINT (255) NULL DEFAULT NULL,
`c2` SMALLINT (255) NULL DEFAULT NULL,
`c3` MEDIUMINT (255) NULL DEFAULT NULL,
`c4` INT (255) NULL DEFAULT NULL,
`c5` BIGINT (255) NULL DEFAULT NULL,
`c6` FLOAT (255, 0) NULL DEFAULT NULL,
`c7` DOUBLE (255, 0) NULL DEFAULT NULL,
PRIMARY KEY (`c0`),
INDEX `index_tinyint` (`c1`) USING BTREE,
INDEX `index_smallint` (`c2`) USING BTREE,
INDEX `index_mediumint` (`c3`) USING BTREE,
INDEX `index_int` (`c4`) USING BTREE,
INDEX `index_bigint` (`c5`) USING BTREE,
INDEX `index_float` (`c6`) USING BTREE,
INDEX `index_double` (`c7`) USING BTREE
) ENGINE = INNODB DEFAULT CHARACTER
SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = COMPACT
12345678910111213141516171819
这写的啥玩意。。我也不知道,删删
日期和时间类型计算
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tQR8Hkqx-1602490777392)(C833F0B59F274FD0A9742085295CE0AC)]](https://i-blog.csdnimg.cn/blog_migrate/96c9c13e7b22da95159f540d17924ee0.png)
datetime 类型在 5.6 中字段长度是 5 个字节
datetime 类型在 5.5 中字段长度是 8 个字节
CREATE TABLE `datatimekeylen ` (
`c1` date NULL DEFAULT NULL,
`c2` time NULL DEFAULT NULL,
`c3` YEAR NULL DEFAULT NULL,
`c4` datetime NULL DEFAULT NULL,
`c5` TIMESTAMP NULL DEFAULT NULL,
INDEX `index_date` (`c1`) USING BTREE,
INDEX `index_time` (`c2`) USING BTREE,
INDEX `index_year` (`c3`) USING BTREE,
INDEX `index_datetime` (`c4`) USING BTREE,
INDEX `index_timestamp` (`c5`) USING BTREE
) ENGINE = INNODB DEFAULT CHARACTER
SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = COMPACT
12345678910111213141516
总结
字符类型
变长字段需要额外的 2 个字节(VARCHAR 值保存时只保存需要的字符数,另加一个字节来记录长度(如果列声明的长度超过 255,则使用两个字节),所以 VARCAHR 索引长度计算时候要加 2),固定长度字段不需要额外的字节。
而 NULL 都需要 1 个字节的额外空间,所以索引字段最好不要为 NULL,因为 NULL 让统计更加复杂并且需要额外的存储空间。
复合索引有最左前缀的特性,如果复合索引能全部使用上,则是复合索引字段的索引长度之和,这也可以用来判定复合索引是否部分使用,还是全部使用。
整数/浮点数/时间类型的索引长度
NOT NULL=字段本身的字段长度
NULL=字段本身的字段长度+1(因为需要有是否为空的标记,这个标记需要占用 1
个字节)
datetime 类型在 5.6 中字段长度是 5 个字节,datetime 类型在 5.5 中字段长度是 8 个字节
Ref
显示索引的哪一列被使用了,如果可能的话,是一个常数。哪些列或常量被用于查找索引列上的值
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ieoqwrkg-1602490777394)(23C39A38AB3A428693B43289ED533878)]](https://i-blog.csdnimg.cn/blog_migrate/999101ca668fc1b54a0fdcb1cd7909c6.png)
由 key_len 可知 t1 表的 idx_col1_col2 被充分使用,col1 匹配 t2 表的 col1,col2 匹配了一个常量,即 ‘ac’
其中 【shared.t2.col1】 为 【数据库.表.列】
Rows
根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oDUmLD7Q-1602490777396)(B407510B0C784F0BBBA3A54D43F4E1B7)]](https://i-blog.csdnimg.cn/blog_migrate/8575ce2066d02a5cd2a37f9d617dbaed.png)
Extra
包含不适合在其他列中显示但十分重要的额外信息。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kxMyJQMk-1602490777397)(48CB72F03C734767B0DF087280D8F396)]](https://i-blog.csdnimg.cn/blog_migrate/292f2bdbff3dfab0cacd6504566ca01a.png)
Using filesort
说明 mysql 会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。 MySQL 中无法利用索引完成的排序操作称为“文件排序”
当发现有 Using filesort 后,实际上就是发现了可以优化的地方
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pBzFntst-1602490777399)(BFF486FDB57141A2AFE2AF65E651C88E)]](https://i-blog.csdnimg.cn/blog_migrate/8f51860ca8539d35facf2a0a779a6956.png)
上图其实是一种索引失效的情况,后面会讲,可以看出查询中用到了个联合索引,索引分别为 col1,col2,col3
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GtPBpy7Z-1602490777401)(C18F29C95B0F458C88404E977C452C5C)]](https://i-blog.csdnimg.cn/blog_migrate/301beb06da80b383ec6abd93e83bf2b4.png)
当我排序新增了个 col2,发现 using filesort 就没有了。
EXPLAIN select col1 from t1 where col1=‘ac’ order by col3
EXPLAIN select col1 from t1 where col1=‘ac’ order by col2,col3
这你可是真是个逗比… 左前缀啊,左前缀
Using temporary
使了用临时表保存中间结果,MySQL 在对查询结果排序时使用临时表。常见于排序 order by和分组查询 group by。
尤其发现在执行计划里面有 using filesort 而且还有 Using temporary 的时候,特别需要注意
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vWIhLohX-1602490777403)(7E2579D2CF1643DF8A69B0ACBDD3F45A)]](https://i-blog.csdnimg.cn/blog_migrate/43ecdcc926ec8bc8d5efc94b1104a54b.png)
Using index
表示相应的 select 操作中使用了覆盖索引(Covering Index),避免访问了表的数据行,效率不错!
如果同时出现 using where,表明索引被用来执行索引键值的查找;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4c2CTNKj-1602490777405)(3FD447A140C34DE6BD0BEC38AC60E69A)]](https://i-blog.csdnimg.cn/blog_migrate/c08e84a895db6732e4bcde3fd8b0c666.png)
如果没有同时出现 using where,表明索引用来读取数据而非执行查找动作
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7S6DnCFD-1602490777408)(279BE156B0914E92AD6F086E899D2912)]](https://i-blog.csdnimg.cn/blog_migrate/139f77d1ada9abdac14baea304142e58.png)
这里提一下覆盖索引
覆盖索引(Covering Index),一说为索引覆盖。
理解方式一:就是 select 的数据列只用从索引中就能够取得,不必读取数据行,MySQL 可以利用索引返回 select 列表中的字段,而不必根据索引再次读取数据文件,换句话说查询列要被所建的索引覆盖。
理解方式二:索引是高效找到行的一个方法,但是一般数据库也能使用索引找到一个列的数据,因此它不必读取整个行。毕竟索引叶子节点存储了它们索引的数据;当能通过读取索引就可以得到想要的数据,那就不需要读取行了。一个索引包含了(或覆盖了)满足查询结果的数据就叫做覆盖索引
这写的是个啥,索引就是一个简化表,就这么个事
注意:
如果要使用覆盖索引,一定要注意 select 列表中只取出需要的列,不可 select *,因为如果将所有字段一起做索引会导致索引文件过大,查询性能下降。所以,千万不能为了查询而在所有列上都建立索引,会严重影响修改维护的性能
这不是性能下降,这是逗比行为…
Using where 与 using join buffer
Using where
表明使用了 where 过滤
using join buffer
使用了连接缓存:
show VARIABLES like '%join_buffer_size%'
1
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TWDicC4C-1602490777410)(2EDA275735674731B1E58AD75AB1D3A4)]](https://i-blog.csdnimg.cn/blog_migrate/d8ef0fd4db4eec5c92051128eecc4206.png)
impossible where
where 子句的值总是 false,不能用来获取任何元组
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AWRB0YtV-1602490777412)(DA7B4D28C5994DD69E93D241B793B4F1)]](https://i-blog.csdnimg.cn/blog_migrate/aede383f5c4a285ffe0a25e9c0bca4bc.png)
SQL优化
优化实战
尽量全值匹配
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ndy3ccul-1602490777414)(4EF09CD68ECC4EBBB5FC8EC2E0E1E885)]](https://i-blog.csdnimg.cn/blog_migrate/24cd9901b1f146c402c3dde25c8e0183.png)
CREATE TABLE `staffs` (
id INT PRIMARY KEY auto_increment,
NAME VARCHAR (24) NOT NULL DEFAULT "" COMMENT '姓名',
age INT NOT NULL DEFAULT 0 COMMENT '年龄',
pos VARCHAR (20) NOT NULL DEFAULT "" COMMENT '职位',
add_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间'
) charset utf8 COMMENT '员工记录表';
insert into staffs(name,age,pos,add_time) values('z3',22,'manage',now());
insert into staffs(name,age,pos,add_time) values('july',23,'dev',now());
insert into staffs(name,age,pos,add_time) values('2000',23,'dev',now());
alter table staffs add index idx_staffs_nameAgePos(name,age,pos);
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July';
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July' AND age = 25;
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July' AND age = 25 AND pos = 'dev'
当建立了索引列后,能在 wherel 条件中使用索引的尽量所用。
这个例子毫无意义,主要想说的就是一点,尽量明确自己需要的字段,避免返回过多数据。
最佳左前缀法则
如果索引了多列,要遵守最左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引中的列。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jWzfPU7R-1602490777416)(616684E08DA74D449743850A57E09862)]](https://i-blog.csdnimg.cn/blog_migrate/3ad4e8dc7ae5cfd61c53e818ae88882b.png)
不在索引列上做函数计算等操作
不在索引列上做任何操作(计算、函数、(自动 or 手动)类型转换),可能会导致索引失效而转向全表扫描
。即便不失效,也会将索引列遍历计算,影响性能。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QIKsFGvh-1602490777418)(AA572F2F36FD4A0D91C93A85C4E1E08F)]](https://i-blog.csdnimg.cn/blog_migrate/fc59523990555d96fe37c02e1a863e5b.png)
范围条件放最后
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9BivD071-1602490777419)(95E99406495A4BBB81DB4D0162D5682A)]](https://i-blog.csdnimg.cn/blog_migrate/beea5f588bacaacd9d8be94908261757.png)
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July' ;
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July' and age =22;
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July' and age =22 and pos='manager'
中间有范围查询会导致范围字段后面的索引列全部失效
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July' and age >22 and pos='manager'
覆盖索引尽量用
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ge41gQDV-1602490777421)(BBE28DB89A1644D5BAD65553FF37E4B7)]](https://i-blog.csdnimg.cn/blog_migrate/4412921ce1e06b506112553622b1aabe.png)
尽量使用覆盖索引(只访问索引的查询(索引列和查询列一致)),减少 select *
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July' and age =22 and pos='manager'
EXPLAIN SELECT name,age,pos FROM staffs WHERE NAME = 'July' and age =22 and pos='manager';
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July' and age >22 and pos='manager';
EXPLAIN SELECT name,age,pos FROM staffs WHERE NAME = 'July' and age >22 and pos='manager';
原则上是这样,适可而止,最小限度满足查询列,最大限度增加查询条件,目的是达到数据返回量最小。
不等于要甚用
mysql 在使用不等于(!= 或者<>)的时候无法使用索引会导致全表扫描
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-osvZwTAQ-1602490777424)(2671850465CD472CB55C5A9A3E62B3DE)]](https://i-blog.csdnimg.cn/blog_migrate/af2b0d3686075f6bcddb15b655c60ee5.png)
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July';
EXPLAIN SELECT * FROM staffs WHERE NAME != 'July';
EXPLAIN SELECT * FROM staffs WHERE NAME <> 'July';
如果定要需要使用不等于,请用覆盖索引
EXPLAIN SELECT name,age,pos FROM staffs WHERE NAME != 'July';
EXPLAIN SELECT name,age,pos FROM staffs WHERE NAME <> 'July';
还是那句话,适可而止,全表扫描又怎么样,cost消耗才是真的决定执行计划的东西
Null/Not null 有影响
注意 null/not null 对索引的可能影响
自定定义为 NOT NULL
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HqORtKQz-1602490777426)(3B07B128F16048578E1E3136941E9B08)]](https://i-blog.csdnimg.cn/blog_migrate/a11d118fb1d0bed8dc743bfe010d377d.png)
EXPLAIN select * from staffs where name is null;
EXPLAIN select * from staffs where name is not null;
在字段为 not null 的情况下,使用 is null 或 is not null 会导致索引失效
但是is null都已经不扫描表和索引了,就不用在意了,但not null 这种还是真需要覆盖索引的。
解决方式:覆盖索引
自定义为 NULL 或者不定义
此时允许空值存在。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lih1DIdi-1602490777427)(F0F0E2AAA1864EBCBF0791506141006B)]](https://i-blog.csdnimg.cn/blog_migrate/5b04083479b972d3cb59b06642436f07.png)
EXPLAIN select * from staffs2 where name is null
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5s1Z1qoF-1602490777429)(A863C2533D484A958C5337E19CC7149E)]](https://i-blog.csdnimg.cn/blog_migrate/cdf887fb2fae8f32b2ec8da1cf7dd548.png)
EXPLAIN select * from staffs2 where name is not null
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Msybe19q-1602490777431)(67C12EE184644C479B4AEEFC31BF49DF)]](https://i-blog.csdnimg.cn/blog_migrate/7ea90aed7d58d89c110774b10819ef70.png)
Is not null 的情况会导致索引失效
解决方式:覆盖索引
总结,这个部分还真是深入浅出,有点需要明确
null值不影响性能,not null 才是罪魁祸首。这种条件本身就是遍历索引的存在。
Like 查询要当心
like 以通配符开头(’%abc…’)mysql 索引失效会变成全表扫描的操作
前通配符会导致索引失效,后通配符还是能用的
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Sv9K0NwQ-1602490777433)(59CAC1D26CF44482BB382765C245FB3A)]](https://i-blog.csdnimg.cn/blog_migrate/5b93e0a9e01a1243ef553a6dabfdf31b.png)
EXPLAIN select * from staffs where name ='july';
EXPLAIN select * from staffs where name like '%july%';
EXPLAIN select * from staffs where name like '%july';
EXPLAIN select * from staffs where name like 'july%';
解决方式:覆盖索引
隐式转换问题
字符串不加单引号索引失效
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wlQMEm9A-1602490777435)(4A6B7B4CE6CF4B12AA57D1B92A30B7A2)]](https://i-blog.csdnimg.cn/blog_migrate/391bb1321264ba1e6e9cdc04d48b317b.png)
数值型并没有隐式转换成varchar使用索引。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HfBje3BH-1602490777437)(67E54F19C1CC48D8B7A6D5365FC3B0C5)]](https://i-blog.csdnimg.cn/blog_migrate/551fffb30d01add2f41b8562701a01cd.png)
但varchar可以隐式转换为数值型
所以,字符串必须加引号,字符串尽量单引吧。
解决方式:请加引号
OR 改 UNION 效率高
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qqGo9pjU-1602490777438)(C770CB187A9D4B908044400A9D6041DE)]](https://i-blog.csdnimg.cn/blog_migrate/52486c0a2880334596663dd02f91f447.png)
EXPLAIN select * from staffs where name='July' or name = 'z3'
EXPLAIN select * from staffs where name='July' UNION select * from staffs where name = 'z3'
解决方式:覆盖索引
测试题
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nhglDXl9-1602490777440)(45B6D3E94B934FEC97916680377A55BC)]](https://i-blog.csdnimg.cn/blog_migrate/0661733f7e24122299b65a94d2de8f4a.png)
答案
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oW5pbZmW-1602490777442)(C6278280EFF744B08D3007E2A43561CC)]](https://i-blog.csdnimg.cn/blog_migrate/e7d576717941bf19edd8aeb1e8fec63e.png)
记忆总结:
- 全职匹配我最爱,最左前缀要遵守;
- 带头大哥不能死,中间兄弟不能断;
- 索引列上少计算,范围之后全失效;
- LIKE 百分写最右,覆盖索引不写*;
- 不等空值还有 OR,索引影响要注意;
- VAR 引号不可丢, SQL 优化有诀窍。
批量导入优化
批量insert
- 提交前关闭自动提交
- 尽量使用批量 insert 语句
- 可以使用 MyISAM 存储引擎
set session autocommit = 0;
LOAD DATA INFLIE
使用 LOAD DATA INFLIE ,比一般的 insert 语句快 20 倍
select * into OUTFILE 'D:\\product.txt' from product_info
load data INFILE 'D:\\product.txt' into table product_info
load data INFILE '/soft/product3.txt' into table product_info
show VARIABLES like 'secure_file_priv'
- secure_file_priv 为 NULL 时,表示限制 mysqld 不允许导入或导出。
- secure_file_priv 为 /tmp 时,表示限制 mysqld 只能在/tmp 目录中执行导入导出,其他目录不能执行。
- secure_file_priv 没有值时,表示不限制 mysqld 在任意目录的导入导出。
secure_file_priv=''
参数默认关闭,需要在配置文件中修改,重新启动才行。即便mysqldump --tab也是需要开启,因为本质上也是调用select… into outfile
备份恢复
Mysqldump
percona xtrabackup
全量备份、还原
备份
- 指定–defaults-file
xtrabackup --defaults-file=/data/app/mysql-3307/my.cnf --user=dba --password="123456" --port=3307 --backup --target-dir=/data/dump/$(date +%Y%m%d)/
--port可以省略
- 用–datadir取代–defaults-file
xtrabackup --user=dba --password=123456 --backup --datadir=/data/app/mysql-3307/data --target-dir=/data/dump/$(date +%Y%m%d%H%M%S)/
备份压缩:
xtrabackup --defaults-file=/etc/my.cnf--user=root --password="" --port=3306 --backup --socket=/usr/local/mysql/mysql.sock--stream=tar --target-dir=/data/backups/mysql/$(date +%Y%m%d)/ |gzip >alldbfullbackup.tar.gz
还原
- 关闭mysql–在copy前关闭
$ mysqladmin -udba -p -h127.0.0.1 -P 3307 shutdown
- prepare
xtrabackup --prepare --target-dir=/data/dump/20180911095738/
- copy
方法1:–copy-back
xtrabackup --defaults-file=/data/app/mysql-3307/my.cnf --copy-back --target-dir=/data/dump/20180911095738/
方法2:rsync或者cp
rsync -avrP /home/zhoujy/xtrabackup/* /var/lib/mysql/
- 改权限、启动
chown -R mysql.mysql *
增量备份、还原
备份
- 库全量备份
xtrabackup --defaults-file=/data/app/mysql-3307/my.cnf --user=dba --password="123456" --backup --parallel=3 --target-dir=/data/dump/$(date +%Y%m%d)/
- 增量备份
xtrabackup --defaults-file=/data/app/mysql-3307/my.cnf --user=dba --password="123456" --backup --parallel=3 --target-dir=/data/dump/$(date +%Y%m%d%H%M%S)/ --incremental-basedir=/data/dump/20180911
注意:要是有多个增量备份,第2个增量需要指定第一个增量的目录。和innobackupex一样。
还原
prepare全备
xtrabackup --prepare --apply-log-only --target-dir=/data/dump/20180911
prepare增量
xtrabackup --prepare --apply-log-only --target-dir=/data/dump/20180911 --incremental-dir=/data/dump/20180911114234
prepare 全备
xtrabackup --prepare --target-dir=/data/dump/20180911
copy、改权限
指定表的备份
--databases=dbname.tablename和--tables-file,也可以用--tables(–include),支持正则。
如备份sakila2开头的数据库下的所有表:
xtrabackup --defaults-file=/data/app/mysql-3307/my.cnf --user=root --password=123456 --backup --parallel=3 --tables="^sakila2[.].*" --target-dir=/data/dump/$(date +%Y%m%d%H%M%S)/
假如只备份一张表test.t1,参数写法 --tables="^test[.]t1"
压缩备份
xtrabackup --defaults-file=/data/app/mysql-3307/my.cnf --user=root --password=123456 --backup --parallel=3 --compress --compress-threads=5 --databases="ipwappdb sakila2" --target-dir=/data/dump/$(date +%Y%m%d%H%M%S)/
解压
xtrabackup --decompress --target-dir=/data/dump/20180911161605
如果无法解压需要安装插件qpress,安装方式有两种
方式一: yum install qpress
方式二:操作如下
wget http://www.quicklz.com/qpress-11-linux-x64.tar
tar xvf qpress-11-linux-x64.tar
cp qpress /usr/bin
prepare
xtrabackup --prepare --target-dir=/home/zhoujy/xtrabackup/
copy,改权限
打包备份
备份打包
xtrabackup --defaults-file=/data/app/mysql-3307/my.cnf --user=root --password=123456 --backup --parallel=3 --compress --compress-threads=5 --stream=xbstream --target-dir=/data/dump/$(date +%Y%m%d%H%M%S)/ >/data/dump/alldb.xbstream
compress不支持tar解包
xbstream -x < alldb.xbstream
解压
for f in `find ./ -iname "*\.qp"`; do qpress -dT2 $f $(dirname $f) && rm -f $f; done
prepare
copy,改权限
tar压缩备份
xtrabackup --defaults-file=/data/app/mysql-3307/my.cnf --user=root --password=123456 --backup --parallel=3 --stream=tar --target-dir=/data/dump/$(date +%Y%m%d%H%M%S)/ | gzip /data/dump/alldb.tar.gz
解压
tar izxvf alldb.tar.gz
prepare
copy,改权限
加密备份
备份
压缩加密全量备份所有数据库
生成加密key
openssl rand -base64 24
把Key写到文件
echo -n "Ue2Wp6dIDWszpI76HQ1u57exyjAdHpRO" > keyfile
压缩加密全量备份
xtrabackup --user=root --password=123 --datadir=/var/lib/mysql/ --backup --no-timestamp --compress --compress-threads=3 --encrypt=AES256 --encrypt-key-file=/home/zhoujy/keyfile ----encrypt-threads=3 --parallel=5 --target-dir=/home/zhoujy/xtrabackup/
还原
解密
for i in `find . -iname "*\.xbcrypt"`; do xbcrypt -d --encrypt-key-file=/home/zhoujy/keyfile --encrypt-algo=AES256 < $i > $(dirname $i)/$(basename $i .xbcrypt) && rm $i; done
解压
for f in `find ./ -iname "*\.qp"`; do qpress -dT2 $f $(dirname $f) && rm -f $f; done
prepare
$ xtrabackup --prepare --target-dir=/home/zhoujy/xtrabackup/
copy,改权限
$ rsync -avrP /home/zhoujy/xtrabackup/* /var/lib/mysql/
chown -R mysql.mysql *
复制环境中的备份
一般生产环境大部分都是主从模式,主提供服务,从提供备份。
说明:备份 5个线程备份2个数据库,并且文件xtrabackup_slave_info记录GTID和change的信息
备份
xtrabackup --defaults-file=/data/app/mysql-3307/my.cnf --user=root --password=123456 --backup --no-timestamp --slave-info --safe-slave-backup --parallel=5 --target-dir=/data/dump/$(date +%Y%m%d%H%M%S)
还原
prepare
xtrabackup --prepare --target-dir=/home/zhoujy/xtrabackup/
copy,改权限
xtrabackup 参数说明(xtrabackup --help )
--apply-log-only:prepare备份的时候只执行redo阶段,用于增量备份。
--backup:创建备份并且放入--target-dir目录中
--close-files:不保持文件打开状态,xtrabackup打开表空间的时候通常不会关闭文件句柄,目的是为了正确处理DDL操作。如果表空间数量非常巨大并且不适合任何限制,一旦文件不在被访问的时候这个选项可以关闭文件句柄.打开这个选项会产生不一致的备份。
--compact:创建一份没有辅助索引的紧凑备份
--compress:压缩所有输出数据,包括事务日志文件和元数据文件,通过指定的压缩算法,目前唯一支持的算法是quicklz.结果文件是qpress归档格式,每个xtrabackup创建的*.qp文件都可以通过qpress程序提取或者解压缩
--compress-chunk-size=#:压缩线程工作buffer的字节大小,默认是64K
--compress-threads=#:xtrabackup进行并行数据压缩时的worker线程的数量,该选项默认值是1,并行压缩('compress-threads')可以和并行文件拷贝('parallel')一起使用。例如:'--parallel=4 --compress --compress-threads=2'会创建4个IO线程读取数据并通过管道传送给2个压缩线程。
--create-ib-logfile:这个选项目前还没有实现,目前创建Innodb事务日志,你还是需要prepare两次。
--datadir=DIRECTORY:backup的源目录,mysql实例的数据目录。从my.cnf中读取,或者命令行指定。
--defaults-extra-file=[MY.CNF]:在global files文件之后读取,必须在命令行的第一选项位置指定。
--defaults-file=[MY.CNF]:唯一从给定文件读取默认选项,必须是个真实文件,必须在命令行第一个选项位置指定。
--defaults-group=GROUP-NAME:从配置文件读取的组,innobakcupex多个实例部署时使用。
--export:为导出的表创建必要的文件
--extra-lsndir=DIRECTORY:(for --bakcup):在指定目录创建一份xtrabakcup_checkpoints文件的额外的备份。
--incremental-basedir=DIRECTORY:创建一份增量备份时,这个目录是增量别分的一份包含了full bakcup的Base数据集。
--incremental-dir=DIRECTORY:prepare增量备份的时候,增量备份在DIRECTORY结合full backup创建出一份新的full backup。
--incremental-force-scan:创建一份增量备份时,强制扫描所有增在备份中的数据页即使完全改变的page bitmap数据可用。
--incremetal-lsn=LSN:创建增量备份的时候指定lsn。
--innodb-log-arch-dir:指定包含归档日志的目录。只能和xtrabackup --prepare选项一起使用。
--innodb-miscellaneous:从My.cnf文件读取的一组Innodb选项。以便xtrabackup以同样的配置启动内置的Innodb。通常不需要显示指定。
--log-copy-interval=#:这个选项指定了log拷贝线程check的时间间隔(默认1秒)。
--log-stream:xtrabakcup不拷贝数据文件,将事务日志内容重定向到标准输出直到--suspend-at-end文件被删除。这个选项自动开启--suspend-at-end。
--no-defaults:不从任何选项文件中读取任何默认选项,必须在命令行第一个选项。
--databases=#:指定了需要备份的数据库和表。
--database-file=#:指定包含数据库和表的文件格式为databasename1.tablename1为一个元素,一个元素一行。
--parallel=#:指定备份时拷贝多个数据文件并发的进程数,默认值为1。
--prepare:xtrabackup在一份通过--backup生成的备份执行还原操作,以便准备使用。
--print-default:打印程序参数列表并退出,必须放在命令行首位。
--print-param:使xtrabackup打印参数用来将数据文件拷贝到datadir并还原它们。
--rebuild_indexes:在apply事务日志之后重建innodb辅助索引,只有和--prepare一起才生效。
--rebuild_threads=#:在紧凑备份重建辅助索引的线程数,只有和--prepare和rebuild-index一起才生效。
--stats:xtrabakcup扫描指定数据文件并打印出索引统计。
--stream=name:将所有备份文件以指定格式流向标准输出,目前支持的格式有xbstream和tar。
--suspend-at-end:使xtrabackup在--target-dir目录中生成xtrabakcup_suspended文件。在拷贝数据文件之后xtrabackup不是退出而是继续拷贝日志文件并且等待知道xtrabakcup_suspended文件被删除。这项可以使xtrabackup和其他程序协同工作。
--tables=name:正则表达式匹配database.tablename。备份匹配的表。
--tables-file=name:指定文件,一个表名一行。
--target-dir=DIRECTORY:指定backup的目的地,如果目录不存在,xtrabakcup会创建。如果目录存在且为空则成功。不会覆盖已存在的文件。
--throttle=#:指定每秒操作读写对的数量。
--tmpdir=name:当使用--print-param指定的时候打印出正确的tmpdir参数。
--to-archived-lsn=LSN:指定prepare备份时apply事务日志的LSN,只能和xtarbackup --prepare选项一起用。
--user-memory = #:通过--prepare prepare备份时候分配多大内存,目的像innodb_buffer_pool_size。默认值100M如果你有足够大的内存。1-2G是推荐值,支持各种单位(1MB,1M,1GB,1G)。
--version:打印xtrabackup版本并退出。
--xbstream:支持同时压缩和流式化。需要客服传统归档tar,cpio和其他不允许动态streaming生成的文件的限制,例如动态压缩文件,xbstream超越其他传统流式/归档格式的的优点是,并发stream多个文件并且更紧凑的数据存储(所以可以和--parallel选项选项一起使用xbstream格式进行streaming)。
load
数据库中间件
mycat
安装配置
mysql主从配置
主服务器端口:3307 从服务器端口:3308
下载mysql5.7.2
wget https://cdn.mysql.com/archives/mysql-5.7/mysql-5.7.21-linux-glibc2.12-x86_64.tar.gz
若下载中断掉客户端,可使用wget -c命令继续下载
创建mysql用户和目录
新增用户,组
groupadd mysql
useradd -r -g mysql -s /bin/false mysql
/bin/false可以禁止mysql用户登录系统
新增目录
/data/app/mysql-3307 /data/app/mysql-3308
将解压后的文件放置在该目录下并赋权
cp -rf ./mysql-5.7.21-linux-glibc2.12-x86_64/. /data/app/mysql-3307
cp -rf ./mysql-5.7.21-linux-glibc2.12-x86_64/. /data/app/mysql-3308
chown -R mysql:mysql /data/app/mysql-3307
chown -R mysql:mysql /data/app/mysql-3308
/data/app/mysql-3307/bin/mysqld --initialize-insecure --user=mysql --basedir=/data/app/mysql-3307 --datadir=/data/app/mysql-3307/data
/data/app/mysql-3308/bin/mysqld --initialize-insecure --user=mysql --basedir=/data/app/mysql-3308 --datadir=/data/app/mysql-3308/data
配置mysql.cnf文件
/data/app/mysql-3307/my.cnf
[client]
port = 3307
socket=/data/app/mysql-3307/mysql.sock
[mysqld]
port =3307
user=mysql
server-id=1
bind-address=0.0.0.0
basedir=/data/app/mysql-3307
datadir=/data/app/mysql-3307/data
socket=/data/app/mysql-3307/mysql.sock
pid-file=/data/app/mysql-3307/mysql.pid
log-error=/data/app/mysql-3307/mysqld.log
skip-name-resolve
log_bin=/data/app/mysql-3307/mysql-bin
log-slave-updates
auto-increment-increment=2
auto-increment-offset=1
lower_case_table_names=1
sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION'
binlog_format=mixed
mysql-3308相同操作
/data/app/mysql-3308/my.cnf
[client]
port = 3308
socket=/data/app/mysql-3308/mysql.sock
[mysqld]
port =3308
user=mysql
server-id=1
bind-address=0.0.0.0
basedir=/data/app/mysql-3308
datadir=/data/app/mysql-3308/data
socket=/data/app/mysql-3308/mysql.sock
pid-file=/data/app/mysql-3308/mysql.pid
log-error=/data/app/mysql-3308/mysqld.log
skip-name-resolve
log_bin=/data/app/mysql-3308/mysql-bin
log-slave-updates
#auto-increment-increment=2
#auto-increment-offset=1
lower_case_table_names=1
sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION'
binlog_format=mixed
touch /data/app/mysql-3307/mysqld.log && chown -R mysql:mysql /data/app/
touch /data/app/mysql-3308/mysqld.log && chown -R mysql:mysql /data/app/
替代/data/app/mysql-3307/bin/mysqld_safe文件中/usr/local/mysql为/data/app/mysql-3307
sed -i 's#/usr/local/mysql#/data/app/mysql-3307#g' /data/app/mysql-3307/bin/mysqld_safe
sed -i 's#/usr/local/mysql#/data/app/mysql-3308#g' /data/app/mysql-3308/bin/mysqld_safe
mysql启动,修改密码
/data/app/mysql-3307/bin/mysqld_safe --defaults-file=/data/app/mysql-3307/my.cnf --basedir=/data/app/mysql-3307 --datadir=/data/app/mysql-3307/data --user=mysql &
/data/app/mysql-3307/bin/mysqld_safe --defaults-file=/data/app/mysql-3307/my.cnf --basedir=/data/app/mysql-3307 --datadir=/data/app/mysql-3307/data --user=mysql
首次无法登陆,原因为/root/.mysql.secret密码不对 my.cnf增加 skip-grant-tables
登陆mysql
mysql -uroot -S mysql.sock -P 3307
mysql> alter user root@localhost identified by '123456';
ERROR 1290 (HY000): The MySQL server is running with the --skip-grant-tables option so it cannot execute this statement
mysql> update mysql.user set authentication_string=password('123456') where user='root' and host='localhost';
Query OK, 1 row affected, 1 warning (0.13 sec)
Rows matched: 1 Changed: 1 Warnings: 1
重新启动
$ mysqladmin -S mysql.sock shutdown -uroot -p
/data/app/mysql-3307/bin/mysqld_safe --defaults-file=/data/app/mysql-3307/my.cnf --basedir=/data/app/mysql-3307 --datadir=/data/app/mysql-3307/data --user=mysql &
数据库主备配置
master端
mysql> create user 'repl'@'%' identified by '123456';
Query OK, 0 rows affected (0.06 sec)
mysql> grant replication slave on *.* to 'repl'@'%';
Query OK, 0 rows affected (0.01 sec)
mysql> show master status;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000004 | 605 | | | |
+------------------+----------+--------------+------------------+-------------------+
slave端
mysql> change master to master_host='127.0.0.1',master_port=3307,master_user='repl',master_password='123456',master_log_file='mysql-bin.000004',master_log_pos=605;
Query OK, 0 rows affected, 2 warnings (0.13 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.10 sec)
mysql> start slave;
Query OK, 0 rows affected (0.00 sec)
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State:
Master_Host: 127.0.0.1
Master_User: repl
Master_Port: 3307
Connect_Retry: 60
Master_Log_File: mysql-bin.000004
Read_Master_Log_Pos: 605
Relay_Log_File: VM_0_2_centos-relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: mysql-bin.000004
Slave_IO_Running: No
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 605
Relay_Log_Space: 154
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 1593
Last_IO_Error: Fatal error: The slave I/O thread stops because master and slave have equal MySQL server ids; these ids must be different for replication to work (or the --replicate-same-server-id option must be used on slave but this does not always make sense; please check the manual before using it).
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID:
Master_Info_File: /data/app/mysql-3308/data/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp: 180714 11:58:14
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)
安装生产JDK
- 删除openjdk
rpm -qa|grep java
yum -y remove java*
- 安装java
rpm -ivh jdk-8u171-linux-x64.rpm
java -version
mycat 安装配置
解压并修改文件
解压缩到/data/app目录下
修改/data/app/mycat/conf/schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<!-- auto sharding by id (long) -->
<table name="travelrecord" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" />
<!-- global table is auto cloned to all defined data nodes ,so can join
with any table whose sharding node is in the same data node -->
<table name="temp" primaryKey="ID" type="global" dataNode="dn1" />
<table name="company" primaryKey="ID" type="global" dataNode="dn1,dn2,dn3" />
<table name="goods" primaryKey="ID" type="global" dataNode="dn1,dn2" />
<!-- random sharding using mod sharind rule -->
<table name="hotnews" primaryKey="ID" autoIncrement="true" dataNode="dn1,dn2,dn3"
rule="mod-long" />
<!-- <table name="dual" primaryKey="ID" dataNode="dnx,dnoracle2" type="global"
needAddLimit="false"/> <table name="worker" primaryKey="ID" dataNode="jdbc_dn1,jdbc_dn2,jdbc_dn3"
rule="mod-long" /> -->
<table name="employee" primaryKey="ID" dataNode="dn1,dn2"
rule="sharding-by-intfile" />
<table name="customer" primaryKey="ID" dataNode="dn1,dn2"
rule="sharding-by-intfile">
<childTable name="orders" primaryKey="ID" joinKey="customer_id"
parentKey="id">
<childTable name="order_items" joinKey="order_id"
parentKey="id" />
</childTable>
<childTable name="customer_addr" primaryKey="ID" joinKey="customer_id"
parentKey="id" />
</table>
<!-- <table name="oc_call" primaryKey="ID" dataNode="dn1$0-743" rule="latest-month-calldate"
/> -->
</schema>
<!-- <dataNode name="dn1$0-743" dataHost="localhost1" database="db$0-743"
/> -->
<dataNode name="dn1" dataHost="localhost1" database="test" />
<dataNode name="dn2" dataHost="localhost1" database="test" />
<dataNode name="dn3" dataHost="localhost1" database="test" />
<!--<dataNode name="dn4" dataHost="sequoiadb1" database="SAMPLE" />
<dataNode name="jdbc_dn1" dataHost="jdbchost" database="db1" />
<dataNode name="jdbc_dn2" dataHost="jdbchost" database="db2" />
<dataNode name="jdbc_dn3" dataHost="jdbchost" database="db3" /> -->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="localhost:3307" user="dba"
password="123456">
<!-- can have multi read hosts -->
<readHost host="hostS1" url="localhost:3308" user="dba" password="123456" />
</writeHost>
<writeHost host="hostM2" url="localhost:3309" user="dba"
password="123456">
<!-- can have multi read hosts -->
<readHost host="hostS2" url="localhost:3310" user="dba" password="123456" />
</writeHost>
<!-- <writeHost host="hostM2" url="localhost:3310" user="root" password="123456"/> -->
</dataHost>
server.xml文件注意部分,用于登陆mycat的用户名密码
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">TESTDB</property>
启动mycat
/data/app/mycat/bin/mycat start
启动日志:/data/app/mycat/logs/wrapper.log查看启动进度
登陆mycat
-h处指定
mysql -uroot -p -h127.0.0.1 -P8066
swap空间不足报错
2018-07-16T03:39:46.301178Z 0 [ERROR] InnoDB: mmap(137428992 bytes) failed; errno 12
2018-07-16T03:39:46.301200Z 0 [ERROR] InnoDB: Cannot allocate memory for the buffer pool
schema.xml文件说明
TESTDB是默认的库,在启动时会默认启动配置,生成指定的一个逻辑库,库名TESTDB,可修改server和schmas中TESTDB。- 表名指定,主键指定,类型对应的数据节点指定几个,写入节点就为几个。该例子中一旦
dataNode="dn1,dn2,dn3",写入的时候会向对应位置写入,即便对应位置相同。 dataNode可以认为是写入节点。相同的一套数据源指定一个dataNode。
各参数含义详情参考mycat帮助文档。
dbDriver 属性
指定连接后端数据库使用的 Driver,目前可选的值有 native 和 JDBC。使用 native 的话,因为这个值执行的是二进制的 mysql 协议,所以可以使用 mysql 和 maridb。其他类型的数据库则需要使用 JDBC 驱动来支持。
从 1.6 版本开始支持 postgresql 的 native 原始协议。
如果使用 JDBC 的话需要将符合 JDBC 4 标准的驱动 JAR 包放到 MYCAT\lib 目录下,并检查驱动 JAR 包中包括如下目录结构的文件:META-INF\services\java.sql.Driver。在这个文件内写上具体的 Driver 类名,例如:com.mysql.jdbc.Driver。
balance 属性
负载均衡类型,目前的取值有 3 种:
- balance=“0”, 不开启读写分离机制,所有读操作都发送到当前可用的writeHost上。
- balance=“1”,全部的readHost与stand by writeHost参与select语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且M1与 M2互为主备),正常情况下,M2,S1,S2都参与select语句的负载均衡。
- balance=“2”,所有读操作都随机的在writeHost、readhost上分发。
- balance=“3”,所有读请求随机的分发到wiriterHost对应的readhost执行,writerHost不负担读压力,注意balance=3只在1.4及其以后版本有,1.3没有。
writeType 属性
负载均衡类型,目前的取值有 3 种:
- writeType=”0”, 所有写操作发送到配置的第一个 writeHost,第一个挂了切到还生存的第二个 writeHost,重新启动后已切换后的为准,切换记录在配置文件中:dnindex.properties .
- writeType=”1”,所有写操作都随机的发送到配置的 writeHost,1.5 以后废弃不推荐。
switchType 属性
- -1 表示不自动切换
- 1 默认值,自动切换
- 2 基于MySQL主从同步的状态决定是否切换
监控命令
show engine innodb status
详细解读
注:以下内容为根据《高性能mysql第三版》和《mysql技术内幕innodb存储引擎》的innodb status部分的个人理解,如果有错误,还望指正!!
innodb存储引擎在show engine innodb status(老版本对应的是show innodb status)输出中,显示除了大量的内部信息,它输出就是一个单独的字符串,没有行和列,内容分为很多小段,每一段对应innodb存储引擎不同部分的信息,其中有一些信息对于innodb开发者来说非常有用,但是,许多信息,如果你尝试去理解,并且应用到高性能innodb调优的时候,你会发现它们非常有趣,甚至是非常有必要的。
输出内容中包含了一些平均值的统计信息,这些平均值是自上次输出结果生成以来的统计数,因此,如果你正在检查这些值,那就要确保已经等待了至少30s的时间,使两次采样之间的积累足够长的统计时间并多次采样,检查计数器变化从而弄清其行为,并不是所有的输出都会在一个时间点上生成,因而也不是所有的显示出来的平均值会在同一时间间隔里重新再计算。而且,innodb有一个内部复位间隔,而它是不可预知的,各个版本也不一样。
这些输出信息足够提供给手工计算出大多数你想要的统计信息,有一款监控工具innotop可以帮你计算出增量差值和平均值。下面,在你的mysql命令行敲下show engine innodb status;看着输出跟着下面的步骤一步一步理解输出信息是什么含义:
注意:以下使用mysql5.5.24版本做解读,mysql5.6.x和5.7.x输出内容有些地方有调整。
1.第一段是头部信息,它仅仅声明了输出的开始,其内容包括当前的日期和时间,以及自上次输出以来经过的时长。
=====================================
160129 12:07:26 INNODB MONITOR OUTPUT #第二行是当前日期和时间
=====================================
Per second averages calculated from the last 24 seconds #第四行显示的是计算出这一平均值的时间间隔,即自上次输出以来的时间,或者是距上次内部复位的时长
2.从innodb1.0.x开始,可以使用命令show engine innodb status;来查看master thread的状态信息:
-----------------
BACKGROUND THREAD
-----------------
srv_master_thread loops: 30977173 1_second, 30975685 sleeps, 3090359 10_second, 166112 background, 165988 flush #这行显示主循环进行了30977173 1_second次,每秒挂起的操作进行了30975685 sleeps次(说明负载不是很大),10秒一次的活动进行了3090359 10_second次,1秒循环和10秒循环比值符合1:10,backgroup loop进行了166112 background次,flush loop进行了165988 flush次,如果在一台很大压力的mysql上,可能看到每秒运行次数和挂起次数比例小于1很多,这是因为innodb对内部进行了一些优化,当压力大时间隔时间并不总是等待1秒,因此,不能认为每秒循环和挂起的值总是相等,在某些情况下,可以通过两者之间的差值来比较反映当前数据库的负载压力。
srv_master_thread log flush and writes: 31160103
3.如果有高并发的工作负载,你就要关注下接下来的段(SEMAPHORES信号量),它包含了两种数据:事件计数器以及可选的当前等待线程的列表,如果有性能上的瓶颈,可以使用这些信息来找出瓶颈,不幸的是,想知道怎么使用这些信息还是有一点复杂,下面先给出一些解释:
----------
SEMAPHORES
----------
OS WAIT ARRAY INFO: reservation count 68581015, signal count 218437328
--Thread 140653057947392 has waited at btr0pcur.c line 437 for 0.00 seconds the semaphore:
S-lock on RW-latch at 0x7ff536c7d3c0 created in file buf0buf.c line 916
a writer (thread id 140653057947392) has reserved it in mode exclusive
number of readers 0, waiters flag 1, lock_word: 0
Last time read locked in file row0sel.c line 3097
Last time write locked in file /usr/local/src/soft/mysql-5.5.24/storage/innobase/buf/buf0buf.c line 3151
--Thread 140653677291264 has waited at btr0pcur.c line 437 for 0.00 seconds the semaphore:
S-lock on RW-latch at 0x7ff53945b240 created in file buf0buf.c line 916
a writer (thread id 140653677291264) has reserved it in mode exclusive
number of readers 0, waiters flag 1, lock_word: 0
Last time read locked in file row0sel.c line 3097
Last time write locked in file /usr/local/src/soft/mysql-5.5.24/storage/innobase/buf/buf0buf.c line 3151
Mutex spin waits 1157217380, rounds 1783981614, OS waits 10610359
RW-shared spins 103830012, rounds 1982690277, OS waits 52051891
RW-excl spins 43730722, rounds 602114981, OS waits 3495769
Spin rounds per wait: 1.54 mutex, 19.10 RW-shared, 13.77 RW-excl
内容比较多,下面分段依次解释:
3.1.
OS WAIT ARRAY INFO: reservation count 68581015, signal count 218437328 #这行给出了关于操作系统等待数组的信息,它是一个插槽数组,innodb在数组里为信号量保留了一些插槽,操作系统用这些信号量给线程发送信号,使线程可以继续运行,以完成它们等着做的事情,这一行还显示出innodb使用了多少次操作系统的等待:保留统计(reservation count)显示了innodb分配插槽的频度,而信号计数(signal count)衡量的是线程通过数组得到信号的频度,操作系统的等待相对于空转等待(spin wait)要昂贵些。
3.2.
--Thread 140653057947392 has waited at btr0pcur.c line 437 for 0.00 seconds the semaphore:
S-lock on RW-latch at 0x7ff536c7d3c0 created in file buf0buf.c line 916
a writer (thread id 140653057947392) has reserved it in mode exclusive
number of readers 0, waiters flag 1, lock_word: 0
Last time read locked in file row0sel.c line 3097
Last time write locked in file /usr/local/src/soft/mysql-5.5.24/storage/innobase/buf/buf0buf.c line 3151
--Thread 140653677291264 has waited at btr0pcur.c line 437 for 0.00 seconds the semaphore:
S-lock on RW-latch at 0x7ff53945b240 created in file buf0buf.c line 916
a writer (thread id 140653677291264) has reserved it in mode exclusive
number of readers 0, waiters flag 1, lock_word: 0
Last time read locked in file row0sel.c line 3097
Last time write locked in file /usr/local/src/soft/mysql-5.5.24/storage/innobase/buf/buf0buf.c line 3151
这部分显示的是当前正在等待互斥量的innodb线程,在这里可以看到有两个线程正在等待,每一个都是以--Thread <数字> has waited...开始,这一段内容在正常情况下应该是空的(即查看的时候没有这部分内容),除非服务器运行着高并发的工作负载,促使innodb采取让操作系统等待的措施,除非你对innodb源码熟悉,否则这里看到的最有用的信息就是发生线程等待的代码文件名 /usr/local/src/soft/mysql-5.5.24/storage/innobase/buf/buf0buf.c line 3151。
在innodb内部哪里才是热点?举例来说,如果看到许多线程都在一个名为buf0buf.c的文件上等待,那就意味着你的系统里存在着
缓冲池竞争,这个输出信息还显示了这些线程等待了多少时间,其中waiters flag显示了有多少个等待着正在等待同一个互斥量。 如果waiters flag为0那就表示没有线程在等待同一个互斥量(此时在waiters flag 0后面可能可以看到wait is ending,表示这个互斥量已经被释放了,但操作系统还没有把线程调度过来运行)。
你可能想知道innodb真正等待的是什么,innodb使用了互斥量和信号量来保护代码的临界区,如:限定每次只能有一个线程进入临界区,或者是当有活动的读时,就限制写入等。在innodb代码里有很多临界区,在合适的条件下,它们都可能出现在那里,常常能见到的一种情形是:获取缓冲池分页的访问权的时候。
3.3.
在等待线程之后的部分信息如下,这部分显示了更多的事件计数器,在每一个情形中,都能看到innodb依靠操作系统等待的频度:
Mutex spin waits 1157217380, rounds 1783981614, OS waits 10610359 #这行显示的是跟互斥量相关的几个计数器
RW-shared spins 103830012, rounds 1982690277, OS waits 52051891 #这行显示读写的共享锁的计数器
RW-excl spins 43730722, rounds 602114981, OS waits 3495769 #这行显示读写的排他锁的计数器
Spin rounds per wait: 1.54 mutex, 19.10 RW-shared, 13.77 RW-excl
innodb有着一个多阶段等待的策略,首先,它会试着对锁进行空转等待,如果经历了一个预设的空转等待周期(设置innodb_sync_spin_loops配置变量命令)之后还没有成功,那就会退到更昂贵更复杂的等待数组中。
空转等待的成本相对较低,但是它们要不停地检查一个资源能否被锁定,这种方式会消耗CPU周期,但是,这没有听起来那么糟糕,因为当处理器在等待IO时,一般都有一些空闲的CPU周期可用,即使是没有空闲的CPU周期,空等也要比其他方式更加廉价一些。然而,当另外一个线程能做一些事情的时候,空转等待也还会把CPU独占着。
空转等待的替代方案就是让操作系统做上下文切换,这样,当一个线程在等待时,另外一个线程就可以被运行,然后,通过等待数组里的信号量发出信号,唤醒那个沉睡的线程,通过信号量来发送信号是比较有效的,但是上下文切换就很昂贵,这很快就会积少成多,每秒钟几千次的切换会引发大量的系统开销。
你可以通过修改innodb_sync_spin_loops的值,试着在空转等待与操作系统等待之间达成平衡,不要担心空转等待,除非你在一秒里看到几十万个空转等待。此时,你可以考虑performance_schema库或者show engine innodb mutex;查看下相关信息。
4.下面这一段外键错误的信息一般不会出现,除非你服务器上发生了外键错误,有时问题在于事务在插入,更新或删除一条记录时要寻找父表或子表,还有时候是当innodb尝试增加或删除一个外键或者修改一个已经存在的外键时,发现表之间类型不匹配,这部分输出对于调试与innodb不明确的外键错误发生的准确原因非常有帮助,下面搞一个示例来看看:
4.1 创建父表:
mysql> create table parent(parent_id int not null,primary key(parent_id)) engine=innodb;
4.2 创建子表:
mysql> create table child(child_id int not null,key child_id(child_id),constraint i_child foreign key(child_id) references parent(parent_id)) engine=innodb;
4.3 插入数据:
mysql> insert into parent(parent_id) values(1);
mysql> insert into child(child_id) values(1);
4.5 有两种基本的外键错误:
第一种:以某种可能违反外键约束关系的方法增加,更新,删除数据,将导致第一类错误,如,在父表中删除行时发生如下错误:
mysql> delete from parent;
ERROR 1451 (23000): Cannot delete or update a parent row: a foreign key constraint fails (`xiaoboluo`.`child`, CONSTRAINT `i_child` FOREIGN KEY (`child_id`) REFERENCES `parent` (`parent_id`))
错误信息相当明了,对所有由增加,删除,更新不匹配的行导致的错误都会看到相似的信息,下面是show engine innodb status的输出:
------------------------
LATEST FOREIGN KEY ERROR
------------------------
160128 1:17:06 Transaction: #这行显示了最近一次外键错误的日期和时间
TRANSACTION D203D6, ACTIVE 0 sec updating or deleting
mysql tables in use 1, locked 1
4 lock struct(s), heap size 1248, 2 row lock(s), undo log entries 1
MySQL thread id 20027, OS thread handle 0x7f0a4c0f8700, query id 1813996 localhost root updating
delete from parent
Foreign key constraint fails for table `xiaoboluo`.`child`:
, #上面部分显示了关于破坏外键约束的事务详情。后边部分显示了发现错误时innodb正尝试修改的准确数据,输出中有许多是转换成可打印格式的行数据。
CONSTRAINT `i_child` FOREIGN KEY (`child_id`) REFERENCES `parent` (`parent_id`)
Trying to delete or update in parent table, in index `PRIMARY` tuple:
DATA TUPLE: 3 fields;
0: len 4; hex 80000001; asc ;;
1: len 6; hex 000000d203d6; asc ;;
2: len 7; hex 1e000001ca0110; asc ;;
But in child table `xiaoboluo`.`child`, in index `child_id`, there is a record:
PHYSICAL RECORD: n_fields 2; compact format; info bits 0
0: len 4; hex 80000001; asc ;;
1: len 6; hex 000013a99b3e; asc >;;
4.6 第二种:尝试修改父表的表结构时发生的错误,这种错误就没有那么清楚了,这可能会让调试更困难:
mysql> alter table parent modify parent_id int unsigned not null;
ERROR 1025 (HY000): Error on rename of './xiaoboluo/#sql-b695_4e3b' to './xiaoboluo/parent' (errno: 150)
查看show engine innodb status输出信息:
------------------------
LATEST FOREIGN KEY ERROR
------------------------
160128 1:32:33 Error in foreign key constraint of table xiaoboluo/child:
there is no index in referenced table which would contain
the columns as the first columns, or the data types in the
referenced table do not match the ones in table. Constraint:
,
CONSTRAINT "i_child" FOREIGN KEY ("child_id") REFERENCES "parent" ("parent_id")
The index in the foreign key in table is "child_id"
See http://dev.mysql.com/doc/refman/5.5/en/innodb-foreign-key-constraints.html
for correct foreign key definition.
InnoDB: Renaming table `xiaoboluo`.<result 2 when explaining filename '#sql-b695_4e3b'> to `xiaoboluo`.`parent` failed!
上面的错误是数据类型不匹配,外键列必须有完全相同的数据类型,包括任何的修饰符(如这里父表多加了一个unsigned,这也是问题所在),当看到1025错误并不理解为什么时,最好查看下innodb status。在每次看到有新错误时,外键错误信息都会被重写,percona toolkit中的pt-fk-error-logger工具可以用表保存这些信息以供后续分析。
5.与外键错误一样,这部分只有当服务器产生死锁时才会出现,死锁信息同样在每次有新的死锁错误时被重写,percona toolkit中的pt-deadlock-logger工具可以用表保存这些信息以供后续分析
死锁在等待关系图里是一个循环,就是一个锁定了行的数据结构又在等待别的锁,这个循环可以任意地大,innodb会立即检测到死锁,因为每当有事务等待行锁的时候,它都会去检查等待关系图里是否有循环,死锁的情况可能会比较复杂,但是,这一部分只显示了最近的两个死锁的情况,它们在各自的事务里执行的最后一条语句,以及它们在等待关系图里形成环锁的信息。在这个循环里你看不到其他事务,也可能看不到在事务里早先真正获得了锁的语句,尽管如此,通常还是可以通过查看这些输出结果来确定到底是什么引起了死锁。
在innodb里实际上有两种死锁,第一种就是常常碰到的那种,它在等待关系图里是一个真正的循环,另外一种就是在一个等待关系图里,因代价昂贵而无法检测它是不是包含了循环,如果innodb要在关系图里检查超过100W个锁,或者在检查过程中,innodb要重做200个以上的事务,那它会放弃,并宣布这里有一个死锁,这些数值都是硬编码在innodb代码里的常量,无法配置(如果你NB可以修改代码然后重新编译)。第二种死锁报错你可以在输出里看到一条信息:TOO DEEP OR LONG SEARCH IN THE LOCK TABLE WAITS-FOR GRAPH
innodb不仅会打印出事务和事务持有和等待的锁,而且还有记录本身,不幸的是,它至于可能超过为输出结果预留的长度(只能打印1M的内容且只能保留最近一次的死锁信息),如果你无法看到完整的输出,此时可以在任意库下创建innodb_monitor或innodb_lock_monitor表,这样innodb status信息会完整且每15s一次被记录到错误日志中。如:create table innodb_monitor(a int)engine=innodb;,不需要记录到错误日志中时就删掉这个表即可。
5.1 下面也搞一个示例来看看:
5.1.1 建表:
mysql> create table test_deadlock(id int unsigned not null primary key auto_increment,test int unsigned not null);
Query OK, 0 rows affected (0.02 sec)
5.1.2 插入测试数据:
mysql> insert into test_deadlock(test) values(1),(2),(3),(4),(5);
Query OK, 5 rows affected (0.00 sec)
Records: 5 Duplicates: 0 Warnings: 0
打开两个会话终端:
5.1.3 会话1执行下面的SQL:
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from test_deadlock where id=1 for update;
+----+------+
| id | test |
+----+------+
| 1 | 1 |
+----+------+
1 row in set (0.00 sec)
5.1.4 接着会话2执行下面的SQL:
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from test_deadlock where id=2 for update;
+----+------+
| id | test |
+----+------+
| 2 | 2 |
+----+------+
1 row in set (0.00 sec)
5.1.5 回到会话1执行下面的SQL,会发生等待:
mysql> select * from test_deadlock where id=2 for update;
5.1.6 回到会话2执行下面的SQL,产生死锁,会话2被回滚:
mysql> select * from test_deadlock where id=1 for update;
ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction
5.2 查看innodb status信息:
------------------------
LATEST DETECTED DEADLOCK
------------------------
160128 1:51:53 #这里显示了最近一次发生死锁的日期和时间
*** (1) TRANSACTION:
TRANSACTION D20847, ACTIVE 141 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 3 lock struct(s), heap size 376, 2 row lock(s)
MySQL thread id 20027, OS thread handle 0x7f0a4c0f8700, query id 1818124 localhost root statistics
select * from test_deadlock where id=2 for update
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 441 page no 3 n bits 72 index `PRIMARY` of table `xiaoboluo`.`test_deadlock` trx id D20847 lock_mode X locks rec but not gap waiting
Record lock, heap no 3 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
0: len 4; hex 00000002; asc ;;
1: len 6; hex 000000d20808; asc ;;
2: len 7; hex ad000001ab011d; asc ;;
3: len 4; hex 00000002; asc ;;
*** (2) TRANSACTION:
TRANSACTION D20853, ACTIVE 119 sec starting index read
mysql tables in use 1, locked 1
3 lock struct(s), heap size 1248, 2 row lock(s)
MySQL thread id 20081, OS thread handle 0x7f0a0f020700, query id 1818204 localhost root statistics
select * from test_deadlock where id=1 for update
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 441 page no 3 n bits 72 index `PRIMARY` of table `xiaoboluo`.`test_deadlock` trx id D20853 lock_mode X locks rec but not gap
Record lock, heap no 3 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
0: len 4; hex 00000002; asc ;;
1: len 6; hex 000000d20808; asc ;;
2: len 7; hex ad000001ab011d; asc ;;
3: len 4; hex 00000002; asc ;;
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 441 page no 3 n bits 72 index `PRIMARY` of table `xiaoboluo`.`test_deadlock` trx id D20853 lock_mode X locks rec but not gap waiting
Record lock, heap no 2 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
0: len 4; hex 00000001; asc ;;
1: len 6; hex 000000d20808; asc ;;
2: len 7; hex ad000001ab0110; asc ;;
3: len 4; hex 00000001; asc ;;
*** WE ROLL BACK TRANSACTION (2)
这部分内容比较多,下面分段逐一进行解释:
5.2.1 下面这部分显示的是死锁的第一个事务的信息:
*** (1) TRANSACTION:
TRANSACTION D20847, ACTIVE 141 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 3 lock struct(s), heap size 376, 2 row lock(s)
MySQL thread id 20027, OS thread handle 0x7f0a4c0f8700, query id 1818124 localhost root statistics
select * from test_deadlock where id=2 for update
TRANSACTION D20847, ACTIVE 141 sec starting index read:这行表示事务D20847,ACTIVE 141 sec表示事务处于活跃状态141s,starting index read表示正在使用索引读取数据行
mysql tables in use 1, locked 1#这行表示事务D20847正在使用1个表,且涉及锁的表有1个
LOCK WAIT 3 lock struct(s), heap size 376, 2 row lock(s) #这行表示在等待3把锁,占用内存376字节,涉及2行记录,如果事务已经锁定了几行数据,这里将会有一行信息显示出锁定结构的数目(注意,这跟行锁是两回事)和堆大小,堆的大小指的是为了持有这些行锁而占用的内存大小,Innodb是用一种特殊的位图表来实现行锁的,从理论上讲,它可将每一个锁定的行表示为一个比特,经测试显示,每个锁通常不超过4比特
MySQL thread id 20027, OS thread handle 0x7f0a4c0f8700, query id 1818124 localhost root statistics #这行表示该事务的线程ID信息,操作系统句柄信息,连接来源、用户
select * from test_deadlock where id=2 for update #这行表示事务涉及的SQL
5.2.2 下面这一部分显示的是当死锁发生时,第一个事务正在等待的锁等信息:
*** (1) WAITING FOR THIS LOCK TO BE GRANTED: #这行信息表示第一个事务正在等待锁被授予
RECORD LOCKS space id 441 page no 3 n bits 72 index `PRIMARY` of table `xiaoboluo`.`test_deadlock` trx id D20847 lock_mode X locks rec but not gap waiting
Record lock, heap no 3 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
0: len 4; hex 00000002; asc ;;
1: len 6; hex 000000d20808; asc ;;
2: len 7; hex ad000001ab011d; asc ;;
3: len 4; hex 00000002; asc ;;
RECORD LOCKS space id 441 page no 3 n bits 72 index `PRIMARY` of table `xiaoboluo`.`test_deadlock` trx id D20847 lock_mode X locks rec but not gap waiting#这行信息表示等待的锁是一个record lock,空间id是441,页编号为3,大概位置在页的72位处,锁发生在表xiaoboluo.test_deadlock的主键上,是一个X锁,但是不是gap lock。 waiting表示正在等待锁
Record lock, heap no 3 PHYSICAL RECORD: n_fields 4; compact format; info bits 0 #这行表示record lock的heap no 位置
#这部分剩下的内容只对调试才有用。
0: len 4; hex 00000002; asc ;;
1: len 6; hex 000000d20808; asc ;;
2: len 7; hex ad000001ab011d; asc ;;
3: len 4; hex 00000002; asc ;;
5.2.3 下面这部分是事务二的状态:
*** (2) TRANSACTION:
TRANSACTION D20853, ACTIVE 119 sec starting index read #事务2处于活跃状态119s
mysql tables in use 1, locked 1 #正在使用1个表,涉及锁的表有1个
3 lock struct(s), heap size 1248, 2 row lock(s) #涉及3把锁,2行记录
MySQL thread id 20081, OS thread handle 0x7f0a0f020700, query id 1818204 localhost root statistics
select * from test_deadlock where id=1 for update #第二个事务的SQL
5.2.4 下面这部分是事务二的持有锁信息:
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 441 page no 3 n bits 72 index `PRIMARY` of table `xiaoboluo`.`test_deadlock` trx id D20853 lock_mode X locks rec but not gap
Record lock, heap no 3 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
0: len 4; hex 00000002; asc ;;
1: len 6; hex 000000d20808; asc ;;
2: len 7; hex ad000001ab011d; asc ;;
3: len 4; hex 00000002; asc ;;
RECORD LOCKS space id 441 page no 3 n bits 72 index `PRIMARY` of table `xiaoboluo`.`test_deadlock` trx id D20853 lock_mode X locks rec but not gap
Record lock, heap no 3 PHYSICAL RECORD: n_fields 4; compact format; info bits 0 #从这两行持有锁信息计息后面几行调试信息上看,就是事务1正在等待的锁。
5.2.5 下面这部分是事务二正在等待的锁,从下面的信息上看,等待的是同一个表,同一个索引,同一个page上的record lock X锁,但是heap no位置不同,即不同的行上的锁:
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 441 page no 3 n bits 72 index `PRIMARY` of table `xiaoboluo`.`test_deadlock` trx id D20853 lock_mode X locks rec but not gap waiting
Record lock, heap no 2 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
0: len 4; hex 00000001; asc ;;
1: len 6; hex 000000d20808; asc ;;
2: len 7; hex ad000001ab0110; asc ;;
3: len 4; hex 00000001; asc ;;
*** WE ROLL BACK TRANSACTION (2) #这个表示事务2被回滚,因为两个事务的回滚开销一样,所以选择了后提交的事务进行回滚,如果两个事务回滚的开销不同(undo 数量不同),那么就回滚开销最小的那个事务。
当一个事务持有了其他事务需要的锁,同时又想获得其他事务持有的锁时,等待关系图上就会产生循环,Innodb不会显示所有持有和等待的锁,但是,它显示了足够的信息来帮你确定,查询操作正在使用哪些索引,这对于你确定能否避免死锁有极大的价值。
如果能使两个查询对同一个索引朝同一个方向进行扫描,就能降低死锁的数目,因为,查询在同一个顺序上请求锁的时候不会创建循环,有时候,这是很容易做到的,如:要在一个事务里更新许多条记录,就可以在应用程序的内存里把它们按照主键进行排序,然后,再用同样的顺序更新到数据库里,这样就不会有死锁发生,但是在另一些时候,这个方法也是行不通的(如果有两个进程使用了不同的索引区间操作同一张表的时候)。
6. 下面这部分包含了一些关于innodb事务的总结信息,紧随其后的是当前活跃事务列表,如:
------------
TRANSACTIONS
------------
Trx id counter 4E0132AD
Purge done for trx's n:o < 4E01090B undo n:o < 0
History list length 1853
LIST OF TRANSACTIONS FOR EACH SESSION:
---TRANSACTION 4E0131D3, not started
MySQL thread id 26208218, OS thread handle 0x7fec7c582700, query id 5274800318 10.207.162.69 gdsser
---TRANSACTION 4E01323F, not started
MySQL thread id 26208217, OS thread handle 0x7fec7c1b3700, query id 5274800938 10.207.162.69 gdsser
....................
---TRANSACTION 4E0132AC, ACTIVE 0 sec preparing
2 lock struct(s), heap size 376, 1 row lock(s), undo log entries 1
MySQL thread id 26208200, OS thread handle 0x7fec567e0700, query id 5274801557 10.207.162.69 gdsser
commit
---TRANSACTION 4E0110E7, ACTIVE 188 sec
mysql tables in use 1, locked 0
MySQL thread id 26208154, OS thread handle 0x7fec7c235700, query id 5274800671 10.143.90.228 root Sending data
SELECT /*!40001 SQL_NO_CACHE */ * FROM `m_flowskillpoint`
Trx read view will not see trx with id >= 4E0110E8, sees < 4E0108EE
---TRANSACTION 4E0108EF, ACTIVE 233 sec fetching rows
mysql tables in use 1, locked 0
MySQL thread id 26208131, OS thread handle 0x7fec578e3700, query id 5274801341 10.143.90.228 root Sending data
SELECT /*!40001 SQL_NO_CACHE */ * FROM `m_flowsilver`
Trx read view will not see trx with id >= 4E0108F0, sees < 4E0108EC
---TRANSACTION 4E0108EE, ACTIVE 233 sec fetching rows
mysql tables in use 1, locked 0
MySQL thread id 26208132, OS thread handle 0x7fec7c78a700, query id 5274797797 10.143.90.228 root Sending data
SELECT /*!40001 SQL_NO_CACHE */ * FROM `m_flowmail`
Trx read view will not see trx with id >= 4E0108EF, sees < 4E0108EC
这部分内容比较多,下面分段逐一进行解释:
6.1.
Trx id counter 4E0132AD #这行表示当前事务ID,这是一个系统变量,每创建一个新事务都会增加
Purge done for trx's n:o < 4E01090B undo n:o < 0 #这是innodb清除旧MVCC行时所用的事务ID,将这个值和当前事务ID进行比较,就可以知道有多少老版本的数据未被清除。这个数字多大才可以安全的取值没有硬性和速成的规定,如果数据没做过任何更新,那么一个巨大的数字也不意味着有未清除的数据,因为实际上所有事务在数据库里查看的都是同一个版本的数据(此时只是事务ID在增加,而数据没有变更),另一方面,如果有很多行被更新,那每一行就会有一个或多个版本留在内存里,减少此类开销的最好办法就是确保事务已完成就立即提交,不要让它长时间地处于打开状态,因为一个打开的事务即使不做任何操作,也会影响到innodb清理旧版本的行数据。 undo n:o < 0这个是innodb清理进程正在使用的撤销日志编号,为0 0时说明清理进程处于空闲状态。
History list length 1853 #历史记录的长度,即位于innodb数据文件的撤销空间里的页面的数目,如果事务执行了更新并提交,这个数字就会增加,而当清理进程移除旧版本数据时,它就会减少,清理进程也会更新Purge done for.....这行中的数值。
6.2.
头部信息之后就是一个事务列表,当前版本的mysql还不支持嵌套事务,因此,在某个时间点上,每个客户端连接能够拥有的事务数量是有一个上限的,而且每一个事务只能属于单一连接(即一个事务只能使用单个线程执行,不能使用多个线程)。在输出信息里,每一个事务至少占有两行内容,如:
---TRANSACTION 4E0131D3, not started #每个事务的第一行以事务的ID和状态开始,not started表示这个事务已经提交并且没有再发起影响事务的语句,可能刚好空闲
MySQL thread id 26208218, OS thread handle 0x7fec7c582700, query id 5274800318 10.207.162.69 gdsser#然后每个事务的第二行是一些线程等信息,MySQL thread id <数字>部分和是hi用show full processlist;命令看到的id列相同。紧随其后的是一个内部查询id和一些连接信息,这些信息同样与show full processlist中的输出相同。
---TRANSACTION 4E01323F, not started
MySQL thread id 26208217, OS thread handle 0x7fec7c1b3700, query id 5274800938 10.207.162.69 gdsser
6.3.
上面是not started状态的事务信息,下面来看看为ACTIVE状态的事务信息:
---TRANSACTION 4E0110E7, ACTIVE 188 sec #这行显示次事务处于活跃状态已经188s,可能的所有状态有not started,active,prepared和committed in memory,一旦事务日志落盘了就会变成not started状态。在时间后面会显示出当前事务正在做什么(在这里为空没有显示出来),在源代码中有超过30个字符串常量可以显示在时间后面,如:fetching,preparing,rows,adding foreign keys等等
mysql tables in use 1, locked 0 #该事务用到的表数和涉及表锁的表数,Innodb一般不会锁定表,但对有些语句会锁定,如果mysql服务器在高于innodb层之上将表锁定,这里也是能够显示出来的,如果事务已经锁定了几行数据,这里将会有一行信息显示出锁定结构的数目(注意,这跟行锁是两回事)和和堆大小,如:2 lock struct(s), heap size 376, 1 row lock(s), undo log entries 1,堆的大小指的是为了持有这些行锁而占用的内存大小,Innodb是用一种特殊的位图表来实现行锁的,从理论上讲,它可将每一个锁定的行表示为一个比特,经测试显示,每个锁通常不超过4比特。
MySQL thread id 26208154, OS thread handle 0x7fec7c235700, query id 5274800671 10.143.90.228 root Sending data #与show processlist输出结果大部分相同
SELECT /*!40001 SQL_NO_CACHE */ * FROM `m_flowskillpoint` #如果事务正在运行一个查询,那么这里就会显示事务涉及的SQL,注意:有些版本可能只显示其中一小段,而不是完整的SQL
Trx read view will not see trx with id >= 4E0110E8, sees < 4E0108EE #这行显示了事务的读视图,它表明了因为版本关系而产生的对于事务可见和不可见两种类型的事务ID的范围,在这里,两个数字之间有一个事务的间隙,这个间隙里的事务可能是不可见的,innodb在执行查询时,对于那些事务ID正好在这个间隙的行,还会检查其可见性。
注:如果事务正在等待一个锁,那么在查询SQL文本后面将可以看到这个锁的信息,在上文的死锁例子里,这样的信息看到过很多了,不幸的是,输出信息并没有说出这个锁正被其他哪个事务持有,不过可以通过information_schema库下的innodb_trx,innodb_lock_waits,innodb_locks三个表来查明这一点。如果输出信息里有很多个事务,innodb可能会限制要打印出来的事务数目,以免输出信息增长得太大,这时就会看到...truncated...提示。
7.FILE I/O部分显示的是I/O辅助线程的状态,还有性能计数器的状态,如下:
--------
FILE I/O
--------
I/O thread 0 state: waiting for i/o request (insert buffer thread) #insert buffer thread
I/O thread 1 state: waiting for i/o request (log thread) #log thread
I/O thread 2 state: waiting for i/o request (read thread)
I/O thread 3 state: waiting for i/o request (read thread)
I/O thread 4 state: waiting for i/o request (read thread)
I/O thread 5 state: doing file i/o (read thread) ev set #以上为默认的4个read thread
I/O thread 6 state: waiting for i/o request (write thread)
I/O thread 7 state: waiting for i/o request (write thread)
I/O thread 8 state: waiting for i/o request (write thread)
I/O thread 9 state: waiting for i/o request (write thread) #以上为默认的4个write thread
Pending normal aio reads: 128 [0, 0, 0, 128] , aio writes: 0 [0, 0, 0, 0] , #读线程和写线程挂起操作的数目等,aio的意思是异步I/O
ibuf aio reads: 0, log i/o's: 0, sync i/o's: 0 #insert buffer thread挂起的fsync()操作数目等
Pending flushes (fsync) log: 0; buffer pool: 0 #log thread挂起的fsync()操作数目等
146246831 OS file reads, 760501349 OS file writes, 247143684 OS fsyncs #这行显示了读,写和fsync()调用执行的数目,在你的机器环境负载下这些绝对值可能会有所不同,因此更重要的是监控它们过去一段时间内是如何改变的。
1 pending preads, 0 pending pwrites #这行显示了当前被挂起的读和写操作数
145.49 reads/s, 783677 avg bytes/read, 28.75 writes/s, 10.67 fsyncs/s #这行显示了在头部显示的时间(指的是第1部分的时间)段内的每秒平均值。
注:三行挂起读写线程、缓冲池线程、日志线程的统计信息的值是检测I/O受限的应用的一个好方法,如果这些I/O大部分有挂起操作,那么负载可能I/O受限。在linux系统下使用参数:innodb_read_io_threads和innodb_write_io_threads两个变量来配置读写线程的数量,默认为各4个线程。
insert buffer thread:负责插入缓冲合并,如:记录被从插入缓冲合并到表空间中
log thread:负责异步刷事务日志
read thread:执行预读操作以尝试预先读取innodb预感需要的数据
write thread:刷新脏页缓冲
8.这部分显示了insert buffer和adaptive hash index两个部分的结构的状态
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 12, free list len 27559, seg size 27572, 18074934 merges #这行显示了关于size(size 12代表了已经合并记录页的数量)、free list(代表了插入缓冲中空闲列表长度)和seg size大小(seg size 27572显示了当前insert buffer的长度,大小为27572*16K=440M左右)的信息。18074934 merges代表合并插入的次数
merged operations: #这个标签下的一行信息insert,delete mark,delete分别表示merge操作合并了多少个insert buffer,delete buffer,purge buffer
insert 81340470, delete mark 8893610, delete 818579
discarded operations: #这个标签下的一行信息表示当change buffer发生merge时表已经被删除了,就不需要再将记录合并到辅助索引中了
insert 0, delete mark 0, delete 0
Hash table size 87709057, node heap has 10228 buffer(s) #这行显示了自使用哈希索引的状态,其中,Hash table size 87709057表示AHI的大小,node heap has 10228 buffer(s)表示AHI的使用情况
1741.05 hash searches/s, 539.48 non-hash searches/s #这行显示了在头部第1部分提及的时间内Innodb每秒完成了多少哈希索引操作,1741.05 hash searches/s表示每秒使用AHI搜索的情况,539.48 non-hash searches/s表示每秒没有使用AHI搜索的情况(因为哈希索引只能用于等值查询,而范围查询,模糊查询是不能使用哈希索引的。),通过hash searches: non-hash searches的比例大概可以了解使用哈希索引后的效率,哈希索引查找与非哈希索引查找的比例仅供参考,自适应哈希索引无法配置,但是可以通过innodb_adaptive_hash_index=ON|OFF参数来选择是否需要这个特性。
注:
innodb从1.0.x开始引入change buffer,可以视为insert buffer的升级,从这个版本开始,innodb可以对DML操作(insert,delete,update)都进行缓冲,他们分别是insert buffer,delete buffer,purge buffer,当然和之前insert buffer一样,change buffer适用对象仍然是非唯一索引的辅助索引,因为没有update buffer,所以对一条记录进行update的操作可以分为两个过程:
A:将记录标记为删除
B:真正将记录删除
因此,delete buffer对应update 操作的第一个过程,即将记录标记为删除,purge buffer对应update的第二个过程,即将记录真正地删除
9.这部分显示了关于innodb事务日志(重做日志)子系统的统计:
---
LOG
---
Log sequence number 1351392990515 #这行显示了当前最新数据产生的日志序列号
Log flushed up to 1351392989504 #这行显示了日志已经刷新到哪个位置了(已经落盘到事务日志中的日志序列号)
Last checkpoint at 1351373900020 #这行显示了上一次检查点的位置(一个检查点表示一个数据和日志文件都处于一致状态的时刻,并且能用于恢复数据),如果上一次检查点落后与上一行太多,并且差异接近于事务日志文件的大小,Innodb会触发“疯狂刷”,这对性能而言非常糟糕。
0 pending log writes, 0 pending chkp writes #这行显示了当前挂起的日志读写操作,可以将这行的值与第7部分FILE I/O对应的值做比较,以了解你的I/O有多少是由于日志系统引起的。
286879989 log i/o's done, 15.92 log i/o's/second #这行显示了日志操作的统计和每秒日志I/O数,可以将这行的值与第7部分FILE I/O对应的值做比较,以了解你的I/O有多少是由于日志系统引起的。
9.这部分显示了关于innodb缓冲池及其如何使用内存的统计:
9.1.
----------------------
BUFFER POOL AND MEMORY
----------------------
Total memory allocated 45357793280; in additional pool allocated 0 #这行显示了由innodb分配的总内存,以及其中多少是额外内存池分配,额外内存池仅分配了其中很小一部分内存,由内部内存分配器分配,现在的innodb版本一般使用操作系统的内存分配器,但老版本使用自己的,这是由于在那个时代有些操作系统并未提供一个非常好的内存分配实现。
Dictionary memory allocated 12681573
Buffer pool size 2705015 #从这行开始的下面4行显示缓冲池度量值,以页为单位,度量值有总的缓冲池大小,空闲页数,分配用来存储数据库页的页数,以及脏数据库页数。这行显示了缓冲池总共有多少个页,即即2705015*16K,共有43G的缓冲池
Free buffers 5 #这行显示了缓冲池空闲页数
Database pages 2694782 #这行显示了分配用来存储数据库页的页数,即,表示LRU列表中页的数量,包含young sublist和old sublist
Old database pages 994651 #这行显示了LRU中的old sublist部分页的数量
Modified db pages 10610 #这行显示脏数据库页数
Pending reads 128 #这行显示了挂起读的数量
Pending writes: LRU 0, flush list 0, single page 0 #这行显示了挂起写的数量
#注意,这里挂起的读和写操作并不与FILE I/O部分的值匹配,因为Innodb可能合并许多的逻辑读写操作到一个物理I/O操作中,LRU代表最近使用到的被挂起数量,它是通过冲刷缓冲中不经常使用的页来释放空间以供给经常使用的页的一种方法,冲刷列表flush list存放着检查点处理需要冲刷的旧页被挂起的数量,单页single page被挂起的数量(single page写是独立的页面写,不会被合并)。
Pages made young 3014373561, not young 0 #这行显示了LRU列表中页移动到LRU首部的次数,因为该服务器在运行阶段改变没有达到innodb_old_blocks_time阀值的值,因此not young为0
6960.42 youngs/s, 0.00 non-youngs/s #表示每秒young和non-youngs这两类操作的次数
Pages read 2946570833, created 43450158, written 574214278 #这行显示了innodb被读取,创建,写入了多少页,读/写页的值是指的从磁盘读到缓冲池的数据,或者从缓冲池写到磁盘中的数据,创建页指的是innodb在缓冲池中分配但没有从数据文件中读取内容的页,因为它并不关心内容是什么(如,它们可能属于一个已经被删除的表)
6960.54 reads/s, 4.42 creates/s, 9.33 writes/s #这行显示了对应上面一行的每秒read,create,write的页数
Buffer pool hit rate 955 / 1000, young-making rate 45 / 1000 not 0 / 1000 #这行显示了缓冲池的命中率,它用来衡量innodb在缓冲池中查找到所需页的比例,它度量自上次Innodb状态输出后到本次输出这段时间内的命中率,因此,如果服务器自那以后一直很安静,你将会看到No buffer pool page gets since the last printout。它对于度量缓存池的大小并没有用处。
Pages read ahead 6928.54/s, evicted without access 8.21/s, Random read ahead 0.00/s #这行显示了页面预读,随机预读的每秒页数
LRU len: 2694782, unzip_LRU len: 0 #innodb1.0.x开始支持压缩页的功能,将原来16K的页压缩为1K,2K,4K,8K,而由于页的大小发生了变化,LRU列表也有了些改变,对于非16K的页,是通过unzip_LRU列表进行管理的,可以看到unzip_LRU len为0表示没有使用压缩页.
I/O sum[60790]:cur[30], unzip sum[0]:cur[0]
对于压缩页的表,每个表的压缩比例可能不同,可能存在有的表页大小为8K,有的表页大小为2K的情况,unzip_LRUs 怎样从缓存池中分配内存的呢?
首先,在unzip_LRU列表中对不同压缩页大小的页进行分别管理,其次,通过伙伴算法进行内存的分配,例如:需要从缓存池中申请页为4K的大小,其过程如下:
a:检查4K的unzip_LRU列表,检查是否有可用的空闲页
b:若有,则直接使用
c:若没有,检查8K的unzip_LRU列表
d:若能够得到空闲页,将页分成2个4K的页,存放到4K的unzip_LRU列表
e:若不能得到空闲页,从LRU列表中申请一个16K的页,将页分成1个8K,2个4K的页,分别存放到各自大小对应的unzip_LRU列表中。
注:可能出现Free buffers和Database pages之和不等于Buffer pool size,因为缓冲池中的页肯会被分配给自适应哈希索引,lock信息,insert buffer等,而这部分页不需要LRU算法进行维护,因此不在LRU列表中。
9.2.如果innodb buffer pool使用参数innodb
_buffer_pool_instances=num设置了大于1个缓冲池实例,那么就会按照这个参数把innodb_buffer_pool_size=xxx平分为num份。每份的信息显示类似如下,这部分的内容和9.1小节内容类似,就不再多说。
----------------------
INDIVIDUAL BUFFER POOL INFO
----------------------
---BUFFER POOL 0
Buffer pool size 541003
Free buffers 1
Database pages 538965
Old database pages 198933
Modified db pages 2190
Pending reads 128
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 603372180, not young 0
1441.81 youngs/s, 0.00 non-youngs/s
Pages read 589705199, created 8703138, written 116954697
1441.61 reads/s, 0.75 creates/s, 1.83 writes/s
Buffer pool hit rate 955 / 1000, young-making rate 45 / 1000 not 0 / 1000
Pages read ahead 1436.98/s, evicted without access 0.87/s, Random read ahead 0.00/s
LRU len: 538965, unzip_LRU len: 0
I/O sum[12158]:cur[6], unzip sum[0]:cur[0]
---BUFFER POOL 1
Buffer pool size 541003
Free buffers 1
Database pages 538959
Old database pages 198931
Modified db pages 2025
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 602366394, not young 0
1481.35 youngs/s, 0.00 non-youngs/s
Pages read 588738997, created 8708171, written 113209540
1480.56 reads/s, 0.83 creates/s, 1.92 writes/s
Buffer pool hit rate 958 / 1000, young-making rate 42 / 1000 not 0 / 1000
Pages read ahead 1473.73/s, evicted without access 1.96/s, Random read ahead 0.00/s
LRU len: 538959, unzip_LRU len: 0
I/O sum[12158]:cur[6], unzip sum[0]:cur[0]
10.这部分显示了其他各项的innodb统计:
--------------
ROW OPERATIONS
--------------
0 queries inside InnoDB, 0 queries in queue #这行显示了innodb内核内有多少个线程,队列中有多少个线程,队列中的查询是innodb为限制并发执行的线程数量而不运行进入内核的线程。查询在进入队列之前会休眠等待。
5 read views open inside InnoDB #这行显示了有多少打开的innodb读视图,读视图是包含事务开始点的数据库内容的MVCC快照,你可以看看某特定事务在第6部分TRANSACTIONS是否有读视图
Main thread process no. 4368, id 140653691242240, state: sleeping #这行显示了内核的主线程状态
Number of rows inserted 3429012215, updated 153529675, deleted 112310240, read 3739562987410 #这行显示了多少行被插入,更新和删除,读取
428.52 inserts/s, 7.21 updates/s, 0.46 deletes/s, 1047933.92 reads/s #这行显示了对应上面一行的每秒平均值,如果想查看innodb有多少工作量在进行,那么这两行是很好的参考值
----------------------------
END OF INNODB MONITOR OUTPUT #要注意了,如果看不到这行输出,可能是有大量事务或者是有一个大的死锁截断了输出信息
============================
注:内核的主线程状态可能的状态值有如下一些:
A:doing background drop tables
B:doing insert buffer merge
C:flushing buffer pool pages
D:making checkpoint
E:purging
F:reserving kernel mutex
G:sleeping
H:suspending
I:waiting for buffer pool flush to end
J:waiting for server activity
注:以下内容为根据《高性能mysql第三版》和《mysql技术内幕innodb存储引擎》的innodb status部分的个人理解,如果有错误,还望指正!!
innodb存储引擎在show engine innodb status(老版本对应的是show innodb status)输出中,显示除了大量的内部信息,它输出就是一个单独的字符串,没有行和列,内容分为很多小段,每一段对应innodb存储引擎不同部分的信息,其中有一些信息对于innodb开发者来说非常有用,但是,许多信息,如果你尝试去理解,并且应用到高性能innodb调优的时候,你会发现它们非常有趣,甚至是非常有必要的。
输出内容中包含了一些平均值的统计信息,这些平均值是自上次输出结果生成以来的统计数,因此,如果你正在检查这些值,那就要确保已经等待了至少30s的时间,使两次采样之间的积累足够长的统计时间并多次采样,检查计数器变化从而弄清其行为,并不是所有的输出都会在一个时间点上生成,因而也不是所有的显示出来的平均值会在同一时间间隔里重新再计算。而且,innodb有一个内部复位间隔,而它是不可预知的,各个版本也不一样。
这些输出信息足够提供给手工计算出大多数你想要的统计信息,有一款监控工具innotop可以帮你计算出增量差值和平均值。下面,在你的mysql命令行敲下show engine innodb status;看着输出跟着下面的步骤一步一步理解输出信息是什么含义:
注意:以下使用mysql5.5.24版本做解读,mysql5.6.x和5.7.x输出内容有些地方有调整。
1.第一段是头部信息,它仅仅声明了输出的开始,其内容包括当前的日期和时间,以及自上次输出以来经过的时长。
=====================================
160129 12:07:26 INNODB MONITOR OUTPUT #第二行是当前日期和时间
=====================================
Per second averages calculated from the last 24 seconds #第四行显示的是计算出这一平均值的时间间隔,即自上次输出以来的时间,或者是距上次内部复位的时长
2.从innodb1.0.x开始,可以使用命令show engine innodb status;来查看master thread的状态信息:
-----------------
BACKGROUND THREAD
-----------------
srv_master_thread loops: 30977173 1_second, 30975685 sleeps, 3090359 10_second, 166112 background, 165988 flush #这行显示主循环进行了30977173 1_second次,每秒挂起的操作进行了30975685 sleeps次(说明负载不是很大),10秒一次的活动进行了3090359 10_second次,1秒循环和10秒循环比值符合1:10,backgroup loop进行了166112 background次,flush loop进行了165988 flush次,如果在一台很大压力的mysql上,可能看到每秒运行次数和挂起次数比例小于1很多,这是因为innodb对内部进行了一些优化,当压力大时间隔时间并不总是等待1秒,因此,不能认为每秒循环和挂起的值总是相等,在某些情况下,可以通过两者之间的差值来比较反映当前数据库的负载压力。
srv_master_thread log flush and writes: 31160103
3.如果有高并发的工作负载,你就要关注下接下来的段(SEMAPHORES信号量),它包含了两种数据:事件计数器以及可选的当前等待线程的列表,如果有性能上的瓶颈,可以使用这些信息来找出瓶颈,不幸的是,想知道怎么使用这些信息还是有一点复杂,下面先给出一些解释:
----------
SEMAPHORES
----------
OS WAIT ARRAY INFO: reservation count 68581015, signal count 218437328
--Thread 140653057947392 has waited at btr0pcur.c line 437 for 0.00 seconds the semaphore:
S-lock on RW-latch at 0x7ff536c7d3c0 created in file buf0buf.c line 916
a writer (thread id 140653057947392) has reserved it in mode exclusive
number of readers 0, waiters flag 1, lock_word: 0
Last time read locked in file row0sel.c line 3097
Last time write locked in file /usr/local/src/soft/mysql-5.5.24/storage/innobase/buf/buf0buf.c line 3151
--Thread 140653677291264 has waited at btr0pcur.c line 437 for 0.00 seconds the semaphore:
S-lock on RW-latch at 0x7ff53945b240 created in file buf0buf.c line 916
a writer (thread id 140653677291264) has reserved it in mode exclusive
number of readers 0, waiters flag 1, lock_word: 0
Last time read locked in file row0sel.c line 3097
Last time write locked in file /usr/local/src/soft/mysql-5.5.24/storage/innobase/buf/buf0buf.c line 3151
Mutex spin waits 1157217380, rounds 1783981614, OS waits 10610359
RW-shared spins 103830012, rounds 1982690277, OS waits 52051891
RW-excl spins 43730722, rounds 602114981, OS waits 3495769
Spin rounds per wait: 1.54 mutex, 19.10 RW-shared, 13.77 RW-excl
内容比较多,下面分段依次解释:
3.1.
OS WAIT ARRAY INFO: reservation count 68581015, signal count 218437328 #这行给出了关于操作系统等待数组的信息,它是一个插槽数组,innodb在数组里为信号量保留了一些插槽,操作系统用这些信号量给线程发送信号,使线程可以继续运行,以完成它们等着做的事情,这一行还显示出innodb使用了多少次操作系统的等待:保留统计(reservation count)显示了innodb分配插槽的频度,而信号计数(signal count)衡量的是线程通过数组得到信号的频度,操作系统的等待相对于空转等待(spin wait)要昂贵些。
3.2.
--Thread 140653057947392 has waited at btr0pcur.c line 437 for 0.00 seconds the semaphore:
S-lock on RW-latch at 0x7ff536c7d3c0 created in file buf0buf.c line 916
a writer (thread id 140653057947392) has reserved it in mode exclusive
number of readers 0, waiters flag 1, lock_word: 0
Last time read locked in file row0sel.c line 3097
Last time write locked in file /usr/local/src/soft/mysql-5.5.24/storage/innobase/buf/buf0buf.c line 3151
--Thread 140653677291264 has waited at btr0pcur.c line 437 for 0.00 seconds the semaphore:
S-lock on RW-latch at 0x7ff53945b240 created in file buf0buf.c line 916
a writer (thread id 140653677291264) has reserved it in mode exclusive
number of readers 0, waiters flag 1, lock_word: 0
Last time read locked in file row0sel.c line 3097
Last time write locked in file /usr/local/src/soft/mysql-5.5.24/storage/innobase/buf/buf0buf.c line 3151
这部分显示的是当前正在等待互斥量的innodb线程,在这里可以看到有两个线程正在等待,每一个都是以--Thread <数字> has waited...开始,这一段内容在正常情况下应该是空的(即查看的时候没有这部分内容),除非服务器运行着高并发的工作负载,促使innodb采取让操作系统等待的措施,除非你对innodb源码熟悉,否则这里看到的最有用的信息就是发生线程等待的代码文件名 /usr/local/src/soft/mysql-5.5.24/storage/innobase/buf/buf0buf.c line 3151。
在innodb内部哪里才是热点?举例来说,如果看到许多线程都在一个名为buf0buf.c的文件上等待,那就意味着你的系统里存在着
缓冲池竞争,这个输出信息还显示了这些线程等待了多少时间,其中waiters flag显示了有多少个等待着正在等待同一个互斥量。 如果waiters flag为0那就表示没有线程在等待同一个互斥量(此时在waiters flag 0后面可能可以看到wait is ending,表示这个互斥量已经被释放了,但操作系统还没有把线程调度过来运行)。
你可能想知道innodb真正等待的是什么,innodb使用了互斥量和信号量来保护代码的临界区,如:限定每次只能有一个线程进入临界区,或者是当有活动的读时,就限制写入等。在innodb代码里有很多临界区,在合适的条件下,它们都可能出现在那里,常常能见到的一种情形是:获取缓冲池分页的访问权的时候。
3.3.
在等待线程之后的部分信息如下,这部分显示了更多的事件计数器,在每一个情形中,都能看到innodb依靠操作系统等待的频度:
Mutex spin waits 1157217380, rounds 1783981614, OS waits 10610359 #这行显示的是跟互斥量相关的几个计数器
RW-shared spins 103830012, rounds 1982690277, OS waits 52051891 #这行显示读写的共享锁的计数器
RW-excl spins 43730722, rounds 602114981, OS waits 3495769 #这行显示读写的排他锁的计数器
Spin rounds per wait: 1.54 mutex, 19.10 RW-shared, 13.77 RW-excl
innodb有着一个多阶段等待的策略,首先,它会试着对锁进行空转等待,如果经历了一个预设的空转等待周期(设置innodb_sync_spin_loops配置变量命令)之后还没有成功,那就会退到更昂贵更复杂的等待数组中。
空转等待的成本相对较低,但是它们要不停地检查一个资源能否被锁定,这种方式会消耗CPU周期,但是,这没有听起来那么糟糕,因为当处理器在等待IO时,一般都有一些空闲的CPU周期可用,即使是没有空闲的CPU周期,空等也要比其他方式更加廉价一些。然而,当另外一个线程能做一些事情的时候,空转等待也还会把CPU独占着。
空转等待的替代方案就是让操作系统做上下文切换,这样,当一个线程在等待时,另外一个线程就可以被运行,然后,通过等待数组里的信号量发出信号,唤醒那个沉睡的线程,通过信号量来发送信号是比较有效的,但是上下文切换就很昂贵,这很快就会积少成多,每秒钟几千次的切换会引发大量的系统开销。
你可以通过修改innodb_sync_spin_loops的值,试着在空转等待与操作系统等待之间达成平衡,不要担心空转等待,除非你在一秒里看到几十万个空转等待。此时,你可以考虑performance_schema库或者show engine innodb mutex;查看下相关信息。
4.下面这一段外键错误的信息一般不会出现,除非你服务器上发生了外键错误,有时问题在于事务在插入,更新或删除一条记录时要寻找父表或子表,还有时候是当innodb尝试增加或删除一个外键或者修改一个已经存在的外键时,发现表之间类型不匹配,这部分输出对于调试与innodb不明确的外键错误发生的准确原因非常有帮助,下面搞一个示例来看看:
4.1 创建父表:
mysql> create table parent(parent_id int not null,primary key(parent_id)) engine=innodb;
4.2 创建子表:
mysql> create table child(child_id int not null,key child_id(child_id),constraint i_child foreign key(child_id) references parent(parent_id)) engine=innodb;
4.3 插入数据:
mysql> insert into parent(parent_id) values(1);
mysql> insert into child(child_id) values(1);
4.5 有两种基本的外键错误:
第一种:以某种可能违反外键约束关系的方法增加,更新,删除数据,将导致第一类错误,如,在父表中删除行时发生如下错误:
mysql> delete from parent;
ERROR 1451 (23000): Cannot delete or update a parent row: a foreign key constraint fails (`xiaoboluo`.`child`, CONSTRAINT `i_child` FOREIGN KEY (`child_id`) REFERENCES `parent` (`parent_id`))
错误信息相当明了,对所有由增加,删除,更新不匹配的行导致的错误都会看到相似的信息,下面是show engine innodb status的输出:
------------------------
LATEST FOREIGN KEY ERROR
------------------------
160128 1:17:06 Transaction: #这行显示了最近一次外键错误的日期和时间
TRANSACTION D203D6, ACTIVE 0 sec updating or deleting
mysql tables in use 1, locked 1
4 lock struct(s), heap size 1248, 2 row lock(s), undo log entries 1
MySQL thread id 20027, OS thread handle 0x7f0a4c0f8700, query id 1813996 localhost root updating
delete from parent
Foreign key constraint fails for table `xiaoboluo`.`child`:
, #上面部分显示了关于破坏外键约束的事务详情。后边部分显示了发现错误时innodb正尝试修改的准确数据,输出中有许多是转换成可打印格式的行数据。
CONSTRAINT `i_child` FOREIGN KEY (`child_id`) REFERENCES `parent` (`parent_id`)
Trying to delete or update in parent table, in index `PRIMARY` tuple:
DATA TUPLE: 3 fields;
0: len 4; hex 80000001; asc ;;
1: len 6; hex 000000d203d6; asc ;;
2: len 7; hex 1e000001ca0110; asc ;;
But in child table `xiaoboluo`.`child`, in index `child_id`, there is a record:
PHYSICAL RECORD: n_fields 2; compact format; info bits 0
0: len 4; hex 80000001; asc ;;
1: len 6; hex 000013a99b3e; asc >;;
4.6 第二种:尝试修改父表的表结构时发生的错误,这种错误就没有那么清楚了,这可能会让调试更困难:
mysql> alter table parent modify parent_id int unsigned not null;
ERROR 1025 (HY000): Error on rename of './xiaoboluo/#sql-b695_4e3b' to './xiaoboluo/parent' (errno: 150)
查看show engine innodb status输出信息:
------------------------
LATEST FOREIGN KEY ERROR
------------------------
160128 1:32:33 Error in foreign key constraint of table xiaoboluo/child:
there is no index in referenced table which would contain
the columns as the first columns, or the data types in the
referenced table do not match the ones in table. Constraint:
,
CONSTRAINT "i_child" FOREIGN KEY ("child_id") REFERENCES "parent" ("parent_id")
The index in the foreign key in table is "child_id"
See http://dev.mysql.com/doc/refman/5.5/en/innodb-foreign-key-constraints.html
for correct foreign key definition.
InnoDB: Renaming table `xiaoboluo`.<result 2 when explaining filename '#sql-b695_4e3b'> to `xiaoboluo`.`parent` failed!
上面的错误是数据类型不匹配,外键列必须有完全相同的数据类型,包括任何的修饰符(如这里父表多加了一个unsigned,这也是问题所在),当看到1025错误并不理解为什么时,最好查看下innodb status。在每次看到有新错误时,外键错误信息都会被重写,percona toolkit中的pt-fk-error-logger工具可以用表保存这些信息以供后续分析。
5.与外键错误一样,这部分只有当服务器产生死锁时才会出现,死锁信息同样在每次有新的死锁错误时被重写,percona toolkit中的pt-deadlock-logger工具可以用表保存这些信息以供后续分析
死锁在等待关系图里是一个循环,就是一个锁定了行的数据结构又在等待别的锁,这个循环可以任意地大,innodb会立即检测到死锁,因为每当有事务等待行锁的时候,它都会去检查等待关系图里是否有循环,死锁的情况可能会比较复杂,但是,这一部分只显示了最近的两个死锁的情况,它们在各自的事务里执行的最后一条语句,以及它们在等待关系图里形成环锁的信息。在这个循环里你看不到其他事务,也可能看不到在事务里早先真正获得了锁的语句,尽管如此,通常还是可以通过查看这些输出结果来确定到底是什么引起了死锁。
在innodb里实际上有两种死锁,第一种就是常常碰到的那种,它在等待关系图里是一个真正的循环,另外一种就是在一个等待关系图里,因代价昂贵而无法检测它是不是包含了循环,如果innodb要在关系图里检查超过100W个锁,或者在检查过程中,innodb要重做200个以上的事务,那它会放弃,并宣布这里有一个死锁,这些数值都是硬编码在innodb代码里的常量,无法配置(如果你NB可以修改代码然后重新编译)。第二种死锁报错你可以在输出里看到一条信息:TOO DEEP OR LONG SEARCH IN THE LOCK TABLE WAITS-FOR GRAPH
innodb不仅会打印出事务和事务持有和等待的锁,而且还有记录本身,不幸的是,它至于可能超过为输出结果预留的长度(只能打印1M的内容且只能保留最近一次的死锁信息),如果你无法看到完整的输出,此时可以在任意库下创建innodb_monitor或innodb_lock_monitor表,这样innodb status信息会完整且每15s一次被记录到错误日志中。如:create table innodb_monitor(a int)engine=innodb;,不需要记录到错误日志中时就删掉这个表即可。
5.1 下面也搞一个示例来看看:
5.1.1 建表:
mysql> create table test_deadlock(id int unsigned not null primary key auto_increment,test int unsigned not null);
Query OK, 0 rows affected (0.02 sec)
5.1.2 插入测试数据:
mysql> insert into test_deadlock(test) values(1),(2),(3),(4),(5);
Query OK, 5 rows affected (0.00 sec)
Records: 5 Duplicates: 0 Warnings: 0
打开两个会话终端:
5.1.3 会话1执行下面的SQL:
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from test_deadlock where id=1 for update;
+----+------+
| id | test |
+----+------+
| 1 | 1 |
+----+------+
1 row in set (0.00 sec)
5.1.4 接着会话2执行下面的SQL:
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from test_deadlock where id=2 for update;
+----+------+
| id | test |
+----+------+
| 2 | 2 |
+----+------+
1 row in set (0.00 sec)
5.1.5 回到会话1执行下面的SQL,会发生等待:
mysql> select * from test_deadlock where id=2 for update;
5.1.6 回到会话2执行下面的SQL,产生死锁,会话2被回滚:
mysql> select * from test_deadlock where id=1 for update;
ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction
5.2 查看innodb status信息:
------------------------
LATEST DETECTED DEADLOCK
------------------------
160128 1:51:53 #这里显示了最近一次发生死锁的日期和时间
*** (1) TRANSACTION:
TRANSACTION D20847, ACTIVE 141 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 3 lock struct(s), heap size 376, 2 row lock(s)
MySQL thread id 20027, OS thread handle 0x7f0a4c0f8700, query id 1818124 localhost root statistics
select * from test_deadlock where id=2 for update
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 441 page no 3 n bits 72 index `PRIMARY` of table `xiaoboluo`.`test_deadlock` trx id D20847 lock_mode X locks rec but not gap waiting
Record lock, heap no 3 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
0: len 4; hex 00000002; asc ;;
1: len 6; hex 000000d20808; asc ;;
2: len 7; hex ad000001ab011d; asc ;;
3: len 4; hex 00000002; asc ;;
*** (2) TRANSACTION:
TRANSACTION D20853, ACTIVE 119 sec starting index read
mysql tables in use 1, locked 1
3 lock struct(s), heap size 1248, 2 row lock(s)
MySQL thread id 20081, OS thread handle 0x7f0a0f020700, query id 1818204 localhost root statistics
select * from test_deadlock where id=1 for update
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 441 page no 3 n bits 72 index `PRIMARY` of table `xiaoboluo`.`test_deadlock` trx id D20853 lock_mode X locks rec but not gap
Record lock, heap no 3 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
0: len 4; hex 00000002; asc ;;
1: len 6; hex 000000d20808; asc ;;
2: len 7; hex ad000001ab011d; asc ;;
3: len 4; hex 00000002; asc ;;
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 441 page no 3 n bits 72 index `PRIMARY` of table `xiaoboluo`.`test_deadlock` trx id D20853 lock_mode X locks rec but not gap waiting
Record lock, heap no 2 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
0: len 4; hex 00000001; asc ;;
1: len 6; hex 000000d20808; asc ;;
2: len 7; hex ad000001ab0110; asc ;;
3: len 4; hex 00000001; asc ;;
*** WE ROLL BACK TRANSACTION (2)
这部分内容比较多,下面分段逐一进行解释:
5.2.1 下面这部分显示的是死锁的第一个事务的信息:
*** (1) TRANSACTION:
TRANSACTION D20847, ACTIVE 141 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 3 lock struct(s), heap size 376, 2 row lock(s)
MySQL thread id 20027, OS thread handle 0x7f0a4c0f8700, query id 1818124 localhost root statistics
select * from test_deadlock where id=2 for update
TRANSACTION D20847, ACTIVE 141 sec starting index read:这行表示事务D20847,ACTIVE 141 sec表示事务处于活跃状态141s,starting index read表示正在使用索引读取数据行
mysql tables in use 1, locked 1#这行表示事务D20847正在使用1个表,且涉及锁的表有1个
LOCK WAIT 3 lock struct(s), heap size 376, 2 row lock(s) #这行表示在等待3把锁,占用内存376字节,涉及2行记录,如果事务已经锁定了几行数据,这里将会有一行信息显示出锁定结构的数目(注意,这跟行锁是两回事)和堆大小,堆的大小指的是为了持有这些行锁而占用的内存大小,Innodb是用一种特殊的位图表来实现行锁的,从理论上讲,它可将每一个锁定的行表示为一个比特,经测试显示,每个锁通常不超过4比特
MySQL thread id 20027, OS thread handle 0x7f0a4c0f8700, query id 1818124 localhost root statistics #这行表示该事务的线程ID信息,操作系统句柄信息,连接来源、用户
select * from test_deadlock where id=2 for update #这行表示事务涉及的SQL
5.2.2 下面这一部分显示的是当死锁发生时,第一个事务正在等待的锁等信息:
*** (1) WAITING FOR THIS LOCK TO BE GRANTED: #这行信息表示第一个事务正在等待锁被授予
RECORD LOCKS space id 441 page no 3 n bits 72 index `PRIMARY` of table `xiaoboluo`.`test_deadlock` trx id D20847 lock_mode X locks rec but not gap waiting
Record lock, heap no 3 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
0: len 4; hex 00000002; asc ;;
1: len 6; hex 000000d20808; asc ;;
2: len 7; hex ad000001ab011d; asc ;;
3: len 4; hex 00000002; asc ;;
RECORD LOCKS space id 441 page no 3 n bits 72 index `PRIMARY` of table `xiaoboluo`.`test_deadlock` trx id D20847 lock_mode X locks rec but not gap waiting#这行信息表示等待的锁是一个record lock,空间id是441,页编号为3,大概位置在页的72位处,锁发生在表xiaoboluo.test_deadlock的主键上,是一个X锁,但是不是gap lock。 waiting表示正在等待锁
Record lock, heap no 3 PHYSICAL RECORD: n_fields 4; compact format; info bits 0 #这行表示record lock的heap no 位置
#这部分剩下的内容只对调试才有用。
0: len 4; hex 00000002; asc ;;
1: len 6; hex 000000d20808; asc ;;
2: len 7; hex ad000001ab011d; asc ;;
3: len 4; hex 00000002; asc ;;
5.2.3 下面这部分是事务二的状态:
*** (2) TRANSACTION:
TRANSACTION D20853, ACTIVE 119 sec starting index read #事务2处于活跃状态119s
mysql tables in use 1, locked 1 #正在使用1个表,涉及锁的表有1个
3 lock struct(s), heap size 1248, 2 row lock(s) #涉及3把锁,2行记录
MySQL thread id 20081, OS thread handle 0x7f0a0f020700, query id 1818204 localhost root statistics
select * from test_deadlock where id=1 for update #第二个事务的SQL
5.2.4 下面这部分是事务二的持有锁信息:
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 441 page no 3 n bits 72 index `PRIMARY` of table `xiaoboluo`.`test_deadlock` trx id D20853 lock_mode X locks rec but not gap
Record lock, heap no 3 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
0: len 4; hex 00000002; asc ;;
1: len 6; hex 000000d20808; asc ;;
2: len 7; hex ad000001ab011d; asc ;;
3: len 4; hex 00000002; asc ;;
RECORD LOCKS space id 441 page no 3 n bits 72 index `PRIMARY` of table `xiaoboluo`.`test_deadlock` trx id D20853 lock_mode X locks rec but not gap
Record lock, heap no 3 PHYSICAL RECORD: n_fields 4; compact format; info bits 0 #从这两行持有锁信息计息后面几行调试信息上看,就是事务1正在等待的锁。
5.2.5 下面这部分是事务二正在等待的锁,从下面的信息上看,等待的是同一个表,同一个索引,同一个page上的record lock X锁,但是heap no位置不同,即不同的行上的锁:
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 441 page no 3 n bits 72 index `PRIMARY` of table `xiaoboluo`.`test_deadlock` trx id D20853 lock_mode X locks rec but not gap waiting
Record lock, heap no 2 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
0: len 4; hex 00000001; asc ;;
1: len 6; hex 000000d20808; asc ;;
2: len 7; hex ad000001ab0110; asc ;;
3: len 4; hex 00000001; asc ;;
*** WE ROLL BACK TRANSACTION (2) #这个表示事务2被回滚,因为两个事务的回滚开销一样,所以选择了后提交的事务进行回滚,如果两个事务回滚的开销不同(undo 数量不同),那么就回滚开销最小的那个事务。
当一个事务持有了其他事务需要的锁,同时又想获得其他事务持有的锁时,等待关系图上就会产生循环,Innodb不会显示所有持有和等待的锁,但是,它显示了足够的信息来帮你确定,查询操作正在使用哪些索引,这对于你确定能否避免死锁有极大的价值。
如果能使两个查询对同一个索引朝同一个方向进行扫描,就能降低死锁的数目,因为,查询在同一个顺序上请求锁的时候不会创建循环,有时候,这是很容易做到的,如:要在一个事务里更新许多条记录,就可以在应用程序的内存里把它们按照主键进行排序,然后,再用同样的顺序更新到数据库里,这样就不会有死锁发生,但是在另一些时候,这个方法也是行不通的(如果有两个进程使用了不同的索引区间操作同一张表的时候)。
6. 下面这部分包含了一些关于innodb事务的总结信息,紧随其后的是当前活跃事务列表,如:
------------
TRANSACTIONS
------------
Trx id counter 4E0132AD
Purge done for trx's n:o < 4E01090B undo n:o < 0
History list length 1853
LIST OF TRANSACTIONS FOR EACH SESSION:
---TRANSACTION 4E0131D3, not started
MySQL thread id 26208218, OS thread handle 0x7fec7c582700, query id 5274800318 10.207.162.69 gdsser
---TRANSACTION 4E01323F, not started
MySQL thread id 26208217, OS thread handle 0x7fec7c1b3700, query id 5274800938 10.207.162.69 gdsser
....................
---TRANSACTION 4E0132AC, ACTIVE 0 sec preparing
2 lock struct(s), heap size 376, 1 row lock(s), undo log entries 1
MySQL thread id 26208200, OS thread handle 0x7fec567e0700, query id 5274801557 10.207.162.69 gdsser
commit
---TRANSACTION 4E0110E7, ACTIVE 188 sec
mysql tables in use 1, locked 0
MySQL thread id 26208154, OS thread handle 0x7fec7c235700, query id 5274800671 10.143.90.228 root Sending data
SELECT /*!40001 SQL_NO_CACHE */ * FROM `m_flowskillpoint`
Trx read view will not see trx with id >= 4E0110E8, sees < 4E0108EE
---TRANSACTION 4E0108EF, ACTIVE 233 sec fetching rows
mysql tables in use 1, locked 0
MySQL thread id 26208131, OS thread handle 0x7fec578e3700, query id 5274801341 10.143.90.228 root Sending data
SELECT /*!40001 SQL_NO_CACHE */ * FROM `m_flowsilver`
Trx read view will not see trx with id >= 4E0108F0, sees < 4E0108EC
---TRANSACTION 4E0108EE, ACTIVE 233 sec fetching rows
mysql tables in use 1, locked 0
MySQL thread id 26208132, OS thread handle 0x7fec7c78a700, query id 5274797797 10.143.90.228 root Sending data
SELECT /*!40001 SQL_NO_CACHE */ * FROM `m_flowmail`
Trx read view will not see trx with id >= 4E0108EF, sees < 4E0108EC
这部分内容比较多,下面分段逐一进行解释:
6.1.
Trx id counter 4E0132AD #这行表示当前事务ID,这是一个系统变量,每创建一个新事务都会增加
Purge done for trx's n:o < 4E01090B undo n:o < 0 #这是innodb清除旧MVCC行时所用的事务ID,将这个值和当前事务ID进行比较,就可以知道有多少老版本的数据未被清除。这个数字多大才可以安全的取值没有硬性和速成的规定,如果数据没做过任何更新,那么一个巨大的数字也不意味着有未清除的数据,因为实际上所有事务在数据库里查看的都是同一个版本的数据(此时只是事务ID在增加,而数据没有变更),另一方面,如果有很多行被更新,那每一行就会有一个或多个版本留在内存里,减少此类开销的最好办法就是确保事务已完成就立即提交,不要让它长时间地处于打开状态,因为一个打开的事务即使不做任何操作,也会影响到innodb清理旧版本的行数据。 undo n:o < 0这个是innodb清理进程正在使用的撤销日志编号,为0 0时说明清理进程处于空闲状态。
History list length 1853 #历史记录的长度,即位于innodb数据文件的撤销空间里的页面的数目,如果事务执行了更新并提交,这个数字就会增加,而当清理进程移除旧版本数据时,它就会减少,清理进程也会更新Purge done for.....这行中的数值。
6.2.
头部信息之后就是一个事务列表,当前版本的mysql还不支持嵌套事务,因此,在某个时间点上,每个客户端连接能够拥有的事务数量是有一个上限的,而且每一个事务只能属于单一连接(即一个事务只能使用单个线程执行,不能使用多个线程)。在输出信息里,每一个事务至少占有两行内容,如:
---TRANSACTION 4E0131D3, not started #每个事务的第一行以事务的ID和状态开始,not started表示这个事务已经提交并且没有再发起影响事务的语句,可能刚好空闲
MySQL thread id 26208218, OS thread handle 0x7fec7c582700, query id 5274800318 10.207.162.69 gdsser#然后每个事务的第二行是一些线程等信息,MySQL thread id <数字>部分和是hi用show full processlist;命令看到的id列相同。紧随其后的是一个内部查询id和一些连接信息,这些信息同样与show full processlist中的输出相同。
---TRANSACTION 4E01323F, not started
MySQL thread id 26208217, OS thread handle 0x7fec7c1b3700, query id 5274800938 10.207.162.69 gdsser
6.3.
上面是not started状态的事务信息,下面来看看为ACTIVE状态的事务信息:
---TRANSACTION 4E0110E7, ACTIVE 188 sec #这行显示次事务处于活跃状态已经188s,可能的所有状态有not started,active,prepared和committed in memory,一旦事务日志落盘了就会变成not started状态。在时间后面会显示出当前事务正在做什么(在这里为空没有显示出来),在源代码中有超过30个字符串常量可以显示在时间后面,如:fetching,preparing,rows,adding foreign keys等等
mysql tables in use 1, locked 0 #该事务用到的表数和涉及表锁的表数,Innodb一般不会锁定表,但对有些语句会锁定,如果mysql服务器在高于innodb层之上将表锁定,这里也是能够显示出来的,如果事务已经锁定了几行数据,这里将会有一行信息显示出锁定结构的数目(注意,这跟行锁是两回事)和和堆大小,如:2 lock struct(s), heap size 376, 1 row lock(s), undo log entries 1,堆的大小指的是为了持有这些行锁而占用的内存大小,Innodb是用一种特殊的位图表来实现行锁的,从理论上讲,它可将每一个锁定的行表示为一个比特,经测试显示,每个锁通常不超过4比特。
MySQL thread id 26208154, OS thread handle 0x7fec7c235700, query id 5274800671 10.143.90.228 root Sending data #与show processlist输出结果大部分相同
SELECT /*!40001 SQL_NO_CACHE */ * FROM `m_flowskillpoint` #如果事务正在运行一个查询,那么这里就会显示事务涉及的SQL,注意:有些版本可能只显示其中一小段,而不是完整的SQL
Trx read view will not see trx with id >= 4E0110E8, sees < 4E0108EE #这行显示了事务的读视图,它表明了因为版本关系而产生的对于事务可见和不可见两种类型的事务ID的范围,在这里,两个数字之间有一个事务的间隙,这个间隙里的事务可能是不可见的,innodb在执行查询时,对于那些事务ID正好在这个间隙的行,还会检查其可见性。
注:如果事务正在等待一个锁,那么在查询SQL文本后面将可以看到这个锁的信息,在上文的死锁例子里,这样的信息看到过很多了,不幸的是,输出信息并没有说出这个锁正被其他哪个事务持有,不过可以通过information_schema库下的innodb_trx,innodb_lock_waits,innodb_locks三个表来查明这一点。如果输出信息里有很多个事务,innodb可能会限制要打印出来的事务数目,以免输出信息增长得太大,这时就会看到...truncated...提示。
7.FILE I/O部分显示的是I/O辅助线程的状态,还有性能计数器的状态,如下:
--------
FILE I/O
--------
I/O thread 0 state: waiting for i/o request (insert buffer thread) #insert buffer thread
I/O thread 1 state: waiting for i/o request (log thread) #log thread
I/O thread 2 state: waiting for i/o request (read thread)
I/O thread 3 state: waiting for i/o request (read thread)
I/O thread 4 state: waiting for i/o request (read thread)
I/O thread 5 state: doing file i/o (read thread) ev set #以上为默认的4个read thread
I/O thread 6 state: waiting for i/o request (write thread)
I/O thread 7 state: waiting for i/o request (write thread)
I/O thread 8 state: waiting for i/o request (write thread)
I/O thread 9 state: waiting for i/o request (write thread) #以上为默认的4个write thread
Pending normal aio reads: 128 [0, 0, 0, 128] , aio writes: 0 [0, 0, 0, 0] , #读线程和写线程挂起操作的数目等,aio的意思是异步I/O
ibuf aio reads: 0, log i/o's: 0, sync i/o's: 0 #insert buffer thread挂起的fsync()操作数目等
Pending flushes (fsync) log: 0; buffer pool: 0 #log thread挂起的fsync()操作数目等
146246831 OS file reads, 760501349 OS file writes, 247143684 OS fsyncs #这行显示了读,写和fsync()调用执行的数目,在你的机器环境负载下这些绝对值可能会有所不同,因此更重要的是监控它们过去一段时间内是如何改变的。
1 pending preads, 0 pending pwrites #这行显示了当前被挂起的读和写操作数
145.49 reads/s, 783677 avg bytes/read, 28.75 writes/s, 10.67 fsyncs/s #这行显示了在头部显示的时间(指的是第1部分的时间)段内的每秒平均值。
注:三行挂起读写线程、缓冲池线程、日志线程的统计信息的值是检测I/O受限的应用的一个好方法,如果这些I/O大部分有挂起操作,那么负载可能I/O受限。在linux系统下使用参数:innodb_read_io_threads和innodb_write_io_threads两个变量来配置读写线程的数量,默认为各4个线程。
insert buffer thread:负责插入缓冲合并,如:记录被从插入缓冲合并到表空间中
log thread:负责异步刷事务日志
read thread:执行预读操作以尝试预先读取innodb预感需要的数据
write thread:刷新脏页缓冲
8.这部分显示了insert buffer和adaptive hash index两个部分的结构的状态
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 12, free list len 27559, seg size 27572, 18074934 merges #这行显示了关于size(size 12代表了已经合并记录页的数量)、free list(代表了插入缓冲中空闲列表长度)和seg size大小(seg size 27572显示了当前insert buffer的长度,大小为27572*16K=440M左右)的信息。18074934 merges代表合并插入的次数
merged operations: #这个标签下的一行信息insert,delete mark,delete分别表示merge操作合并了多少个insert buffer,delete buffer,purge buffer
insert 81340470, delete mark 8893610, delete 818579
discarded operations: #这个标签下的一行信息表示当change buffer发生merge时表已经被删除了,就不需要再将记录合并到辅助索引中了
insert 0, delete mark 0, delete 0
Hash table size 87709057, node heap has 10228 buffer(s) #这行显示了自使用哈希索引的状态,其中,Hash table size 87709057表示AHI的大小,node heap has 10228 buffer(s)表示AHI的使用情况
1741.05 hash searches/s, 539.48 non-hash searches/s #这行显示了在头部第1部分提及的时间内Innodb每秒完成了多少哈希索引操作,1741.05 hash searches/s表示每秒使用AHI搜索的情况,539.48 non-hash searches/s表示每秒没有使用AHI搜索的情况(因为哈希索引只能用于等值查询,而范围查询,模糊查询是不能使用哈希索引的。),通过hash searches: non-hash searches的比例大概可以了解使用哈希索引后的效率,哈希索引查找与非哈希索引查找的比例仅供参考,自适应哈希索引无法配置,但是可以通过innodb_adaptive_hash_index=ON|OFF参数来选择是否需要这个特性。
注:
innodb从1.0.x开始引入change buffer,可以视为insert buffer的升级,从这个版本开始,innodb可以对DML操作(insert,delete,update)都进行缓冲,他们分别是insert buffer,delete buffer,purge buffer,当然和之前insert buffer一样,change buffer适用对象仍然是非唯一索引的辅助索引,因为没有update buffer,所以对一条记录进行update的操作可以分为两个过程:
A:将记录标记为删除
B:真正将记录删除
因此,delete buffer对应update 操作的第一个过程,即将记录标记为删除,purge buffer对应update的第二个过程,即将记录真正地删除
9.这部分显示了关于innodb事务日志(重做日志)子系统的统计:
---
LOG
---
Log sequence number 1351392990515 #这行显示了当前最新数据产生的日志序列号
Log flushed up to 1351392989504 #这行显示了日志已经刷新到哪个位置了(已经落盘到事务日志中的日志序列号)
Last checkpoint at 1351373900020 #这行显示了上一次检查点的位置(一个检查点表示一个数据和日志文件都处于一致状态的时刻,并且能用于恢复数据),如果上一次检查点落后与上一行太多,并且差异接近于事务日志文件的大小,Innodb会触发“疯狂刷”,这对性能而言非常糟糕。
0 pending log writes, 0 pending chkp writes #这行显示了当前挂起的日志读写操作,可以将这行的值与第7部分FILE I/O对应的值做比较,以了解你的I/O有多少是由于日志系统引起的。
286879989 log i/o's done, 15.92 log i/o's/second #这行显示了日志操作的统计和每秒日志I/O数,可以将这行的值与第7部分FILE I/O对应的值做比较,以了解你的I/O有多少是由于日志系统引起的。
9.这部分显示了关于innodb缓冲池及其如何使用内存的统计:
9.1.
----------------------
BUFFER POOL AND MEMORY
----------------------
Total memory allocated 45357793280; in additional pool allocated 0 #这行显示了由innodb分配的总内存,以及其中多少是额外内存池分配,额外内存池仅分配了其中很小一部分内存,由内部内存分配器分配,现在的innodb版本一般使用操作系统的内存分配器,但老版本使用自己的,这是由于在那个时代有些操作系统并未提供一个非常好的内存分配实现。
Dictionary memory allocated 12681573
Buffer pool size 2705015 #从这行开始的下面4行显示缓冲池度量值,以页为单位,度量值有总的缓冲池大小,空闲页数,分配用来存储数据库页的页数,以及脏数据库页数。这行显示了缓冲池总共有多少个页,即即2705015*16K,共有43G的缓冲池
Free buffers 5 #这行显示了缓冲池空闲页数
Database pages 2694782 #这行显示了分配用来存储数据库页的页数,即,表示LRU列表中页的数量,包含young sublist和old sublist
Old database pages 994651 #这行显示了LRU中的old sublist部分页的数量
Modified db pages 10610 #这行显示脏数据库页数
Pending reads 128 #这行显示了挂起读的数量
Pending writes: LRU 0, flush list 0, single page 0 #这行显示了挂起写的数量
#注意,这里挂起的读和写操作并不与FILE I/O部分的值匹配,因为Innodb可能合并许多的逻辑读写操作到一个物理I/O操作中,LRU代表最近使用到的被挂起数量,它是通过冲刷缓冲中不经常使用的页来释放空间以供给经常使用的页的一种方法,冲刷列表flush list存放着检查点处理需要冲刷的旧页被挂起的数量,单页single page被挂起的数量(single page写是独立的页面写,不会被合并)。
Pages made young 3014373561, not young 0 #这行显示了LRU列表中页移动到LRU首部的次数,因为该服务器在运行阶段改变没有达到innodb_old_blocks_time阀值的值,因此not young为0
6960.42 youngs/s, 0.00 non-youngs/s #表示每秒young和non-youngs这两类操作的次数
Pages read 2946570833, created 43450158, written 574214278 #这行显示了innodb被读取,创建,写入了多少页,读/写页的值是指的从磁盘读到缓冲池的数据,或者从缓冲池写到磁盘中的数据,创建页指的是innodb在缓冲池中分配但没有从数据文件中读取内容的页,因为它并不关心内容是什么(如,它们可能属于一个已经被删除的表)
6960.54 reads/s, 4.42 creates/s, 9.33 writes/s #这行显示了对应上面一行的每秒read,create,write的页数
Buffer pool hit rate 955 / 1000, young-making rate 45 / 1000 not 0 / 1000 #这行显示了缓冲池的命中率,它用来衡量innodb在缓冲池中查找到所需页的比例,它度量自上次Innodb状态输出后到本次输出这段时间内的命中率,因此,如果服务器自那以后一直很安静,你将会看到No buffer pool page gets since the last printout。它对于度量缓存池的大小并没有用处。
Pages read ahead 6928.54/s, evicted without access 8.21/s, Random read ahead 0.00/s #这行显示了页面预读,随机预读的每秒页数
LRU len: 2694782, unzip_LRU len: 0 #innodb1.0.x开始支持压缩页的功能,将原来16K的页压缩为1K,2K,4K,8K,而由于页的大小发生了变化,LRU列表也有了些改变,对于非16K的页,是通过unzip_LRU列表进行管理的,可以看到unzip_LRU len为0表示没有使用压缩页.
I/O sum[60790]:cur[30], unzip sum[0]:cur[0]
对于压缩页的表,每个表的压缩比例可能不同,可能存在有的表页大小为8K,有的表页大小为2K的情况,unzip_LRUs 怎样从缓存池中分配内存的呢?
首先,在unzip_LRU列表中对不同压缩页大小的页进行分别管理,其次,通过伙伴算法进行内存的分配,例如:需要从缓存池中申请页为4K的大小,其过程如下:
a:检查4K的unzip_LRU列表,检查是否有可用的空闲页
b:若有,则直接使用
c:若没有,检查8K的unzip_LRU列表
d:若能够得到空闲页,将页分成2个4K的页,存放到4K的unzip_LRU列表
e:若不能得到空闲页,从LRU列表中申请一个16K的页,将页分成1个8K,2个4K的页,分别存放到各自大小对应的unzip_LRU列表中。
注:可能出现Free buffers和Database pages之和不等于Buffer pool size,因为缓冲池中的页肯会被分配给自适应哈希索引,lock信息,insert buffer等,而这部分页不需要LRU算法进行维护,因此不在LRU列表中。
9.2.如果innodb buffer pool使用参数innodb
_buffer_pool_instances=num设置了大于1个缓冲池实例,那么就会按照这个参数把innodb_buffer_pool_size=xxx平分为num份。每份的信息显示类似如下,这部分的内容和9.1小节内容类似,就不再多说。
----------------------
INDIVIDUAL BUFFER POOL INFO
----------------------
---BUFFER POOL 0
Buffer pool size 541003
Free buffers 1
Database pages 538965
Old database pages 198933
Modified db pages 2190
Pending reads 128
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 603372180, not young 0
1441.81 youngs/s, 0.00 non-youngs/s
Pages read 589705199, created 8703138, written 116954697
1441.61 reads/s, 0.75 creates/s, 1.83 writes/s
Buffer pool hit rate 955 / 1000, young-making rate 45 / 1000 not 0 / 1000
Pages read ahead 1436.98/s, evicted without access 0.87/s, Random read ahead 0.00/s
LRU len: 538965, unzip_LRU len: 0
I/O sum[12158]:cur[6], unzip sum[0]:cur[0]
---BUFFER POOL 1
Buffer pool size 541003
Free buffers 1
Database pages 538959
Old database pages 198931
Modified db pages 2025
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 602366394, not young 0
1481.35 youngs/s, 0.00 non-youngs/s
Pages read 588738997, created 8708171, written 113209540
1480.56 reads/s, 0.83 creates/s, 1.92 writes/s
Buffer pool hit rate 958 / 1000, young-making rate 42 / 1000 not 0 / 1000
Pages read ahead 1473.73/s, evicted without access 1.96/s, Random read ahead 0.00/s
LRU len: 538959, unzip_LRU len: 0
I/O sum[12158]:cur[6], unzip sum[0]:cur[0]
10.这部分显示了其他各项的innodb统计:
--------------
ROW OPERATIONS
--------------
0 queries inside InnoDB, 0 queries in queue #这行显示了innodb内核内有多少个线程,队列中有多少个线程,队列中的查询是innodb为限制并发执行的线程数量而不运行进入内核的线程。查询在进入队列之前会休眠等待。
5 read views open inside InnoDB #这行显示了有多少打开的innodb读视图,读视图是包含事务开始点的数据库内容的MVCC快照,你可以看看某特定事务在第6部分TRANSACTIONS是否有读视图
Main thread process no. 4368, id 140653691242240, state: sleeping #这行显示了内核的主线程状态
Number of rows inserted 3429012215, updated 153529675, deleted 112310240, read 3739562987410 #这行显示了多少行被插入,更新和删除,读取
428.52 inserts/s, 7.21 updates/s, 0.46 deletes/s, 1047933.92 reads/s #这行显示了对应上面一行的每秒平均值,如果想查看innodb有多少工作量在进行,那么这两行是很好的参考值
----------------------------
END OF INNODB MONITOR OUTPUT #要注意了,如果看不到这行输出,可能是有大量事务或者是有一个大的死锁截断了输出信息
============================
注:内核的主线程状态可能的状态值有如下一些:
A:doing background drop tables
B:doing insert buffer merge
C:flushing buffer pool pages
D:making checkpoint
E:purging
F:reserving kernel mutex
G:sleeping
H:suspending
I:waiting for buffer pool flush to end
J:waiting for server activity
苦逼一线36军规
核心军规
- 尽量不在数据库做运算
- 控制单表数据量 纯INT不超过10M条,含Char不超过5M条
- 保持表身段苗条
- 平衡范式和冗余
- 拒绝大SQL,复杂事务,大批量任务
字段类军规
- 用好数值字段,尽量简化字段位数
- 把字符转化为数字
- 优先使用Enum或Set
- 避免使用Null字段
- 少用并拆封Text/Blob
- 不在数据库中存图片
索引类军规
- 谨慎合理添加索引
- 字符字段必须建立前缀索引?
- 不在索引列做运算
- 自增列或全局ID做InnoDB主键
- 尽量不用外键
SQL类军规
- SQL尽可能简单
- 保持事务连接短小
- 尽可能避免使用SP/Trigger/Function
- 尽量不用Select *
- 改写Or为IN()
- 改写Or为Union
- 避免负向查询和%前缀模糊查询
- Count不要使用在可Null的字段上面
- 减少Count(*)
- Limit高效分页,SELECT * FROM message WHERE id > 9527 (or sub select) limit 10
- 使用Union ALL 而不用Union
- 分解链接,保证高并发
- Group By 去除排序
- 同数据类型的列值比较
- Load Data导入数据,比Insert快20倍
- 打散大批量更新,尽量凌晨操作
约定类军规
-
隔离线上线下
-
禁止未经DBA认证的子查询
-
永远不在程序段显式加锁
-
表字符集统一使用UTF8MB4
常见问题及解决办法
遇事不决问官方文档
SQL没有走合适索引
原因: 表统计信息不准确。
手动分析表
执行analyze table table_name
innodb和myisam存储引擎都可以通过执行“Analyze table tablename”来收集表的统计信息,除非执行计划不准确,否则不要轻易执行该操作,如果是很大的表该操作会影响表的性能。
其实表自身会定期收集统计信息,下面分析一下自动触发条件,
自动触发
以下行为会自动触发统计信息的收集
1.第一次打开表的时候
2.表修改的行超过1/6或者20亿条时
3.当有新的记录插入时
4.执行show index from tablename或者执行show table、查询information_schema.tables\statistics 时
有一个参数也能决定统计信息的收集,下面简单说下
参数innodb_stats_on_metadata
innodb_stats_on_metadata默认是关闭的,当开启参数innodb_stats_on_metadata后访问以下表会触发统计信息的收集
在访问以下表时,innodb表的统计信息可自动收集
information_schema.TABLES
information_schema.STATISTICS
information_schema.PARTITIONS
information_schema.KEY_COLUMN_USAGE
information_schema.TABLE_CONSTRAINTS
information_schema.REFERENTIAL_CONSTRAINTS
information_schema.table_constraints
参数说明:
Innodb_stats_sample_pages:每次收集统计信息时采样的页数,默认为20
innodb_stats_persistent:默认on,将analyze table产生的统计信息保存于磁盘,直至下次analyze table为止,此举避免了统计信息动态更新,保证了执行计划的稳定,对于大表也节省了收集统计信息的所需资源;
忘记 MySQL 的 root 密码
登录到数据库所在的服务器,手工 kill 掉 mysql 进程。
- 登录到数据库所在的服务器,手工 kill 掉 MySQL 进程:
root@bogon:/data/mysql# kill cat ./mysql.pid
其中,mysql.pid 指的是 MySQL 数据目录下的 pid 文件,它记录了 MySQL 服务的进程号。
- 使用
--skip-grant-tables选项重启 MySQL 服务:
zj@bogon:/data/mysql$ sudo /usr/local/mysql/bin/mysqld --skip-grant-tables --user=root &
–skip-grant-tables 选项意思是启动 MySQL 服务时跳过权限表认证。启动后,连接到 MySQL 的 root 将不需要口令。
- 用空密码的 root 用户连接到 mysql ,并且更改 root 口令:
zj@bogon:/usr/local/mysql/bin$ mysql -uroot
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 3Server version: 5.7.18-log Source distribution
Copyright (c) 2000, 2017, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or itsaffiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MySQL [(none)]> set password = password('123456');
ERROR 1290 (HY000): The MySQL server is running with the --skip-grant-tables option so it cannot execute this statementMySQL [(none)]> use mysql
Database changed
MySQL [mysql]> update user set authentication_string=password('123456') where user="root" and host="localhost";
Query OK, 1 row affected, 1 warning (0.02 sec)
Rows matched: 1 Changed: 1 Warnings: 1
MySQL [mysql]> flush privileges;
Query OK, 0 rows affected (0.00 sec)
MySQL [mysql]> exit;
由于使用了 --skip-grant-tables 选项启动,使用 “set password” 命令更改密码失败,直接更新 user 表的 authentication_string(测试版本为5.7.18,有的版本密码字段是 ‘password’) 字段后,更改密码成功。刷新权限表,使权限认证重新生效。重新用 root 登录时,就可以使用刚刚修改后的口令了。
myisam 存储引擎的表损坏
有的时候可能会遇到 myisam 表损坏的情况。一张损坏的表的症状通常是查询意外中断,并且能看到下述错误:
‘table_name.frm’ 被锁定不能更改
不能找到文件 ‘tbl_name.MYYI’ (errcode:nnn)
文件意外结束
记录文件被毁坏
从表处理器得到错误 nnn。
通常有以下两种解决方法:
- 使用 myisamchk 工具
使用 MySQL 自带的 myisamchk 工具进行修复:
myisamchk -r tablename
其中 -r 参数的含义是 recover,上面的方法几乎能解决所有问题,如果不行,则使用命令:
mysiamchk -o tablename
其中 -o 参数的含义是 --safe-recover,可以进行更安全的修复。
- 使用check,repair命令
使用 MySQL 的 check table 和 repair table 命令一起进行修复,check table 用来检查表是否有损坏;repair table 用来对坏表进行修复。
数据目录磁盘空间不足的问题
系统上线后,随着数据量的不断增加,会发现数据目录下的可用空间越来越小,从而给应用造成了安全隐患。
- 对于 myisam 存储引擎的表
对于 myisam 存储引擎的表,在建表时可以用如下选项分别制定数据目录和索引目录存储到不同的磁盘空间,而默认会同时放在数据目录下:
data directory = 'absolute path to directory’index directory = ‘absolute path to directory’
如果表已经创建,只能先停机或者将表锁定,防止表的更改,然后将表的数据文件和索引文件 mv 到磁盘充足的分区上,然后在原文件处创建符号链接即可。
- 对于 innodb 存储引擎的表
因为数据文件和索引文件是存放在一起的,所以无法将它们分离。当磁盘空间出现不足时,可以增加一个新的数据文件,这个文件放在充足空间的磁盘上。
具体实现方法是在参数innodb_data_file_path 中增加此文件,路径写为新磁盘的绝对路径。
例如,如果 /home 下空间不足,希望在 /home1 下新增加一个可自动扩充数据的文件,那么参数可以这么写:
innodb_data_file_path = /home/ibdata1:2000M;/home1/ibdata2:2000M:autoextend
参数修改后,必须重启数据库才可以生效。
DNS反向解析的问题 (5.0 以后的版本默认跳过域名逆向解析)
在客户端执行 show processlist 命令,有时会出现很多进程,类似于:
unauthenticated user | 192.168.10.10:55644 | null | connect | null | login | null
这些进程会累计的越来越多,并且不会消失,应用无法正常相应,导致系统瘫痪。
MySQL 在默认情况下对于远程连接过来的 IP 地址会进行域名的逆向解析,如果系统的 hosts 文件中没有与之对应的域名,MySQL 就会将此连接认为是无效用户,所以下进程中出现 unauthenticated user 并导致进程阻塞。
解决的方法很简单,在启动时加上--skip-name-resolve选项,则 MySQL 就可以跳过域名解析过程,避免上述问题。
mysql.sock 丢失后如何连接数据库
在 MySQL 服务器本机上连接数据库时,经常会出现 mysql.sock 不存在,导致无法连接的问题。这是因为如果指定 localhost 作为一个主机名,则 mysqladmin 默认使用 Unix 套接字文件连接,而不是 tcp/ip。而这个套接字文件(一般命名为 mysql.sock)经常会因为各种原因而被删除。通过 --protocol=TCP|SOCKET|PIPE|MEMORY 选项,用户可以显式地指定连接协议,下面演示使用了 Unix 套接字失败后使用 tcp 协议连接成功的例子。
从库断电导致日志文件损坏,reset 重做
Relay log read failure: Could not parse relay log event entry. The possible reasons are: the master’s binary log is corrupted (you can check this by running ‘mysqlbinlog’ on the binary log), the slave’s relay log is corrupted (you can check this by running ‘mysqlbinlog’ on the relay log), a network problem, or a bug in the master’s or slave’s MySQL code. If you want to check the master’s binary log or slave’s relay log, you will be able to know their names by issuing ‘SHOW SLAVE STATUS’ on this slave.
mysqlbinlog --base64-output=decode-rows -vvv localhost-relay-bin.000002 > test111.sql
ERROR: Error in Log_event::read_log_event(): 'read error', data_len: 8205, event_type: 30
ERROR: Could not read entry at offset 288976935: Error in log format or read error.
WARNING: The range of printed events ends with a row event or a table map event that does not have the STMT_END_F flag set. This might be because the last statement was not fully written to the log, or because you are using a --stop-position or --stop-datetime that refers to an event in the middle of a statement. The event(s) from the partial statement have not been written to output.
重做步骤如下
mysql> stop slave;
mysql> reset slave all;
mysql> change master to master_host='192.168.2.113',master_port=3307,master_user='repl',master_password='123456',master_auto_position=1;
mysql> start slave;

















 812
812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









