







Shulin Yang, Liefeng Bo, Jue Wang, Linda Shapiro
Washington U
Two steps:
1) aligning image regions that contain the same object part
2) extracting image features within the aligned image regions
This model is learned using an alternative algorithm, which iterates between detecting aligned image regions, and updating the template model.
dataset: Caltech-UCSD Bird200 and Stanford Dogs

Learn the template and relationships between patterns.->use LBP or other methods to extract features of each template->SVM
Template model:
Score function between templates and a give image It :
衡量三个部分:
1)fitness, 某一个模板和最为相似的图像区域的相似程度。
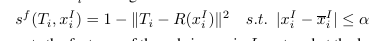
模板Ti在初始位置xi_l附近alpha范围内和该模板的匹配程度
对于同一image,对各模板的fitness求和
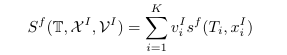
2)co-occurrence, 在同一张图像中同时出现两种模板的可能性。
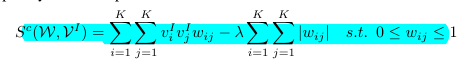
3) diversity:任意两个模板之间的距离不应太短
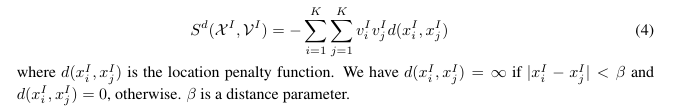
Overall score function between templates and images
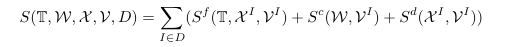
Template learning
alternating algorithm to optimize the overall score function
找出模板子集和位置
学习模板特征
学习模板间关系,权重w
总结:参数太多了,而且学习到的特征受训练集的种类影响很大,generalization ability 尚待考察。
特征层次性抽象表示?好像做不到















 2041
2041











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









