







数据分析的一般过程
- 明确项目背景,待解决的问题 ;
- 分析逻辑,画出逻辑树,明确分析过程中的指标 ;
- 提数分析,同时进行可视化 ;
- 写分析报告 ;
数据来源及内容
数据来源以及代码参考
https://www.kesci.com/home/dataset/5eb60cab366f4d002d779163
本文在原有代码的基础上进行了进一步的整合分析。
数据内容
数据内容主要是行为数据。
1.订单编号:订单编号
2.总金额:订单总金额
3.买家实际支付金额:总金额 - 退款金额(在已付款的情况下);金额为0(在未付款的情况下)
4.收货地址:各个省份
5.订单创建时间:下单时间
6.订单付款时间:付款时间(如果未付款,显示NaN)
7.退款金额:付款后申请退款的金额。未付款的退款金额为0
天猫订单分析过程
一.项目背景以及目的
对天猫一个月内的订单数据进行分析,观察这个月的订单量以及销售额。探索日期,地址等因素对订单量,退款率和销售额的影响,进而提高用户实际支付额。
目的
1.一个月内的总体趋势(订单量和金额)
2.地区对于订单量,退款率等指标的影响
3.订单转化率的漏斗分析
二.画逻辑树及分析指标
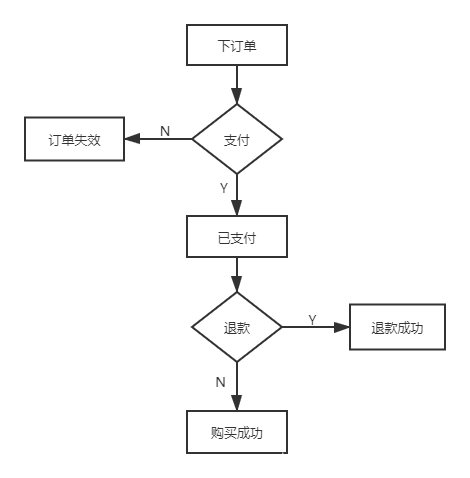
数据集的逻辑较简单,主要是从用户下订单到用户确认收货的过程,其逻辑如下图所示。涉及到的主要指标分为两种:总体运营指标和销售转化指标
电商数据分析基本指标体系:https://mp.weixin.qq.com/s/ukTmoK_fguG8_x9Q4C9ibw
总体运营指标:总订单数量,GMV(销售金额+取消订单金额+拒收订单金额+退货订单金额),销售金额和成交订单数
销售转化指标:订单数,支付数,下单支付转化率,成功订单数,退款率等。
三.数据提取及可视化
1.数据读取及处理
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import os
import warnings
warnings.filterwarnings('ignore')
读取数据
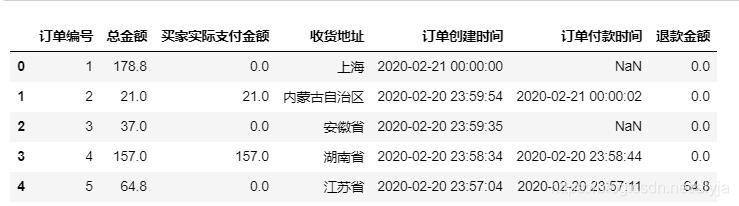
df=pd.read_csv('tmall_order_report.csv')
df.head()
数据处理
#规范字段名称
df=df.rename(columns={'收货地址 ':'收货地址','订单付款时间 ':'订单付款时间'})
#查看基本信息
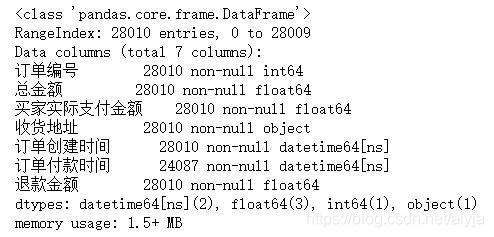
df.info()

其中,订单创建时间和订单付款时间的数据类型为object,把其转换为datetime方便后续处理
#类型转换
df['订单创建时间']=pd.to_datetime(df.订单创建时间)
df['订单付款时间']=pd.to_datetime(df.订单付款时间)
df.info()
#查看重复值
df.duplicated().sum()

#查看缺失值
df.isnull().sum()

订单付款时间为NaN表示订单未支付,为正常值。
#查看数据集描述性信息
df.describe()
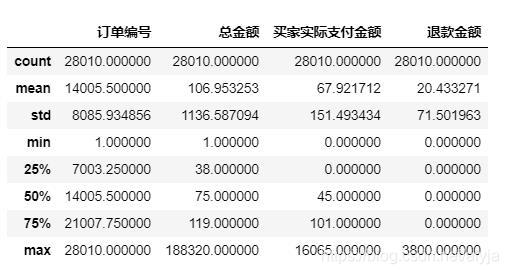
从表中可以看出,总金额的平均值为107,75%与平均值相差不大,最大值与75%相差较大,说明符合二八法则。实际支付金额和退款金额也都符合二八法则。
2.总体运营指标分析
根据是否支付,可将总订单分为已支付和未支付,在已支付数据集中根据实际支付金额来判断卖家是否有金钱到款,在已支付数据集中根据退款金额判断出订单全额到款的部分数据。
df_payed=df[df['订单付款时间'].notnull()] #支付订单数据集
df_trans=df_payed[df_payed['买家实际支付金额']!=0]#到款订单数据集
df_trans_full=df_payed[df_payed['退款金额']==0]#全额到款订单数据集
总订单数量,GMV,销售金额和成交订单数在2月的变化趋势
df['day']=df.订单创建时间.values.astype('datetime64[D]')
plt.figure(figsize=(12,12))
plt.subplot(221)
df.groupby('day').总金额.sum().plot(title='GMV')
plt.subplot(222)
df.groupby('day').总金额.count().plot(title='总订单数量')
df_trans['day']=df_trans.订单创建时间.values.astype('datetime64[D]')
plt.subplot(223)
df_trans.groupby('day').买家实际支付金额.sum().plot(title='销售金额')
plt.subplot(224)
df_trans.groupby('day').买家实际支付金额.count().plot(title='成交订单数量')
plt.tight_layout() #不让每个图的坐标轴相重叠
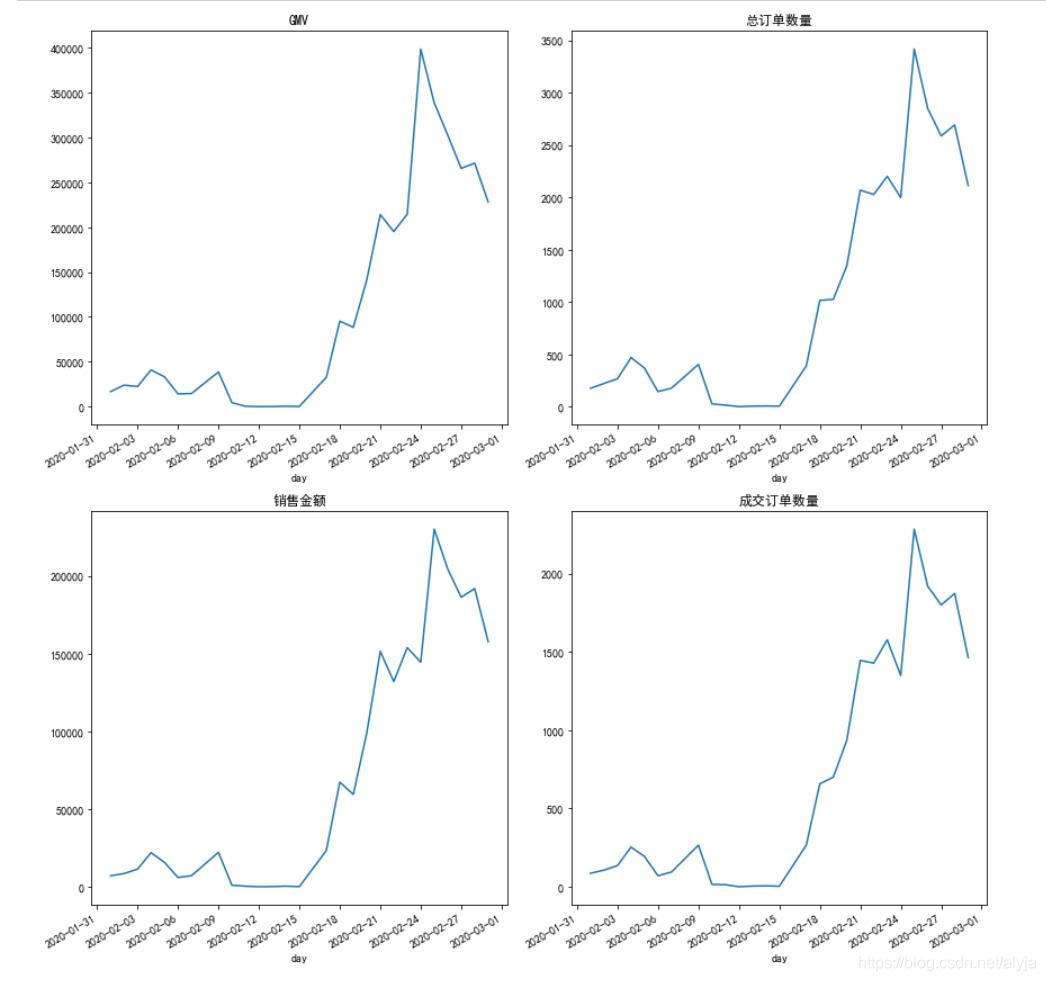
总体来看,四个指标在上半个月都偏低,下半月的数值较高。这是由于
2月上半月企业多数未复工,快递停运,无法发货;下半个月,随着企业复工逐渐增多,订单数开始上涨。
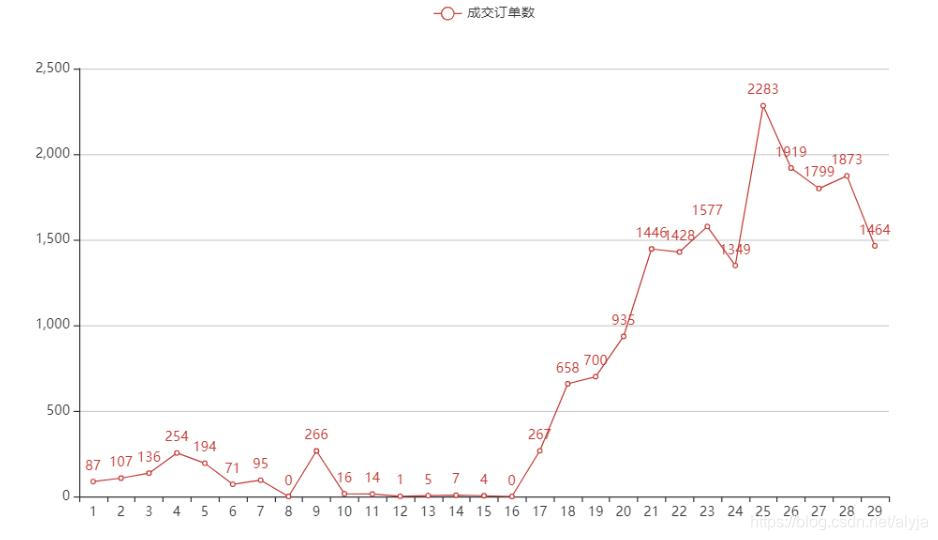
补充另一种做法以及在图像上标具体数(成交订单数):
#将订单创建时间设为index
df_trans=df_trans.set_index('订单创建时间')
#按天重新采样
se_trans_month = df_trans.resample('D')['订单编号'].count()
from pyecharts.charts import Line
#做出标有具体数值的变化图
name = '成交订单数'
(
Line()
.add_xaxis(xaxis_data = list(se_trans_month.index.day.map(str)))
.add_yaxis(
series_name= name,
y_axis= se_trans_month,
)
.set_global_opts(
yaxis_opts = opts.AxisOpts(
splitline_opts = opts.SplitLineOpts(is_show = True)
)
)
.render_notebook()
)
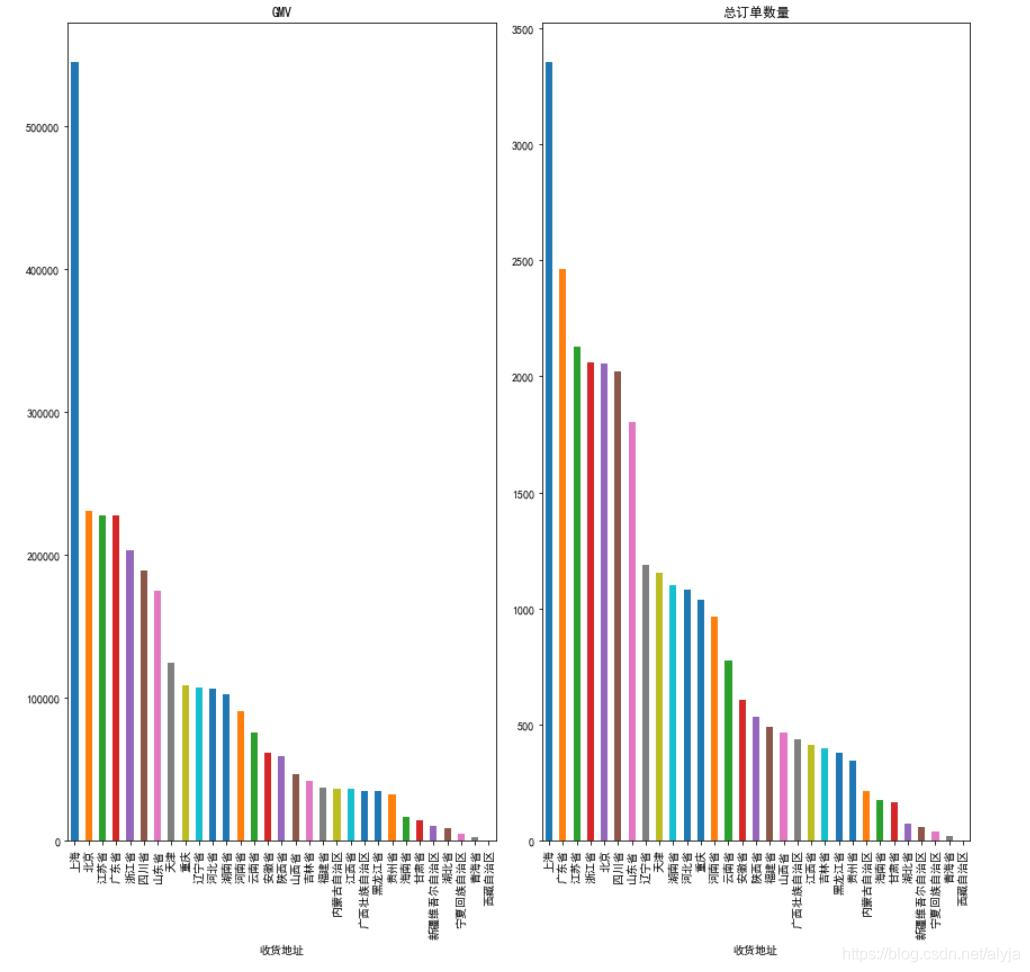
总订单数量,GMV,销售金额和成交订单数在不同地区的变化
plt.figure(figsize=(12,12))
plt.subplot(121)
fig1=df.groupby('收货地址').总金额.sum().sort_values(ascending = False).plot(kind = 'bar',title='GMV')
plt.subplot(122)
fig2=df.groupby('收货地址').总金额.count().sort_values(ascending = False).plot(kind = 'bar',title='总订单数量')
plt.tight_layout()
plt.figure(figsize=(12,12))
plt.subplot(121)
fig3=df_trans.groupby('收货地址').买家实际支付金额.sum().sort_values(ascending = False).plot(kind = 'bar',title='销售金额')
plt.subplot(122)
fig4=df_trans.groupby('收货地址').买家实际支付金额.count().sort_values(ascending = False).plot(kind = 'bar',title='成交订单数量')
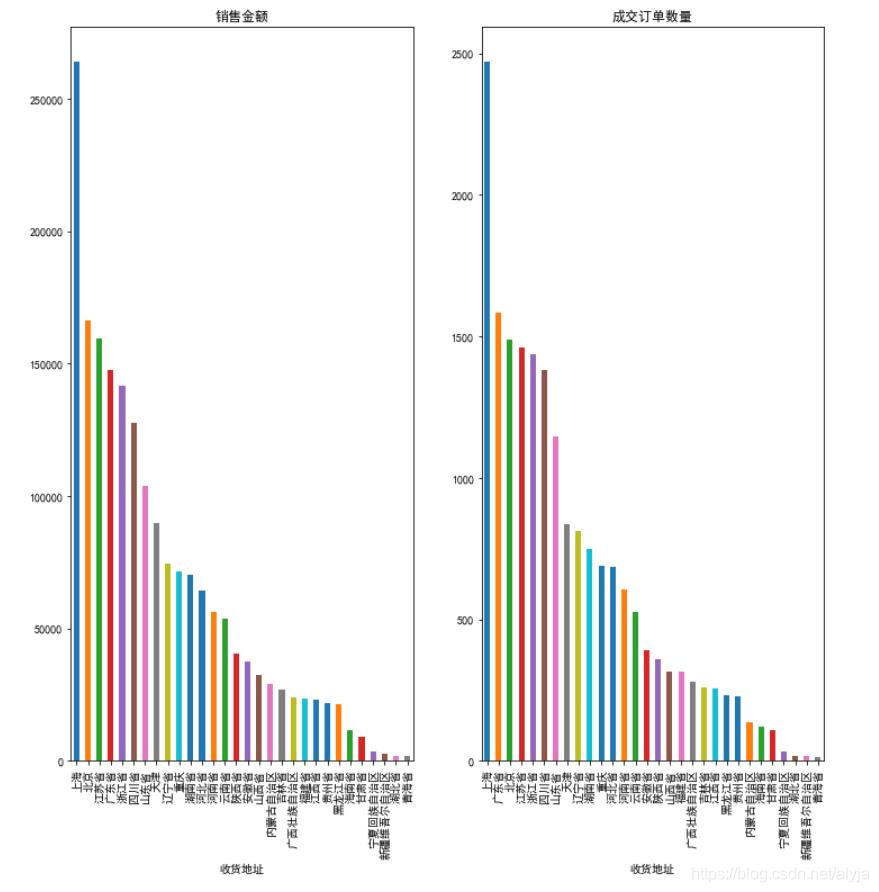
可以看出地区对订单数量和金额影响较大,一般较发达地区订单量和金额较大,边远地区较小。其中上海地区成交的金额是销售额第二多的北京的1.5倍,成交订单量是订单量第二多的广东省的1.5倍。这里可能需要具体分析每个地区的商品种类、消费群体以及优惠政策,快递等原因。可以根据原因进一步提高其他地区的订单数量和销售金额。
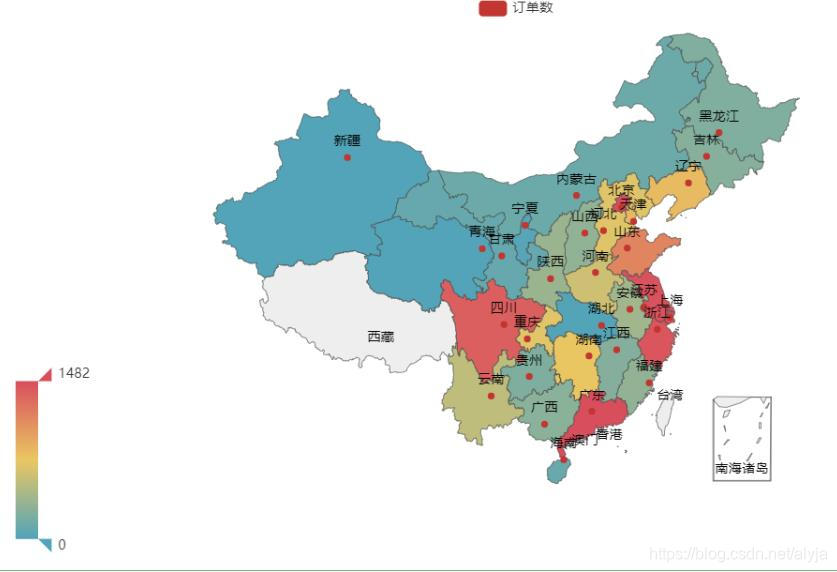
补充以更加直观的地图来观察成交订单数的变化
处理数据
se_trans_map=df_trans.groupby('收货地址')['收货地址'].count().sort_values(ascending=False)
# 为了保持由于下面的地理分布图使用的省份名称一致,定义一个处理自治区的函数
def strip_region(iterable):
result = []
for i in iterable:
if i.endswith('自治区'):
if i == '内蒙古自治区':
i = i[:3]
result.append(i)
else:
result.append(i[:2])
else:
result.append(i)
return result
# 处理自治区
se_trans_map.index = strip_region(se_trans_map.index)
# 去掉末位‘省’字
se_trans_map.index = se_trans_map.index.str.strip('省')
import pyecharts.options as opts
from pyecharts.charts import Map
# 展示地理分布图
name = '订单数'
(
Map()
.add(
series_name = name,
data_pair= [list(i) for i in se_trans_map.items()])
.set_global_opts(visualmap_opts=opts.VisualMapOpts(
max_=max(se_trans_map)*0.6
)
)
.render_notebook()
)
3.销售转化指标
转化率以及订单数的呈现
总体转换率
#前面处理过的数据集
#df_payed=df[df['订单付款时间'].notnull()] 支付订单数据集
#df_trans=df_payed[df_payed['买家实际支付金额']!=0] 到款订单数据集
#df_trans_full=df_payed[df_payed['退款金额']==0] 全额到款订单数据集
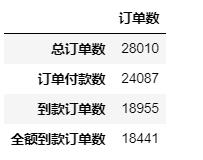
dict_convs=dict() #字典
dict_convs['总订单数']=len(df)
df_payed
dict_convs['订单付款数']=len(df_payed.notnull())
df_trans=df[df['买家实际支付金额']!=0]
dict_convs['到款订单数']=len(df_trans)
dict_convs['全额到款订单数']=len(df_trans_full)
#字典转为dataframe
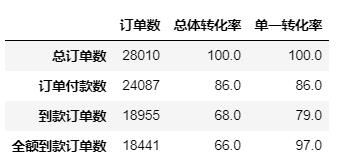
df_convs = pd.Series(dict_convs,name = '订单数').to_frame()
df_convs
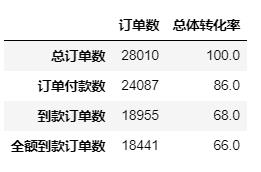
#求总体转换率,依次比上总订单数
total_convs=df_convs['订单数']/df_convs.loc['总订单数','订单数']*100
df_convs['总体转化率']=total_convs.apply(lambda x:round(x,0))
df_convs
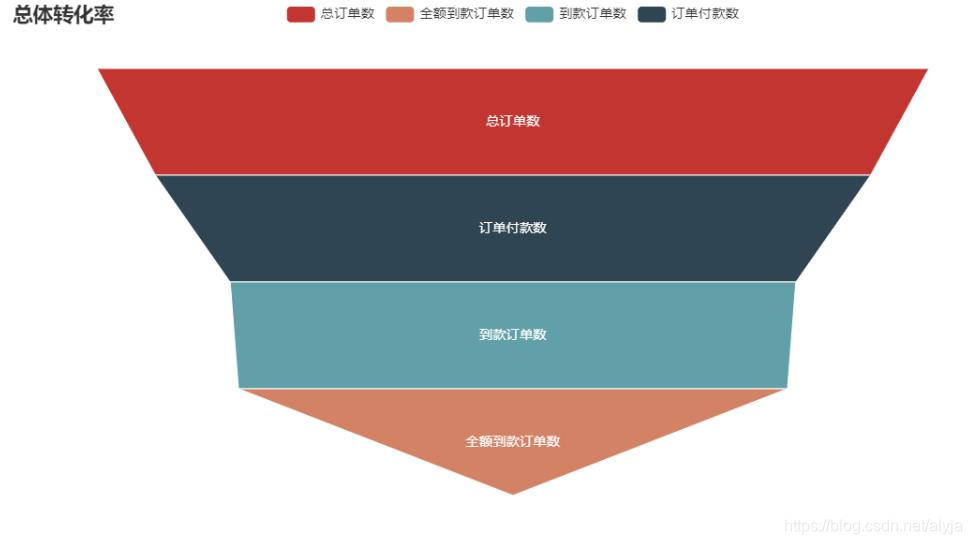
画转换率漏斗图
from pyecharts.charts import Funnel
from pyecharts import options as opts
name = '总体转化率'
funnel = Funnel().add(
series_name = name,
data_pair = [ list(z) for z in zip(df_convs.index,df_convs[name]) ],
is_selected = True,
label_opts = opts.LabelOpts(position = 'inside')
)
funnel.set_series_opts(tooltip_opts = opts.TooltipOpts(formatter = '{a}<br/>{b}:{c}%'))
funnel.set_global_opts( title_opts = opts.TitleOpts(title = name),
# tooltip_opts = opts.TooltipOpts(formatter = '{a}<br\>{b}:{c}%'),
)
funnel.render_notebook()
单一环节转化率
single_convs=df_convs.订单数/(df_convs.订单数.shift())*100
single_convs=single_convs.fillna(100)
df_convs['单一转化率']=single_convs.apply(lambda x:round(x,0))
df_convs
name = '单一转化率'
funnel = Funnel().add(
series_name = name,
data_pair = [ list(z) for z in zip(df_convs.index,df_convs[name]) ],
is_selected = True,
label_opts = opts.LabelOpts(position = 'inside')
)
funnel.set_series_opts(tooltip_opts = opts.TooltipOpts(formatter = '{a}<br/>{b}:{c}%'))
funnel.set_global_opts( title_opts = opts.TitleOpts(title = name),
# tooltip_opts = opts.TooltipOpts(formatter = '{a}<br\>{b}:{c}%'),
)
funnel.render_notebook()
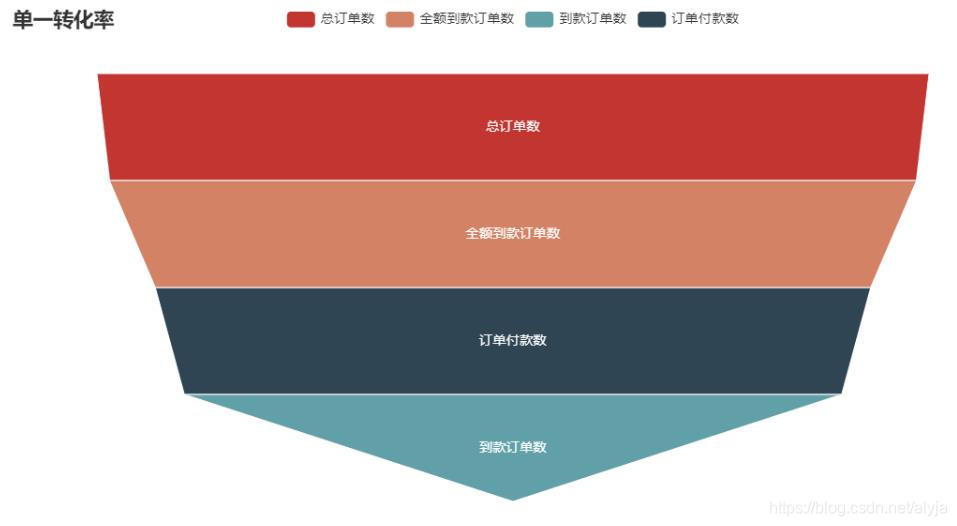
从转化率可以看出,到款-支付转换率为79%,可以从退款率下手提高转换率。
退款率的地区分布
plt.figure(figsize=(12,12))
refund=df_payed.groupby('收货地址').订单创建时间.count()-df_trans_full.groupby('收货地址').订单创建时间.count()#退款订单数
(refund/df_payed.groupby('收货地址').订单创建时间.count()).sort_values(ascending = False).plot(kind = 'bar')#退款订单数/支付订单数

从退款率分布可以看出,大部分地区都维持在20%~30%之间,湖北和新疆则是达到了60%以上。湖北退款率高的原因推测为疫情的影响,新疆退款率高的原因推测为运费贵和疫情的影响。














 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









