






1.项目背景
项目来自阿里天池数据竞赛:
以金融风控中的个人信贷为背景,根据贷款申请人的数据信息预测其是否有违约的可能,以此判断是否通过此项贷款。
2.数据探索
用pandas的read_csv函数直接读取训练集合测试集,合并至dataset,便于统一进行特种工程。
import pandas as pd
import numpy as np
df_train=pd.read_csv('train.csv')
df_test=pd.read_csv('testA.csv')
dataset=[df_train,df_test]
df_train.info()对数据缺失情况可视化
import seaborn as sns
import matplotlib.pyplot as plt
nulls=df_train.isnull().sum()/len(df_train)
nulls=nulls[nulls>0]
nulls.plot.bar()
筛选出对象类型和数值类型的数据,并过滤数值型类别特征。
# 查看特征数值类型,对象类型
# 将特征按object,number类型进行分类;numberical_fea为数值型特征,category_fea为对象特征
numerical_fea = list(df_train.select_dtypes(exclude=['object']).columns)
category_fea = list(filter(lambda x: x not in numerical_fea,list(df_train.columns)))
# category_fea = list(data_train.select_dtypes(include = ['object']).columns)
# 过滤数值型类别特征
def get_numerical_serial_fea(data,feas):
numerical_serial_fea = []
numerical_noserial_fea = []
for fea in feas:
temp = data[fea].nunique()
if temp <= 10:
numerical_noserial_fea.append(fea)
continue
numerical_serial_fea.append(fea)
return numerical_serial_fea,numerical_noserial_fea
numerical_serial_fea,numerical_noserial_fea = get_numerical_serial_fea(df_train,numerical_fea)
# 对离散型数值特征进行一个统计
i = 1
for fea in numerical_noserial_fea:
if i <= len(numerical_noserial_fea):
print(f'{fea}的汇总统计如下:')
print(df_train[fea].value_counts().sort_index())
print('----------------------分割线------------------------')
i+=1检验异常值,这里用的是箱线图里对异常点的定义,对于异常值,采取截尾的处理方式。
def fill_outliers(df,features):
for col in features:
# 1st quartile (25%)
Q1 = np.percentile(df[col], 25)
# 3rd quartile (75%)
Q3 = np.percentile(df[col],75)
# Interquartile range (IQR)
IQR = Q3 - Q1
# print (Q1,Q3)
# outlier step
outlier_step = 1.5 * IQR
df[col].loc[(df[col] < Q1 - outlier_step)]= Q1
df[col].loc[(df[col] > Q3 + outlier_step)]= Q3
# datamap[col]=[len(outlier_list_col),len(not_outlier_list_col)]
return df对连续型变量的分布做个可视化,主要是查看变量的偏态。对于偏度比较大的数据取log,尽量使之符合正态分布(变量较多,所以图片只呈现部分变量)。
# 连续型数值变量的分析
f = pd.melt(df_train,value_vars=numerical_serial_fea)
g = sns.FacetGrid(f,col="variable",col_wrap=2,sharex=False,sharey=False)
g = g.map(sns.distplot,"value")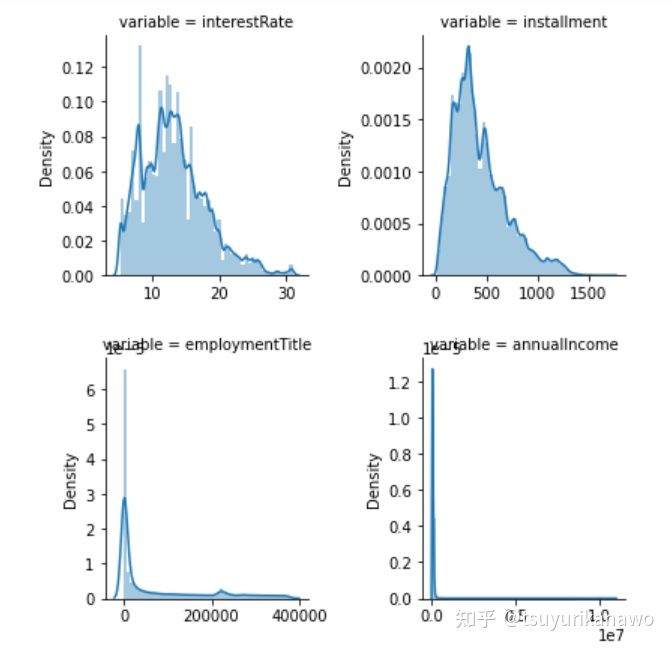
时间格式数据处理
对于时间变量,我们用每个时间减去最早出现的时间,并转化为天数或年数。把employmentLength里的年数提取出来。
#转化成时间格式
import datetime
df_train['issueDate'] = pd.to_datetime(df_train['issueDate'],format='%Y-%m-%d')
df_test['issueDate'] = pd.to_datetime(df_test['issueDate'],format='%Y-%m-%d')
startdate = datetime.datetime.strptime('2007-06-01', '%Y-%m-%d')
df_train['issueDateDT'] = df_train['issueDate'].apply(lambda x: x-startdate).dt.days
df_test['issueDateDT'] = df_test['issueDate'].apply(lambda x: x-startdate).dt.days
df_train['earliesCreditLine'] = df_train['earliesCreditLine'].apply(lambda s: int(s[-4:]))
startyear = 1944
df_test['earliesCreditLine'] = df_test['earliesCreditLine'].apply(lambda s: int(s[-4:]))
df_train['earliesCreditLine'] = df_train['earliesCreditLine'].apply(lambda x:int(x)-startyear)
df_test['earliesCreditLine'] = df_test['earliesCreditLine'].apply(lambda x:int(x)-startyear)
import re
def get_employmentLength(data):
if isinstance(data,str):
return (int(re.findall('[0-9]+',data)[0]))
else:
return None
df_train['employmentLength']=df_train['employmentLength'].map(lambda x:get_employmentLength(x))
df_test['employmentLength']=df_test['employmentLength'].map(lambda x:get_employmentLength(x))3.特征工程
先分离出离散型变量和分类变量
discrete_fea = ['term','grade','subGrade','employmentLength','homeOwnership','verificationStatus',
'purpose','regionCode','delinquency_2years','ficoRangeLow','ficoRangeHigh','pubRec',
'initialListStatus','applicationType'
]
continuous_fea = ['loanAmnt','interestRate','installment','annualIncome','issueDate','dti','openAcc',
'revolBal','revolUtil','totalAcc']填充空值,我们这里简单粗暴用中位数来取代填充。
for df in [df_train, df_test]:
j=df.isnull().sum()
null_col_df=j.to_frame().reset_index()
null_col_df.columns=['feature','nullcounts']
# 填空值
for i in range(len(null_col_df)):
if null_col_df['nullcounts'][i]>0:
# print (null_col_df['feature'][i])
df[null_col_df['feature'][i]].fillna(df[null_col_df['feature'][i]].median(),inplace = True)对高基数类别特征进行编码,其实就是取每个特征值的出现次数和id的排序。
for data in [df_train, df_test]:
for f in ['employmentTitle', 'postCode', 'title']:
data[f+'_cnts'] = data.groupby([f])['id'].transform('count')
data[f+'_rank'] = data.groupby([f])['id'].rank(ascending=False).astype(int)对低基数的分类变量,这里采取类似target encoding的方式进行编码,就是取每个特征值对应的目标变量的平均值。
for col in ['grade', 'subGrade','pubRec','regionCode']: #分类数据
temp_dict = df_train.groupby([col])['isDefault'].agg(['mean']).reset_index().rename(columns={'mean': col + '_target_mean'})
temp_dict.index = temp_dict[col].values
temp_dict = temp_dict[col + '_target_mean'].to_dict()
df_train[col + '_target_mean'] = df_train[col].map(temp_dict)
df_test[col + '_target_mean'] = df_test[col].map(temp_dict)用loanAmnt除以installment,衍生出新特征loanTerm(贷款期限)。并对loanAmnt取log,降低偏度。
for data in [df_train, df_test]:
#贷款金额/分期付款金额 = 贷款期限
data['loanTerm'] = data['loanAmnt'] / data['installment']
#手动分箱
data['pubRec'] = data['pubRec'].apply(lambda x: 7.0 if x >= 7.0 else x)
data['pubRecBankruptcies'] = data['pubRecBankruptcies'].apply(lambda x: 7.0 if x >= 7.0 else x)
df_train['loanAmnt_Log'] = np.log(df_train['loanAmnt'])
df_test['loanAmnt_Log'] = np.log(df_test['loanAmnt'])分类变量间的二阶交叉,主要是提取两个分类变量的共现次数,熵,比例偏好。
from tqdm import tqdm_notebook
import math
def entropy(c):
result=-1;
if(len(c)>0):
result=0;
for x in c:
result+=(-x)*math.log(x,2)
return result
def cross_qua_cat_num(df):
for f_pair in tqdm_notebook([
['subGrade', 'regionCode'], ['grade', 'regionCode'], ['subGrade', 'postCode'], ['grade', 'postCode'], ['employmentTitle','title'],
['regionCode','title'], ['postCode','title'], ['homeOwnership','title'], ['homeOwnership','employmentTitle'],['homeOwnership','employmentLength'],
['regionCode', 'postCode']
]):
### 共现次数
df['_'.join(f_pair) + '_count'] = df.groupby(f_pair)['id'].transform('count')
df[f_pair[1] + '_count'] = df.groupby(f_pair[1])['id'].transform('count')
df[f_pair[0] + '_count'] = df.groupby(f_pair[0])['id'].transform('count')
### n unique、熵
df = df.merge(df.groupby(f_pair[0], as_index=False)[f_pair[1]].agg({
'{}_{}_nunique'.format(f_pair[0], f_pair[1]): 'nunique',
'{}_{}_ent'.format(f_pair[0], f_pair[1]): lambda x: entropy(x.value_counts() / x.shape[0])
}), on=f_pair[0], how='left')
df = df.merge(df.groupby(f_pair[1], as_index=False)[f_pair[0]].agg({
'{}_{}_nunique'.format(f_pair[1], f_pair[0]): 'nunique',
'{}_{}_ent'.format(f_pair[1], f_pair[0]): lambda x: entropy(x.value_counts() / x.shape[0])
}), on=f_pair[1], how='left')
### 比例偏好
df['{}_in_{}_prop'.format(f_pair[0], f_pair[1])] = df['_'.join(f_pair) + '_count'] / df[f_pair[1] + '_count']
df['{}_in_{}_prop'.format(f_pair[1], f_pair[0])] = df['_'.join(f_pair) + '_count'] / df[f_pair[0] + '_count']
return (df)
df_train=cross_qua_cat_num(df_train)
df_test=cross_qua_cat_num(df_test)用决策树对连续型特征进行分箱
discrete_fea = ['term','grade','subGrade','employmentLength','homeOwnership','verificationStatus',
'purpose','regionCode','delinquency_2years','ficoRangeLow','ficoRangeHigh','pubRec',
'initialListStatus','applicationType'
]
continuous_fea = ['loanAmnt','interestRate','installment','annualIncome','issueDate','dti','openAcc',
'revolBal','revolUtil','totalAcc']
from sklearn.tree import DecisionTreeClassifier
def optimal_binning_boundary(x: pd.Series, y: pd.Series, nan: float = -999.) -> list:
'''
利用决策树获得最优分箱的边界值列表
'''
boundary = [] # 待return的分箱边界值列表
x = x.fillna(nan).values # 填充缺失值
y = y.values
clf = DecisionTreeClassifier(criterion='entropy', #“信息熵”最小化准则划分
max_leaf_nodes=6, # 最大叶子节点数
min_samples_leaf=0.05) # 叶子节点样本数量最小占比
clf.fit(x.reshape(-1, 1), y) # 训练决策树
n_nodes = clf.tree_.node_count
children_left = clf.tree_.children_left
children_right = clf.tree_.children_right
threshold = clf.tree_.threshold
for i in range(n_nodes):
if children_left[i] != children_right[i]: # 获得决策树节点上的划分边界值
boundary.append(threshold[i])
boundary.sort()
min_x = x.min()-0.1
max_x = x.max() + 0.1 # +0.1是为了考虑后续groupby操作时,能包含特征最大值的样本
boundary = [min_x] + boundary + [max_x]
return boundary
for fea in continuous_fea:
print (fea)
boundary = optimal_binning_boundary(x=df_train[fea],
y=df_train['isDefault'])
df_train[fea+'bins'] = pd.cut(df_train[fea], bins= boundary, labels=False)
df_test[fea+'bins'] = pd.cut(df_test[fea], bins= boundary, labels=False)对n开头的一系列特征,暴力提取其特征,主要有sum,mean等。
def myEntro(x):
"""
calculate shanno ent of x
"""
x = np.array(x)
x_value_list = set([x[i] for i in range(x.shape[0])])
ent = 0.0
for x_value in x_value_list:
p = float(x[x == x_value].shape[0]) / x.shape[0]
logp = np.log2(p)
ent -= p * logp
# print(x_value,p,logp)
# print(ent)
return ent
#求均方根
def myRms(records):
records = list(records)
"""
均方根值 反映的是有效值而不是平均值
"""
return np.math.sqrt(sum([x ** 2 for x in records]) / len(records))
# 求取众数
def myMode(x):
return np.mean(pd.Series.mode(x))
# 求值的范围
def myRange(x):
return pd.Series.max(x) - pd.Series.min(x)
n_feat = ['n0', 'n1', 'n2', 'n4', 'n5', 'n6', 'n7', 'n8', 'n9', 'n10', 'n11', 'n12', 'n13', 'n14', ]
nameList = ['min', 'max', 'mean', 'median']
statList = ['min', 'max', 'mean', 'median']
# dataset2 = pd.concat(objs=[df_train, df_test], axis=0).reset_index(drop=True)
for i in tqdm_notebook(range(len(nameList))):
df_train['n_feat_{}'.format(nameList[i])] = df_train[n_feat].agg(statList[i], axis=1)
df_test['n_feat_{}'.format(nameList[i])] = df_train[n_feat].agg(statList[i], axis=1)对loanAmnt进行手工分箱。
for data in [df_train, df_test]:
data['loanAmnt_bn1'] = np.floor_divide(data['loanAmnt'], 1000)
## 通过对数函数映射到指数宽度分箱
data['loanAmnt_bin2'] = np.floor(np.log10(data['loanAmnt']))
# 分位数分箱
data['loanAmnt_bin3'] = pd.qcut(data['loanAmnt'], 10, labels=False)对低基数分类变量取哑变量。
for data in [df_train, df_test]:
data = pd.get_dummies(data, columns=['subGrade', 'homeOwnership', 'verificationStatus', 'purpose', 'regionCode'], drop_first=True)对分类变量进行label encoder编码。
from tqdm import tqdm_notebook
from sklearn import preprocessing
for col in tqdm_notebook(category_fea):
le = preprocessing.LabelEncoder()
le.fit(list(df_train[col].astype(str).values) + list(df_test[col].astype(str).values))
df_train[col] = le.transform(list(df_train[col].astype(str).values))
df_test[col] = le.transform(list(df_test[col].astype(str).values))
print('Label Encoding 完成')4.数据建模
由于个人的PC性能不足,所以只用逻辑回归和xgboost两种模型。首先是xgboost模型:
from sklearn.model_selection import KFold
numerical_fea = list(df_train.select_dtypes(exclude=['object']).columns)
category_fea = list(filter(lambda x: x not in numerical_fea,list(df_train.columns)))
train_df=df_train.copy()
test_df=df_test.copy()
Y = train_df["isDefault"]
X = train_df.drop(labels = ["isDefault","id"],axis = 1)
X=X.drop(labels = category_fea, axis = 1)
test_df= test_df.drop(labels = category_fea,axis = 1)
# 去除合并数据集产生的索引列
# X_test.drop(columns="Unnamed: 0", inplace=True)
# X_train.drop(columns="Unnamed: 0", inplace=True)
#"""对训练集数据进行划分,分成训练集和验证集,并进行相应的操作"""
from sklearn.model_selection import train_test_split
import lightgbm as lgb
# 数据集划分
X_train_split, X_val, y_train_split, y_val = train_test_split(X, Y, test_size=0.25)
train_matrix = xgb.DMatrix(X_train_split , label=y_train_split)
# print (train_matrix)
valid_matrix = xgb.DMatrix(X_val , label=y_val)
# test_matrix= clf.DMatrix(test_x , label=test_x)
params = {'booster': 'gbtree',
'objective': 'binary:logistic',
'eval_metric': 'auc',
'gamma': 1,
'min_child_weight': 1.5,
'max_depth': 5,
'lambda': 10,
'subsample': 0.7,
'colsample_bytree': 0.7,
'colsample_bylevel': 0.7,
'eta': 0.04,
'tree_method': 'exact',
'seed': 2020,
'nthread': 36,
"silent": True,
}
watchlist = [(train_matrix, 'train'),(valid_matrix, 'eval')]
model = xgb.train(params, train_matrix, num_boost_round=50000, evals=watchlist, verbose_eval=200, early_stopping_rounds=200)
#"""使用训练集数据进行模型训练"""
# 对验证集进行预测
from sklearn import metrics
from sklearn.metrics import roc_auc_score
"""预测并计算roc的相关指标"""
val_pre_lgb = model.predict(xgb.DMatrix(X_val), ntree_limit=model.best_ntree_limit)
fpr, tpr, threshold = metrics.roc_curve(y_val, val_pre_lgb)
roc_auc = metrics.auc(fpr, tpr)
print('未调参前xgb单模型在验证集上的AUC:{}'.format(roc_auc))
"""画出roc曲线图"""
plt.figure(figsize=(8, 8))
plt.title('Validation ROC')
plt.plot(fpr, tpr, 'b', label = 'Val AUC = %0.4f' % roc_auc)
plt.ylim(0,1)
plt.xlim(0,1)
plt.legend(loc='best')
plt.title('ROC')
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
# 画出对角线
plt.plot([0,1],[0,1],'r--')
plt.show()运行结果以及绘制ROC曲线,得到的AUC为0.7374。

用训练好的模型预测测试集,保存csv并提交结果,得分为0.7294。
pre = model.predict(xgb.DMatrix(test_df), ntree_limit=model.best_ntree_limit)
results = pd.concat([df_test['id'],pd.Series(pre)],axis=1)
results.columns=['id','isDefault']
results.to_csv('result'+datetime.datetime.now().strftime('%Y-%m-%d %H%M%S')+'.csv',index=False)
然后是逻辑回归模型
from sklearn.model_selection import train_test_split
import sklearn.linear_model as lm
import sklearn
from sklearn.model_selection import cross_val_score,KFold
train_df=df_train.copy()
test_df=df_test.copy()
Y = train_df["isDefault"]
X = train_df.drop(labels = ["isDefault","id"],axis = 1)
X=X.drop(labels = category_fea, axis = 1)
test_df= test_df.drop(labels = category_fea,axis = 1)
X_train, X_test, y_train, y_test=train_test_split(X,Y,test_size=0.5)
lr=sklearn.linear_model._logistic.LogisticRegression()
lr.fit(X_train,y_train)
lr.score(X_test,y_test)
逻辑回归的测试集打分是0.8064,但成绩并不理想,只有0.6732,需要后续在分箱和特征筛选上进一步优化。















 2226
2226











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









