



目录
实验简介
个人信息、财务状况和贷款状态等)来训练模型,通过模型分析贷款人的偿还能力,
预测贷款申请人是否会发生违约。
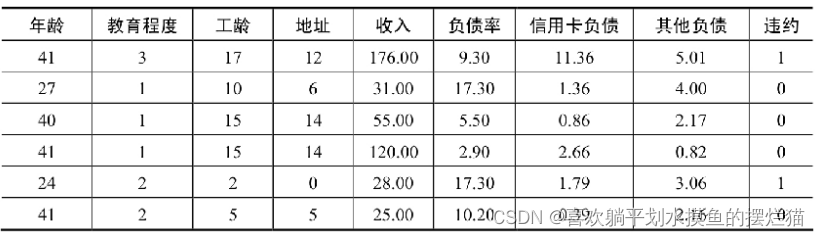
本案例采用的数据集的部分样本如表所示,该数据集共包含700条样本记录,存放在 bank-load.xls 文件中。每条记录有 8 个特征属性,1 个类别属性(是否违约)。数据集已经做过预处理,去掉了个人姓名、身份证号等唯一属性,并将所有数据都已经转换为数值型数据。
完整实验数据(需要自行提取)链接:https://pan.baidu.com/s/1joiQlsvL5q-ux3MjH44e2A
提取码:8809
一、实验目的与要求
1.掌握基于逻辑回归算法应用于实际问题的编程方法
2.掌握简单的机器学习项目开发思路和代码流程
二、实验软、硬件环境
1.硬件:PC机(参与实验的学生每人一台)
2.软件环境:Python3.7 + Pycharm
三、实验内容及主要代码
1.实验内容
贷款违约预测是现代金融机构信用风险管理的基础。为了避免贷款违约,金融机构在对借款人发放贷款的时候必须对借款人的信用程度进行评估打分,预测贷款违约的概率,并做出是否发放贷款的判断。本案例利用逻辑回归模型预测贷款人是否会发生违约行为。通过贷款数据(包括个人信息、财务状况和贷款状态等)来训练模型,通过模型分析贷款人的偿还能力,预测贷款申请人是否会发生违约。程序流程为:
(1) 导入相关模块(pandas, numpy, matplotlib, seaborn, sklearn)
(2) 定义读取数据函数(*.csv 格式)
(3) 定义特征选择函数(利用 sklearn 库中的 SelectBest 模块自动选择得分最高的特征)
(4) 定义测试逻辑回归模型的函数与模型预测函数
(5) 定义 main( )函数,内容包括读取样本,删选特征,测试模型
2.实验过程及主要代码
1)导入相关模块
import pandas # 引入pandas库用于数据加载和操作
import seaborn # 用于可视化
from matplotlib import pyplot as plt # 导入绘图相关的模块
from sklearn.feature_selection import SelectKBest # 导入从特征向量中选择部分特征的方法
from sklearn.feature_selection import chi2 # 导入卡方检验方法
from sklearn.linear_model import LogisticRegression # 用于导入逻辑回归模型
from sklearn.model_selection import train_test_split # 用于划分训练集和测试集2)定义读取数据函数
get_data(path)函数 从指定路径的CSV文件中加载数据 并根据数据的特定范围抽取数据
def get_data(path):
bank_data = pandas.read_csv(path) # 用于读取CSV文件中的数据 保存为Pandas DataFrame对象
x = bank_data.iloc[0:700, :8] # 选取了从第1行到第700行、第1列到第8列的数据作为特征集 x包含700个样本和8个特征
y = bank_data.iloc[0:700, 8] # 选取了从第1行到第700行、第9列的数据作为标签集 y包含了700个样本
return x, y # 返回特征集x和标签集y3)定义特征选择函数
screening(x, y)函数 对数据集进行特征筛选 保留最重要的特征以用于模型训练
使用卡方检验方法选择一定数量的特征 并打印出选择的特征 之所以使用卡方检验 是因为它适用于分类问题的特征选择
def screening(x, y):
selector = SelectKBest(chi2, k=4) # 使用卡方检验作为评价指标 选择重要性最高的4个特征
selector.fit_transform(x, y) # 调用了选择器的fit_transform方法 该方法会根据卡方检验对特征进行评估并选取最重要的特征
cols = x.columns[selector.get_support(indices=True)] # 获取了被选择的特征列的列名 这些列将被用于后续训练模型
print(cols) # 打印被选择的特征列名
return cols # 返回被选取的特征列名4)定义测试逻辑回归模型的函数与模型预测函数
text(x, y)函数 先使用逻辑回归模型进行训练和预测 然后对结果进行绘图 包括散点图和小提琴图
def test(x, y):
lr = LogisticRegression(solver='liblinear') # 创建逻辑回归模型实例 使用liblinear求解器
# 创建逻辑回归模型
lr.fit(x, y) # 使用输入的特征数据x和标签数据y对逻辑回归模型进行训练
print('模型的准确率为{0}%'.format('%.2f' % (lr.score(x, y) * 100))) # 计算并打印出模型的准确率
x_train, x_test, y_train, y_test = train_test_split(x, y) # 将数据集划分为训练集和测试集
y_predict = lr.predict(x_test) # 对测试集的特征数据进行预测 得到预测值
# 1.绘制测试结果的散点图
plt.figure(figsize=(14, 12)) # 图形大小为14×12
plt.subplots_adjust(hspace=.3) # 调整子图间的距离
plt.subplot(311)
plt.scatter(range(len(x_test)), y_test + 0.5, c='g', s=2, label='test')
plt.scatter(range(len(x_test)), y_predict, c='r', s=2, label='pred')
plt.title('测试结果')
plt.yticks([0, 1], ['不违约', '违约'])
plt.legend()
plt.ylim([-0.5, 2.5])
# 2. 绘制测试结果的小提琴图
# 通过pandas.concat将预测结果和测试结果连接起来
data = pandas.concat([pandas.DataFrame(y_predict, columns=['pred']),
pandas.DataFrame(y_test.tolist(), columns=['test'])], axis=1)
data = data.stack().reset_index() # 合并并分类数据
data = data.drop(columns=[data.columns[0]]) # 删除无用的数据
data = data.rename(columns={data.columns[0]: 'labels', data.columns[1]: 'value'}) # 对每一列重命名
data['xzhou'] = 1
# 小提琴图
plt.subplot(312)
plt.title('测试结果')
# 将结果使用seaborn绘制成小提琴图
seaborn.violinplot(data=data, x='xzhou', y='value', split=True, hue='labels')
plt.yticks([0, 1], ['不违约', '违约'])
plt.show()
return lr5)定义main()函数
在main()函数中会依次调用get_data()、screening()和test()函数来完成整个数据预处理和模型训练的过程
def main():
path = 'bank-loan.csv'
x, y = get_data(path)
cols = screening(x, y)
test(x[cols].values, y)3.调试过程截图
四、运行结果
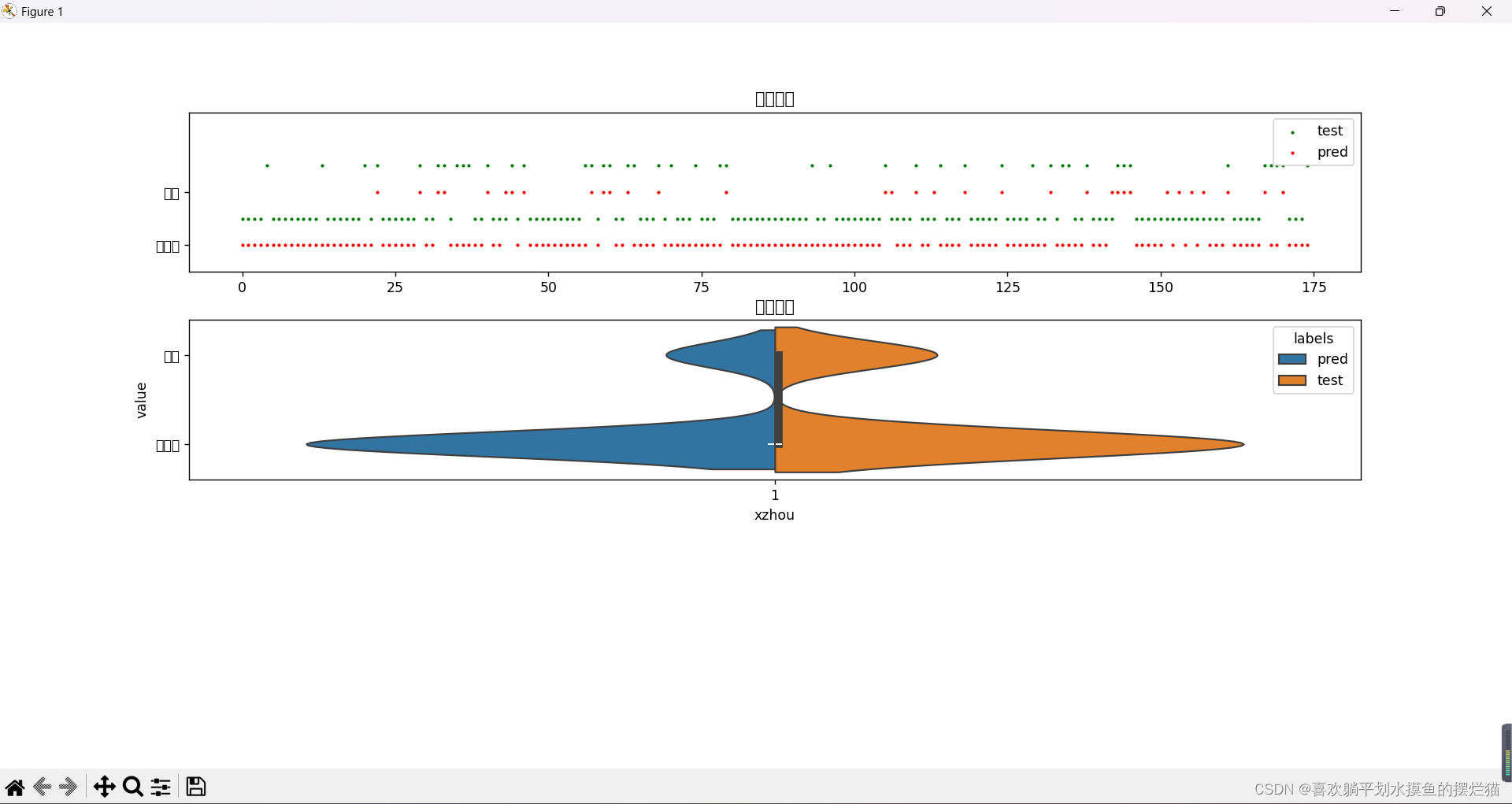
本次实验通过逻辑回归模型对银行贷款风险数据进行了分析和预测。结果显示,模型在测试集上的准确率达到了70%。但是在分析实验结果时,我们需要考虑到准确率并不是唯一衡量模型性能的标准。
通过散点图和小提琴图的分析显示,预测结果的分布情况,这有助于我们对模型预测效果有更清晰的了解。通过小提琴图,我们能够观察到预测结果在不同类别上的分布情况,帮助我们发现模型预测的偏差和准确性。
在实际应用中,70%的准确率可能会被认为是一项良好的结果。但是,我们需要注意辨别率(recall)、精确率(precision)和 F1 值等指标以获得更全面的评估。这些评估指标将帮助我们更好地理解模型的性能,尤其是在对于银行贷款风险这样的重要场景中。
综上所述,在进一步的研究中,我们应该注意到模型性能的多个方面,并且在真实场景中进行更全面的验证和测试,以便对模型的真实性能有更为准确的把握。
五 、实验总代码
import pandas
import seaborn
from matplotlib import pyplot as plt
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
def get_data(path):
bank_data = pandas.read_csv(path)
x = bank_data.iloc[0:700, :8]
y = bank_data.iloc[0:700, 8]
return x, y
def screening(x, y):
selector = SelectKBest(chi2, k=4)
selector.fit_transform(x, y)
cols = x.columns[selector.get_support(indices=True)]
print(cols)
return cols
def test(x, y):
lr = LogisticRegression(solver='liblinear')
lr.fit(x, y)
print('模型的准确率为{0}%'.format('%.2f' % (lr.score(x, y) * 100)))
x_train, x_test, y_train, y_test = train_test_split(x, y)
y_predict = lr.predict(x_test)
plt.figure(figsize=(14, 12))
plt.subplots_adjust(hspace=.3)
plt.subplot(311)
plt.scatter(range(len(x_test)), y_test + 0.5, c='g', s=2, label='test')
plt.scatter(range(len(x_test)), y_predict, c='r', s=2, label='pred')
plt.title('测试结果')
plt.yticks([0, 1], ['不违约', '违约'])
plt.legend()
plt.ylim([-0.5, 2.5])
data = pandas.concat([pandas.DataFrame(y_predict, columns=['pred']),
pandas.DataFrame(y_test.tolist(), columns=['test'])], axis=1)
data = data.stack().reset_index()
data = data.drop(columns=[data.columns[0]])
data = data.rename(columns={data.columns[0]: 'labels', data.columns[1]: 'value'})
data['xzhou'] = 1
plt.subplot(312)
plt.title('测试结果')
seaborn.violinplot(data=data, x='xzhou', y='value', split=True, hue='labels')
plt.yticks([0, 1], ['不违约', '违约'])
plt.show()
return lr
def main():
path = 'bank-loan.csv'
x, y = get_data(path)
cols = screening(x, y)
test(x[cols].values, y)
if __name__ == '__main__':
main()

















 1279
1279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









