






导读:问题分析的过程也正是技术成长之路,本文以一个gcc编译优化引发的crash为切入点,逐步展开对编译器优化细节的探索之路,在分析过程中打开了新世界的大门……
背景:一个平平无奇的crash
去年,客户提了个bug,并甩给了我们一个Segmentation fault截图,必现crash。
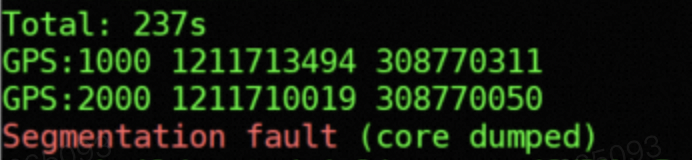
这种必现问题我根本不慌的,段错误,无非就是use after free、越界读写等导致的非法内存访问而已。平平无奇的crash,且看我分析!
一、寻找元凶
1.1 一顿分析猛如虎
经过一顿分析,最终问题锁定在了一个循环赋值函数中,
void* readTileContentIndexCallback(TileContentIndexStruct *tileIndexData, int32_t count) {
TileContentIndex* tileContentIndexList = new TileContentIndex[count];
for (int32_t index = 0; index < count; index++) {
TileContentIndexStruct &inData = tileIndexData[index];
TileContentIndex &outData = tileContentIndexList[index];
outData.urID = inData.urCode;
outData.adcode = inData.adcode;
outData.level = inData.levelNumber;
outData.southWestTileId = inData.southWestTileId;
outData.numRows = inData.numRows;
outData.numColumns = inData.numColumns;
outData.tileIndex = inData.tileContentIndex;
}
return tileContentIndexList;
}这里面赋值出了问题,导致上层访问数据的时候地址非法了。
但是这个循环赋值操作逻辑非常简单,确实看不出来有啥毛病,问题的分析一时陷入了僵局。
1.2 机智的宗翰
宗翰是我们组的一个非常机智的小伙儿。他反馈这块代码很久没改过,本次必现崩溃是因为修改了gcc编译优化级别,从O2改成O3导致的,发现修改回O2之后必现crash就不见了。
因此,问题就很明朗了,我们来看看gcc O3相比于O2做了哪些优化是不是就行了?
Optimize yet more. -O3 turns on all optimizations specified by -O2 and also turns on the following optimization flags:
-fgcse-after-reload
-fipa-cp-clone
-floop-interchange
-floop-unroll-and-jam
-fpeel-loops
-fpredictive-commoning
-fsplit-loops
-fsplit-paths
-ftree-loop-distribution
-ftree-partial-pre
-funswitch-loops
-fvect-cost-model=dynamic
-fversion-loops-for-strides
1.3 问题模拟复现
虽然知道了是编译器优化的问题,但是gcc官网上对于各个优化选项没有代码示例,只有几句解释,看着他们的解释我还是不知道我们的代码命中了哪个优化。
还好,我也很机智!
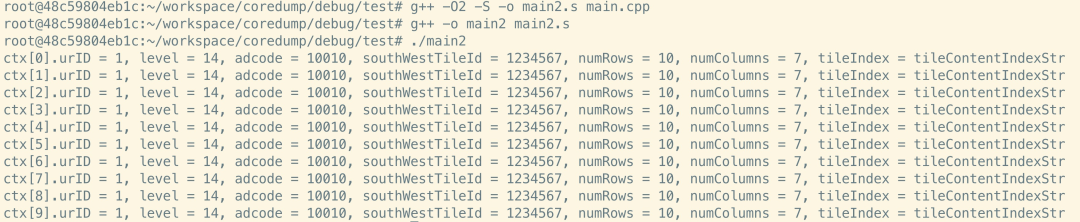
机智的我决定仿照我们出问题的代码写个小demo,然后用出问题的环境编译链去复现这个问题,具体做法如下,我写了个跟问题代码类似逻辑的demo,然后用问题环境的工具链尝试编译,先用O2试一下。
g++ -O2 -S -o main2.s main.cpp // 这个命令可以生成O2下的汇编文件
g++ -o main2 main2.s //根据汇编文件生成可执行程序main2
执行一下,发现一切正常
再用O3搞一下:
g++ -O3 -S -o mainO3.s main.cpp
g++ -o mainO3 mainO3.s
问题复现!

1.4 编译优化选项排查
先查一下当前版本gcc编译器O2和O3分别开了哪些编译优化,使用命令:
gcc/g++ -Q -O<number> --help=optimizers
例如:
gcc/g++ -Q -O2 --help=optimizers
gcc/g++ -Q -O3 --help=optimizers
差异如下(左边O3,右边O2):
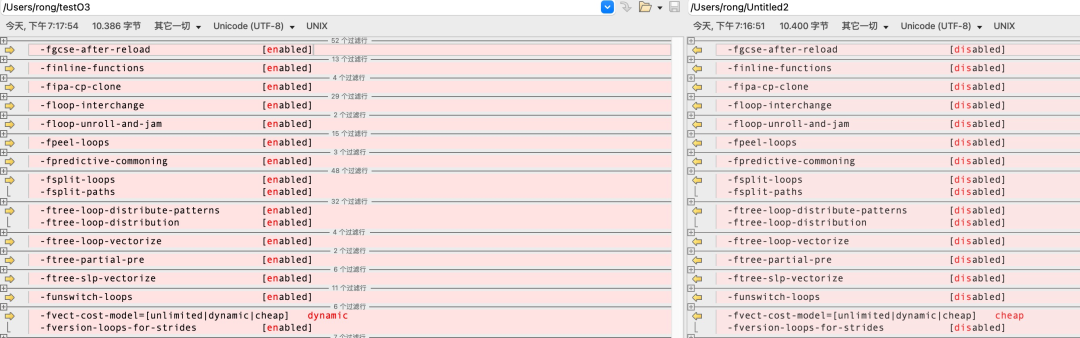
可以看到除了上面官网说的几个选项外,O3还比O2多了下面几个优化:
-ftree-loop-distribute-patterns
-ftree-loop-vectorize
-finline-functions
-ftree-slp-vectorize
其中从字面上看跟循环相关的有如下几个:
-floop-interchange
-floop-unroll-and-jam
-ftree-loop-distribution
-funswitch-loops
-fversion-loops-for-strides
-ftree-loop-distribute-patterns
-ftree-loop-vectorize
拿-ftree-loop-vectorize举例,-f表示打开某选项,改成-fno-前缀就是关闭,改成-fno-tree-loop-vectorize再查一下:

这样最差也可以挨个关闭O3默认比O2多的优化选项来确认是哪个优化选项引起的问题了~
经过简单测试发现是优化选项-ftree-loop-vectorize导致的问题,编译命令如下:
g++ -O3 -fno-tree-loop-vectorize -S -o main3t.s main.cpp // 打开O3,但是关闭tree-loop-vectorize
g++ -o main3t main3t.s // 生成可执行程序main3t
必现的崩溃不见了!!
1.5 了解-ftree-loop-vectorize
gcc官网上说这个优化选项是O2默认开启的
Perform loop vectorization on trees. This flag is enabled by default at -O2 and by -ftree-vectorize, -fprofile-use, and -fauto-profile.
这与实测不符(官网说的不准或者有版本号前提),
g++ -Q -O2 --help=optimizers|grep tree-loop-vectorize
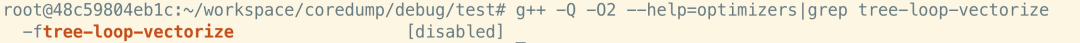
实际上问题环境中O3才会开启这个优化选项,上文说到,正是这个编译优化导致的崩溃,那么它都优化了点啥呢?官网上的描述有点少,其大体思想就是将简单的循环语句展开,减少循环体执行次数,例如如下循环赋值代码:
for (int i = 0; i < 16; i++) {
a[i] = b[i];
}可能会被优化成:
for (int i = 0; i < 16; i+=4) {
a[i] = b[i];
a[i + 1] = b[i + 1];
a[i + 2] = b[i + 2];
a[i + 3] = b[i + 3];
}通过增加循环的步长减少了循环体执行次数,提高代码效率。上述的例子中一个向量单元内部做了四个赋值,而优化之前需要执行四次循环才可以。
我们先查一下demo中哪些代码被向量化优化了,使用命令g++ -fopt-info-vec-optimized main.cpp -O3

可以看到就是循环赋值的代码(行号38)。
1.6 初获战果&战术性撤退
至此,元凶已经缉拿归案——循环向量化优化导致了本次crash。
作为SDK交付团队,我们必须跟客户的编译工具链保持一致,编译选项也需要尽可能一致,因此需要开启O3(正常release版本也应该如此),但是单独关闭tree-loop-vectorize来规避此问题。
那么,循环向量优化到底是如何导致的crash?是gcc的bug还是我们自己的代码写的有问题呢?
由于当时汇编功底过于薄弱,难以查出凶手的作案动机与详细手法,我选择了战术性撤退,回去修炼内功来日再战。
二、再探作案细节
一年后。
最近学习汇编略有所得(我觉得我又行了!!),所以再次找到了这个问题!决定把它的根因挖一挖,将凶手作案过程详细展开,昭告天下——正义虽迟但到!
2.1 重写demo复现问题
时隔一年,资料有些许散佚,遂再次构造demo复现此问题。demo代码见文末链接test2(为了方便gdb调试入参和出参用了全局变量)。
核心代码如下:
struct TileContentIndexStruct {
int32_t urCode; // 4字节
int32_t adcode; // 4字节
int32_t levelNumber; // 4字节
int32_t southWestTileId; // 4字节
int32_t numRows; // 4字节
int32_t numColumns; // 4字节
uint8_t* tileContentIndex; // 8字节
int32_t dataSize; // 4字节
//64位系统8字节对齐,填充4字节
}; // 共40字节
struct TileContentIndex {
uint16_t urID; // 2字节
uint16_t level; // 2字节
uint32_t adcode; // 4字节
uint32_t southWestTileId; // 4字节
uint16_t numRows; // 2字节
uint16_t numColumns; // 2字节(至此正好8字节对齐,无需填充)
uint8_t* tileIndex; // 8字节
}; // 共24字节
int g_rowCount = 10;
TileContentIndex g_tileContentIndexList[10]; // 被复制
TileContentIndexStruct g_tileContentVector[10]; // 源数据
void* readTileContentIndexCallback(TileContentIndexStruct *tileIndexData, int32_t count)
{
for (int32_t index = 0; index < count; index++) {
TileContentIndexStruct &inData = tileIndexData[index];
TileContentIndex &outData = g_tileContentIndexList[index];
outData.urID = (uint16_t)inData.urCode;
outData.adcode = (uint32_t)inData.adcode;
outData.level = (uint16_t)inData.levelNumber;
outData.southWestTileId = (uint32_t)inData.southWestTileId;
outData.numRows = (uint16_t)inData.numRows;
outData.numColumns = (uint16_t)inData.numColumns;
outData.tileIndex = inData.tileContentIndex;
}
return g_tileContentIndexList;
}
// 注:readTileContentIndexCallback调用时入参传的是g_tileContentVector和g_rowCount2.2 对比优化前后的汇编
优化前的汇编涉及指令较少,看起来就很轻松了。
需要注意的是readTileContentIndexCallback函数只有两个参数,所以通过寄存器传递即可。因此函数readTileContentIndexCallback的第一个参数使用的是x0寄存器传递,第二个参数使用的是x1寄存器,而w1寄存器是指x1的低32bit。
_Z28readTileContentIndexCallbackP22TileContentIndexStructi:
.LFB48:
.cfi_startproc
cmp w1, 0 // w1寄存器的值和0比较(w1对应入参count)
ble .L2 // 比较结果w1 <= 0则跳转到.L2
mov x2, x0 // x2 = x0 (x0对应入参tileIndexData)
adrp x3, .LANCHOR0 // 将.LANCHOR0高地址(低12bit清零后的地址)load到x3寄存器
add x3, x3, :lo12:.LANCHOR0 // 将.LANCHOR0低12位加到x3中,至此x3拥有了完整的.LANCHOR0,即全局变量 g_tileContentIndexList 的地址
sub w1, w1, #1 // w1减一后存入w1,w1是x1的低32bit
add x1, x1, x1, lsl 2 // 将寄存器x1的值与寄存器x1左移2位的值相加,并将结果存储回寄存器x1. 相当于将寄存器x1的值乘以5
add x0, x0, 40 // x0 = x0 + 40
add x0, x0, x1, lsl 3 // x0 = (x1 << 3) + x0
// 综合这4行相当于x0 = (x1 - 1) * 40 + (x0 + 40) = x1 * 40 + x0
.L3:
ldr w1, [x2] // w1 = tileIndexData->urCode,将寄存器x2指向的地址的值加载到寄存器w1
strh w1, [x3] // 将寄存器w1的值存储到寄存器x3指向的地址(因为强转成了uint16_t所以是半字存储,只存低16bit)
ldr w1, [x2, 4] // w1 = tileIndexData->adcode
str w1, [x3, 4] // [x3 + 4] = w1
ldr w1, [x2, 8] // w1 = tileIndexData->levelNumber
strh w1, [x3, 2] // g_tileContentIndexList.level = (uint16_t)inData.levelNumber
ldr w1, [x2, 12] // w1 = tileIndexData->southWestTileId
str w1, [x3, 8] // 存到 g_tileContentIndexList.southWestTileId
ldr w1, [x2, 16] // tileIndexData->numRows
strh w1, [x3, 12] // 存到 g_tileContentIndexList.numRows
ldr w1, [x2, 20] // tileIndexData->numColumns
strh w1, [x3, 14] // 存到 g_tileContentIndexList.numColumns
ldr x1, [x2, 24] // x1 = tileIndexData->tileContentIndex
str x1, [x3, 16] // 存到 g_tileContentIndexList.tileIndex
add x2, x2, 40 // tileIndexData++(sizeof(TileContentIndexStruct) = 40)
add x3, x3, 24 // g_tileContentIndexList++ (sizeof(TileContentIndex) = 24)
cmp x2, x0 // 比较x2和x0
bne .L3 //若x2不等于x0则跳转到.L3继续循环
.L2:
adrp x0, .LANCHOR0
add x0, x0, :lo12:.LANCHOR0 // 两行指令将.LANCHOR0的地址赋给寄存器x0
ret // 返回
.cfi_endproc
.LFE48:
.size _Z28readTileContentIndexCallbackP22TileContentIndexStructi, .-_Z28readTileContentIndexCallbackP22TileContentIndexStructi
.align 2
.global _Z15readTileContentRiPFPvP22TileContentIndexStructiE
.type _Z15readTileContentRiPFPvP22TileContentIndexStructiE, %function我果然行了,这几个汇编指令根本难不倒我,直接逐行解读完。
可以看到这个for循环就是把struct TileContentIndexStruct g_tileContentVector[10]这个数组的内容拷贝到struct TileContentIndex g_tileContentIndexList[10]这个数组中。其中sizeof(TileContentIndexStruct) = 40,sizeof(TileContentIndex) = 24。汇编中通过x0 = (x1 - 1) * 40 + (x0 + 40) = x1 * 40 + x0
将x0赋值成g_tileContentVector的地址 + 40 * count,即数组结尾地址,循环开始前x2为g_tileContentVector[0]的地址,循环中给各个结构体分量赋值,每次循环结束就执行add x2, x2, 40 让x2自增40,变成数组下一个元素的地址,直到x2 == x0时循环结束。
开启循环向量优化后的汇编见文末链接中的est_bad.S,内容较长不再逐行展开,详见下文解析。
2.3 详解优化后的汇编
2.3.1 感受循环向量化优化的威力
看汇编之前,我们先来感受下循环向量化的威力。
如下所示,进入循环赋值之前,数组g_tileContentIndexList数组所有成员还都是初始化的0,执行两行代码后,发现g_tileContentIndexList[0]~g_tileContentIndexList[3]这四个数组成员已经都有两个分量被赋值了:
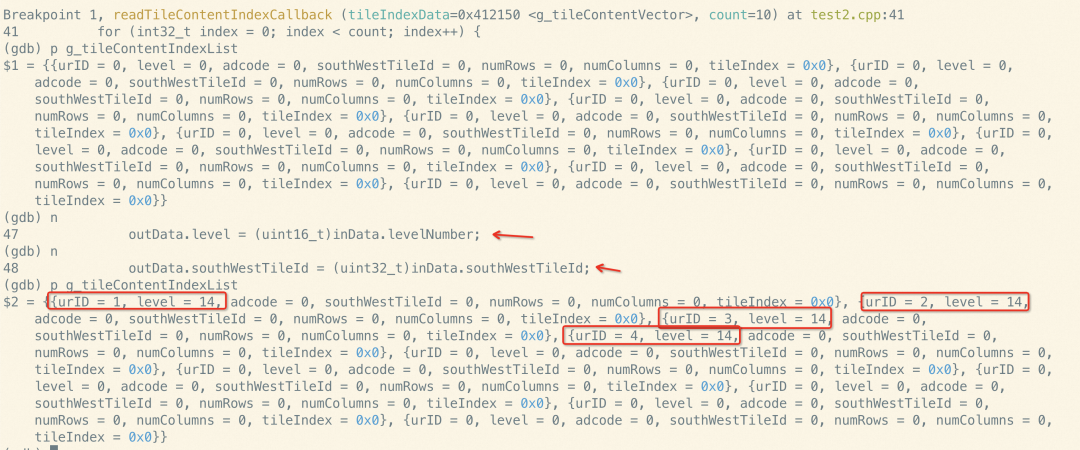
这就是循环向量化优化的威力——减少了循环的次数,一次循环就能完成4个数组成员的赋值!
2.3.2 了解汇编指令背后的寄存器逻辑
首先来看函数readTileContentIndexCallback汇编码的第一个标签.LFB48的内容。此处不再逐行解释了,其实汇编语法并不复杂,只是汇编指令不常用的话确实也记不住,但我们可以查字典,参考ARMv8 A64 Quick Reference即可。但是仅凭这些仍然不足以理解汇编指令,这只是ARM汇编大法的残本。我们还需要对arm寄存器多一些了解,建议参考官方文档网友翻译版ARMv8 寄存器(第4小节)入个门,后续再以此为跳板去看官方原始文档会容易很多。除了汇编指令表面的语法含义,我们还需要知道它背后的寄存器隐含逻辑。
需要特别指出的是armv8-A架构AARCH64 运行模式下,函数的第一个入参存在x0中,第二个入参存在x1中,通用寄存器xn是64bit,Wn表示Xn的低32bit,如果对Wn进行赋值,则Xn的高32bit会被清空。
除此之外.LFB48中还包含了很多条件操作,它们都是围绕条件标记来的。参考官方文档Condition-flags,例如CMP操作相当于做减法(SUB)只是不存储减法运算的结果,但是会影响条件标记,N (Negative) Z (Zero) C (Carry) V (overflow) 四个标志位官方解释如下,
N
Set to 1 when the result of the operation is negative, cleared to 0 otherwise.
Z
Set to 1 when the result of the operation is zero, cleared to 0 otherwise.
C
Set to 1 when the operation results in a carry, or when a subtraction results in no borrow, cleared to 0 otherwise.
V
Set to 1 when the operation causes overflow, cleared to 0 otherwise.
我们重点关注Z和C,需要注意的是C是进位标志,但是如果产生借位则会清掉C,例如,CMP x0, x1若 x0 < x1则x0 - x1产生借位,结果C=0,否则C=1,参考官方文档Carry-flag中更详细的介绍。
For a subtraction, including the comparison instruction CMP, C is set to 0 if the subtraction produced a borrow (that is, an unsigned underflow), and to 1 otherwise.
另一个需要注意的是condition code的含义,例如ARMv8 A64 Quick Reference对于CCMP指令的解释为:

即,如果cc为真则CCMP执行类似CMP的操作并影响标志位,否则标志位被置为指令设置的值f。这里的cc是condition code中的一个,表示carry clear的意思即C == 0,参考Condition Flags and Codes

NZCV这4个标志位存在寄存器CPSR的四个bit中,参考CPSR--Current-Program-Status-Register

使用gdb调试时gdb会直接展示出被置位的标记位,例如下面的C表示C=1,
(gdb) i reg cpsr
cpsr 0x20200000 [ EL=0 SS C ]
将这些文档结合起来看才算是完成了一个小周天,对于官方文档理解拿不准的,我们使用gdb设置set disassemble-next-line on后,通过ni命令单汇编指令调试,箭头指向待执行的指令(如果嫌慢可以ni <num>执行<num>条指令)结合i reg <寄存器>查看寄存器内容来实践验证。如此,理论与实践相结合后,你会发现这些汇编突然就都能看懂了!简直打通了任督二脉!!
2.3.3 了解NEON
ARMv8 A64 Quick Reference中确实包含了大部分常用指令,上一小节的方法让我们势如破竹。但是当看到.L5时,就发现了一些Quit Reference查不到的指令,例如,zip1,zip2,ins,xtn等,都查不到。
其实,这些都是NEON指令。即advanced single instruction multiple data (SIMD),所谓高级单指令多数据相关技术。NEON需要用到向量寄存器,armv8-A架构有32个向量寄存器v0~v31(也叫浮点寄存器),参考官方文档Parameters-in-NEON-and-floating-point-registers。一个向量寄存器128bit,以v0为例,如下图所示,
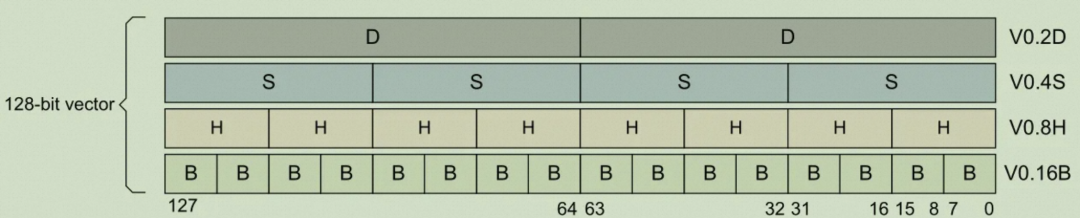
V可以分为两个D,例如V0的低64bit是D0,高64bit为{V0.D}[1](注意不是D1,D1是V1的低64bit),一个D(double word)又可以分成两个S(signal word),以此类推,又可以再分成H(half word)和B。
通常,每个NEON指令有n个并行操作,其中n就是输入向量被划分的通道/车道(lanes)数,例如V0.8H,表示8通道并行操作,add V0.8H V1.8H V2.8H表示如下效果:
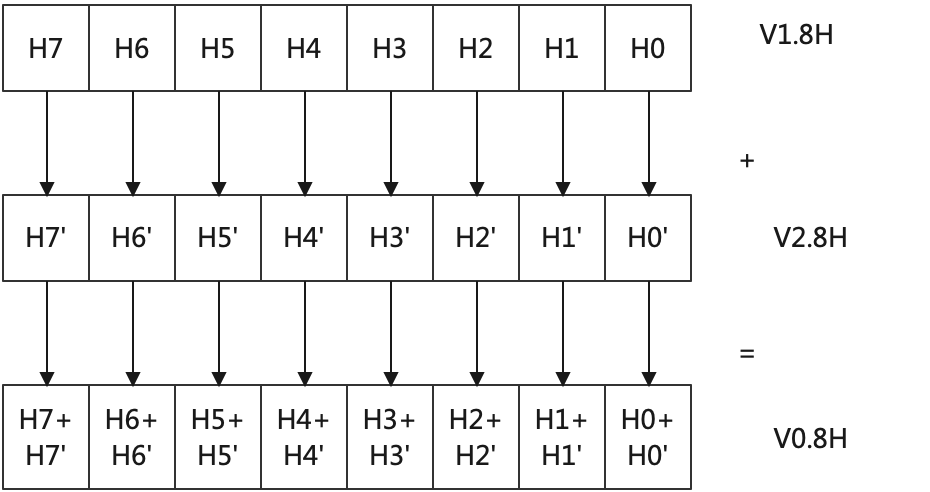
这就是SIMD的魅力,一条指令操作了多个数据!
NEON相关指令参考官方文档Arm® A64 Instruction Set Architecture,
.L5中用到的zip1、zip2效果如下,
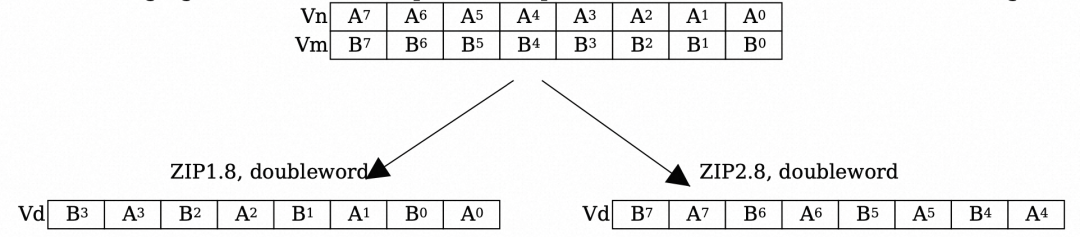
NEON技术在音视频领域算法优化场景使用广泛(想一下,这种向量或者矩阵的运算跟图像处理中的像素是不是很搭),除了编译器优化时使用外,NEON还可以通过显式地使用内部函数(intrinsic)来生效,详情参考官方文档:Neon programmers' guide。
2.3.4 继续看优化后涉及NEON的汇编
现在再来看标签.L5的内容,是不是豁然开朗。
.L5: // 之前已经做了mov x2, x0,所以此时x2中存的是入参&g_tileContentVector的地址
ldr d0, [x2] // 将x2为起始地址的8字节内存存入d0,即d0存了 g_tileContentVector[0].urCode(4字节), g_tileContentVector[0].adcode(4字节)这2个变量的值
ldr d1, [x2, 8] // d1存 g_tileContentVector[0].levelNumber(4字节),g_tileContentVector[0].southWestTileId(4字节)
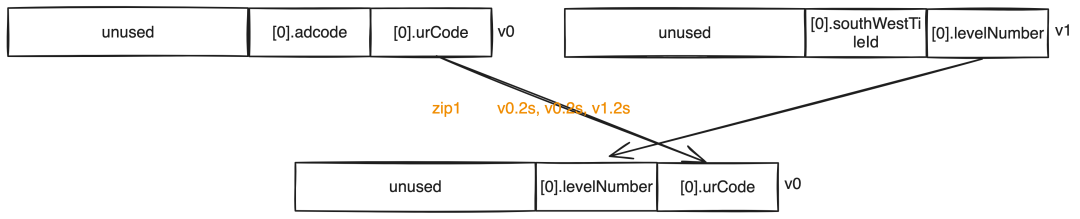
zip1 v0.2s, v0.2s, v1.2s // 见下图zip1 v0.2s, v0.2s, v1.2s效果如下(注:[0].adcode表示g_tileContentVector[0].adcode):
.L5:
...
ldr d1, [x2, 40]
ldr d2, [x2, 48]
zip1 v1.2s, v1.2s, v2.2s
ins v0.d[1], v1.d[0]
xtn v1.4h, v0.4s同理,.L5片段2,zip1 v1.2s, v1.2s, v2.2s执行之后寄存器v1内容如下(数组g_tileContentVector一个成员size是40):

ins v0.d[1], v1.d[0]效果如下(ins 是 insert 的意思):

紧接着的xtn v1.4h, v0.4s中的xtn指令表示Extract Narrow,是一个窄指令,表示将数据提取到宽度更小的寄存器中。其中的4h,4s的4表示通道 (lanes),h和s就是half-word和sigle-word的意思,执行效果如下:

这就是.L5的片段1+片段2汇编的最终目的,将入参数组前两个元素(g_tileContentVector[0]和g_tileContentVector[1])中的urCode和levelNumber存到了{v1.h}[0]~{v1.h}[3]这四个宽度是16bit的寄存器中,使用16bit寄存器的原因是我们代码中将这两个uint32_t类型的分量(urCode和levelNumber都是uint32_t)赋值给了uint16_t类型。
有了如上经验,我们接着看.L5的汇编就轻车熟路了。
.L5:
...
ldr d0, [x2, 80]
ldr d2, [x2, 88]
zip1 v0.2s, v0.2s, v2.2s
ldr d2, [x2, 120]
ldr d3, [x2, 128]
zip1 v2.2s, v2.2s, v3.2s
mov v0.8b, v0.8b
ins v0.d[1], v2.d[0]
xtn v0.4h, v0.4s显然,[x2, 80]和[x2, 120]分别是g_tileContentVector[2]和g_tileContentVector[3],因此最终xtn后结果为:

函数readTileContentIndexCallback的逻辑其实就是把数组g_tileContentVector的部分成员存入数据数组g_tileContentIndexList中,现在我们已经把g_tileContentVector[0]~g_tileContentVector[3]中的urCode和levelNumber内容存入v0和v1中了,下一步自然是将这些数据从寄存器存入出参的内存中。见.L5的片段4:
.L5:
...
mov x7, x4 // 将地址&g_tileContentIndexList存入x7
str s1, [x7], 24 // str s1, [x7] 后令 x7 = x7 + 24
st1 {v1.s}[1], [x7]
str s0, [x4, 48]
add x3, x4, 72
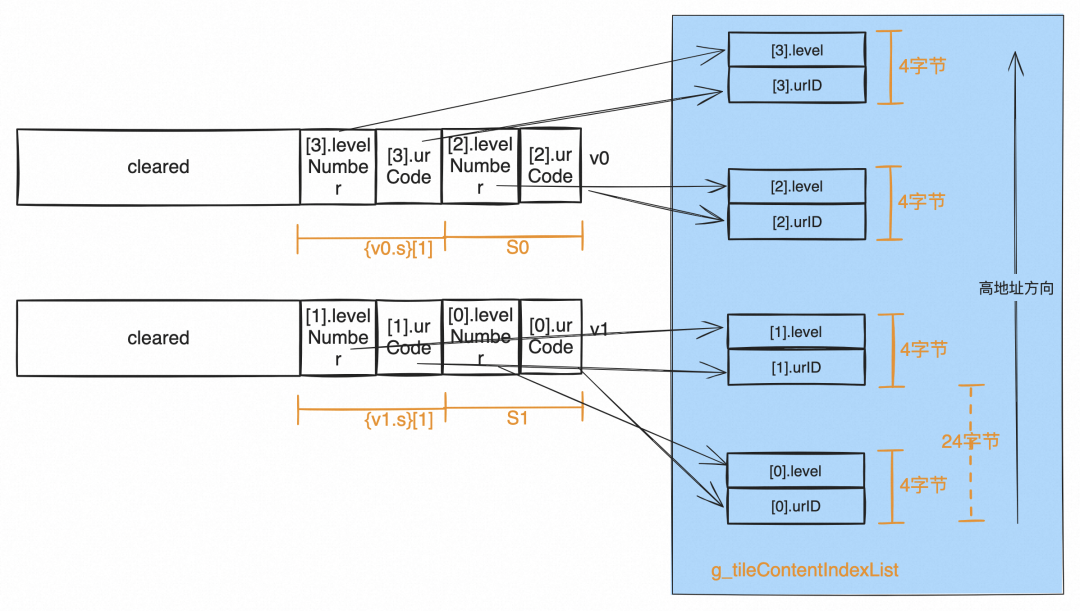
st1 {v0.s}[1], [x3]注意,在进入.L5之前,即.LFB48的结尾处,我们已经将全局变量g_tileContentIndexList的地址存入了x4中,它正是出参数组。注意出参数组成员的类型是struct TileContentIndex,大小是24字节。因此片段4执行效果如下,g_tileContentIndexList[0]~g_tileContentIndexList[3]四个元素的urID和level值都完成了赋值:
.L5:
...
ldr d2, [x2, 40]
ldr d0, [x2, 48]
zip2 v2.2s, v2.2s, v0.2s
ldr d1, [x2, 80]
ldr d0, [x2, 88]
zip2 v1.2s, v1.2s, v0.2s
ldr d0, [x2, 120]
ldr d3, [x2, 128]
zip2 v0.2s, v0.2s, v3.2s
ldr d3, [x2]
ldr d4, [x2, 8]
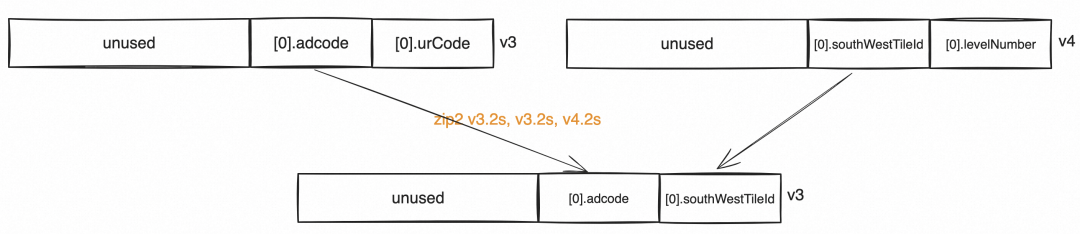
zip2 v3.2s, v3.2s, v4.2s该片段还是从入参数组g_tileContentVector[0]~g_tileContentVector[3]中取数据,我们仅以最后三行为例进行说明即可,其他同理,其效果如下,
.L5:
...
str d3, [x4, 4]
str d2, [x4, 28]
str d1, [x4, 52]
str d0, [x4, 76]因为出参的adcode和southWestTileId与入参一样都是uint32_t类型,因此不需要做类似xtn的操作,直接str即可,以str d3, [x4, 4]为例,直接将d3的内容存入了g_tileContentIndexList[0] + 4字节的内存中,因为它的前两个分量urID和level一共占用了4字节,因此需要从x4+4的地方开始存,d3寄存器为8字节,这一条指令就完成了g_tileContentIndexList[0].adcode和g_tileContentIndexList[0].southWestTileId两个变量的赋值,这就是NEON的魅力!片段6执行后g_tileContentIndexList[0]~g_tileContentIndexList[3]这四个元素的前4个分量就都完成赋值了。
.L5:
...
ldr d1, [x2, 56]
ldr d0, [x2, 16]
ins v0.d[1], v1.d[0]
xtn v1.4h, v0.4s
ldr d2, [x2, 136]
ldr d0, [x2, 96]
ins v0.d[1], v2.d[0]
xtn v0.4h, v0.4s
str s1, [x4, 12]
add x3, x4, 36
st1 {v1.s}[1], [x3]
str s0, [x4, 60]
add x3, x4, 84
st1 {v0.s}[1], [x3]这里又是熟悉的操作,因为出参使用uint16_t类型的numRows和numColumns接入参uint32_t类型的对应变量,因此又有了窄指令xtn,因为不涉及顺序交换,因此没有使用zip1和zip2指令。执行后g_tileContentIndexList[0]~g_tileContentIndexList[3]的成员numRows和numColumns就都完成了赋值,不再赘述。
至此,.L5中的NEON指令都跑完了,并没有什么异常,接着再看(必须死磕到底!!),
.L5:
...
ldr x8, [x6, 32]
ldr x7, [x6, 40]
ldr x3, [x6, 48]
ldr x9, [x6, 24]
str x9, [x4, 16]
str x8, [x4, 40]
str x7, [x4, 64]
str x3, [x4, 88]这里主要是从x6寄存器所示地址附近内存加载数据,存入x4寄存器附近内存中。x6是入参g_tileContentVector的地址,在.LFB48最后一行执行了mov x6, x0将x0赋值给了x6,x0就是第一个入参。x4上面已经说过是出参g_tileContentIndexList的地址。因此这四个ldr和str就是给g_tileContentIndexList[0]~g_tileContentIndexList[3]的最后一个成员uint8_t* tileIndex赋值了。数据源来自g_tileContentVector[0]~g_tileContentVector[3]的uint8_t* tileContentIndex成员。
万万没想到这里居然出了问题,回看demo关键代码,g_tileContentVector的成员类型是struct TileContentIndexStruct,该结构体大小是40字节:
struct TileContentIndexStruct {
int32_t urCode; // 4字节
int32_t adcode; // 4字节
int32_t levelNumber; // 4字节
int32_t southWestTileId; // 4字节
int32_t numRows; // 4字节
int32_t numColumns; // 4字节
uint8_t* tileContentIndex; // 8字节
int32_t dataSize; // 4字节
//64位系统8字节对齐,填充4字节
}; // 共40字节因此
g_tileContentVector[0].tileContentIndex~g_tileContentVector[3].tileContentIndex应该分别对应[x6, 24],[x6, 64],[x6, 104],[x6, 144]。但是上述片段汇编中却取成了[x6, 24],[x6, 32],[x6, 40],[x6, 48],除了g_tileContentVector[0].tileContentIndex以外全错了,gcc好像突然忘了这个结构体size是40字节,这里明显是按照8字节处理了。
存储的出参地址没有错,因为出参结构体TileContentIndex大小是24字节,
struct TileContentIndex {
uint16_t urID; // 2字节
uint16_t level; // 2字节
uint32_t adcode; // 4字节
uint32_t southWestTileId; // 4字节
uint16_t numRows; // 2字节
uint16_t numColumns; // 2字节(至此正好8字节对齐,无需填充)
uint8_t* tileIndex; // 8字节
}; // 共24字节出参g_tileContentIndexList[0].tileIndex~g_tileContentIndexList[3].tileIndex对应的内存正是[x4, 16],[x4, 40],[x4, 64],[x6, 88],没有问题。
我们跟踪第一个出错的数组元素g_tileContentIndexList[1].tileIndex,它的值来自x8,x8来自[x6, 32],即g_tileContentVector[0].dataSize的值。这个值是字符串tileContentIndex的长度加1,即strlen("tileContentIndexStr") + 1 = 20.这个int变量显然不是一个字符串地址,因此最终在打印函数访问字符串g_tileContentIndexList[1].tileIndex时发生了crash!
三、验证与结案
3.1 修改问题汇编代码
手动修改.S文件中的汇编指令,对偏移量计算进行修正,详情见文末链接。

另外,标签.LBE6中add x6, x6, 32 也有问题,向量化一次处理4个成员,sizeof(TileContentIndexStruct) = 40 所以此处应该把32改成40*4 = 160才对(gcc突然把size = 40的结构体当成了size = 8, 4 * 8 = 32)。
除此之外,.LBE6中将x6和x10进行比较判断是否继续进行向量化优化操作(是否继续4个4个处理),我们定义的g_rowCount = 10,只能4个4个处理两回,因此x10预期应该是x6 + 8*40,
cmp x6, x10
bne .L5因此x10赋值指令 add x10, x0, x10, lsl 5(x10 = x0 + 64,其中 64 = 8 * 8,也是把size = 40当成了8)也应该修正一下,我们将其改成 add x10, x0, 320
如下是完整patch内容:

将修改后的汇编码编译成二进制,g++ test_bad_fix_debugv3.S -o test_bad_fix_debugv3
运行结果如下:
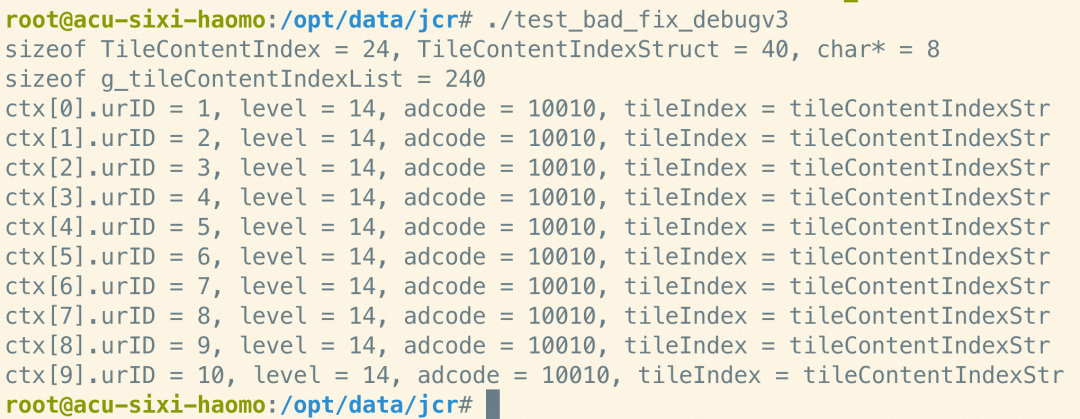
崩溃问题修复了!!
3.2 编译器横向对比
gcc突然把一个size是40字节的结构体大小算成了8字节,这么低级的错误太不可思议了。这不得不让我们再次怀疑到底是gcc的bug还是我们代码的bug?
但是这个代码仅仅是for循环中两个不同结构体数组的拷贝而已。既然我们自认代码没问题,那就控制变量——让代码不变,换一下编译器进行试验。
3.2.1 clang没问题
相同代码使用clang( version: clang-1400.0.29.102)仍编译arm64架构可执行程序,并使用#pragma clang loop vectorize(enable)使能clang的循环向量化优化。发现程序运行正常。只不过gcc循环向量优化后的编译产物是一次循环处理4个数组元素,clang是8个。
3.2.2 高版本gcc也没问题
本次出问题的gcc版本是gcc-arm-9.2-2019.12-x86_64-aarch64-none-linux-gnu,改用更高版本的gcc例如gcc-arm-10.3-2021.07-x86_64-aarch64-none-linux-gnu,发现相同代码相同编译参数下,gcc10.3并没有对其开启循环向量化优化。看到gcc10上有一些收紧循环向量化优化触发条件的patch,可能与这些修改有关,导致相同代码不再进行优化了。
3.3 结论
这就是gcc-arm-9.2版本的一个bug!
最终修复方案仍为 1.6 小节结论,即开启 O3 的前提下关闭tree-loop-vectorize。
因为代码本身没问题,没必要修改代码,并且单点修改代码后也无法评估是否还有其他地方会命中这个优化,而我们是 SDK 交付团队,无法修改编译器版本,因此只能单独关闭循环向量化优化来进行规避。
四、未完待续
本次我们追踪了一个一年陈的bug,成功回答了自己一年前的疑问,得以印证所学。但是事情远没有结束,问题分析的过程也正是技术成长之路,在行进的过程中我们打通了任督二脉,开启了代码内部的微观世界大门!
在这个世界中,有一条性能优化之路非常诱人,这条路有两个分叉,一个是编译器特性层面,另一个是ARM芯片架构指令技术层面。
4.1 编译器优化
本次我们主要遇到的是tree-loop-vectorize,即循环向量化优化。在早期,甚至有人为了性能专门来写类似思想的代码,见《短短20行经典C语言代码很多人看不明白》一文中的代码示例。在今天,我们当然不推荐大家写这种可读性不利于维护的代码。我们有编译器帮忙。但是编译器使能性能优化也是有一些触发条件的,例如tree-loop-vectorize只会在循环中内容非常简单时触发,如果demo代码的循环中指针赋值改成先分配内存再memcpy,仅仅稍微复杂了一点gcc-arm-9.2也不会对其进行循环向量化优化了。
编译器从设计之初就一直致力于优化代码,这包含二进制大小优化、代码运行性能优化等多个方面。除了tree-loop-vectorize,编译器还提供了各种各样的性能优化特性,对这些特性,尤其是那些不经意间可能用到的特性的细节深入探究,是一个很有意思和意义的课题。未完待续……
4.2 ARM芯片架构指令
编译器对性能优化的具体实现可以说是各显神通。本次示例中gcc在循环向量优化的实现中还引入了NEON技术,而在对比实验中clang对循环向量优化的实现就没用NEON(当然本次出问题的点也不是NEON)。但是编译器如何各显神通,以及各显神通时能够用上哪些底层的弹药,是一个值得探索的课题。仍以NEON为例,如果编译器实现未使用NEON,我们也可以通过显式的方式使用它,即2.3.4小节中提到的NEON内部函数(intrinsic),这在矩阵运算的算法场景中应用广泛。无论是对NEON的更深入了解还是ARM架构的其他性能优化技术的学习都是一个引人入胜的课题,未完待续……
4.3 写在最后
程序员就是一个活到老学到老的职业,无论是行业还是个人,我们的技术迭代一直未完待续……
附件地址:
https://files.alicdn.com/tpsservice/c9c5f648084bc821509305041ad99bd8.zip
关注「高德技术」,了解更多


















 395
395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









