







ICASSP

作为IEEE信号处理学会(Signal Processing Society)年度旗舰会议,ICASSP是全球声学、语音及信号处理领域规模最大的综合性国际学术会议,其影响力在语音技术研究与应用中始终处于顶尖地位。
第50届国际声学、语音与信号处理会议ICASSP(International Conference on Acoustics, Speech, and Signal Processing 2025)会议以"Celebrating Signal Processing."为主题,聚焦语音识别、语音合成、语音增强、自然语言处理、机器学习等前沿方向。
高德技术团队两篇论文分别围绕多模态大模型推理检测能力与生成式图像编辑技术研究成果入选会议论文集,欢迎交流。


Lenna: Language Enhanced Reasoning Detection Assistant
技术领域:多模态大模型、推理检测
论文地址:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=10888428

内容介绍
大语言模型(LLM)的快速发展极大地增强了其对自然语言的理解和生成能力。在这些大语言模型的助力下,多模态大语言模型(MLLM)在诸如检测、分割等感知任务,以及字幕生成、视觉问答等生成任务方面,实现了显著的性能提升。
指代表达理解任务(Referring expression comprehension,REC) 作为评估多模态大型模型自然语言理解和定位能力的关键任务,一直是许多研究的焦点。然而,模型的逻辑推理能力作为一项非常重要的理解人类隐性意图的能力,受到的关注较少。
为了促进 LLM 在感知任务中的推理能力和对世界知识的理解能力,提出了一种语言增强的推理检测助手 Lenna。如图1所示,相比于其他方法,Lenna 能够在简单和可扩展的框架中结合基于 REC 和基于推理的检测。此外,Lenna 还构建了一个名为 ReasonDet 的基准数据集来定量测量 MLLM 进行逻辑推断并对意图目标进行检测的性能。Lenna 不仅具有低廉的训练成本,并且在 REC 和 ReasonDet 上优于以前的 MLLM。
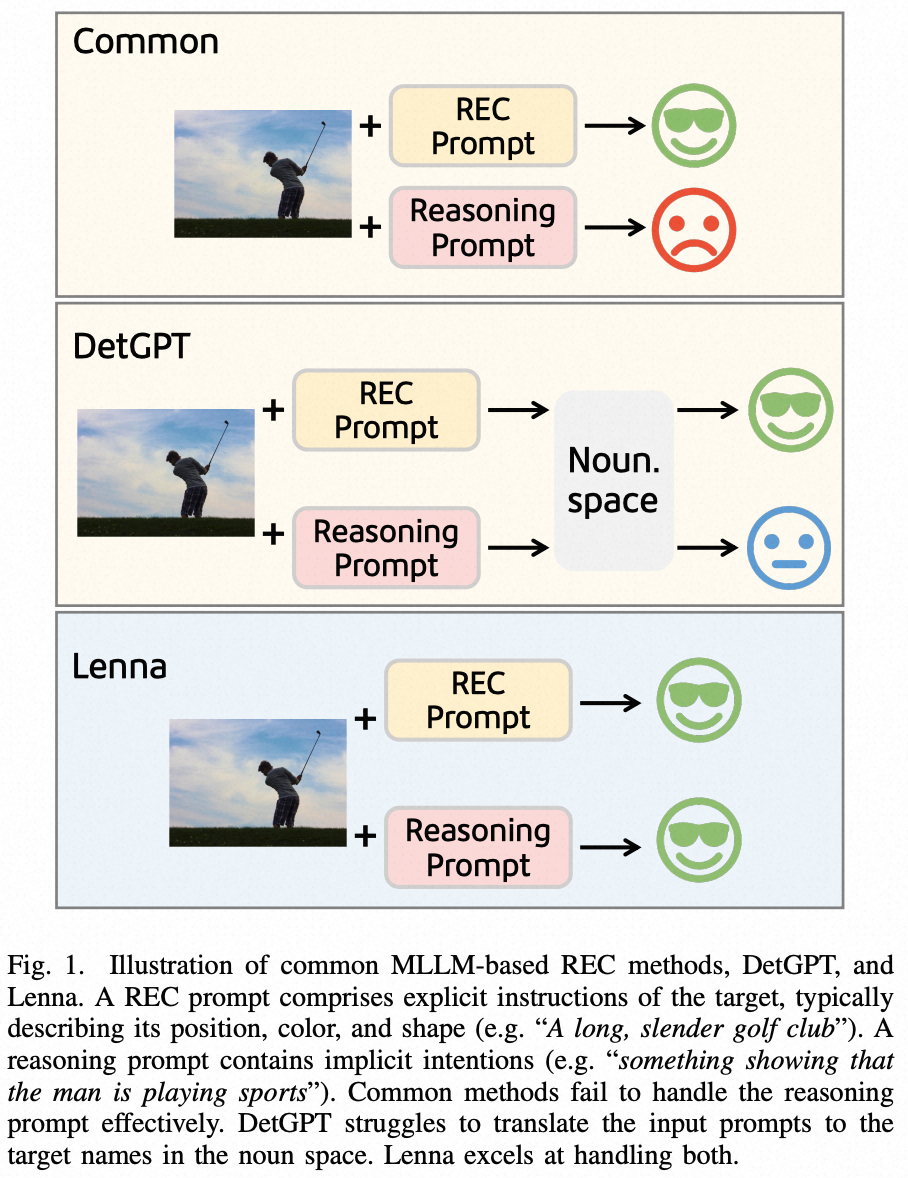
图1

模型架构
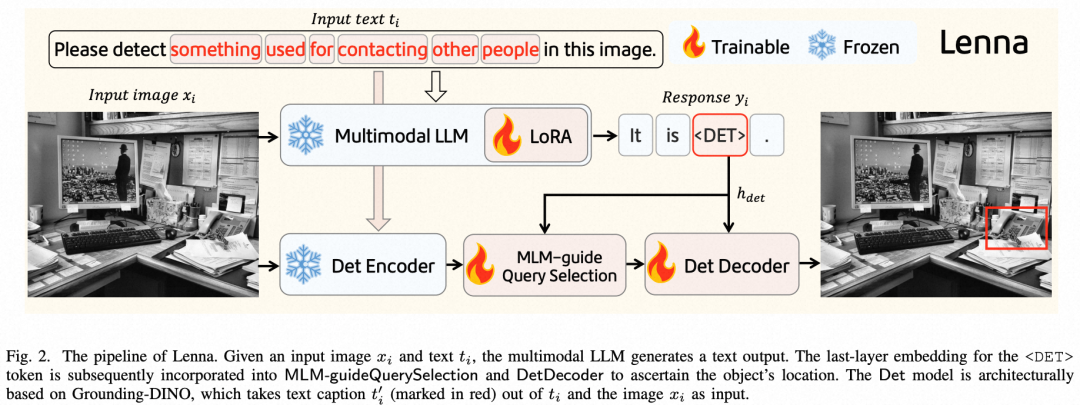
图2
Lenna(图2)通过巧妙地结合多模态大语言模型 LLaVA和开放集检测器 Grounding-DINO,并使用特殊token <DET> 扩展原始 LLM 词汇表以表示对检测输出的需求,实现了一个端到端由大语言模型增强的推理检测助手。
首先,在接收到图像xi和文本指令ti后,MLLM产生文本响应yi。
接着,提取与<DET>对应的嵌入表示hdet,该表示富含与目标相关的语义及位置信息。同时,将图像xi与目标描述(object caption, 对应图中输入文本的红色部分)输入检测器的Encoder(对应图中 Det Encoder),提取用于提取增强的图像特征fimg和文本特征ftxt。
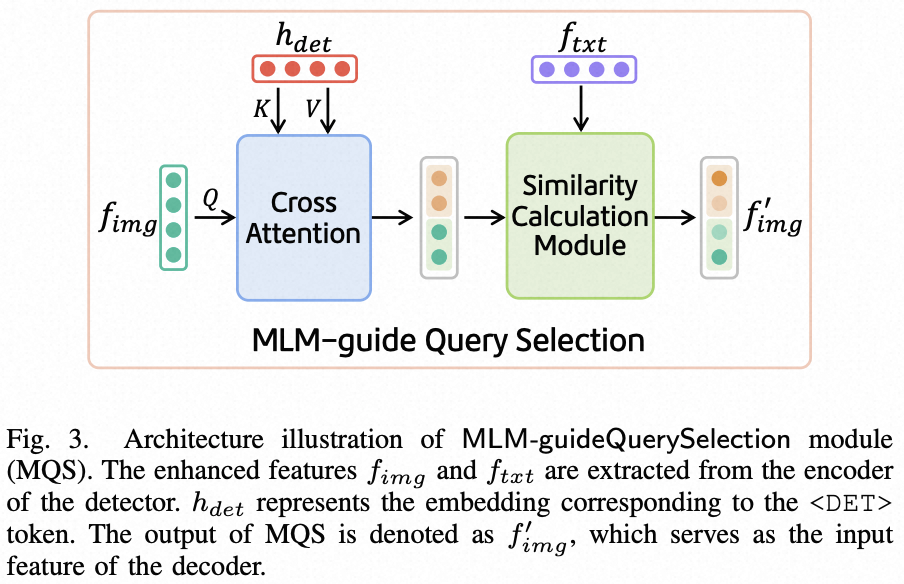
图3
获取到hdet,fimg,ftxt后,这三者输入 MSQ(MLM 引导的 query 选取)模块(如图3所示)。该模块旨在结合交叉注意模块和相似度计算模块,促进基于 BERT 与 LLM 的特征之间的跨空间对齐以及不同模态之间的对齐。在交叉注意模块中,使用hdet作为 K, V 来激活增强图像特征fimg中的对应特征。在相似度计算模块中,类似于 Grounding-DINO,选择出与输入文本特征ftxt相关性更大的特征,得到f'img。
最终,hdet被合并到解码器(对应图中Det Decoder)的每个文本交叉注意力层中,从而生成最终的位置pred。公式如下:
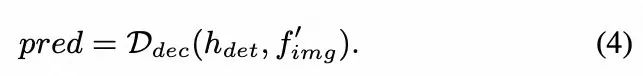
eq4
训练目标如下:
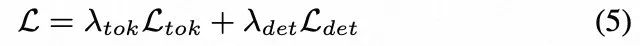
eq5
具体而言,Ltok是自回归语言建模损失,Ldet和Grounding-DINO一样使用L1 loss和GIOU loss进行边界框回归,并且使用对比学习损失进行分类,具体公式为:
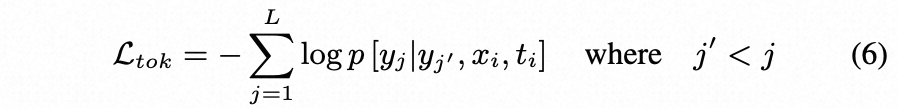
eq6
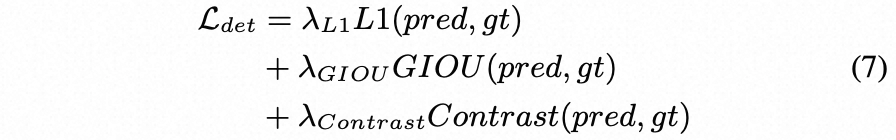
eq7

实验结果
为了保证比较的公正性,使用 IoU 为 0.5 的准确度指标在 RefCOCO、RefCOCO+ 和 RefCOCOg 上评估所有方法。如表1所示。
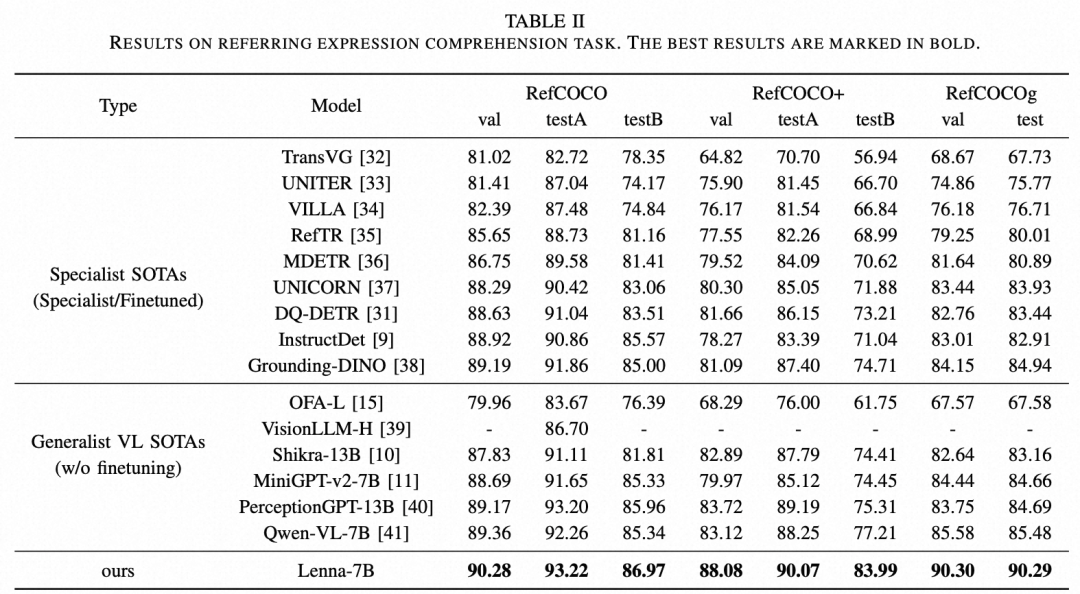
表1
ReasonDet 数据集上的定量结果如表2 所示。为了确保公平比较, Lenna (w/o RD) 从训练数据集中排除了 ReasonDet 数据。结果表明,无论在训练中是否使用 ReasonDet 数据,Lenna 都显著优于其他方法。
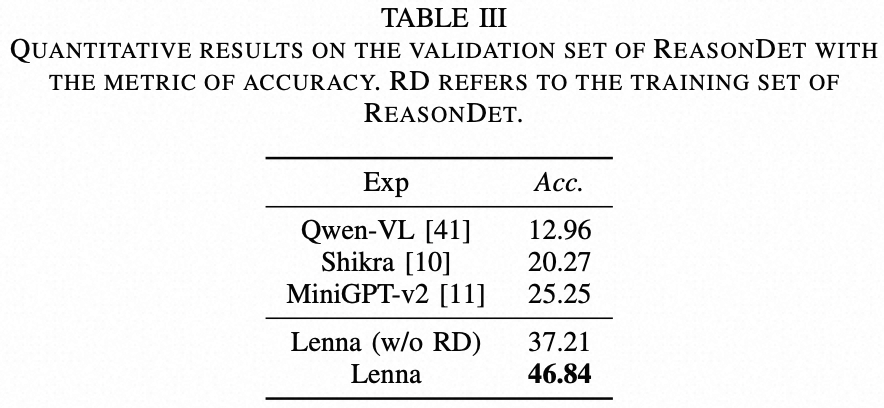
表2
Lenna (w/o RD) 比在 SOTA 中性能最佳的 MiniGPT-v2 准确率高了 47.37%,Lenna 甚至超过 85.50%。这很好地证明Lenna 可以真正理解问题中的内容并完成精确定位。

总结
Lenna作为一个新颖的框架,利用大语言模型(LLM)的表征能力和世界知识来增强目标检测任务中的推理能力。Lenna 引入了一个独特的 <DET> token,以便在不丧失推理信息的情况下进行精确定位。Lenna的不同之处在于其高效的训练和能够以低廉的额外成本扩展到各种任务的能力。其设计的简洁性使得快速适应和扩展成为可能,相较于之前的模型,在训练效率和多功能性方面展示出显著的改进。基于Lenna的训练效率和其广泛的应用潜力,希望能为未来的多模态大语言模型领域的研究和实际部署提供新的思路。

Enhancing Image Editing with Chain-of-Thought Reasoning and Multimodal Large Language Models
技术领域:图像编辑
论文地址:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=10890562

内容介绍
在日常生活中,图像编辑通常需要模型首先理解用户意图,然后进行编辑。尽管图像编辑技术取得了显著进步,但理解和执行复杂的指令仍然是一个重大挑战。现有的图像编辑模型要么无法理解复杂的意图,要么在处理多个对象时出错。为了解决这些挑战,我们提出了一种创新的图像编辑框架,它利用Chain-of-Thought(CoT)推理和多模态大语言模型(LLMs)的定位能力来帮助扩散模型生成更精致的图像。我们精心设计了一个CoT过程,包括指令分解、区域定位和详细描述。我们训练模型学习CoT过程和编辑图像的掩模。通过向扩散模型提供生成的提示和掩模,我们的模型能够以更高的指令理解能力编辑图像。大量的实验表明,我们的模型在图像生成方面在定性和定量上都超越了现有最先进的模型。特别是,我们的模型在理解复杂提示和生成相应图像方面表现出增强的能力。

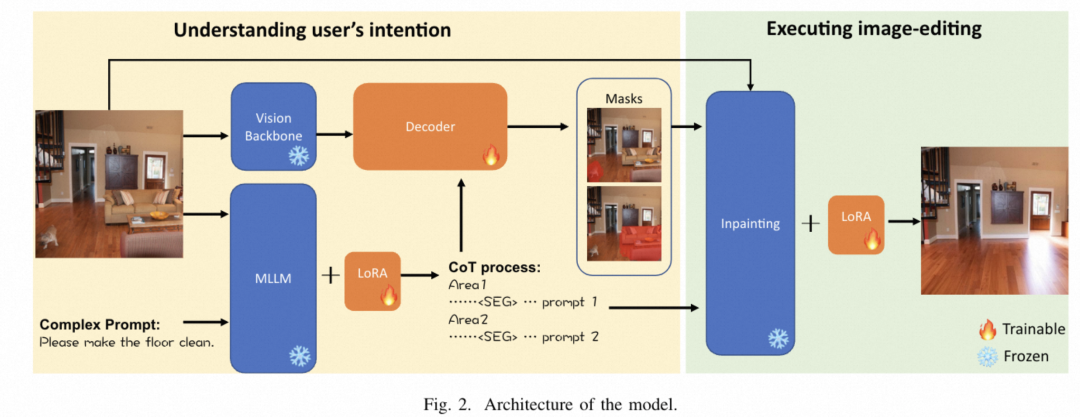
模型架构
1.图像和复杂的提示被输入到多模态大型语言模型(MLLM)中。
2.输出是一个思维链(CoT)过程,该过程将复杂的提示分解为几个简单的提示。
3.每个简单的提示包含一个新的标记,即[SEG],它响应分割请求,并将它的嵌入输入到解码器中,以产生最终的分割掩码作为M。
4.每个简单的提示还包括相应的修复提示P。
5. 然后,将原始图像、预测的掩码M和相关编辑区域的修复提示P发送到强大的修复模型inpainting中。这种架构利用MLLM进行复杂的提示理解,并通过CoT过程将其分解为更简单的任务,然后使用专门的修复模型进行图像编辑。

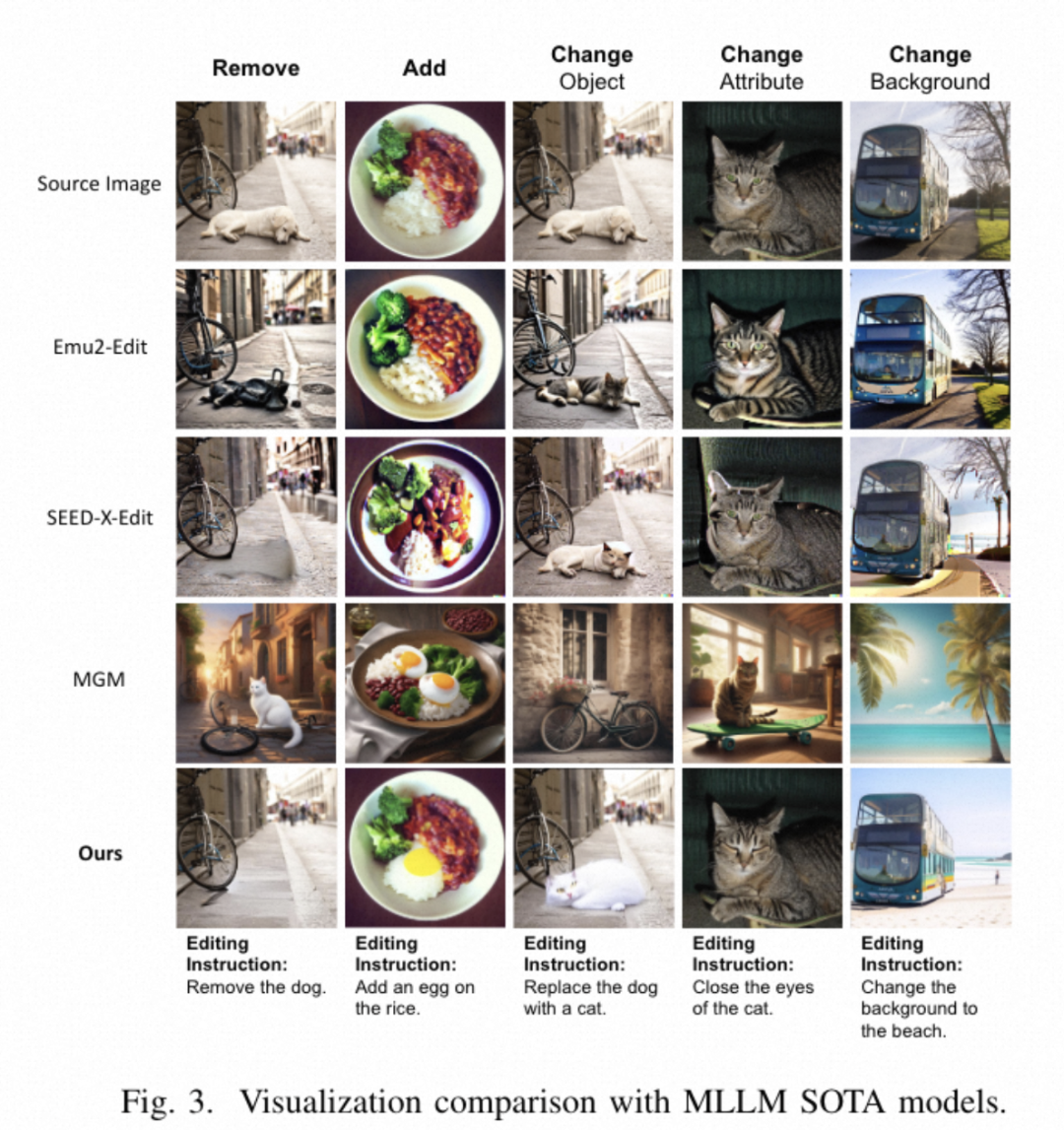
实验结果
该研究提出的图像编辑框架在多个方面优于现有的最先进模型。具体来说,实验结果展示了以下几点:
复杂指令遵循能力:该模型在遵循复杂指令方面表现出色。相较于纯扩散模型和基于多模态大型语言模型的生成模型,该模型能够更准确地执行编辑操作,减少编辑操作的丢失或混淆。
编辑前后的图像一致性:在编辑前后图像的一致性方面,该模型也表现出了优势。其他模型在编辑前后图像之间存在显著差异,而该模型能够更精确地修改指定区域,保持编辑前后的图像一致性。


总结
本文提出了一种创新的图像编辑框架,该框架结合了链式思考(Chain-of-Thought, CoT)推理和多模态大型语言模型(Multimodal Large Language Models, MLLMs)的区域定位能力,以协助扩散模型生成更精细的图像。通过精心设计的CoT过程,包括指令分解、区域定位和详细描述,模型能够学习CoT过程和编辑图像的掩码。通过为扩散模型提供生成的提示和掩码,模型能够以对指令的更深入理解来编辑图像。实验结果表明,与现有的最先进模型相比,本文提出的模型在图像生成方面在质量和数量上都表现更优。特别是,该模型在理解复杂提示和生成相应图像方面的能力得到了显著提升。
往期推荐

📚CVPR 2025 Highlight|HumanRig:3D数字人黑科技,解锁更智能的3D角色动画框架
📚CVPR 2025|突破自动驾驶"交规困境":高德车道级交通规则在线理解,让AI更懂交规!


















 688
688

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









