







字符串的驻留机制
字符串
在Python中字符串是基本数据类型,是一个不可变的字符序列
什么叫字符串的驻留机制?
仅保存一份相同且不可变字符串的方法,不同的值被存放在字符串的驻留池中, Python的驻留机制对相同的字符串只保留一份拷贝,后续创建相同字符串时,不会开辟新空间,而是把该字符串的地址赋给新创建的变量
a = 'python'
b = 'python'
c = 'python'
print(a, id(a))
print(b, id(b))
print(c, id(c))
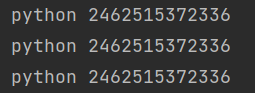

要注意pycharm对内容进行了强制处理,即在pycharm中不符合标识符命名的字符串也会产生驻留
驻留机制的优缺点

字符串的常用操作
字符串查询操作的方法

尽量使用后两个方法进行查询,否则会抛异常
字符串的大小写转换操作

upper()
s = 'hello,python'
a = s.upper()
print(a)
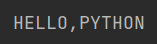
原来的字符串并没有发生改变,相当于取值赋给一个新的对象,对不可变序列进行操作后会产生一个新的不可变序列
lower( )
与upper()同理,如果本身就是小写,使用此方法后不改变字符串内容,但是会产生一个新的字符串
s = 'hello,python'
b = s.lower()
print(b,id(b))
print(s,id(s))

swapcase()
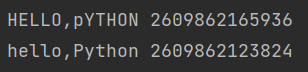
s = 'hello,Python'
b = s.swapcase()
print(b,id(b))
print(s,id(s))
title()
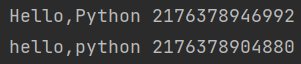
s = 'hello,python'
b = s.title()
print(b,id(b))
print(s,id(s))
字符串内容对齐操作

center( )
s = 'hello,python'
print(s.center(20,'@'))

ljust()
s = 'hello,python'
print(s.ljust(20,'@'))
print(s.ljust(20))
print(s.ljust(10))
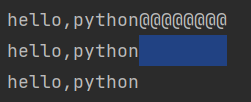
rjust()
s = 'hello,python'
print(s.rjust(20,'@'))
print(s.rjust(20))
print(s.rjust(10))
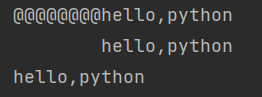
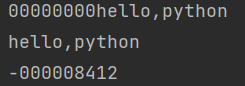
zfill()
右对齐,使用零填充
s = 'hello,python'
print(s.zfill(20))
print(s.zfill(10))
print('-8412'.zfill(10))
字符串的劈分操作

split( )
没有指定分割符默认为空格.
s = 'hello word python'
lst = s.split()
print(lst)

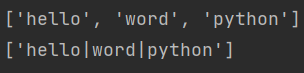
sep可以指定分割符,若没有索要分割的字符,则返回原字符串
s = 'hello|word|python'
lst = s.split(sep='|')
lst1 = s.split()
print(lst)
print(lst1)
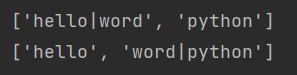
maxsplit可以指定分割的最大次数,达到最大次数之后便不再分割返回剩余字符串
s = 'hello|word|python'
lst = s.split(sep='|',maxsplit=1)
print(lst)
print(s.split(sep='|'))
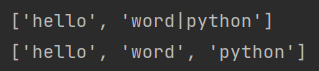
rsplit( )
返回结果仍然是从左到右的列表,与split()的区别在于使用了maxsplit()之后的返回的值不一样
s = 'hello|word|python'
print(s.rsplit(sep='|',maxsplit=1))
print(s.split(sep='|',maxsplit=1))
判断字符串操作的方法

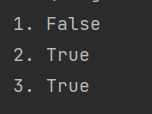
isidentifier()
判断指定字符串是否为合法标识符
s = 'helios,python'
print('1.',s.isidentifier())
print('2.','hello'.isidentifier())
print('3.','sadsa_123'.isidentifier())
其余与表中介绍功能相同,不再一一赘述
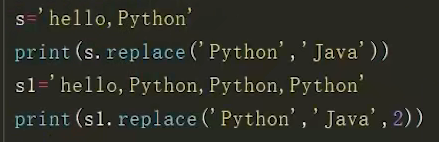
替换与合并

replac()
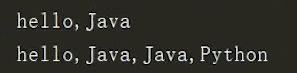
join()
需要注意的是,如果join()里面是个字符串,那么会将每个字符分别用所指定的字符链接
如:
print('*'.join('python'))
字符串的比较操作
首先大致讲述一下比较操作的使用符号和比较原理

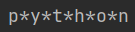
print('apple' > 'app')
print('apple' > 'sad')
print(ord('a'), ord('b')) # 相当于97>98,所以错误
print(chr(97), chr(98)) # 可知chr和ord为相反的操作
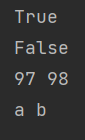
还需要注意的是,==判断的是value是否相等,而is判断的是id是否相等,如下:
a = b = 'python'
c = 'python'
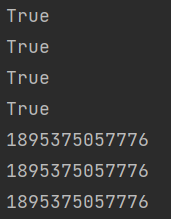
print(a == b)
print(b == c)
print(a is c)
print(b is c)
print(id(a))
print(id(b))
print(id(c))
字符串的切片操作
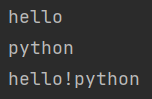
s = 'hello,python'
s1 = s[:5] # 由于没有指定起始位置,所以从零开始切
s2 = s[6:] # 由于没有指定结束位置,所以会切到字符串的最后一个元素
s3 = '!'
newstr = s1+s3+s2
print(s1)
print(s2)
print(newstr)
切片的一般操作[start:end:step]如果没有指定start将会从0开始切,如果没有指定end将会切到最后一个元素,如果没有指定step将会默认步长
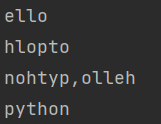
s = 'hello,python'
print(s[1:5:1]) # 从1开始截到5注意不包含5,步长为1
print(s[::2]) # 默认从0开始,没有写结束默认到最后一个元素,两个元素之间索引间隔为2
print(s[::-1]) # 默认从最后一个元素开始,到第一个元素结束,因为步长为负数
print(s[-6::]) # 从索引为-6开始到字符串最后一个结束,步长为1
格式化字符串

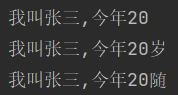
# 1.使用%做占位符
name = '张三'
age = 20
print('我叫%s,今年%d' % (name,age))
# 2.
print('我叫{0},今年{1}岁'.format(name,age))
# 3.
print(f'我叫{name},今年{age}岁')
确定字符串的宽度和精度
使用%
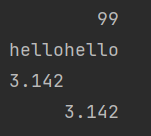
print('%10d' % 99) # 10表示的是宽度
print('hellohello')
print('%.3f' % 3.1415926) # 保留三位小数
# 同时表示宽度和精度
print('%10.3f' % 3.1415926) # 一共总宽度为10,小数点后3位
使用{ }
print('{0:.3}'.format(3.1415926)) # 表示一共是三位数
print('{0:.3f}'.format(3.1415926)) # .3f表示的是三位小数
print('{0:10.3f}'.format(3.1415926)) # 同时设置精度和宽度,一共是10位,三位是小数

字符串的编码转换















 430
430











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









