






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
本文作者:AdamLau | 来源:知乎(已授权)
https://zhuanlan.zhihu.com/p/355299643
论文阅读:Medical Transformer: Gated Axial-Attention for Medical Image Segmentation

论文:https://arxiv.org/abs/2102.10662
代码(已开源):
https://github.com/jeya-maria-jose/Medical-Transformer
CNN网络在提取底层特征和视觉结构方面有比较大的优势。这些底层特征构成了在patch level 上的关键点、线和一些基本的图像结构。这些底层特征具有明显的几何特性,往往关注诸如平移、旋转等变换下的一致性或者说是共变性。比如,一个CNN卷积滤波器检测得到的关键点、物体的边界等构成视觉要素的基本单元在平移等空间变换下应该是同时变换(共变性)的。CNN网络在处理这类共变性时是很自然的选择。
但当我们检测得到这些基本视觉要素后,高层的视觉语义信息往往更关注这些要素之间如何关联在一起进而构成一个物体,以及物体与物体之间的空间位置关系如何构成一个场景,这些是我们更加关心的。目前来看,transformer在处理这些要素之间的关系上更自然也更有效。
Motivation
卷积神经网络缺乏对映像中存在的远程依赖项进行建模的能力。
当分割的mask较大时,学习与该mask相对应的像素之间的远程依存关系也有助于做出有效的预测。
该文章探索了将仅在自注意力机制上工作的Transformer结构用作医学图像分割的编码器而无需进行任何预训练的可行性。
由于医学影像的数据较少,且标注也需耗费大量时间,本文设定了门控位置敏感的轴向注意机制,引入了四个门来控制对key,query和value的位置嵌入供应的信息量。这些门是可学习的参数,这使得所提出的机制可以应用于任何大小的任何数据集。根据数据集的大小,这些门将了解图像数量是否足以学习适当的位置嵌入。
此外,本文提出了局部全局(LoGo)训练策略,在该策略中,本文使用了浅层的全局分支和深层的局部分支来对医学图像的patch进行操作。这种策略可提高分割效果,因为不仅对整个图像进行操作,而且专注于局部patch中存在的更精细的细节。
提出了MedT网络,基于gated position-sensitive axial attention mechanism和局部全局(LoGo)训练策略。
Overview
encoder部分如下图b所示,用了残差结构。两个多头注意力block结果concat起来,一共有八个门控头。
decoder部分还是卷积层+上采样+ReLU激活,外加跳跃连接。
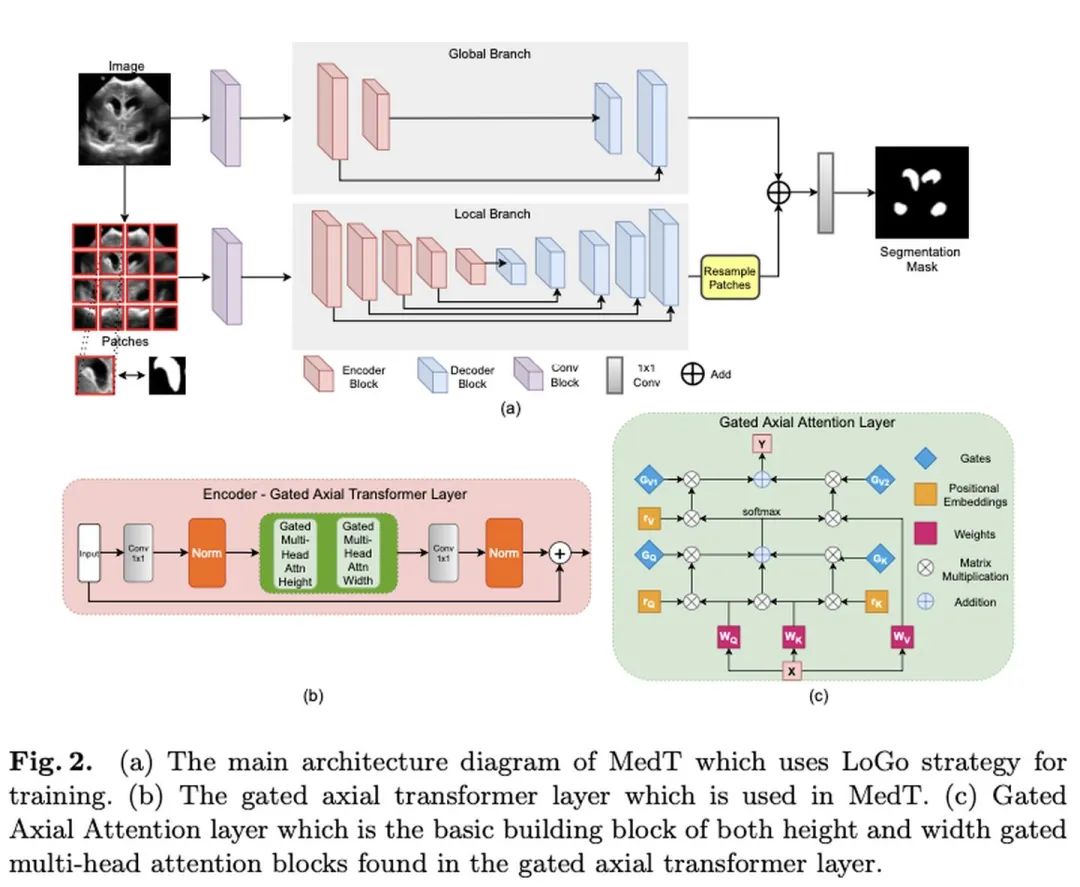
Details
为了克服计算复杂度较高的情况,将传统的自注意力模块分为宽度上以及高度上的两个注意力模块,称为axial attention,大大减小了计算复杂度;
对于使用小规模数据集的实验(在医学图像分割中通常是这种情况),位置偏差很难学习,因此在编码长距离联系时并不总是准确的。在学习的相对位置编码不够准确的情况下,将它们添加到相应的key,query和value张量中会导致性能降低。因此,本文提出了一种改进的轴向注意block,该block可以控制位置偏差可在非局部上下文的编码中施加的影响。GQ,GK,GV1,GV2∈R是可学习的参数,它们共同创建门控机制,该机制控制学习的相对位置编码对编码非局部上下文的影响。通常,如果准确地学习了相对位置编码,则与未准确学习的相对位置编码相比,门控机制将为其分配较高的权重。
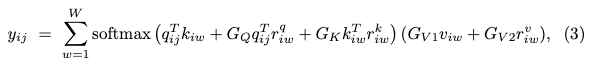
Experiments and results
三个数据集对MedT进行验证:
Brain anatomy segmentation (ultrasound) 脑部超声图像 1300+329
Gland segmentation (microscopic) 腺体显微镜图像 85+80
MoNuSeg (microscopic) 30+14
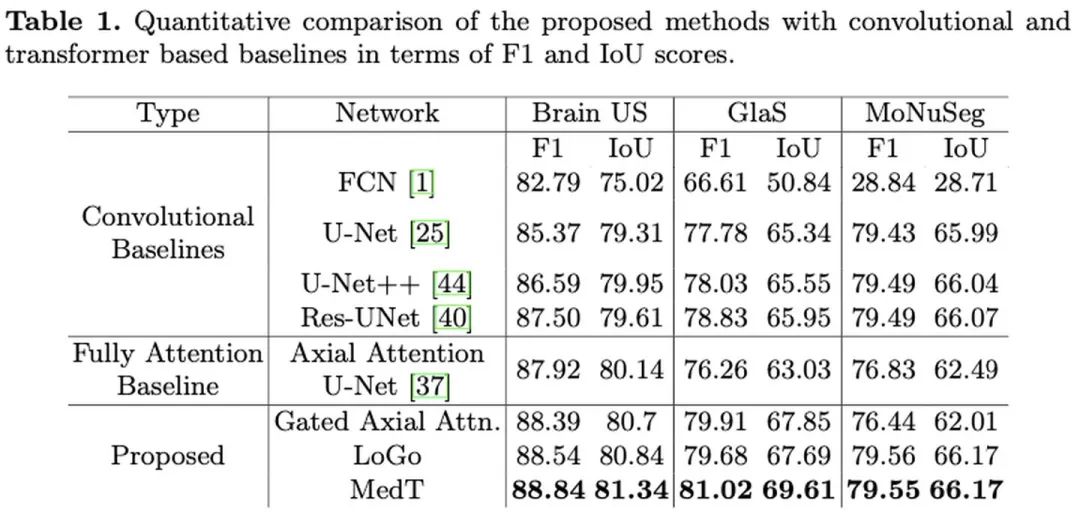
消融实验:
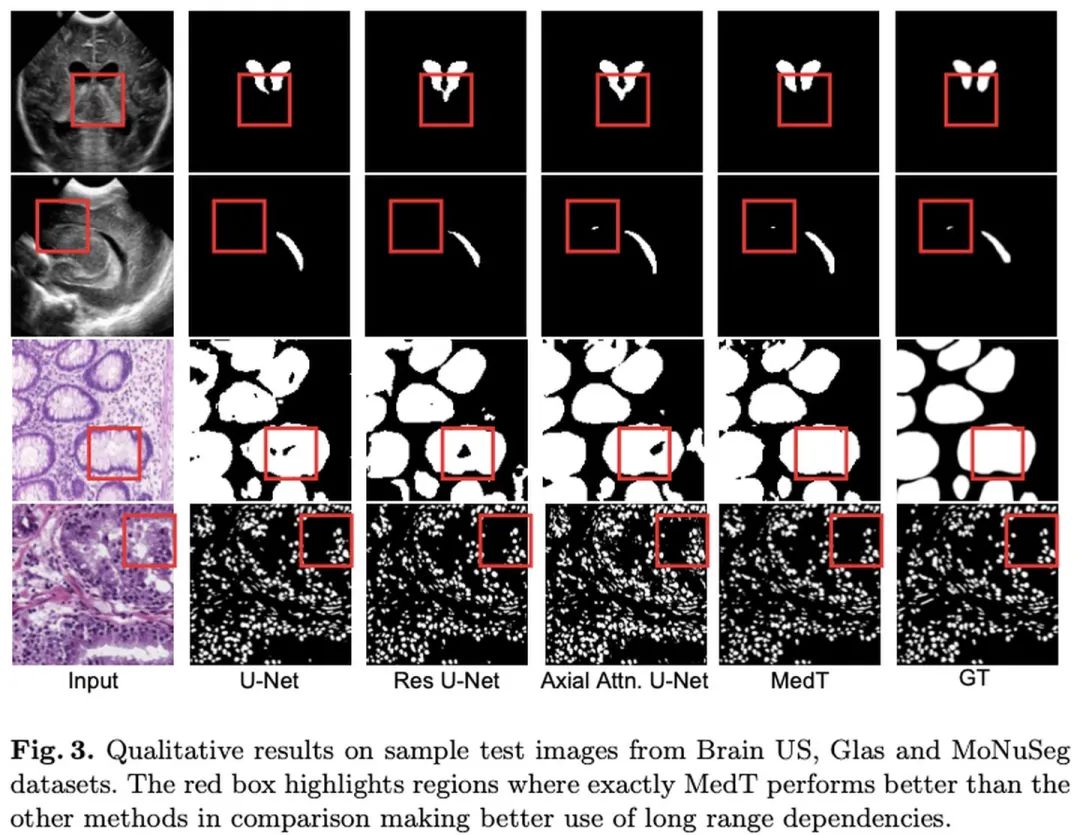
上述论文和代码下载
后台回复:MedT,即可下载上述论文PDF和代码
后台回复:CVPR2021,即可下载CVPR 2021论文和开源代码合集
点击下方卡片并关注,了解CV最新动态
重磅!CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer方向 微信交流群,也可申请加入CVer大群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、Transformer、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,才能通过且邀请进群

▲长按加微信群
▲点击上方卡片,关注CVer公众号
整理不易,请给CVer点赞和在看!![]()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









