






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
本文转载自:新智元
来源:arXiv | 编辑:Priscilla
【导读】东南大学研究团队最新提出的4K实时处理超分辨率系统(EGVSR)不仅能够修复高糊画质,运行速度还比TecoGAN快9倍,代码已开源。
有没有试过辛辛苦苦拍了个视频,最后一看,竟然「真·一塌糊涂」?
问题不大!AI修复能力杠杠的!
而现在,一个能实时重建视频质量,处理速度还比主流方法快9倍的系统就摆在你眼前!
高糊视频有救啦!

没错!这就是东南大学研究团队最新提出的EGVSR——4K实时处理超分辨率系统!

论文:https://arxiv.org/abs/2107.05307
代码:https://github.com/Thmen/EGVSR
兼顾图像质量和速度性能,EGVSR究竟是怎么做到的呢?
什么是VSR?
视频超分辨率(VSR)是从图像超分辨率发展而来的,是计算机视觉领域的热门话题之一。
VSR技术可以重构视频,还原视频清晰度,提升主观视觉质量。
目前,我们常说的4K、8K这些高分辨率显示技术其实已经相对成熟,但无奈主流的视频源仍以1080P或720P为主,从源端就已经限制了视频系统的质量。
然而,在不久的将来,4K甚至更高的分辨率一定会取代全高清(FHD)成为主流格式。
因此,我们就需要有高效、轻量级的 VSR 技术,将大量低分辨率 (LR) 视频升级为高分辨率 (HR) 视频。
就像上面提到的,VSR技术的研究对象是视频资源的图像序列。
而图像序列就是连续的帧,由一系列静态图像组成。
当视频中的物体运动速度较快,在单个图像中表现为运动模糊效果,因此目标帧与其相邻帧之间会出现子像素位移。

因此,VSR系统使用有效的运动补偿算法对齐相邻帧至关重要。
这也是当前VSR研究领域其中一个「老大难」。
此外,大规模VSR的计算十分复杂,内存消耗也大,严重阻碍了视频处理的实时性和低延迟性,难以在实际应用中部署。
为了解决这些问题,东南大学研究团队就为大规模VSR定制了各种网络加速策略,利用GAN来保证视频的重建质量,提出4K实时处理超分辨率系统(EGVSR)。
GAN:重建视频质量的工具
由于生成对抗网络(GAN)能够产生更好的感知质量,因此也广泛应用于超分辨率领域。
研究人员利用GAN强大的深度特征学习能力,来应对VSR任务中大规模的分辨率退化。
此外,参考TecoGAN方法的设计,引入了空间-时间对抗结构,能够让判别器理解学习时空信息的分布,从而避免传统GAN遇到的时域不稳定效应。
研究人员参考高效CNN搭建架构,设计出了一个更通用,质量更高的视频超分辨率网络,也就是EGVSR,这样就能满足高达4K分辨率的超分辨率大规模视频的需求。
EGVSR这个轻量级的网络结构,生成器部分分为FNet和SRNet,分别用于光流估计和视频帧超分辨率。
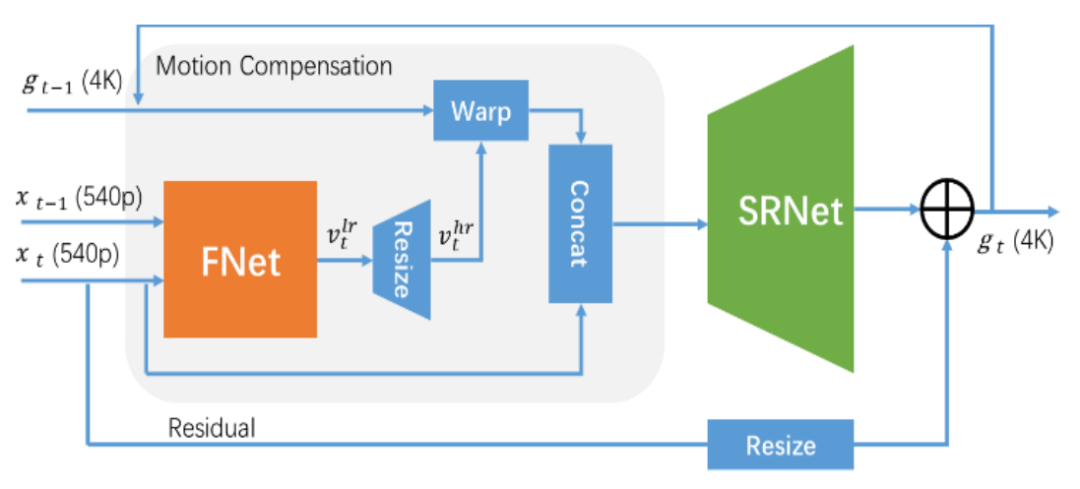 EGVSR生成器部分的框架和推理阶段的数据流
EGVSR生成器部分的框架和推理阶段的数据流
为设计出更加简化的EGVSR,研究团队提出了以下几种神经网络的加速技术。
快点,再快点!
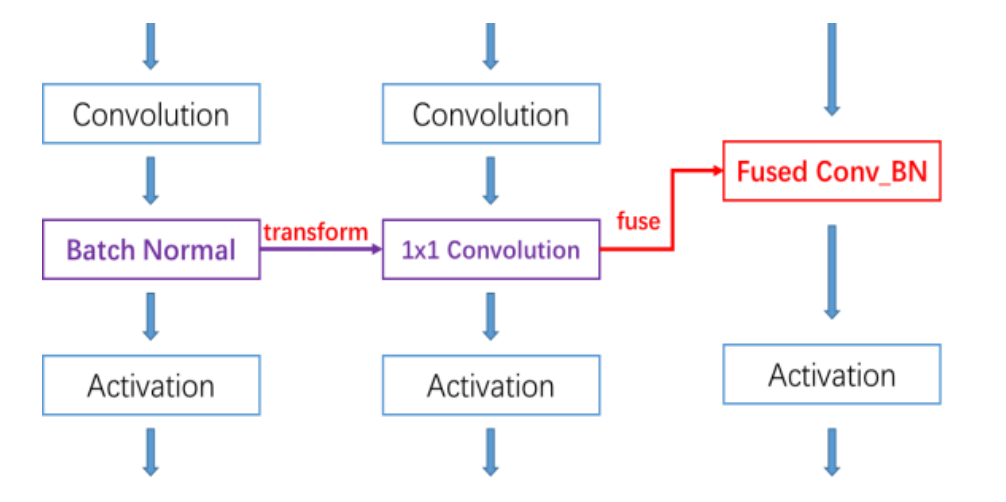
批量归一化融合
批量归一化(BN)是深度学习领域中最常用的一种技术,它能够提高网络的泛化能力,防止过拟合。
因此,EGVSR中的FNet模块大量使用了BN层。
团队用1×1的卷积层来实现和替换BN层,再将1×1的卷积层与之前的卷积层融合,省去了BN层的计算,得到优化的BN融合层提速了5%左右。
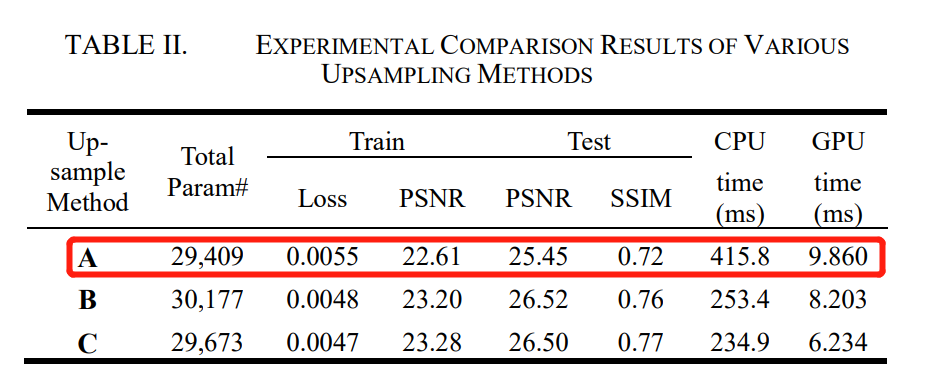
高效的上采样方法
在超分辨率网络中,上采样层(Upsampling layer)是最重要的部分之一。
根据技术路线的不同,大致可以分为两类:基于插值的上采样方法(interpolation-based upsampling methods)和基于学习的上采样方法(learning-based upsampling methods)。
由于所有基于插值的上采样方法都会导致图像边缘模糊,而基于学习的上采样方法则具有强大的特征学习能力,团队选择了后者,具体方法包括:A)调整大小卷积(Resize Convolution);B)去卷积(Deconvolution);C)子像素卷积(Sub-pixel convolution)。
研究团队将ESPCN网络作为超分辨率网络的骨干,只改变上采样层,用上述提到的三种上采样方法训练了多组SRNet,结果显示,子像素卷积方法得出的效果最佳。
提高计算效率
卷积计算是CNN的关键,占总计算量的90%以上,耗费了大量的计算时间。
而传统的朴素卷积(naïve convolution)使用了6个循环结构,计算效率也是相当低。
因此,为了提高计算效率,团队使用矩阵乘法(MatMul)算法进行改进。
经过实验,研究团队发现,通过逆向col2im转换就可以得到所需的输出特征结果。
也就是说,将卷积计算转化为矩阵乘法,通过内存空间节省推理时间,就能提高计算效率。
实验结果
一顿操作猛如虎,最终运行速度如何呢?
来对比一下不同VSR网络在CPU和GPU上的运行速度:
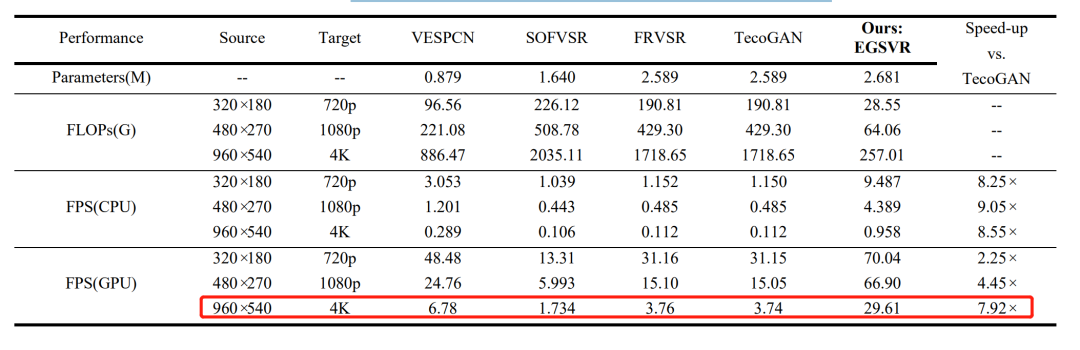
由图可见,相比TecoGAN,仅使用CPU,EGVSR能提速8.25-9.05倍。
而在GPU的加速下,EGVSR的4K实时处理速度比TecoGAN高出7.92倍。
当然,不能只求快,还是要看看总的计算成本。
EGVSR总计算成本仅为VESPCN的29.57%,SOFVSR12.63%,FRVSR和TecoGAN的14.96%。

速度有了提高,计算成本也大大减少,那最重要的画质,是不是真的变高清了呢?

研究人员在VID4、TOS3和GVT72三个数据集上进行了测试实验。
实验数据显示,EGVSR的确比传统模型的性能更好,能够修复更多空间细节,视频看起来更加高清。
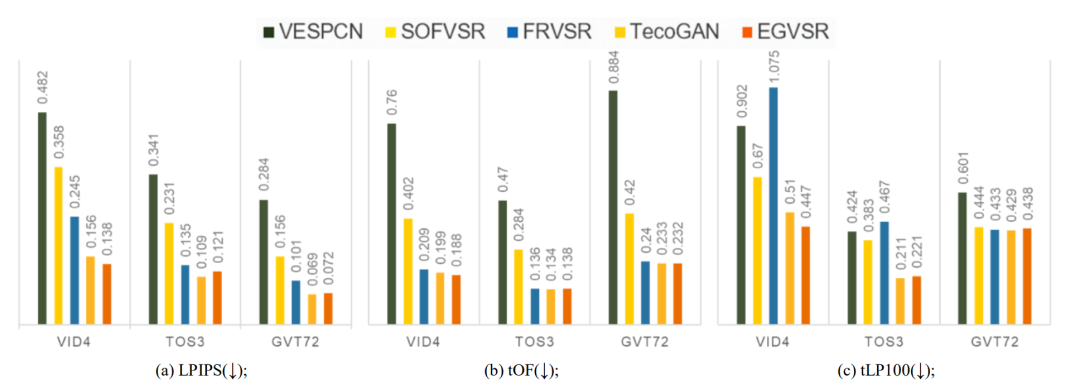
分数越低,越接近真实结果,画面就越流畅
团队在VSR领域中,提出了EGVSR方法,采用了各种优化技术,在保证提高视觉质量的前提下,将计算量降至最低,在硬件平台上,4K VSR得以实时实现。
作者介绍

研究团队共5人,Yanpeng Cao、Chengcheng Wang、Changjun Song和Yongming Tang均来自南京的东南大学的信息显示与可视化国际合作联合实验室。
其中一作Yanpeng Cao是东南大学在读研究生,研究领域为加密域图像处理和图像超分辨率等。
He Li则来自英国剑桥大学工程学院。
EGVSR论文和代码下载
后台回复:EGVSR,即可下载上述论文和代码
CVPR和Transformer资料下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的两篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









