






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:AIWalker
本文是清华大学在MLP方面的探索,不用现有MLP方案在空域进行token间信息交换,提出了一种全局滤波器方案在频域进行token间信息交换。受益于FFT的
log-linear计算复杂度,GFNet可以设计成分层架构形式,能够更高分辨率作为起点,比如。虽然这篇文章的指标对比最新的VOLO、ViP等不算高,不过它为相关架构设计提供了一个非常不错的思路,值得学习。
Abstract
近期Transformer与MLP模型的发展证明了其具有以更少的归纳偏置取得更佳性能的潜力,这些模型往往基于从原始数据学习空间位置上相关性。然而,这些自注意力与MLP的计算复杂度会随图像尺寸迅速增长,这使得这些方法难以满足高分辨率特征需求。
在本文中,我们提出了全局滤波器网络(Global Filter Network, GFNet),一种概念简单且计算高效的架构,它在频域以log-linear复杂度学习长距离空间依赖。所提架构通过如下三个关键操作替代ViT中的自注意力层:
2D 离散傅里叶变换;
频域特征与全局可学习滤波器的点乘操作;
2D逆傅里叶变换。
所提方案在ImageNet以以及下游任务上表现出了非常有力的精度-复杂度均衡。相比Transformer与CNN模型,所提方案在高效性、泛化性以及鲁棒性方面极具竞争力。
Method
在正式介绍之前,我们简单介绍一点关于傅里叶变换的基础知识。
Preliminaries
离散傅里叶变换(DFT)在数字信号处理领域起着非常重要的作用。我们以1D DFT为例进行介绍。给定长度为N的序列,1D DFT通过如下公式将其转换到频域:
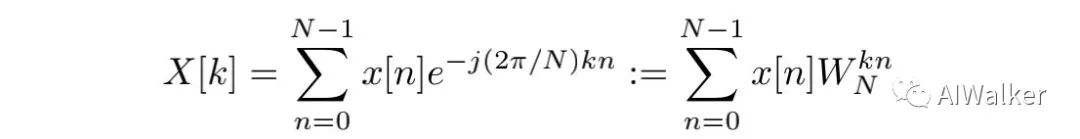
注:表示序列的频谱。
此外,值得注意的是:DFT是一对一变换。因此,给定DFT,我们可以通过如下公式进行原始信号重建:
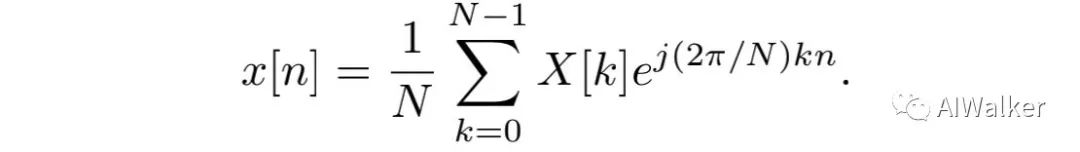
DFT在现代信号处理算法中得到了广泛应用,主要由以下两个原因:
DFT的输入与输出均为离散形势,可以通过计算机快速实现;
DFT存在高效算法,比如利用其对称与周期性的FFT。
Global Filter Networks
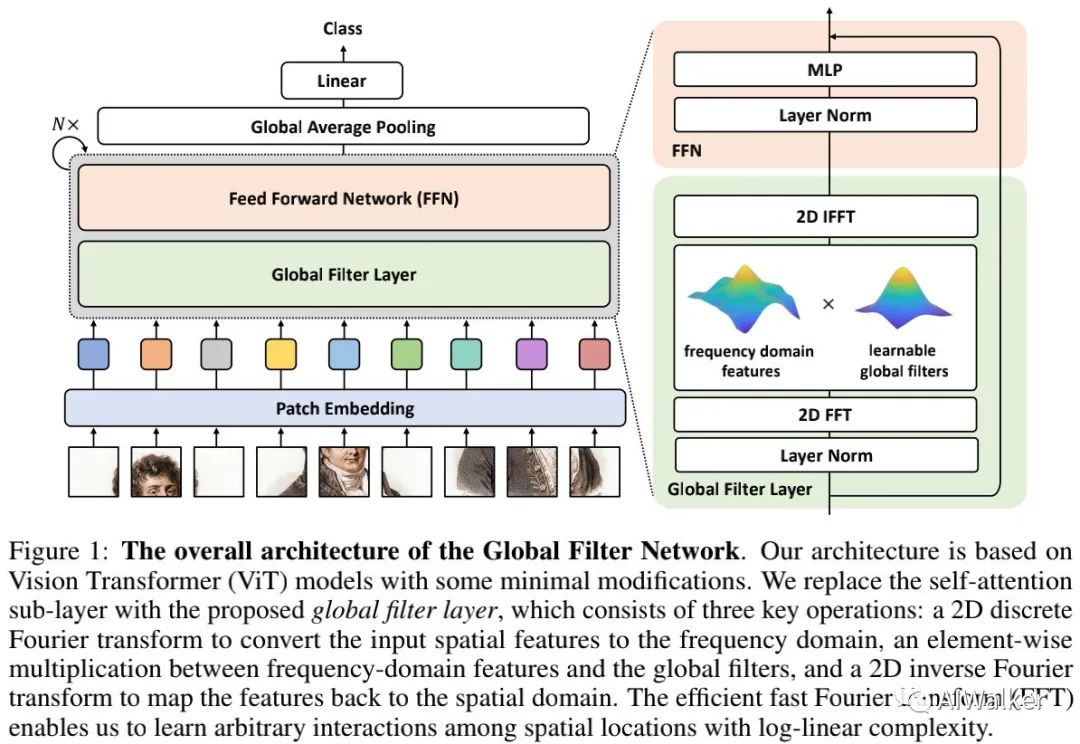
上图给出了本文所提方案整体架构示意图,它是一种类似ViT、DeiT的架构,即仅通过PatchEmbedding进行空间尺寸下降,然后通过多个核心模块进行处理,最后后接线性分类层进行分类。
所提方案的输入尺寸为并进行非重叠块拆分与线性投影得到维度D的词。GFNet的核心模块包含两部分:
全局滤波器层,它用于进行空间信息交换;
前馈网络,即MLP部分。
Global Filter Layer 我们提出了全局滤波器层作为自注意力层之外的选择:在频域进行空间信息交互。给定词,我们首先采用2DFFT变换将其变换到频域:
然后,我们再采用可学习滤波器进行调制:
注:这里的滤波器由于具有与X相同的维度而被称之为全局滤波器。最后,我们采用逆FFT将调制信号变换回空间并更新词:
上述核心部分的实现伪代码如下,就是这么的简单。
X = rfft2(x, dim=(1, 2))
X_tilde = X * K
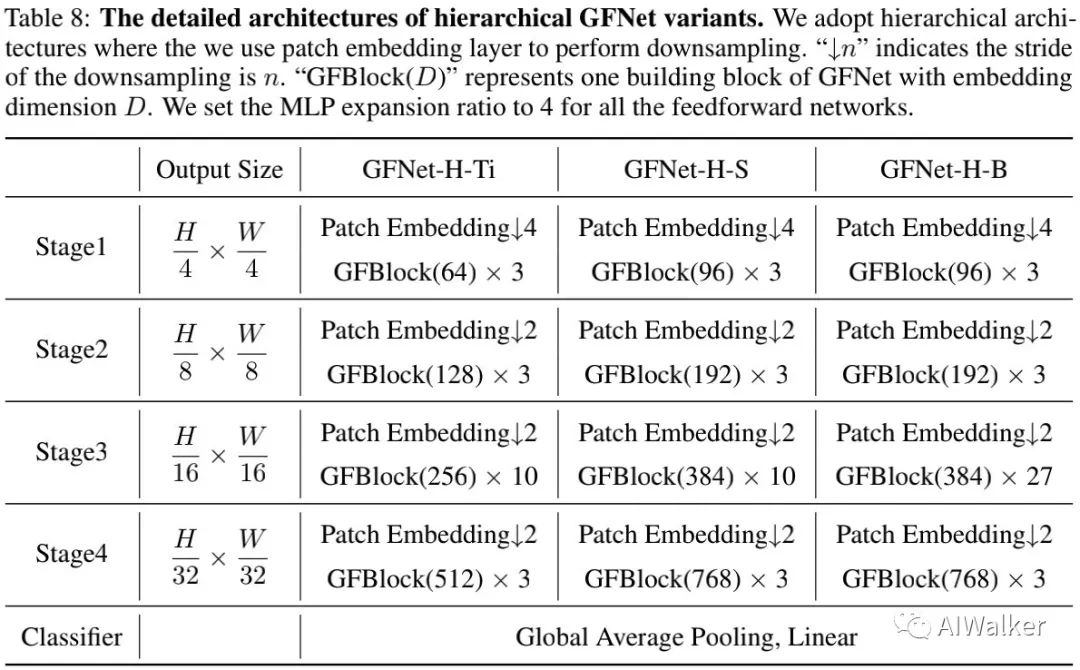
x = irfft2(X_tilde, dim=(1, 2))Architecture variants 考虑到自注意力与MLP的高计算复杂度问题,现有ViT、MLP采用快速降低分辨率的方式,即初始的PatchEmbedding尺寸非常大,比如。然而,GFNet的的计算复杂度为log-linear,可以避免上述问题。因此,我们可以以更高分辨率(比如)的特征作为起点,然后逐渐下采样。在这篇文章中,我们主要探索了两种形式的GFNet,即Transformer风格与CNN风格。
对于Transformer风格,类似DeiT与ResMLP-12,我们同样采用了12层模型并得到了三个尺寸的模型GFNet-Ti、GFNet-S以及GFNet-B(通过调整维度、深度等信息即可得到);
对于类CNN分层风格,我们同样设计了三种复杂度的模型GFNet-H-Ti、GFNet-H-S、GFNet-H-B。相关信息见下表。
Experiments
为验证所提方案的有效性,我们在ImageNet分类以及下游任务(语义分割)上进行了对比分析。
ImageNet
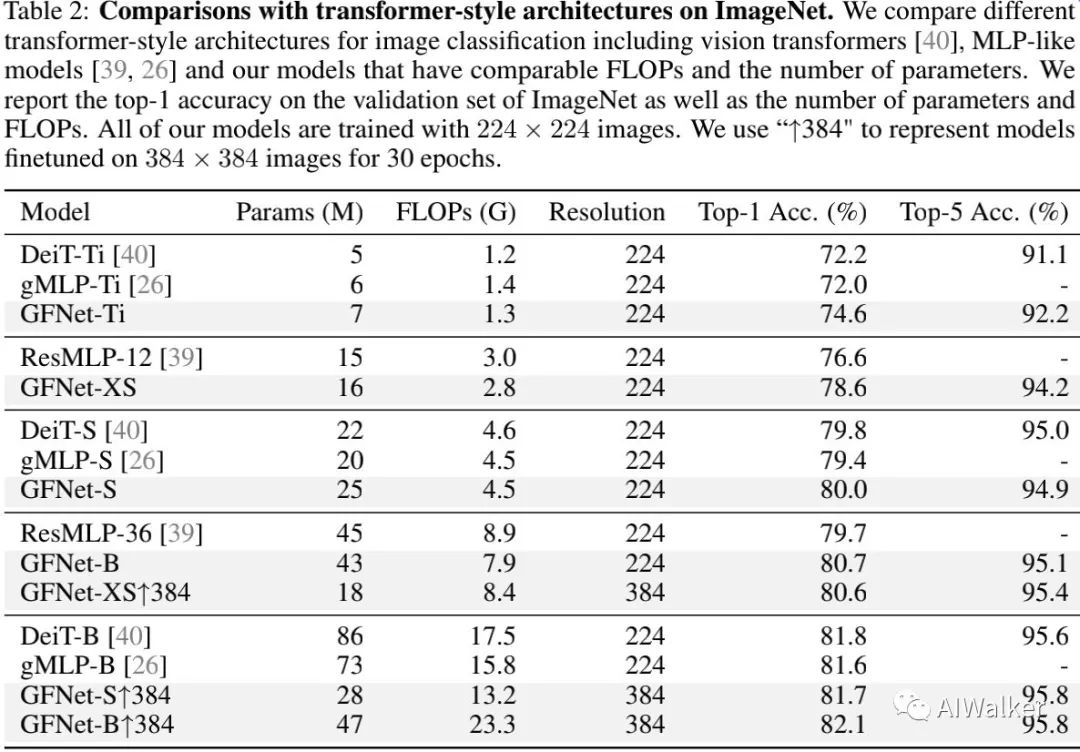
上表给出了Transformer风格架构的性能对比,从中可以看到:
所提方法明显优于近期的MLP类方案与DeiT等方案;
GFNet-XS比ResMLP高2.0%且具有稍少的计算量;
GFNet-S同样具有比gMLP-S、DeiT-S更高的精度;
GFNet-Ti显著优于DeiT-Ti(+2.4%)与gMLP-Ti(+2.6%),且具有相似复杂度。
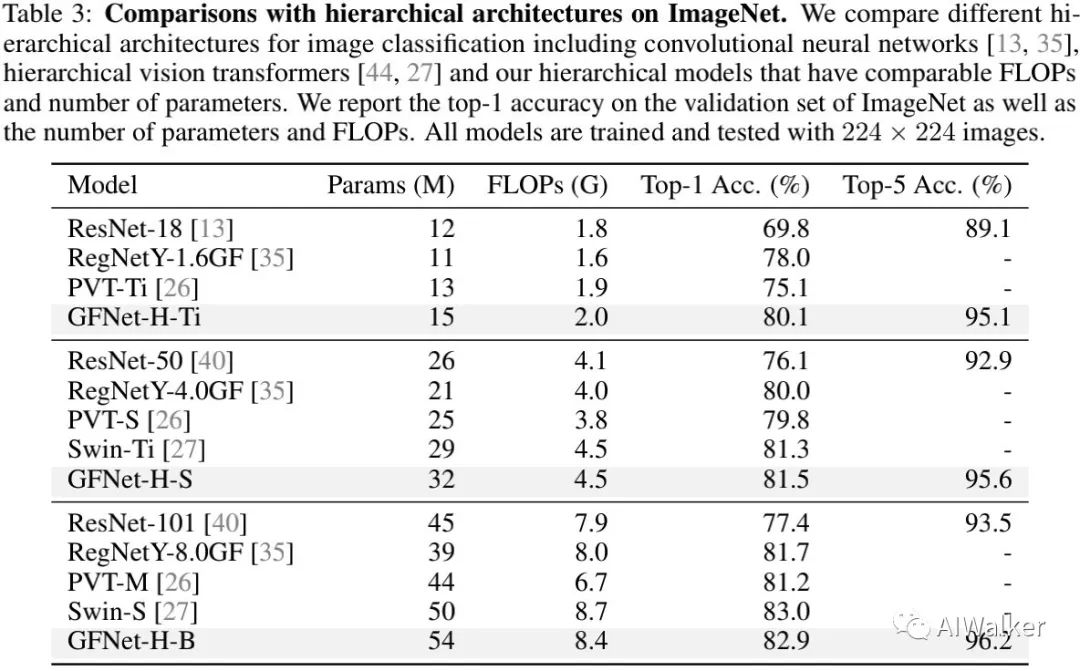
上表对比了分层架构的信息对比,从中可以看到:受益于log-linear复杂度,GFNet-H取得了比ResNet、RegNet、PVT等更高的性能;取得了与Swin相当的精度,但具有更简单更广义设计。
Downstream Tasks
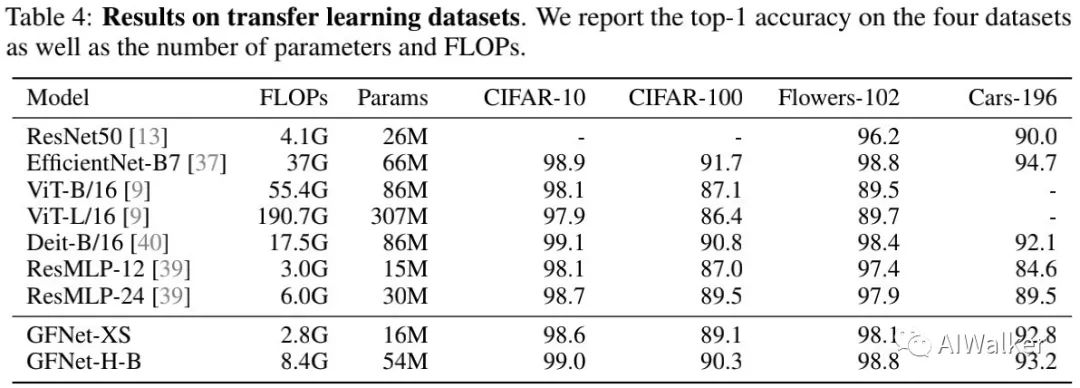
上表对比了所提方案在不同数据集上的迁移能力,从中可以看到:所提方法具有更佳的迁移能力。比如,GFNet显著优于ResMLP,同时具有比EfficientNet-B7相当的性能。
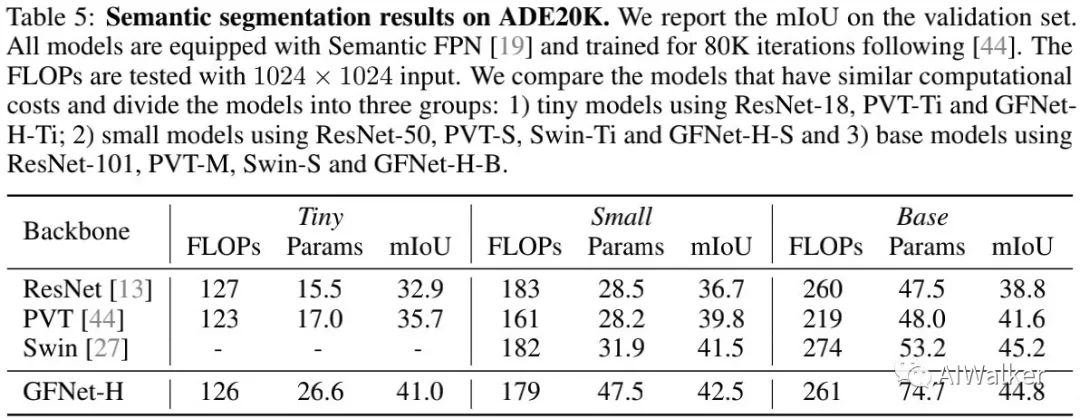
上表对比了所提方法在ADE20K语义分割数据上的性能对比,从中可以看到:所提方案在该任务上表现非常好,在不同复杂度方面取得了与其他模型(比如ResNet、PVT、Swin)相当甚至更好的性能。
CVPR和Transformer资料下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的两篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看
















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









