






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:机器之心
预训练模型是否也能只需要很少的样本就能完成任务?
Transformer 架构的强大性能不仅在 NLP 领域成为了主流,也在代替卷积神经网络 CNN,成为视觉识别的一个方向(ViT)。一些 transformer 模型已经取得了有竞争力的结果,但因为缺乏典型的卷积归纳偏差使得它们比普通 CNN 需要更多的训练数据。
在南京大学吴建鑫团队近日提交的一篇论文中,研究者研究了如何使用有限数据训练 ViT,由于可以捕获特征对齐和实例相似性,新方法展现了优势。
在各种 ViT 主干下的 7 个小型数据集上从头开始训练之后,该研究获得了最先进的结果。研究者还讨论了小数据集的迁移能力,发现从小数据集学习的表示甚至可以改善大规模 ImageNet 的训练。

Training Vision Transformers with Only 2040 Images
论文链接:https://arxiv.org/abs/2201.10728
Transformer 近来已广泛用于视觉识别,替代了卷积神经网络(CNN)。视觉 Transformer(ViT)是一种直接继承自自然语言处理的架构,但适用于以原始图像 patch 作为输入的图像分类。ViT 及其变体获得了可与 CNN 媲美的结果,但却需要更多的训练数据。
例如,在 ImageNet(128 万张图像)上训练时,ViT 的性能比具有相似容量的 ResNet 差。一个可能的原因可能是 ViT 缺乏 CNN 架构中固有的某些理想属性,这使得 CNN 非常适合解决视觉任务,例如局部性、平移不变性和层次结构。因此,ViT 通常需要比 CNN 更大量的数据进行训练。
为了缓解这个问题,很多工作都尝试将卷积引入 ViT。这些架构具有两种范式的优点,注意力层对远程依赖进行建模,而卷积则强调图像的局部属性。实验结果表明,这些在 ImageNet 上训练的 ViT 在该数据集上优于类似大小的 ResNet。
然而,ImageNet 仍是一个大规模数据集,当在小数据集(例如 2040 张图像)上训练时,这些网络的行为仍不清楚。该研究从数据、计算和灵活性的角度进行了分析,证明不能总是依赖如此大规模的数据集。
该论文探究了如何使用有限的数据从头开始训练 ViT。
该研究首先执行自监督预训练,然后对同一目标数据集进行监督微调,与(Cao et al.,2021)等人的方法类似。该研究重点关注自监督的预训练阶段,方法基于参数实例判别(parametric instance discrimination)。
从理论的角度分析,参数实例判别不仅可以捕获 positive pair 之间的特征对齐,还可以找出实例之间的潜在相似性,这要归功于最终可学习的全连接层 W。实验结果进一步验证了研究者的分析,该研究的方法比非参数方法实现了更好的性能。
众所周知,在大规模数据集上,高维全连接层的实例判别会受到大量 GPU 计算、内存过载和收敛速度慢的影响。由于该研究专注于小型数据集,因此不需要针对大型数据集的复杂策略。相反,该研究对小数据设置采用小分辨率、多裁剪和 CutMix 的方法,并且研究者还从理论和实验的角度对其进行了分析。
该研究将这种方法命名为带有 Multi-crop 和 CutMix 的实例判别(Instance Discrimination with Multi-crop and CutMix,IDMM)。实验结果表明,在 7 个小型数据集上从头开始训练多种 ViT 主干网络,实现了 SOTA 结果。例如,该研究在 flowers 数据集(含 2040 张图像)上从头开始训练模型,结果达到 96.7% 的准确率,这表明使用小数据集训练 ViT 是完全可以的。
此外,该研究首先分析了小数据集的迁移能力,并发现:即使在小型数据集上进行预训练,ViT 也具有良好的迁移能力,甚至可以促进对大规模数据集(例如 ImageNet)的训练。(Liu et al.,2021)也研究了使用小型数据集训练 ViT,但他们专注于微调阶段,而南大的这项研究专注于预训练阶段,并且南大的方法取得了更好的结果,其中在 flowers 数据集上获得的最佳准确率为 56.3%。
总的来说,该研究的主要贡献包括:
提出了用于自监督 ViT 训练的 IDMM,即使在 7 个小型数据集上对各种 ViT 主干网络从头开始训练也能获得 SOTA 结果;
对于在处理小数据时为什么应该更注重参数实例判别,该研究给出了损失角度的理论分析。此外,展示了 CutMix 等策略应如何从梯度的角度缓解不频繁更新的问题;
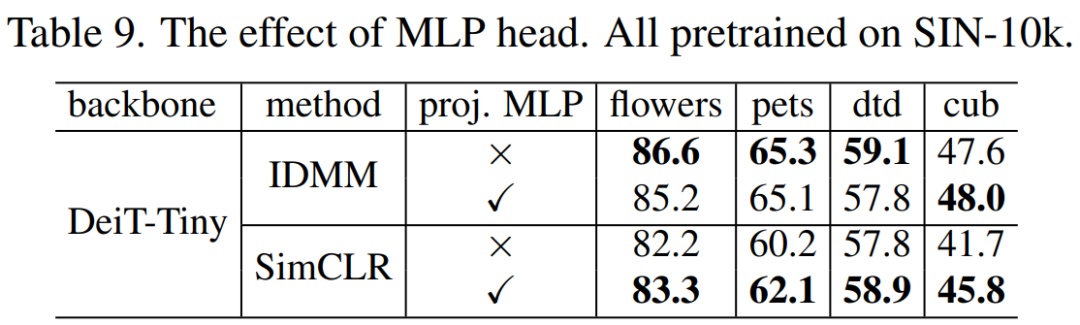
该研究通过实验表明,投影 MLP 头对于非参数方法(例如,SimCLR)是必不可少的,但对于参数实例判别而言却不是,这要归功于实例判别中最终可学习的全连接层;
分析了小数据集的迁移能力,发现即使在小数据集上进行预训练,ViT 也具有良好的迁移能力。
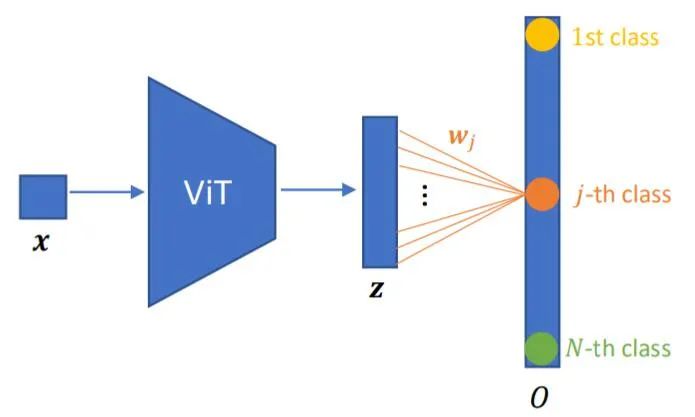
具体方法如上图所示,输入图像 x_i (i = 1, · · · , N) 被传至神经网络 f(·) 中,得到输出表征 z_i = f(x_i) ∈ R^d ,其中 N 表示实例总数。然后使用全连接层 W 进行分类,类数等于用于参数实例判别的训练图像总数 。随后将 w_j ∈ R^d 表示第 j 类的权重,W = [w_1| . . . |w_N ] ∈ R^(d×N) 包含所有 n 个类的权重。
因此有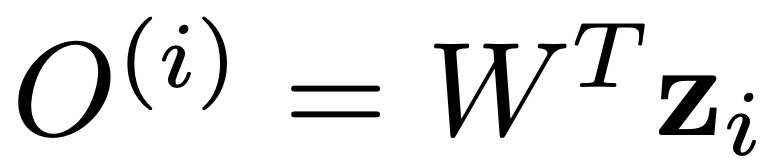 ,其中第 j 类的输出是
,其中第 j 类的输出是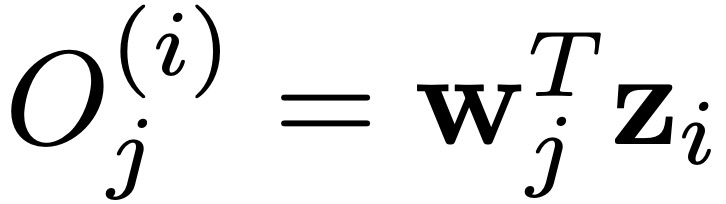 。最后,将 O^(i) 被传到 softmax 层以获得有效的概率分布 P^(i)。
。最后,将 O^(i) 被传到 softmax 层以获得有效的概率分布 P^(i)。
损失函数为:
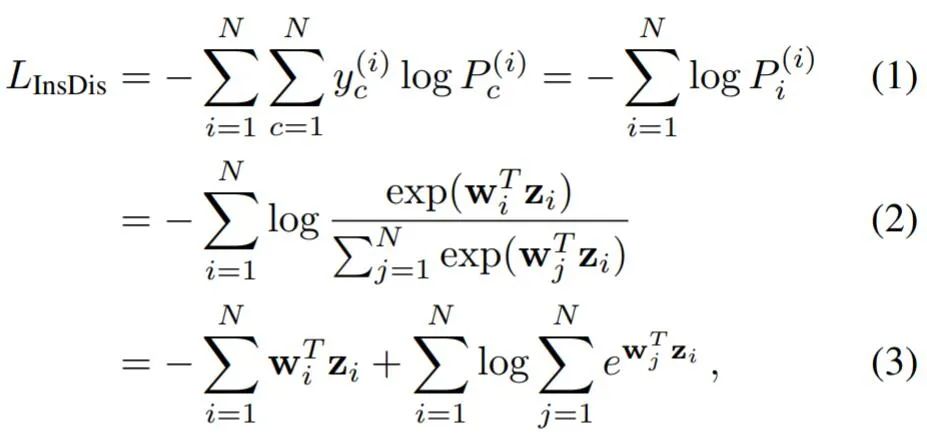
其中上标 i 代表对实例求和,下标 c 代表对类求和。
实验结果
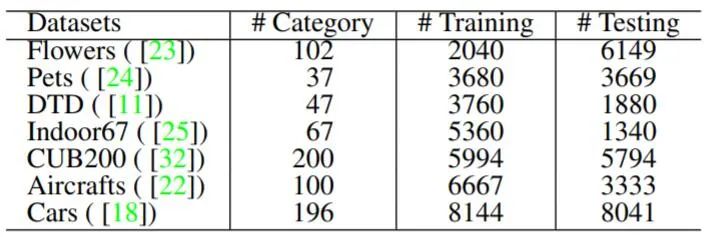
研究者在实验中使用了 7 个小型数据集,具体如下表 1 所示。
为什么要从头开始训练
为什么要直接在目标数据集上从头开始训练呢?研究者从以下三个方面进行了解答
首先是数据。当前的 ViT 模型往往是在大规模数据集(如 ImageNet 或更大)上预训练,然后在各种下游任务中微调。典型卷积归纳偏差的缺失也使得这些模型比常见 CNN 更需要数据。因此,探究是否可以针对某个可用图像有限的任务从头开始训练 ViT 模型非常重要;
其次是计算。大规模数据集、大量 epoch 和复杂的骨干网络,这些组合在一起意味着 ViT 训练的计算成本非常高。这种现象导致 ViT 模型成为少数机构研究人员才能使用的「特权」;
最后是灵活性。下游微调范式之前的预训练有时会变得非常麻烦。例如,我们可能需要为同一个任务训练 10 个不同的模型,并将它们部署到不同的硬件平台,但在大规模数据集上预训练 10 个模型是不切实际的。
从头开始训练的结果
研究者提供了从头开始训练的结果。
在下表 2 和下图 4 中,研究者首先将 IDMM 与用于 CNN 和 ViT 的流行 SSL 方法进行了比较。公平起见,所有方法都预训练了 800 个 epoch,然后微调了 200 个 epoch。可以看出,即使从头开始训练,SSL 预训练也很有用,并且所有 SSL 方法的性能都比随机初始化好。
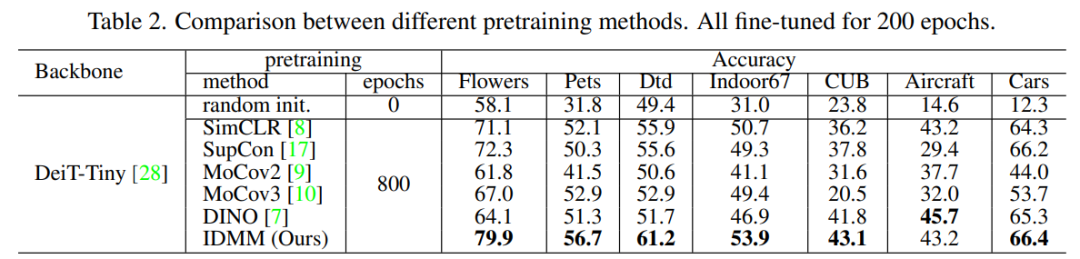
表 2:不同预训练方法之间的比较。
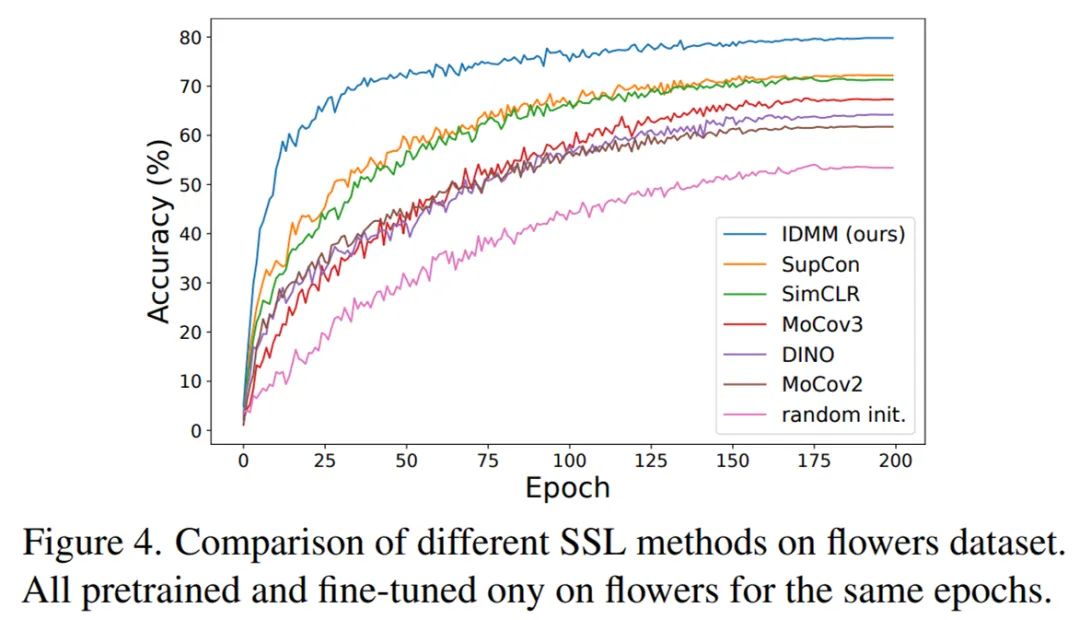
图 4:在花数据集上与不同 SSL 方法进行比较。所有模型都经过了同样 epoch 数的预训练和微调。
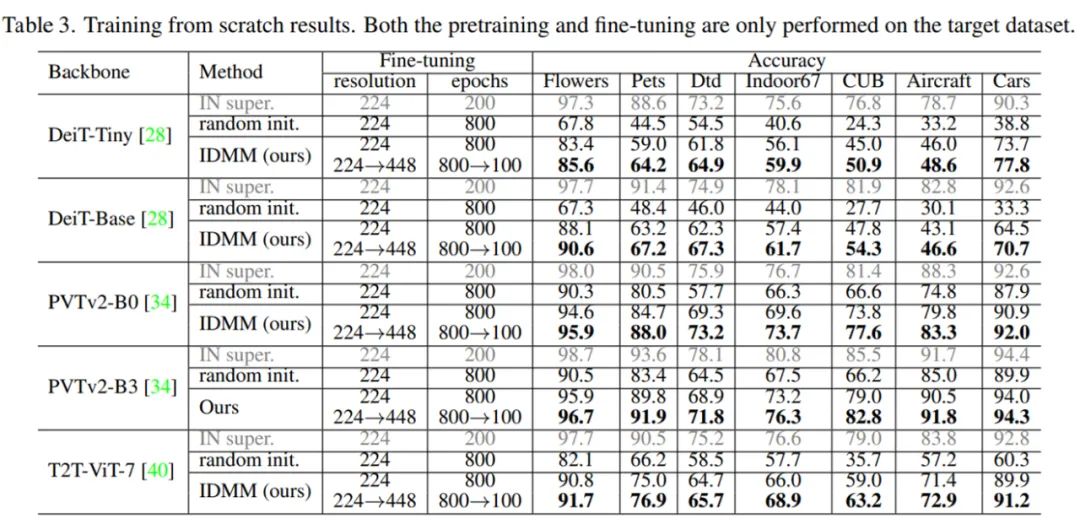
接着,研究者微调模型更长的 epoch,以获得更好的结果。具体来讲,他们使用 IDMM 初始化权重,先在 224x224 分辨率下微调了 800 个 epoch,然后在 448x448 分辨率下微调了 100 个 epoch。如下表 3 所示,当在这 7 个数据集上从头训练所有这些 ViT 模型时,IDMM 实现了 SOTA 结果。
小型数据集上的迁移能力
在下表 5 中,研究者评估了在不同数据集上预训练模型的迁移准确率。可以看到,即使在小型数据集上进行预训练,ViT 也具有良好的迁移能力。与 SimCLR 和 SupCon 相比,IDMM 在所有这些数据集上的迁移准确率也更高。即使预训练数据集和目标数据集不在同一个域中,研究者也可以获得非常好的结果。
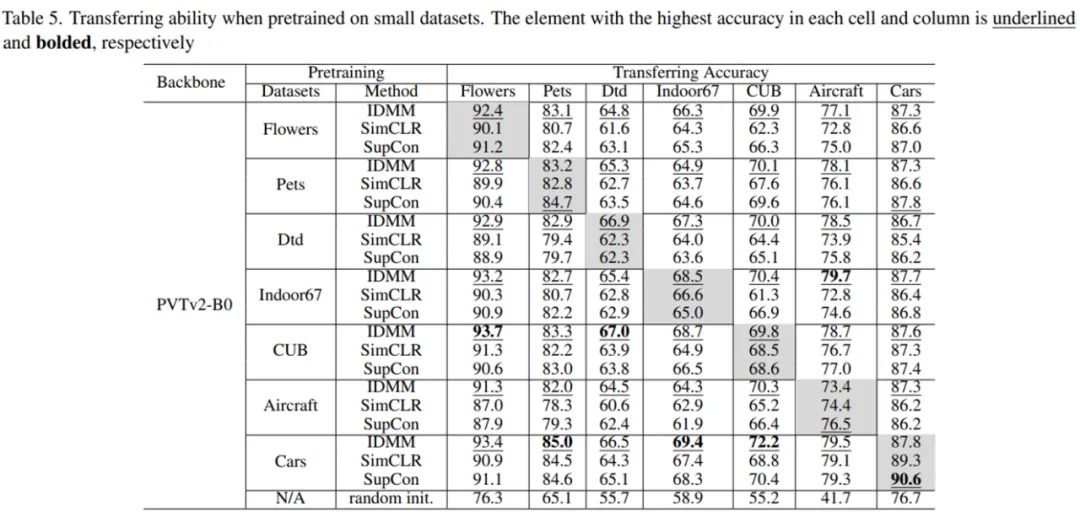
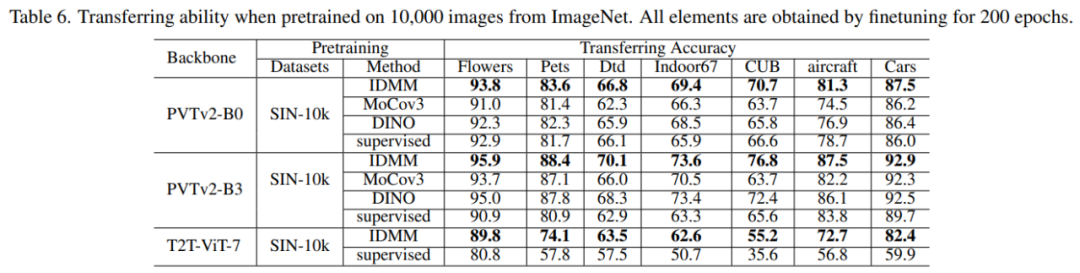
在下表 6 中,研究者将 IDMM 与各种 SSL 方法以及不同主干下的监督基线方法进行了比较。结果显示,IDMM 比这些竞品方法有很大的优势,在 SIN-10k 上学到的表征可以在迁移到其他数据集时作为一个很好的初始化。
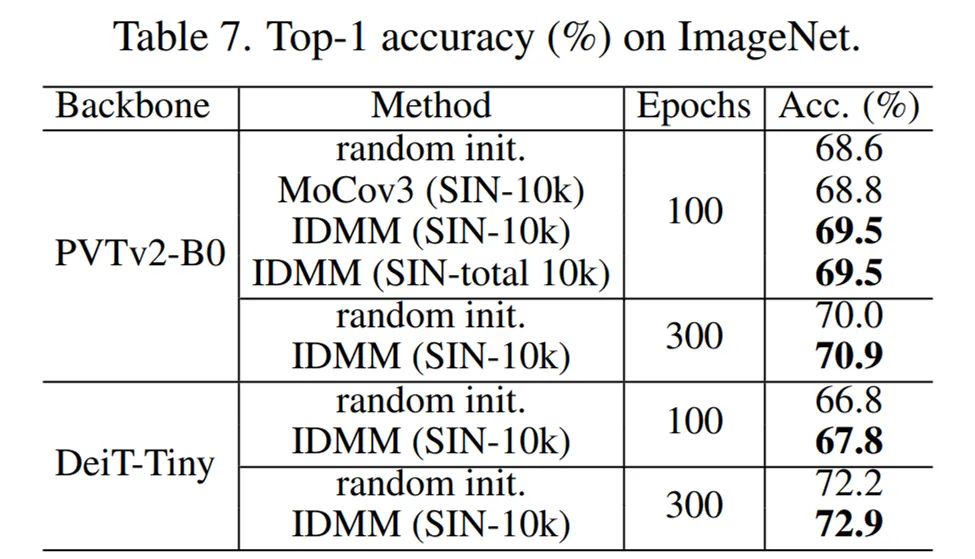
此外,研究者还探究了当在 ImageNet 上训练时,是否可以从 10,000 张图像的预训练中受益。从下表 7 可以看到,使用从 10,000 张图像中学到的表征作为初始化,可以大大加快训练过程,最终在 ImageNet 上实现了更高的准确率(提升约 1%)。
消融实验
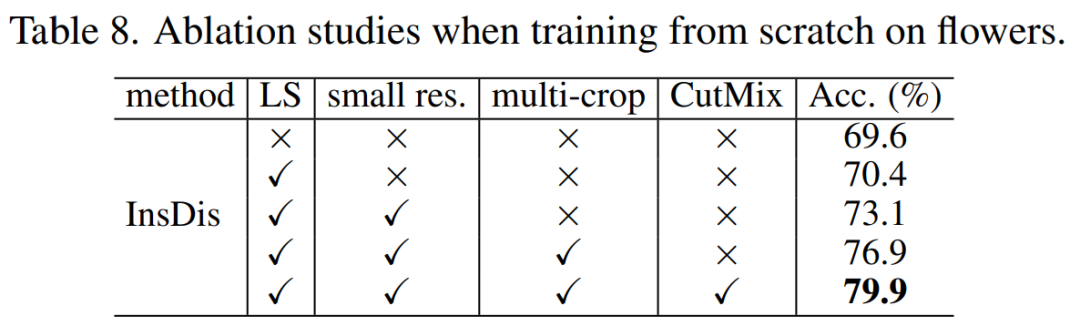
最后,研究者对不同的组件进行了消融实验。所有实验使用 PyTorch 完成,并且在 ImageNet 实验中使用了 Titan Xp GPU,在小型数据集实验中使用了 Tesla K80.
如下表 8 所示,研究者提出的所有策略都很有用,策略的结合使用更是实现了 SOTA 结果。
在下表 9 中,所有方法在 SIN-10k 上预训练了 800 个 epoch,然后在迁移到目标数据集时微调了 200 个 epoch。
该工作中,研究者对于 IDMM 的局限性进行了探讨,在像 DeiT 这样的架构上从头开始训练这些小型数据集时,模型仍有改进的空间。还有哪些属性对于小型数据集预训练起到关键作用?这还有待未来的进一步研究。
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看

















 3203
3203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









