






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:syp2ysy | 已授权转载(源:知乎)编辑:CVer
https://zhuanlan.zhihu.com/p/564674487

Singular Value Fine-tuning: Few-shot Segmentation requires Few-parameters Fine-tuning
论文:https://arxiv.org/abs/2206.06122
代码:https://github.com/syp2ysy/SVF
1、引言
小样本分割的目的是利用少量densely-annotated样本分割出图像中的新类objects。在之前的工作中研究人员通过设计不同的分割头,使模型从少量样本中学习到尽量多的关于新类的知识,以提升few-shot seg的性能。然而众多few-shot seg的方法中有一个通用的设置---freeze backbone(冻结主干网络的参数)。因此传统few-shot seg模型的范式就是freeze backbone + seg head。众所周知,多数任务中finetune 会使backbone更加适应下游任务从而取得优越的性能。因此我们产生了疑惑-- few-shot seg 任务中freeze backbone是否是唯一的选择?能否通过fine-tune backbone来提高few-shot seg model的性能?
我们把传统的fine-tune backbone的方法分为fully fine-tune(微调整个backbone)和part fine-tune(微调backbone的部分参数)。因此我们在同一个few-shot seg model上对不同的fine-tune方法进行了实验。实验结果如下所示;我们发现无论是那种fine-tune方式都会出现过拟合现象 (training set表现优秀,test set表现拉夸)。
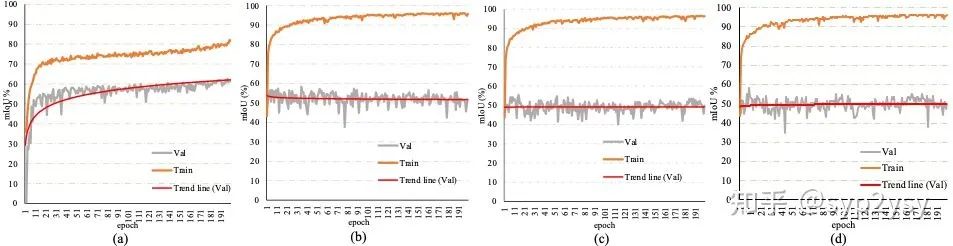
我们猜测导致这种结果出现的原因有两个,第一个是由于few-shot seg独特的属性,training set中学习的类,是不会在test set中出现的,因此传统fine-tune方法使backbone更加适应training set中的类,从而影响了模型泛化到test set的能力;第二个是由于few-shot中的样本数量太少,从而极容易导致过拟合情况的发生。
为了找到few-shot seg中合适的fine-tune方法,我们尝试分析freeze backbone的成功原因。因为few-shot seg中学习的所有类别的知识(我们称之为语义线索)都存在于pre-train weight中(因为voc & coco中所有类别均在imagenet中的出现过)。所以freeze backbone可以保证pre-train中的语义线索不会丢失。但是有一个新问题出现--pre-train中所有的语义线索都是有利于few-shot seg 任务的吗?我们认为并不是的,那如何动态调整pre-train中语义线索的重要程度并不改变pre-train中的语义线索成为我们设计新fine-tune方法的初衷。
pre-trian weight实际上是不同的张量组成,那么如何提取weight中的语义线索,也就转化成为如何从一个张量中获取其中的主成分。我们想到了SVD分解,因为SVD分解会得到特征值和特征向量,而这与我们的初衷契合,特征值可以表示初始pre-train中不同语义线索的权重,而特征向量表示pre-train中不同的语义线索。这样的话我们只需要在训练过程中fine-tune pre-train weight的特征值就可以了。这就是我们SVF的核心思想。
2、方法介绍
核心思想--不改变pre-train中的语义线索,而改变不同语义线索的权重;
使用工具--SVD分解
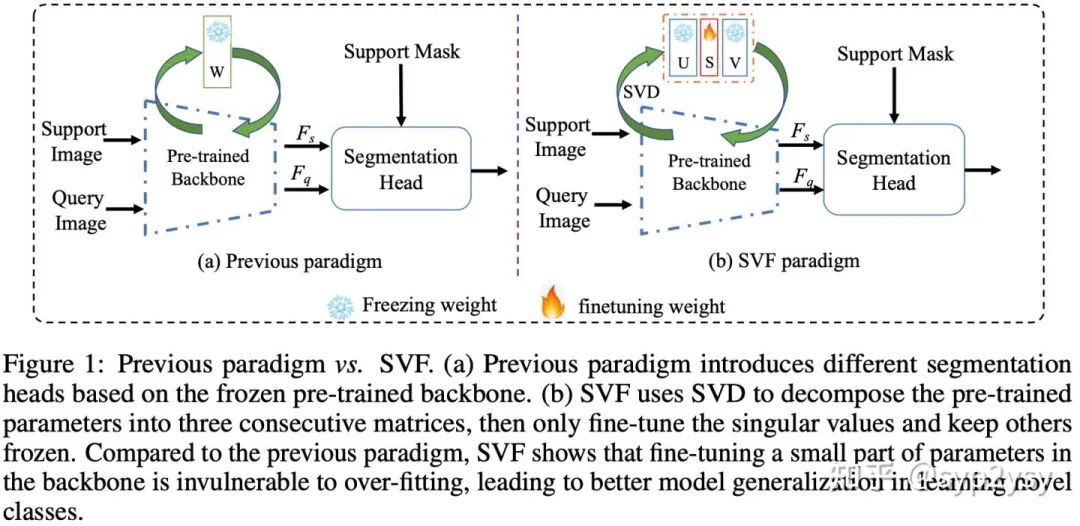
SVF的实现过程也非常简单,其与传统范式的区别如下图所示。不同与传统范式中freeze backbone的做法,SVF首先对pre-train weight进行SVD分解,然后freeze住特征向量空间U和V的参数,而放开特征值空间S的学习。由于SVF是针对backbone进行的,因此适用于大多数的few-shot seg 模型。

SVF的伪代码如下:

3、实验分析
首先,为了验证方法的有效性和通用性,我们分别在三种不同的方法上进行了实验。这三种方法分别是PFENet, BAM和baseline,其中baseline是将PFENet中的head替换成了ASPP。Pascal-5i和COCO-20i上的实验结果如下。
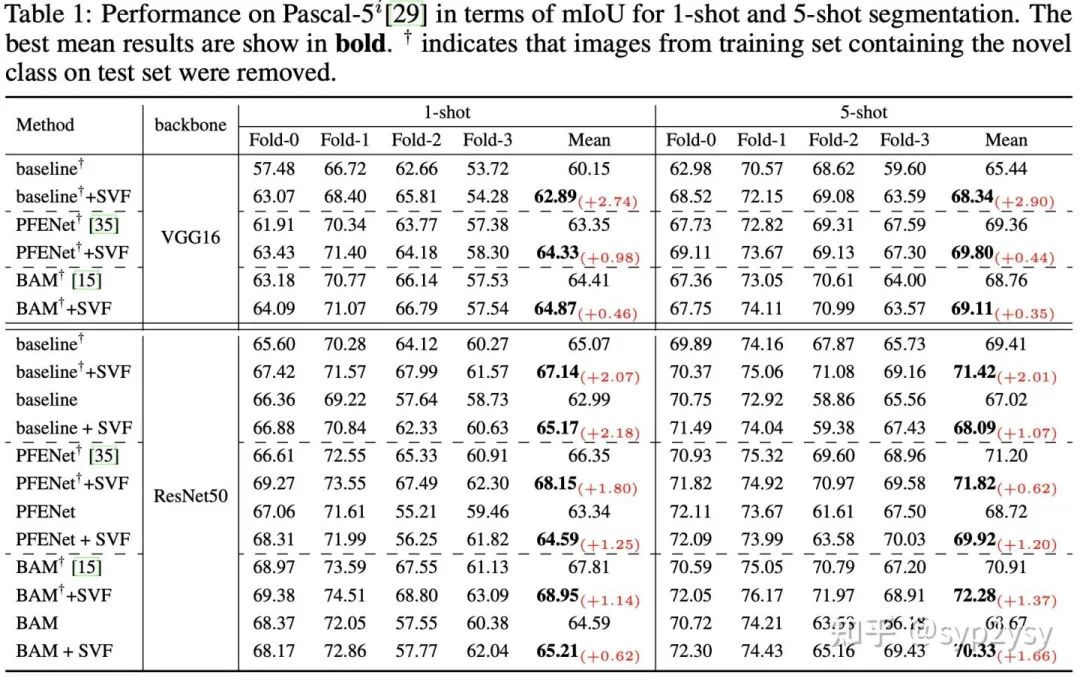
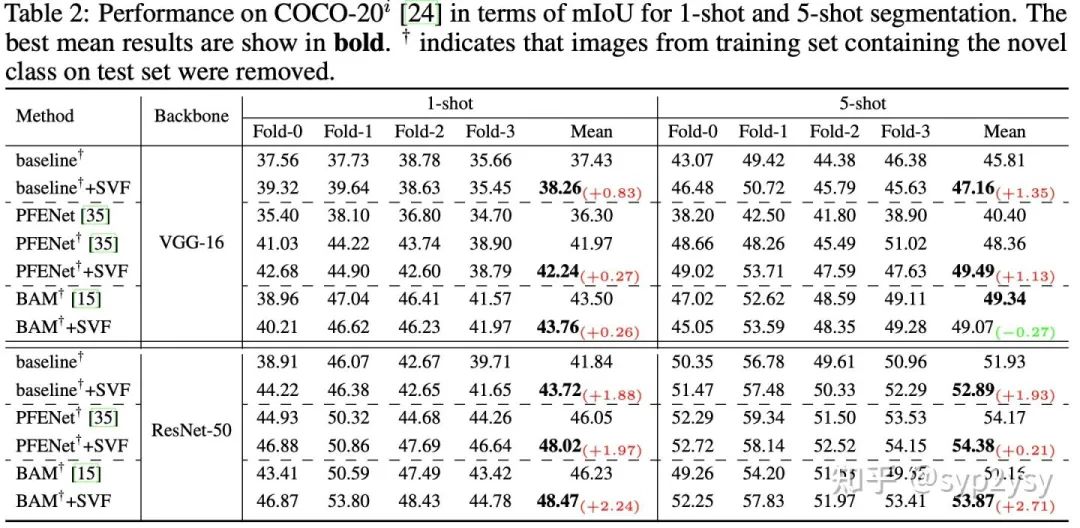
我们可以看到SVF可以很大程度上提高few-shot model的性能,同时不同的方法上的表现是一致的,表明SVF在few-shot seg中是一种通用且有效的新范式。此外论文的补充材料中也有与更多方法的公平对比结果。同时论文中讨论了few-shot seg中的dataset trick对模型性能的影响。
此外,我们探讨SVF成功的原因。SVF的初衷是在不改变pre-train weight的语义线索的前提下,动态调整不同语义线索的权重。首先SVF fine-tune 结束后我们统计了特征值空间S的变化,下图,我们统计了layer3中最后一个3x3卷积层和1x1卷积层中特征值变化最大的TOP-30.我们发现在某些特征值的改变是非常明显的,那么我们分别对特征值降低最大和增长最大的特征值进行可视化。
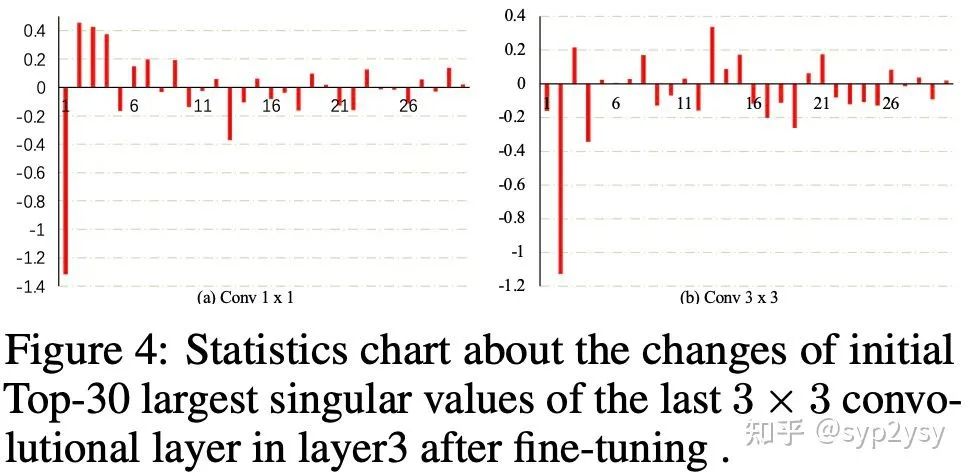

上述可视化结果中(a)表示特征值降低最大的语义线索,(b)表示特征值增长最大的语义线索。我们发现特征值降低最大是背景信息,这是不利于few-shot seg的,而特征值增长最大的语义线索确实更加关注object的前景。这也印证了我们的假设,pre-train weight中的语义线索并不是都有利于我们的下游任务的。因此在few-shot seg中SVF成功的关键是不破坏pre-train中的语义线索,动态调整不同语义线索的权重。
本文简单的介绍了SVF的研究动机,方法介绍和简单实验分析其有效性。paper中有这更加详细的讨论,并且有更详细的细节描述。希望我们的工作能够给 few-shot segmentation带来一些有意思的讨论。同时欢迎大家关注和提意见。
点击进入—> CV 微信技术交流群
CVPR 2022论文和代码下载
后台回复:CVPR2022,即可下载CVPR 2022论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
图像分割 交流群成立
扫描下方二维码,或者添加微信:CVer222,即可添加CVer小助手微信,便可申请加入CVer-图像分割 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如图像分割+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer222,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看














 5499
5499











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









