






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:CSIG文档图像分析与识别专委会

本文简要介绍ICCV 2023录用论文“Revisiting Scene Text Recognition: A Data Perspective”的主要工作。场景文本识别(STR)是计算机视觉中的一个重要任务,用于识别自然图像中的文本,在自然场景理解中有着广泛的应用。近年来,STR已经得到了快速发展,并且最近的一些工作已经在六个常用测试基准(IC13、IC15、SVT、IIIT5K、SVTP、CUTE80)上取得了很高的准确率。这样的高准确率现象也引发了我们的一系列思考:STR是否已经解决了,或者说是常用的测试基准缺乏挑战,导致模型性能存在虚高,并且掩盖了STR模型在真实世界下的性能不足问题?本文从数据的角度出发,通过构建了一个大规模的场景文字识别数据集Union14M来重新审视场景文字识别,解答了上述疑问。并且本文利用MAE的自监督预训练范式,利用大规模的无标注数据,提出了一个在真实世界中具有较强泛化能的场景文字识别器 MAERec,为解决STR问题提供了一个数据驱动方案。相关代码和数据集已开源。
一、背景介绍
场景文字识别(STR)自2015年Shi等人[1]首次提出端到端网络CRNN后,便搭上深度学习的快车,迎来了快速的发展。随着新方法的不断提出,STR领域中的六个常用测试基准的准确率也在不断的提高。如图1所示,STR领域目前的最新进展已经有了准确率饱和的趋势。常用测试基准中的挑战似乎已经“解决”,表现为狭窄的准确率上升空间以及近期的 SOTA 模型性能提升的放缓上。这一现象启发我们提出了以下两个问题:1)常用测试基准是否仍足以推动 STR 领域未来的进展;2)常用测试基准准确率饱和是否意味着STR问题已经解决。
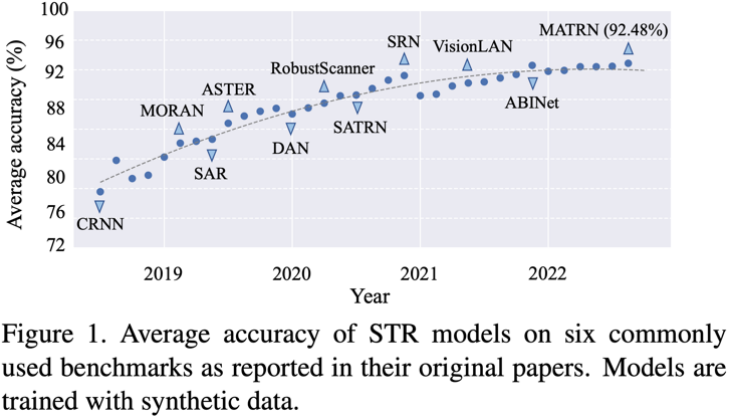
图1. STR模型在6个常用测试基准上的准确率变化曲线
二、问题一: 常用测试基准能否继续推动STR发展?
为了探究这个问题,我们选取了13个常用的STR模型,包括2个基于CTC的模型(CRNN,SVTR),7个基于Attention的模型(MORAN,ASTER,NRTR,SAR,DAN,SATRN,RobustScanner),4个语言模型(SRN,ABINet,VisionLAN,MATRN)进行测试。如图2所示,在7672张常用测试基准图片中,只有3.9%的样本无法被任何一个模型正确识别。其中,83.2%的样本在现有的STR范式下都是无法被正确识别的,包括标注错误样本(25.5%),垂直文本(22.5%),以及人类无法识别样本(35.2%),意味着这6个常用的测试基准可能最多只有1.53%的准确率提升空间。这说明现行的测试基准已经饱和,难以继续推动STR领域的发展。

图2. 六个STR常用测试基准上的错误样本分析
三、问题二: STR 是否已经解决
既然STR的测试基准已经达到了上限,那这是否能够说明STR已经解决了呢 ?为了回答这个问题,我们组建了一个大规模的,真实场景下的场景文字识别数据集 Union14M。Union14M由17个公开的数据集组建而成,包含有400万的标注数据(Union14M-L)以及1000万的高质量无标注数据(Union14M-U)。如图3所示,Union14M涵盖丰富的真实世界场景,包括弯曲文本、多方向文本、艺术字、复杂背景文本、模糊遮挡文本等,可以看作是对真实世界场景文字分布的一个广泛映射,从而使得我们可以评估STR模型在更加复杂且多样的真实场景下的性能表现。

图3. Union14M 数据概览
我们使用Union14M-L对13个常用并且公开的STR算法进行了测试,对比了他们在常用测试基准和Union14M-L上的准确率差异。如表一所示,尽管这13个STR算法在常用的STR测试基准上取得了较高性能,但是他们在Union14M-L上却有平均 20.50%的准确率下降。这说明现有的在合成数据上训练的STR算法缺乏泛化性,远远无法满足真实场景的需求。同时也回答了上述问题:STR远远没有解决。
表3. 常用STR模型在Union14M-L上的性能表现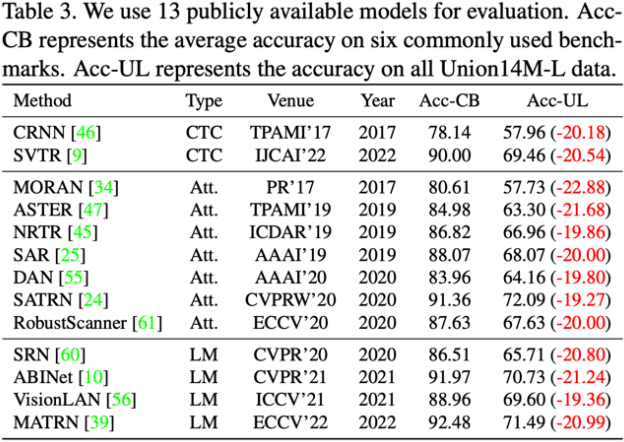
四、STR领域仍然面临的挑战

图4. STR 领域仍然面临的七个挑战
为了进一步分析STR模型在真实世界中面临的挑战,我们对模型的错误样本进行了分析,并总结了如下七个未彻底解决的研究问题:
1. 弯曲文本(Curve Text):弯曲文本识别在过去几年的是一个比较热门研究方向,其主要有两种主流做法:一种依赖于矫正机制,另一种则是采用二维注意力机制。这两种方法在曲线文本基准CUTE上都取得了有希望的结果。然而,CUTE基准中的曲线文本比例有限,曲率较小。对于像图4a所示的高度弯曲的文本,目前的方法仍然表现有限
2. 多方向文本(Multi-Oriented Text):文本可以以任何方向出现在任何物体表面上,包括垂直、倾斜或翻转的情况(图4b)。多方向文本在现实场景中很常见,例如广告牌上的垂直文本、由于摄像机的拍摄角度而倾斜的文本、以及由于镜面反射而翻转的文本。然而,在大多数STR方法中,这个问题被忽视了。这些方法有着一个较强的先验,那就是文本图像是水平的。这些方法会将文本图像的高度缩放到一个小尺寸(例如32像素),然后在保持比例不变的情况下缩放宽度,导致垂直或倾斜的图像在高度上坍塌,从而影响了识别。
3. 艺术字(Artistic Text):与印刷文本相反,艺术字是由艺术家或专业设计师设计的,具有多样的文本字体、文本效果、文本布局和复杂的背景。每个艺术字实例都有可能是独一无二的,这使得它成为一个零样本问题。然而,由于合成数据集中缺乏艺术字样本,目前的模型对于图4e中的艺术文本仍然不够鲁棒。
4. 无语义文本(Contextless Text)无语义文本可以是缩写词,或者字母、数字和符号的随机组合。如图4f所示,即使文本具有清晰的背景和极小的变形,模型仍然无法识别它们。这个问题可能源于模型设计或者数据集语料中过多引入语义信息,也被称为词汇依赖。模型会预测出现在训练集中遵循语法规则的文本(例如,在图4f中错误地将“YQJ”识别为“you”)。在可靠性至关重要的应用程序中,这种行为是无法接受的,例如车牌识别、发票识别或者身份证识别等。这些场景中大部分文本都是无语义的,并且它们的错误识别可能会导致巨大的安全风险和财产损失。
5. 显著性文本(Salient Text). 显著文本是指在文本图像中除了有需要识别的主要字符外,还有共存的额外字符(图4c)。在端到端文本识别中,当不同大小的文本实例相邻或重叠时,可能会无意中引入显著性文本。当检测模型的性能较差时,例如只能输出粗略的文本区域时,识别模型能够关注于视觉重要区域的能力就变得至关重要。然而,如图4c所示,模型可能会因为额外字符而产生混淆,无法识别主要文本。
6. 多词文本(Multi-Words Text).在大多数场景下,我们需要同时识别多个单词以完全解释一个包含文本的自然场景,例如商标和短语。然而,大多数STR模型是在由每个文本图像仅包含一个单词的合成数据集上进行训练的。并且我们观察到模型倾向于将多个单词合并为一个单词,并根据语法规则丢弃或改变可见字符(如图4d所示,“Live to Evolve”被识别为“liveroee”,因为它更像是一个单词)。
7 残缺文本(Incomplete Text).由于遮挡或不准确的检测框,文本图像可能是不完整的。在图4g中,当文本图像的第一个或最后一个字母被裁剪时,模型可能会自动补全预测,即使缺失的字母是不可见的。这个特点可能会降低模型在文本分析应用中的可靠性。例如,一个碎片化的文本图像上写着“ight”,可能就会被预测为“might”或“light”,但是最好的输出应该是识别模型实际看到的“ight”,从而可以引入人工进行异常检测的处理。我们希望模型能够所见即所得。因此,对识别模型自动补全特性的评估,并考虑其对下游应用可能产生的潜在影响是至关重要的。
为了在更全面的真实场景下评估STR模型,并促进对前面提到的七个挑战的未来研究,我们构建了一个问题驱动的测试基准,名为Union14M-Benchmark。它包括八个子集,总共有409,393张图像。
表4. Union14M-Benchmark

五、基准实验
我们在Union14M-L上对上述13个STR模型进行基准测试(表5),以提供更多的定量分析结论。
表5和表6 基准实验结果
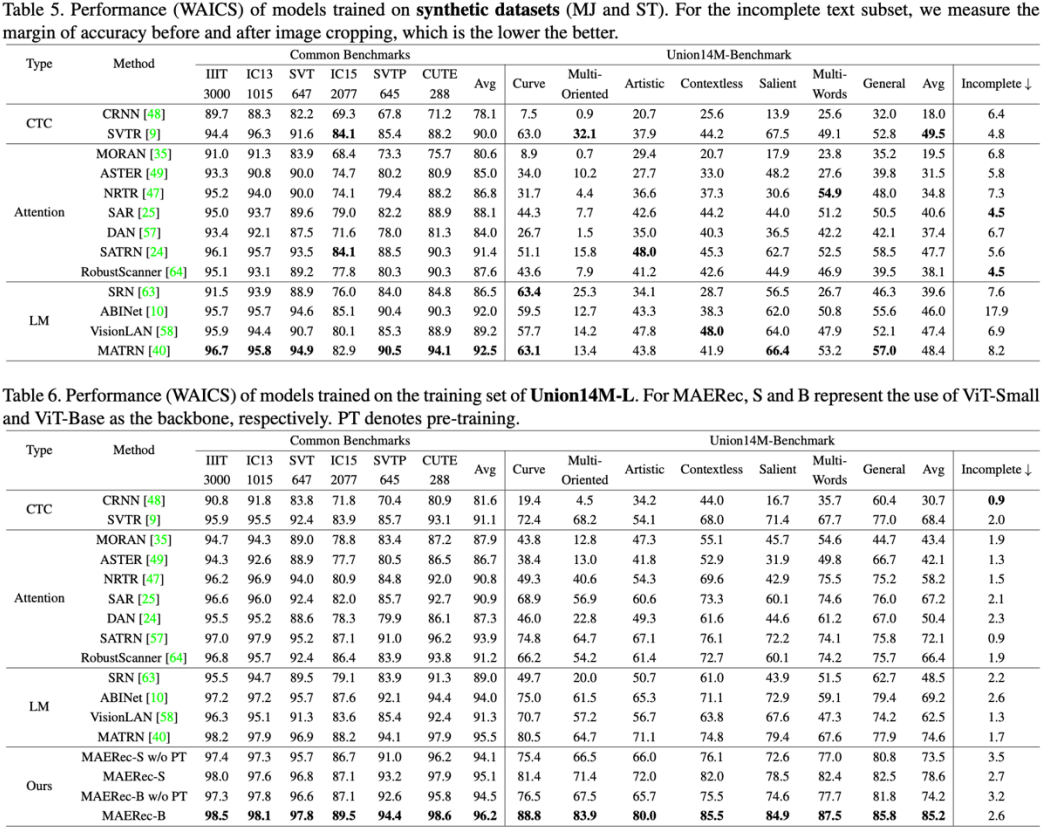
结论1: 真实世界的数据是具有挑战性的。如表5和表6所示,与在常用的测试基准相比,当在合成数据集和Union14M-L上训练时,模型在Union14M-Benchmark上的平均准确率下降了48.5%和33.0%。这表明真实场景中的文本图像要比六个常用测试基准更加复杂。
结论2: 真实世界的数据是有效的。在Union14M-L上训练的模型可以在常用的测试基准上平均提高3.9%的准确率,并在Union14M-Benchmark上提高19.6%的准确率。常见基准测试上相对较小的性能提升也暗示了它们的饱和状态。
结论3: STR仍然远未解决。当仅在Union14M-L上进行训练时,我们观察到在Union14M-Benchmark上的最大平均准确率仅为74.6%。这表明STR远未解决。虽然依赖大规模真实数据可以带来一定的性能提升,但是仍然需要STR社区的进一步研究。
六、数据驱动的STR解决方案
为了进一步探索从数据角度来解决STR的潜力,我们提出了一个基于MAE自监督预训练的场景文字识别模型,名为MAERec。

图5. MAERec 示意图
为了利用Union14M-U中的1000万张无标签图像,我们使用MAE的预训练范式,对MAERec中的ViT骨干网络进行预训练。预训练的重建结果如图7所示。尽管掩码比例高达75%,在Union14M-U上预训练的ViT骨干网络仍然可以高质量重建文本图像。这表明预训练的ViT骨干网络能够有效地捕捉文本图像中的文本结构,并学习到有用的文本表征。

图6. MAE重构效果
在预训练之后,我们使用预训练的ViT权重初始化MAERec,并在Union14M-L上对整个模型进行微调。结果如表6所示。在使用ViT-Base作为骨干网络时,MAERec在Union14M-Benchmark上的平均准确率达到了85.2%,大幅高于目前STR领域的SOTA方法。MAERec在真实场景下的性能极强,如下图所示,MAERec可以识别各种复杂文本,并且具有大小写敏感,可识别空格的特性。这个结果表明在真实世界场景中,利用大规模无标签数据可以显著提高STR模型的性能,并且值得进一步探索。
 图12. MAERec 识别效果
图12. MAERec 识别效果
七、总结
在本文中,我们从数据的角度重新审视了场景文本识别。尽管常用的测试基准接近饱和,但我们认为STR问题远未解决。为了发掘STR模型仍然面临的挑战,我们整合了一个大规模的数据集Union14M进行分析,并引出了七个开放性挑战。此外,我们也提出了一个问题驱动的测试基准,以促进STR领域的未来发展。我们发现通过自监督预训练可以显著提升STR模型在真实场景中的性能,为STR领域提供了一条数据驱动的解决方案。我们希望这项工作能够激发出超越现有数据范式的未来研究。
代码地址:https://github.com/Mountchicken/Union14M
论文地址:https://arxiv.org/pdf/2307.08723.pdf
在线Demo:https://huggingface.co/spaces/Mountchicken/MAERec-Gradio
八、参考文献
[1] Baoguang Shi, Xiang Bai, and Cong Yao. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell., 39(11):2298–2304, 2017.
原文作者:Qing Jiang, Jiapeng Wang, Dezhi Peng, Chongyu Liu, Lianwen Jin
撰稿:蒋 擎 编排:高 学
审校:殷 飞 发布:金连文
ICCV / CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集OCR和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-OCR或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如OCR或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看![]()















 1107
1107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









