






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
本文介绍深度均衡目标检测算法DEQDet,发表在ICCV2023上。

Deep Equilibrium Object Detection
论文:https://arxiv.org/abs/2308.09564
代码:github.com/MCG-NJU/DEQDet
在CVer后台回复:DEQDet,可下载本论文和代码
一. 研究动机
目标检测是计算机视觉中的一个基础任务,从DETR开始,当前主流的基于Query的目标检测器通过将图片中的object instances表示为一系列的可学习Query。之后通过stack起来的多层不共享参数的解码器层对可学习Query进行微调(refinement),即通过Attention或者MLPMixer将采样的图像特征融合到Query中,最终得到稳定的object instances表示,这些表示可以通过FFN解码为object的类别和包围框信息。
虽然基于Query的目标检测范式取得了不错的结果,但是其设计范式中仍旧存在着一些问题:
参数冗余性:每一层decoder layer用不同的参数做着同样的事情,这其中肯定存在着极大的参数浪费以及过拟合风险,那参数的最小极限在什么地方呢?
解码器深度:DETR的实验中也表明,增加更多decoder层数对于性能是提升的,而现在常用的的6层结构,还远远没有表现出饱和的迹象,那这个性能上限在什么地方呢?
为了回答或者解决上面提到的两个问题,我们首先将现有的基于Query的目标检测器建模为一个FFN的视角,基于此,我们可以拓展出一个RNN视角的目标检测器,即通过weight tying策略将Decoder layer每一层共享,将FFN的目标检测器转化为一个RNN的目标检测器RNNDet,之后我们将RNN的微调(refinement)层数通过DEQ模型拓展到一个极端情况得到DEQDet。这和光流领域的RAFT到DEQ-flow有很多相似之处,但是目标检测问题具有的高维语义理解特性以及object 的稀疏特性使得两者实际存在很大差异。
二. 方法介绍
AdaMixer Revisit
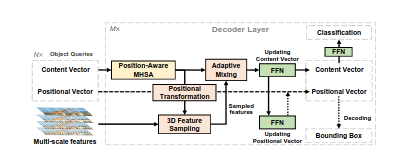
DEQDet基于AdaMixer,首先回顾一下AdaMixer的结构。如图所示,AdaMixer中的Query包含content向量和position向量;decoder layer包含一个多头注意力层(MHSA),3D 特征采样层,自适应采样混合层(Adapative mixing)和多个用于特征变换的FFN。Query首先进入多头注意力层,进行Query之间的信息交互,其中位置编码由positon向量的绝对位置编码和基于iof的相对位置编码构成;更新之后的content向量预测相对于position向量的offsets,这些offset和positon向量通过positional transformation转化成采样点,通过3D 特征采样层在多尺度特征空间进行采样;采样得到的特征和更新后的Query进入自适应采样混合层进行空间信息融合(spatial mixing)和特征信息融合(content mixing)。融合后的content经过FFN预测残差更新position向量。AdaMixer使用多层相同结构的decoder layer更新Query,最终通过FFN将content向量解码成类别分布,通过解码position向量得到物体的包围框。
FFNDet 检测器范式
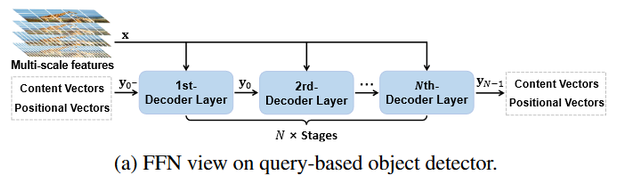
现有的Query-based的目标检测器的Decoder部分服从FFN的范式,其中第一层decoder layer进行将与图片内容无关的可学习Query转化成和图片内容强相关的Query(initialization),后续继续使用不共享参数的一系列decoder layer对输入的object表示Query进行不断微调(refinement)。数学表示如下:

RNNDet检测器范式
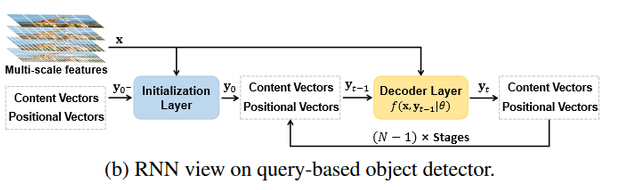
我们首先将FFNDet的第一层和其他层独立出来,称为初始化层(initialization layer),进行图片内容无关的可学习Query到图片内容强相关的Query的初始化;将之后的所有层通过参数共享(weight tying)转化为一个RNN形式的微调层(refinement layer)。数学形式如下所示:

DEQDet检测器范式
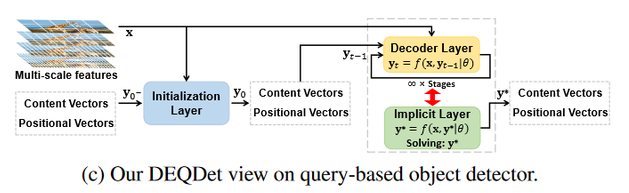
我们通过DEQ模型将RNN的层数拓展到无限层,等价于进行无限次的微调:
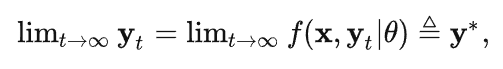
通过DEQ模型将无限次微调转化为一个不动点迭代问题,将最终的稳定表示Query解码得到物体的类别置信度和包围框信息。
这里简单介绍一些深度均衡模型(DEQ),其实就是将深度网络看作一个不动点迭代:
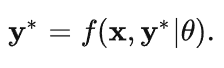
那么这一层的梯度则由如下公式给出:
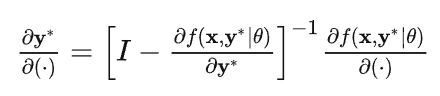
代码实现过程中会结合自动求导框架(pytorch等)的后向求导,或者说JVP,将深度均衡模型的梯度求解也变成一个不动点迭代。
可以发现,前向要不动点迭代,反向传播还要不动点迭代,时间开销是很大的。因此有了一些对DEQ模型的梯度进行估计的算法,JFB(jacobian-free-backpropogation)就是直接把中间雅可比逆矩阵这一项替换成单位矩阵(纽曼级数只取第一项),DEQ-flow中用的正是这种。
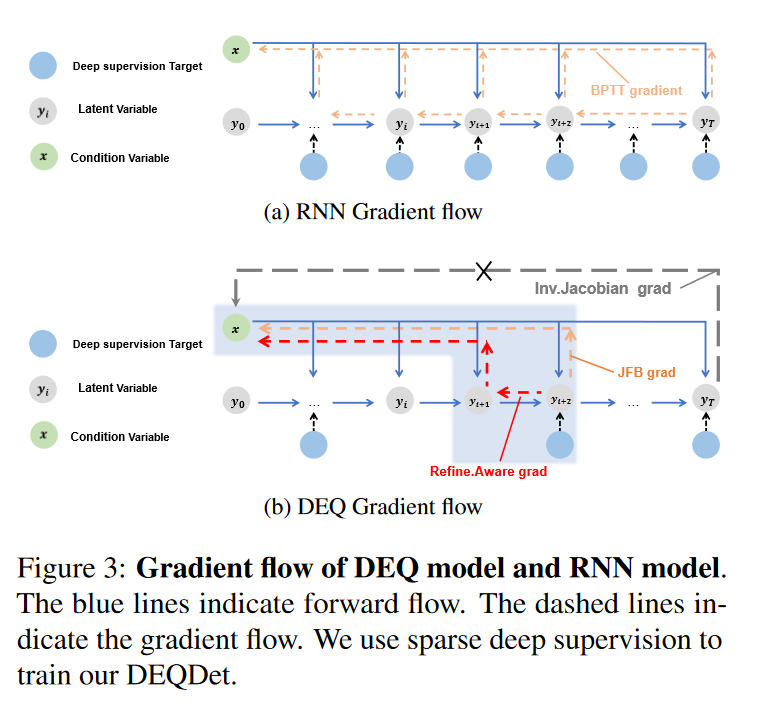
DEQDet的训练算法
RNNDet的训练和主流基于Query的目标检测器训练过程相同。DEQDet的训练算法由RAP(微调感知扰动)和RAG(微调感知梯度)两部分构成。

三. 实验介绍
RNNDet 和 DEQDet 实验
其中NF(num of fucntion)表示总共的有效decoder layer。
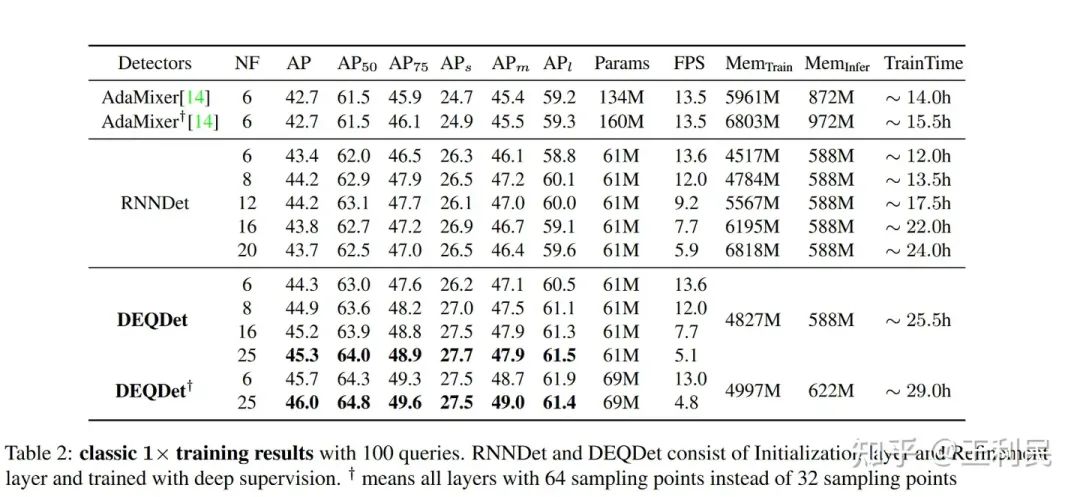
可以看到:

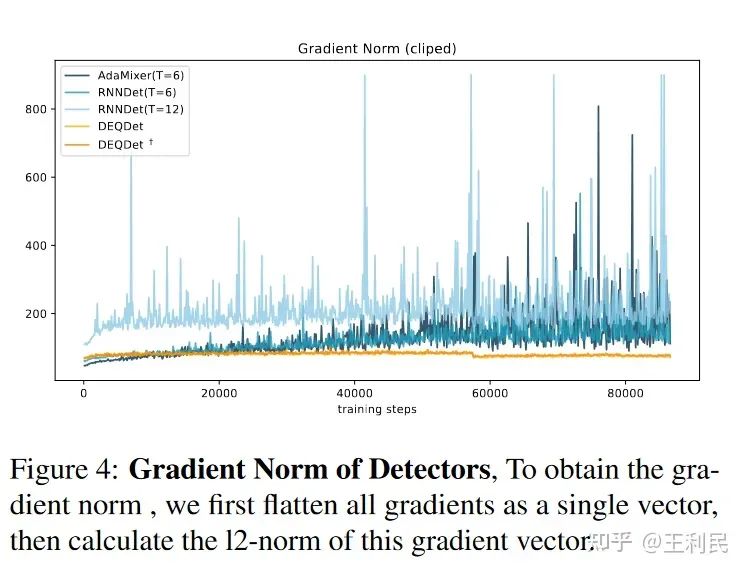
3. 得益于DEQDet的训练策略,DEQDet可以轻松超过RNNDet和FFNDet(原本adamixer的结构)
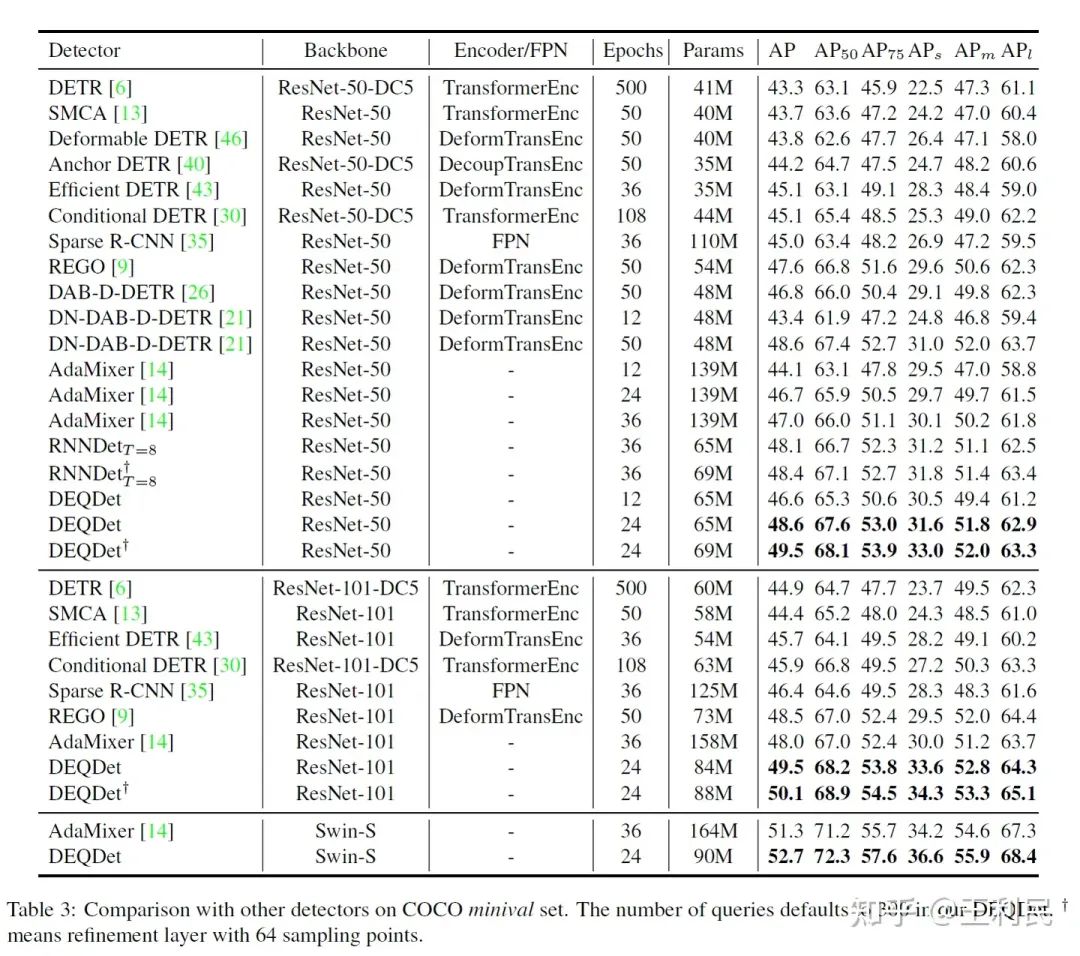
和其他检测器的对比
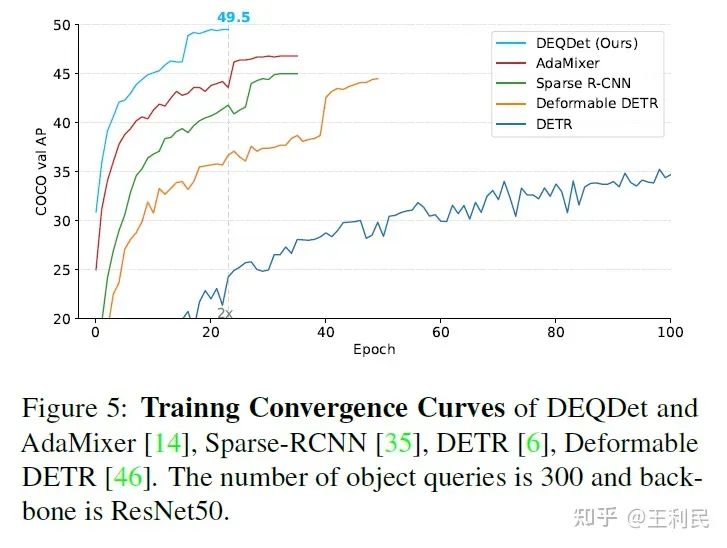
我们的实验证明了 DEQDet收敛速度更快、内存消耗更少、效果更好。结果优于基线模型(AdaMixer)。特别是,在 ResNet50 backbone和 300 queries 设定下,DEQDet在 COCO数据集 上实现了 49.5 mAP 和 33.0 AP small 24个epoch)下的检测效果。
四. 总结
在这篇文章中,我们提出了一个深度均衡目标检测器(DEQDet),为Query based检测器提供了新思想,将目标检测器的decoder layer的refinement微调过程等价建模成一个不动点迭代。DEQDet的训练中,我们发现基于简单估计(JFB)的梯度求解没有感知微调过程的能力,造成了目标检测器的性能下降,针对此我们提出了RAG(微调感知梯度)和RAP(微调感知扰动)来弥补基于简单估计的梯度求解缺乏微调感知的问题。我们的实验证明了 DEQDet收敛速度更快、内存消耗更少、效果更好。结果优于基线模型(AdaMixer)。特别是,在 ResNet50 backbone和 300 queries 设定下,DEQDet在 COCO数据集 上实现了 49.5 mAP 和 33.0 AP small 24个epoch)下的检测效果。
在CVer微信公众号后台回复:DEQDet,可下载本论文和代码
参考文献
[1] Ziteng Gao, Limin Wang, Bing Han, and Sheng Guo. Adamixer: A fast-converging query-based object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5364–5373, 2022.
[2] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-toend object detection with transformers. In Proceedings of the European conference on computer vision, pages 213–229, 2020
[3] Shaojie Bai, Zhengyang Geng, Yash Savani, and J Zico Kolter.Deep equilibrium optical flow estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 620–630, 2022.
[4] Shaojie Bai, J Zico Kolter, and Vladlen Koltun. Deep equilibrium models. Advances in Neural Information Processing Systems, 32, 2019
[5] Zhengyang Geng, Xin-Yu Zhang, Shaojie Bai, Yisen Wang, and Zhouchen Lin. On training implicit models. Advances in Neural Information Processing Systems, 34:24247–24260,2021
ICCV / CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看![]()















 892
892











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









