






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
在CVer微信公众号后台回复:MAGVIT2,可以下载本论文pdf,快学起来!
白交 发自 凹非寺
转载自:量子位(QbitAI)
语言模型击败扩散模型,在视频和图像生成上实现双SOTA!
这是来自谷歌CMU最新研究成果。

论文:https://arxiv.org/abs/2310.05737
https://magvit.cs.cmu.edu/v2/
据介绍,这是语言模型第一次在标志性的ImageNet基准上击败扩散模型。
而背后的关键组件在于视觉分词器(video tokenizer) ,它能将像素空间输入映射为适合LLM学习的token。
谷歌CMU研究团队提出了MAGVIT-v2,在另外两项任务中超越了之前最优视觉分词器。
大语言模型击败扩散模型
已经形成共识的是,大语言模型在各个生成领域都有出色的表现。比如文本、音频、代码生成等。
但一直以来在视觉生成方面,语言模型却落后于扩散模型。
团队认为,其主要原因在于缺乏一个好的视觉表示,类似于自研语言系统,能有效地对视觉世界进行建模。与自然语言不同,人类会对视觉世界尚未演化出最佳的词汇。而这也限制了大语言模型的视觉生成能力。
基于这样的判断,这篇研究主要完成了三项工作:
提出一种新的视觉tokenizer,在视觉生成、视频压缩以及动作识别都优于此前最优表现。
一种全新无查找(lookup-free)的量化方法,可通过学习大量词汇来提高语言模型的视觉生成质量;
首次有证据表明,在相同训练数据、等效模型大小和类似训练预算的条件下,语言模型在ImageNet上击败扩散模型。
据作者介绍,这也是视觉分词器首次成功地实现了与标准编解码器相媲美的效果。
在原有SOTA视觉tokenizerMAGVIT (Masked Generative Video Transformer)基础上,该方法主要完成了两种设计:无查找量化(Lookup-Free Quantization ,LFQ)以及图像-视频联合tokenizer。
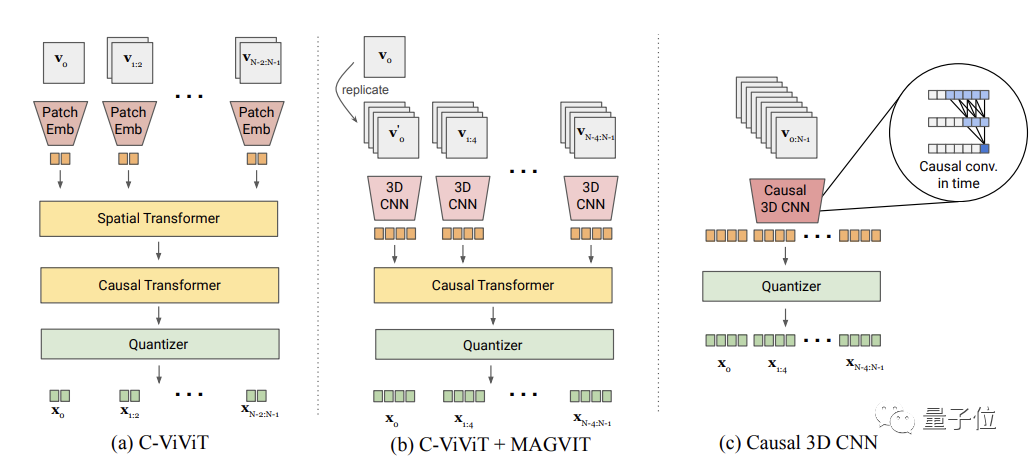
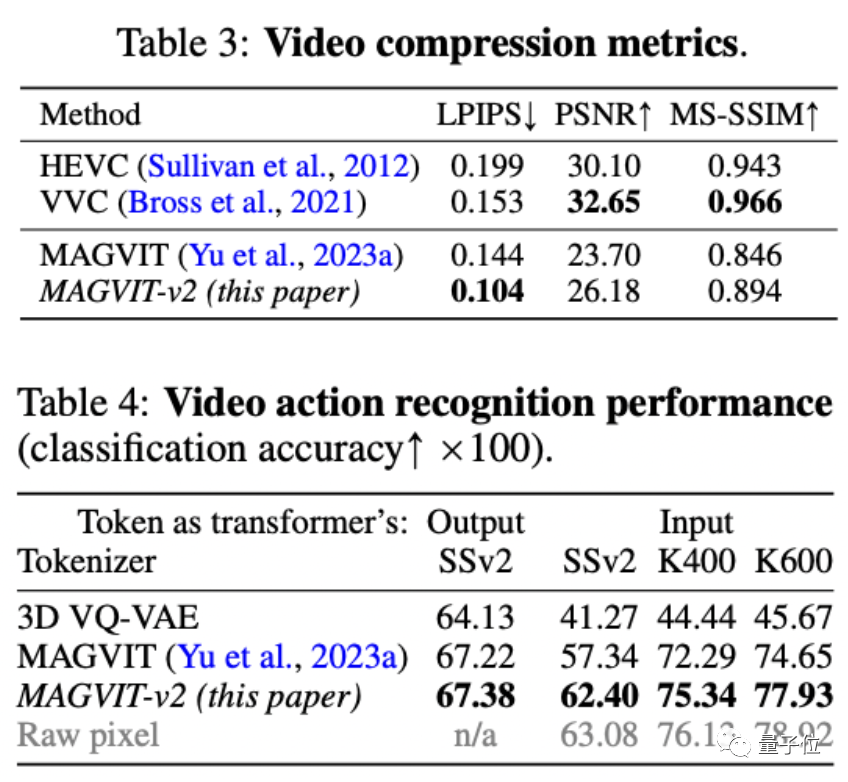
最终在视频/图像生成,ImageNet 512×512和Kinetics-600,都优于Diffusion Model。

而在视频压缩、动作识别上,也优于以往的结果。
一作是北大校友
一作于力军目前是CMU计算机科学学院语言技术研究所博士生,师从Alexander G. Hauptmann教授,同时也是谷歌学生研究员。研究兴趣在于多模态基础模型,特别是多任务视频生成。
在来到CMU前,他在北大获得了计算机和经济学双学士学位。

在研究团队中也看到了其他不少华人面孔。
通讯作者蒋路,目前是谷歌研究院科学家以及CMU的兼职教授。
他的研究主要针对多模态大数据科领域,特别是鲁棒深度学习、生成式人工智能和多模态基础模型。
在CVer微信公众号后台回复:MAGVIT2,可以下载本论文pdf,快学起来!
ICCV / CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集多模态和扩散模型交流群成立
扫描下方二维码,或者添加微信:CVer444,即可添加CVer小助手微信,便可申请加入CVer-多模态或者扩散模型 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如多模态或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer444,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球▲点击上方卡片,关注CVer公众号
















 764
764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









