







Paper name
(MAGVIT-v2) Language Model Beats Diffusion: Tokenizer is key to visual generation
Paper Reading Note
Paper URL: https://arxiv.org/abs/2310.05737
Project URL: https://magvit.cs.cmu.edu/v2/
Code URL: https://github.com/lucidrains/magvit2-pytorch
TL;DR
- 2023 年 google 和 CMU 的文章,介绍了视频 tokenizer MAGVIT-v2,旨在使用共同的词汇表为视频和图像生成简洁而富有表现力的 token。如论文标题提到的,该研究首次在 ImageNet 数据集上展示了基于 LLMs 的生成效果超过扩散模型。
Introduction
背景
- 虽然大型语言模型(LLMs)在语言生成任务上占据主导地位,但在图像和视频生成方面,它们并不如扩散模型表现出色。例如在 Imagenet 上评估时,使用 256x256 的分辨率,Draft-and-Revise 比 Masked Diffusion Transformer (MDT) 精度差(FID 3.41 vs 1.79)
- 作者认为 LLMs 和 diffusion 模型有差距的一个主要原因是缺少一个好的视觉表征,也就是说一个好的视觉分词器(tokenizer)能够带来更好的生成效果
- LLMs 用于视觉生成任务,与其他方法的主要不同点是使用离散的特征形式,也即从视觉分词器获取的 token。这样的好处有:
- 和大语言模型架构兼容:能利用上社区多年来对大语言模型架构积累的优化。同时统一文本和图像的 token space 有利于真正的多模态模型研发
- 压缩视觉特征表示:降低存储和带宽,提升生成效率
- 对视觉理解有利:先前的研究表明,离散 token 在自监督表示学习的预训练目标中具有价值,正如在 BEiT 和 BEVT 中所讨论的那样,将 token 用作模型输入有助于提高模型的鲁棒性和泛化能力
本文方案
- 为了有效地利用 LLMs 进行视觉生成,其中一个至关重要的组件是视觉分词器,它将像素空间的输入映射到适用于 LLMs 学习的离散 token。本文中介绍了 MAGVIT-v2,一个视频分词器,旨在使用共同的 token 词汇表为视频和图像生成简洁而富有表现力的 token。搭载了这个新的分词器,本文展示了 LLMs 在标准图像和视频生成基准测试中胜过扩散模型,包括 ImageNet 和 Kinetics。此外,本文证明了所提出的分词器在两个额外的任务上超越了先前表现最佳的视频分词器:(1)根据人类评估实现与下一代视频编解码器(VCC)相媲美的视频压缩,以及(2)为动作识别任务学习有效的特征表示。
- 论文介绍了两种新技术:
- 首先,提出了一种新的无查找 (lookup-free) 量化方法,使得能够学习一个大型词汇表,从而提高语言模型的生成质量。
- 其次,通过广泛的实证分析,确定了对分词器的修改,这些修改不仅提高了生成质量,还使得使用共享词汇表对图像和视频进行分词成为可能
Methods
lookup-free quantizer (LFQ)
-
改善重建质量与随后生成质量之间的关系暂时还没有明确定论。一个常见的误解是,提高重建等同于提高语言模型的生成能力。例如,扩大词汇表可以提高重建质量。然而,这种改进仅在词汇表大小较小时才会扩展到生成阶段,而且非常庞大的词汇表实际上可能会损害语言模型的性能。如下图所示:对于传统的 VQ 方法,当词汇表大小从 2 10 = 1024 2^{10}=1024 210=1024 增加到 2 16 = 65536 2^{16}=65536 216=65536 时,重建精度都是不断提升,不过生成精度仅在 2 10 = 1024 2^{10}=1024 210=1024 增加到 2 14 = 16384 2^{14}=16384 214=16384 之间才能提升,在 2 16 2^{16} 216 时精度反而有较大程度降低。一个合理的猜测是词汇表太大了第二阶段进行 token 预测的训练难度会显著提升
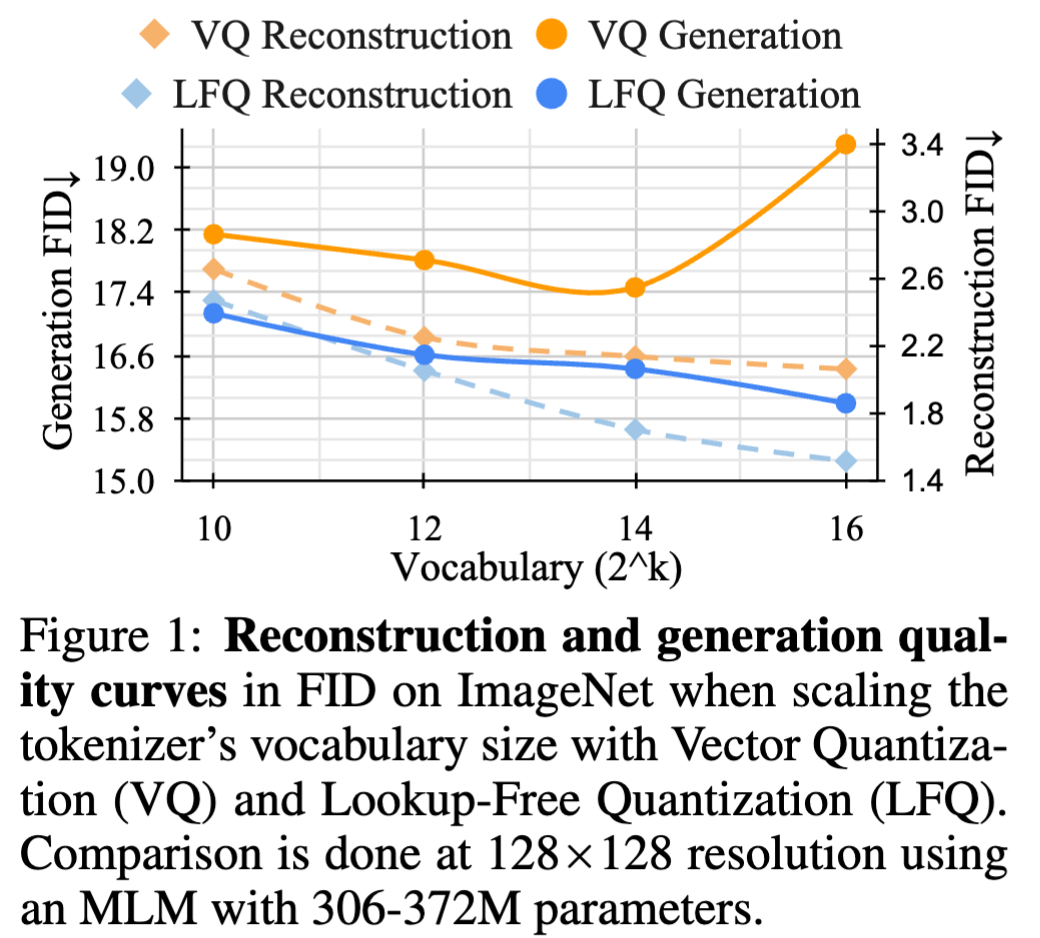
-
训练更大的码书的一个简单技巧是在增加词汇表大小时减少编码嵌入维度。基于以上观察,直接将 VQVAE 的 codebook embedding 维度降低为 0:原始 codebook C ∈ R K × d C \in \mathbb{R}^{K \times d} C∈RK×d 改为一个整数集 ∣ C ∣ = K |\mathbb{C}| = K ∣C∣=K,因为省去了之前的查表过程所以起名为 LFQ。LFQ 可以训练更大的 codebook 从而对后续生成更有利
-
本文引入了一种 LFQ 直接的变体,它假设码本维度独立和 latent 变量为二进制。具体而言,LFQ 的潜在空间被分解为单维变量的笛卡尔积: C = X i = 1 l o g 2 K C i \mathbb{C} = X^{log_{2}K}_{i=1} C_{i} C=Xi=1log2KCi。给定一个特征 z ∈ R l o g 2 K z \in \mathbb{R}^{log_{2}K} z∈Rlog2K,量化表示 q ( z ) q(z) q(z) 的每个维度由以下公式分别计算:
q ( z i ) = C i , j , j = a r g m i n k ∥ z i − C i , k ∥ q(z_{i})=C_{i,j}, j = arg min_{k} \| z_i -C_{i,k}\| q(zi)=Ci,j,j=argmink∥zi−Ci,k∥
其中 C i , j C_{i,j} Ci,j 是 C i C_{i} Ci 中的第 j 个值。 C i = { − 1 , 1 } C_i=\{-1, 1\} Ci={−1,1} , a r g m i n arg min argmin 基于符号函数计算:
q ( z i ) = s i g n ( z i ) = − 1 { z i ≤ 0 } + 1 { z i > 0 } q(z_i) = sign(z_i) = -\mathbf{1}\{z_i \leq 0 \} +\mathbf{1}\{ z_i > 0 \} q(zi)=sign(zi)=−1{zi≤0}+1{zi>0}
基于 LFQ, q ( z ) q(z) q(z) 的 token index 计算方式为:
I n d e x ( z ) = ∑ i = 1 l o g 2 K a r g m i n k ∥ z i − C i , k ∥ ∏ i = 1 l o g 2 K 2 i − 1 1 { z i > 0 } Index(z)=\sum_{i=1}^{log_2 K}{arg min_{k} \| z_i -C_{i, k}\| \prod_{i=1}^{log_2 K}{2^{i-1}\mathbf{1}\{z_i > 0\}}} Index(z)=∑i=1log2Kargmink∥zi−Ci,k∥∏i=1log2K2i−11{zi>0}
其中 ∥ C 0 ∥ = 1 \| C_0 \| = 1 ∥C0∥=1 -
在训练过程中添加熵惩罚以鼓励码书的使用
L e n t r o p y = E [ H ( q ( z ) ) ] − H [ E ( q ( z ) ) ] L_{entropy} = \mathbb{E}[H(q(z))] - H[\mathbb{E}(q(z))] Lentropy=E[H(q(z))]−H[E(q(z))]
LFQ 的代码实现(参考:LFQ)
- 之前的公式描述理解起来不太直观,直接看代码可能会更为直观。简单来说就是将输入张量中的每个元素转换为其符号,即正数变为1,负数变为-1。由于 magvitv2 所需要实现的是将输入 tensor 中的每个位置转换为词汇表中的位置,也即一个整数张量。这需要将符号化值张量转换为整数值张量:对于每个位置,根据是否为正数,分配一个权重为 2 的幂次值,然后计算每个位置的加权和。这样,整个张量就被映射到一个整数。直观的理解就是通过二进制实现了将元素映射为词汇表的位置,网络预测的是词汇表大小的二进制表示中每个位置的值,比如对于 2 n 2^n 2n 大小的词汇表,网络对于 tensor 每个位置预测一个长度为 n n n 的张量,然后将该张量通过二进制转十进制的方式得到在词汇表中的位置。
import torch
class LookupFreeQuantizer:
def __init__(self, vocab_size: int=None):
"""
初始化方法
:param vocab_size: 词汇表大小,表示要将实数值张量映射到的整数范围。如果未提供,表示不限定词汇表大小。
"""
self.vocab_size = vocab_size
def sign(self, z: torch.Tensor):
"""
将张量中的每个元素转换为其符号
:param z: 包含实数值的张量
:return: 符号化的张量
"""
q_z = torch.sign(z)
q_z[q_z == 0] = -1 # 将零元素转换为-1
return q_z
def token_index(self, q_z: torch.Tensor):
"""
将符号化值张量转换为整数值张量
:param q_z: 符号化的张量
:return: 整数值张量
"""
indices = (torch.arange(q_z.size(-1), dtype=torch.float32)).to(q_z.device)
tokens = torch.sum(2**indices * (q_z > 0).float(), dim=-1)
return tokens
def quantize(self, z: torch.Tensor):
"""
对实数值张量进行量化
:param z: 包含实数值的张量
:return: 符号化的值和整数值张量
"""
if self.vocab_size is not None:
assert z.size(-1) == torch.log2(self.vocab_size)
q_z = self.sign(z)
index = self.token_index(q_z)
return q_z, index.int()
VISUAL TOKENIZER MODEL IMPROVEMENT
联合图像和视频 tokenizer
- 视觉 tokenizer 的一个理想特性是能够使用共享的码书对图像和视频进行 token 化。然而,利用 3D CNN 的 MAGVIT tokenizer 在 token 图像方面面临挑战,这是由于时间感受野的存在。
- 如下图所示,C-ViViT 采用完整的空间变换块结合因果时间变换块,有两个缺点:
- 与 CNN 不同,位置嵌入使得在训练期间未见过的空间分辨率难以进行标记化
- 其次,经验上我们发现 3D CNN 比空间 transformer 表现更好,并生成具有相应补丁的更好的空间因果关系的 token
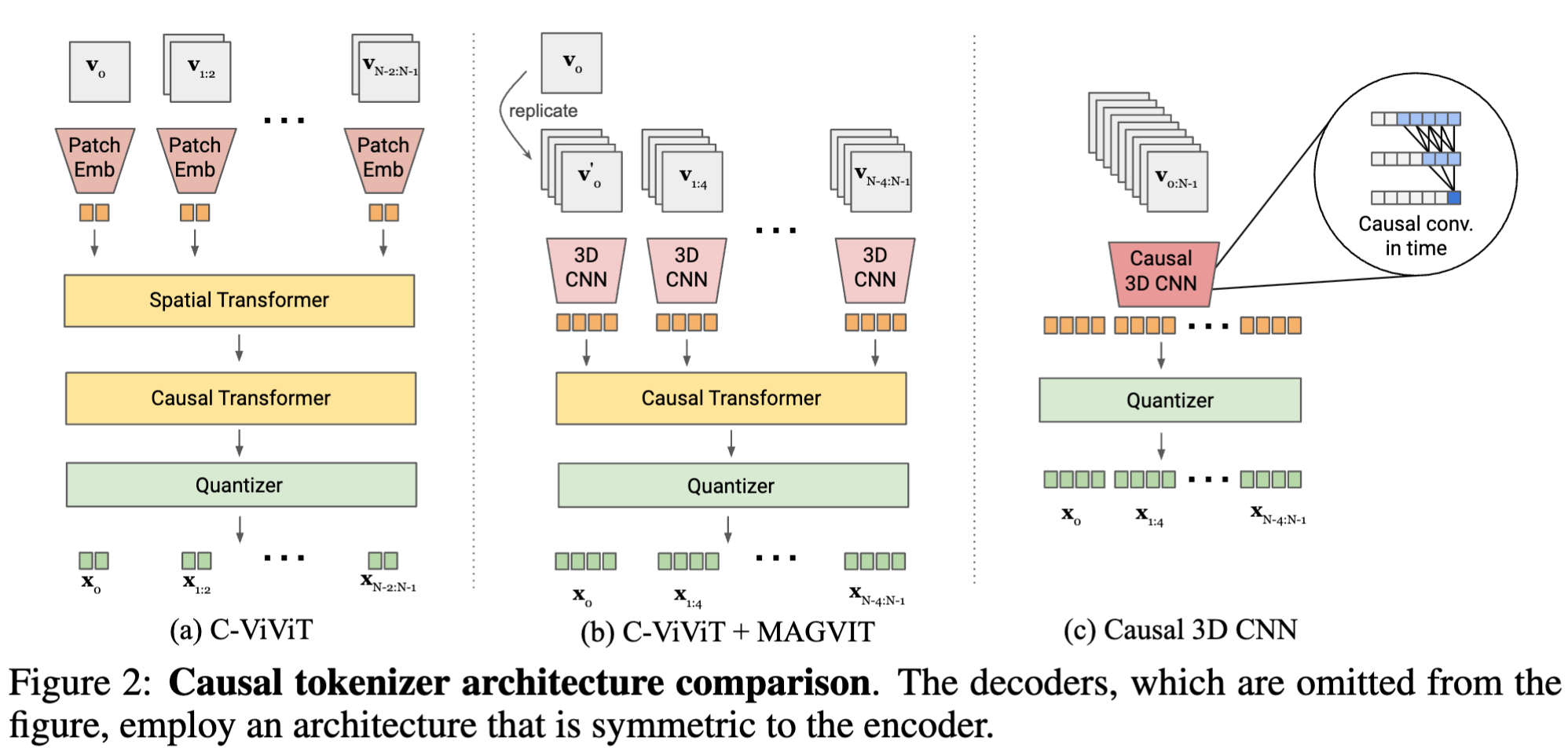
为了解决这些缺点,我们探索了两种可能的设计。上图 b 将 C-ViViT 和 MAGVIT 结合起来。假设时间压缩比为 4,3D CNN 处理 4 帧的块,然后是因果 transformer。在图 c 中,我们使用时间上因果的 3D 卷积(causalcnn)替换常规 3D CNN。具体而言,对于内核大小 k t k_t kt、 k h k_h kh、 k w k_w kw 的常规 3D 卷积层,时间填充方案包括在输入帧之前填充 ⌊ k t − 1 2 ⌋ \lfloor{\frac{k_{t}-1}{2}}\rfloor ⌊2kt−1⌋ 帧,在输入帧之后填充 ⌊ k t 2 ⌋ \lfloor{\frac{k_{t}}{2}}\rfloor ⌊2kt⌋ 帧。相反,因果 3D 卷积层在输入之前填充 k t − 1 {k_{t}-1} kt−1 帧,之后不填充,因此每个帧的输出只取决于先前的帧。因此,第一帧始终独立于其他帧,允许模型对单个图像进行标记化。
架构改动
- 除了上述的 causalcnn 改动,相比于 magvit, magvit2 还有以下改动:
- 将编码器下采样器从平均池化改为步进卷积
- 用深度到空间运算符替换解码器上采样器
- 将时间下采样从第一个编码器块推迟到最后几个块
- 鉴别器中的下采样层现在使用 3D 模糊池化(3D blur pool)以促使平移不变性
- 在解码器中每个分辨率的残差块之前添加一个自适应组归一化层,以将量化潜变量作为控制信号传递,遵循 StyleGAN
用于高效预测的 token 分解
- 输出的 token 可以送到语言模型中生成视频。为了协助较小的 transformer 在大词汇中进行预测,我们可以将 LFQ token 的潜空间分解为相等的子空间。例如,我们可以使用两个连接的大小为 2 9 2^9 29 的码书进行预测,而不是使用大小为 2 18 2^{18} 218 的码书。我们分别嵌入每个子空间 token,并使用它们的嵌入求和作为 transformer 输入的 token 嵌入。对于带有权重绑定的输出层,我们使用每个子空间的嵌入矩阵获得 logits,并具有独立的预测头。
Experiments
实验数据
- video generation: Kinetics-600 (K600) 和 UCF-101
- image generation: ImageNet
- video compression: MCL-JCV
- video understanding: Kinetics400 (K400) 和 SSv2
实验配置
- 词汇表的 K = 2 18 K=2^{18} K=218,也即词汇表的长度为 262144
- Lentropy 设置一个不断衰减的权重
- tokenizer 训练细节
- 训练两个版本 16x 下采样和 32x 下采样,提取的特征尺度都是 16x16,分别用于生成 256px 和 512px 的图片
- 训练 270 epoch,batch size 256,均使用 256x256 图片训练
- video tokenizer 通过 image tokenizer 进行初始化,基于 128x128 分辨率训练。discriminator 为了训练稳定性选择 from scratch 训练。在 kinetics-600 上训练 190 epoch,batch size 256
图片重建对比

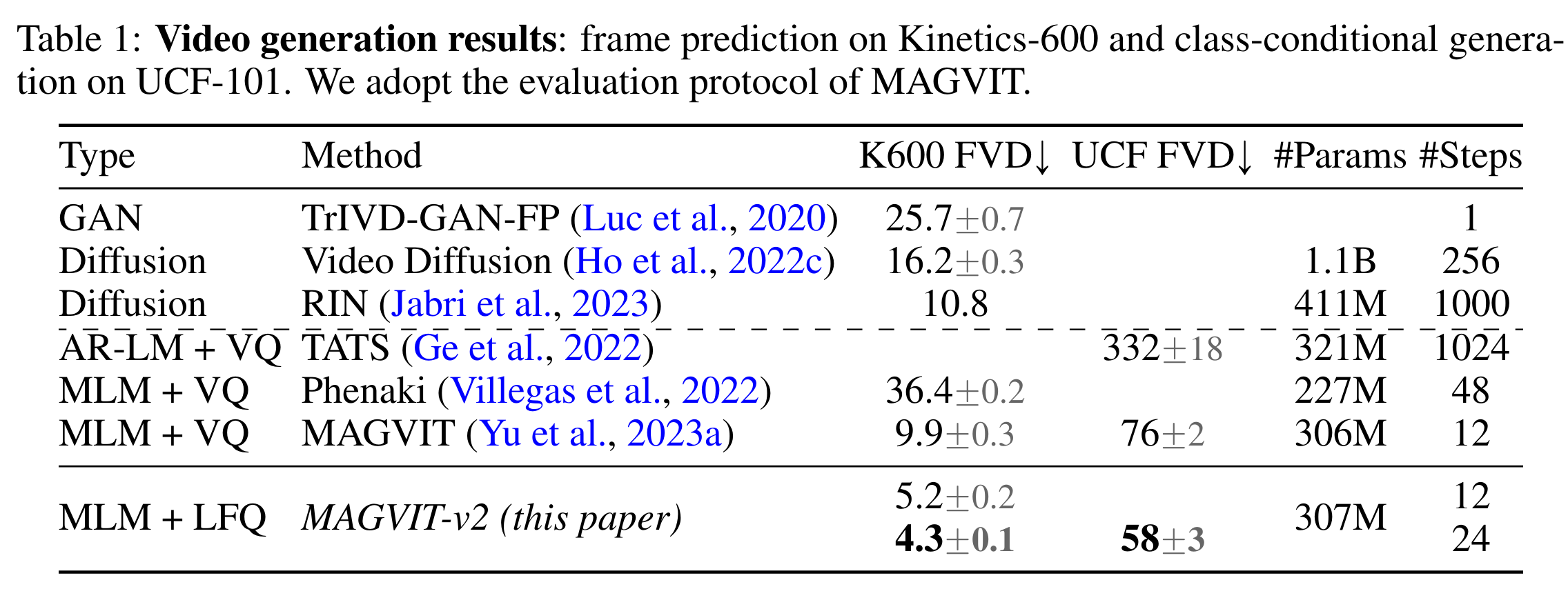
视频生成实验
- 使用 5 帧作为 condition,与 MAGVIT 使用相同的 MLM transformer backbone 情况下,FVD 值远低于 MAGVIT

图像生成实验
- 使用 class condition,512x512
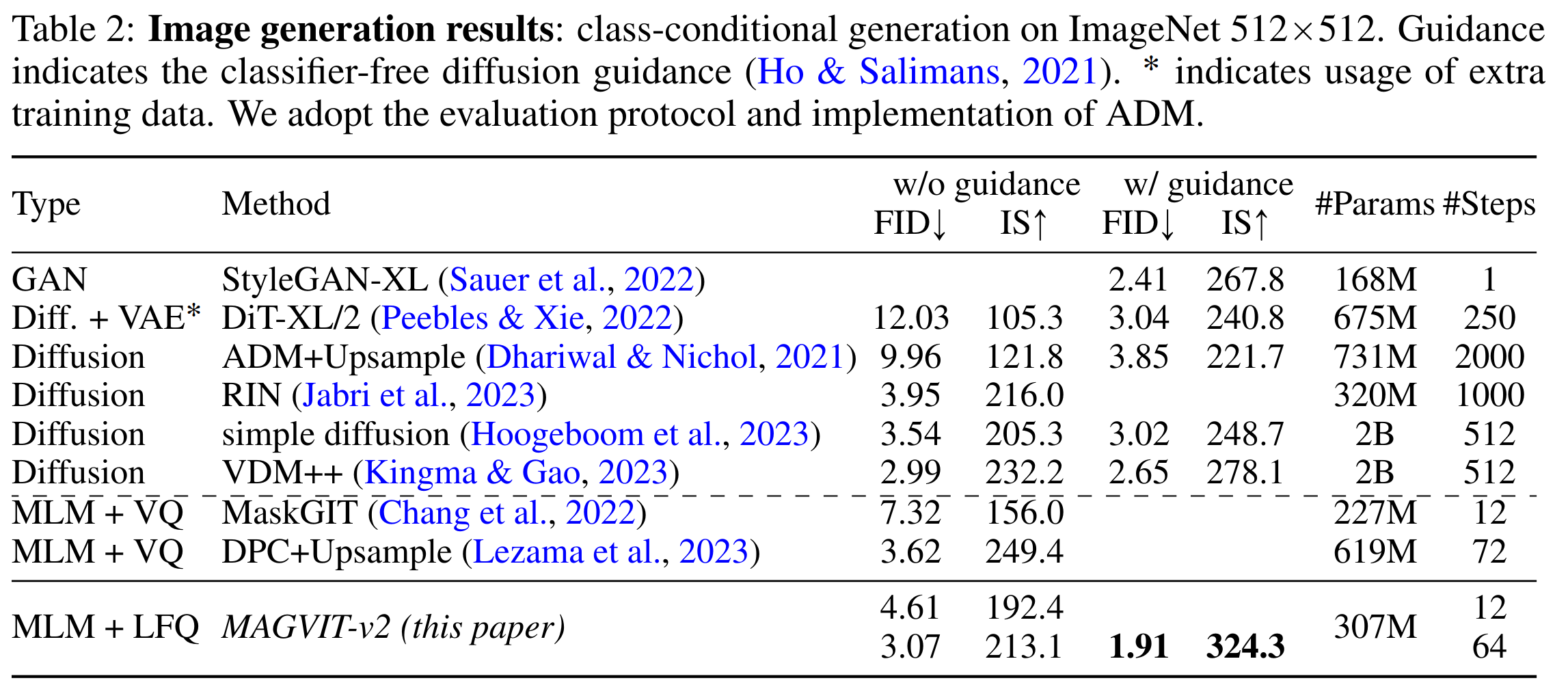
- 生成效果对比

视频压缩实验
- 和 H.265 (HEVC) 对比效果更优
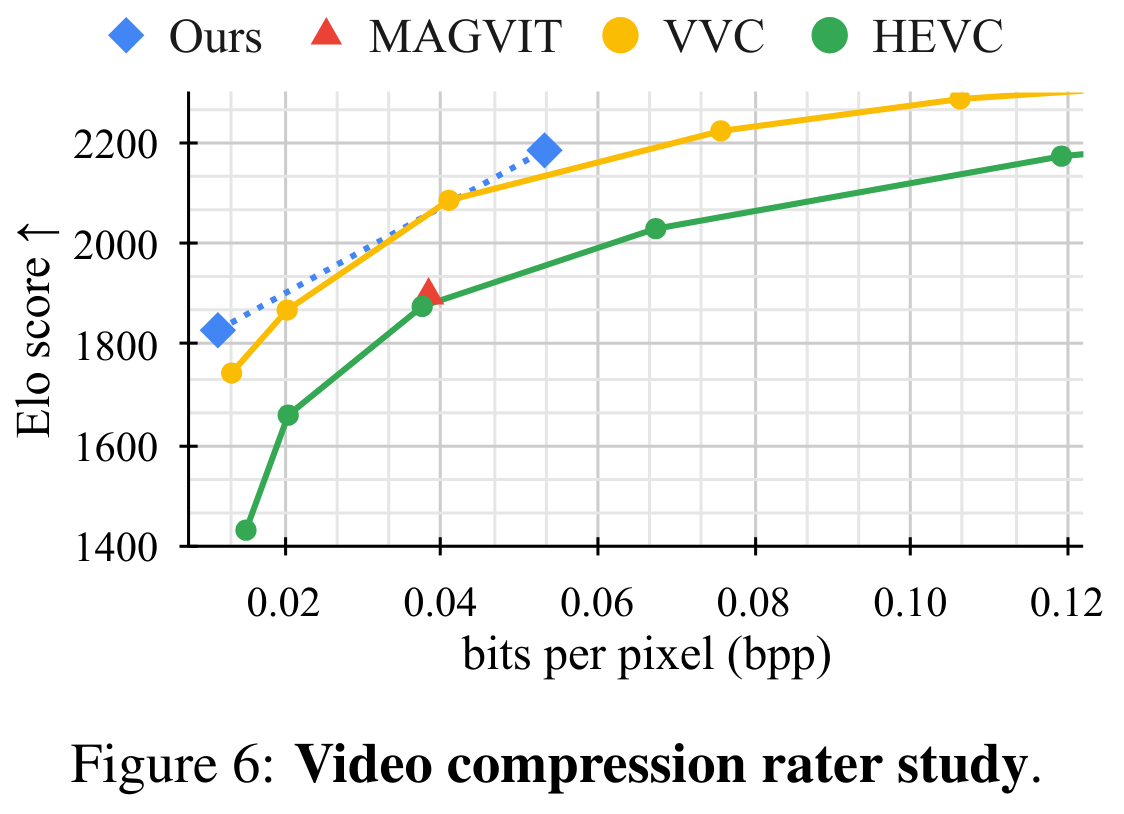
与主观感觉更解决的指标 LPIPS 上精度最高
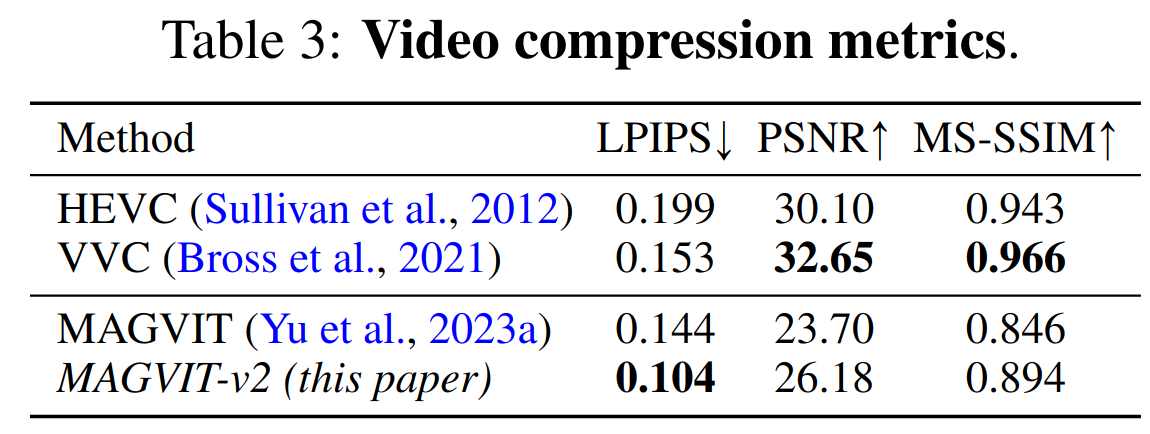
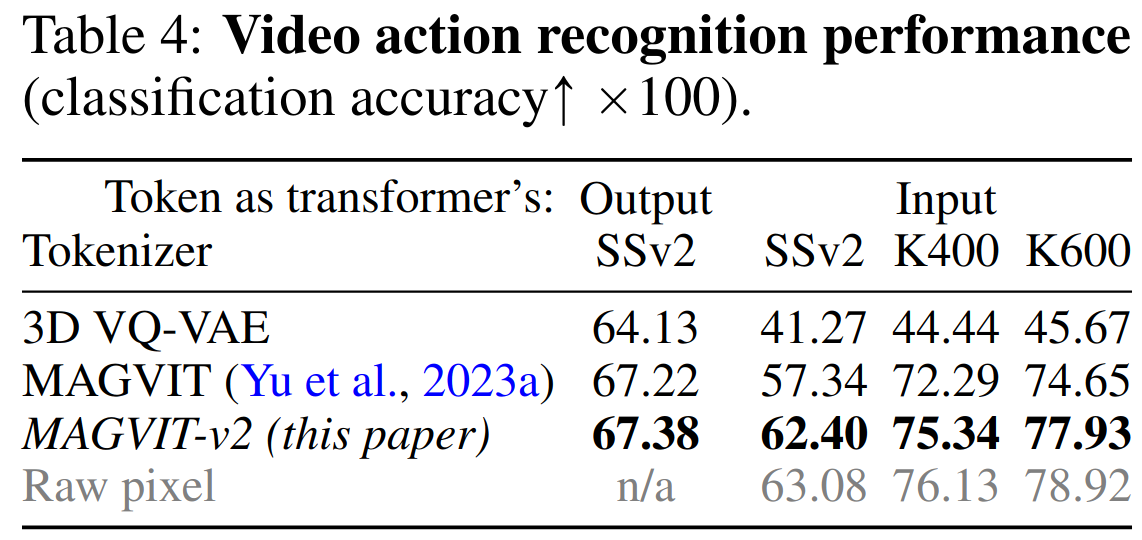
视频理解实验
- 使用 tokenizer 重建的视频作为视频理解模型的输入进行训练,可以看出结果和输入原始视频的很接近
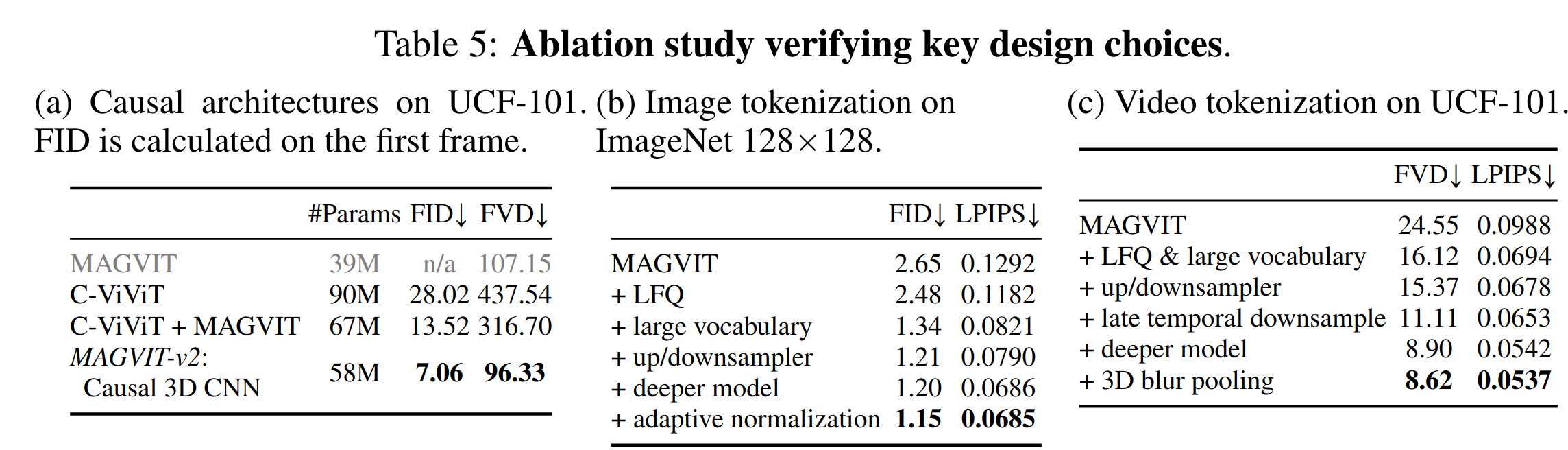
消融实验
- causal cnn 的设计在支持图像的同时让视频也涨点了;LFQ + large vocabulary 显著涨点,靠一些网络结构上的设计也有一定涨点
Thoughts
- causalcnn 的实现统一了图像与视频的 tokenizer 很有价值
- LFQ 等结构的修改带来了比较大的涨点


















 943
943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









