






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
萧箫 发自 凹非寺
转载自:量子位(QbitAI)
AI搞视频生成,已经进化到这个程度了?!
对着一张照片随手一刷,就能让被选中的目标动起来!

明明是一辆静止的卡车,一刷就跑了起来,连光影都完美还原:

原本只是一张火灾照片,现在随手一刷就能让火焰直冲天际,热度扑面而来:

这样下去,哪还分得清照片和实拍视频!
原来,这是Runway给AI视频软件Gen-2打造的新功能,一涂一刷就能让图像中的物体动起来,逼真程度不亚于神笔马良。
虽然只是个功能预热,不过效果一出就在网上爆火:
看得网友一个个变身急急国王,直呼“等不及想要尝试一波”:


Runway同时还放出了更多功能预热效果,一起来看看。
照片变视频,指哪就动哪
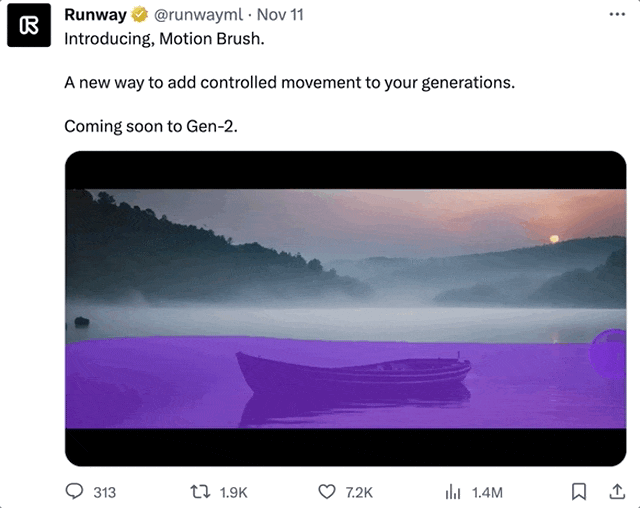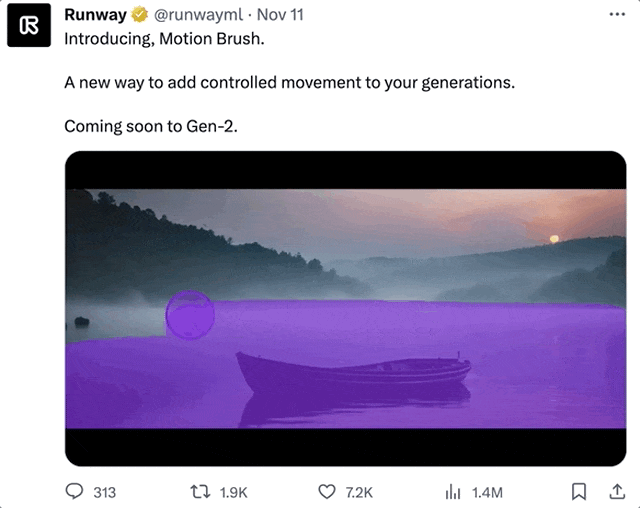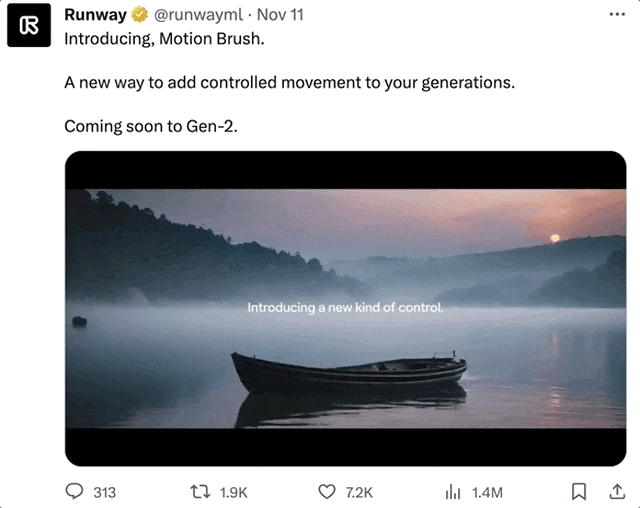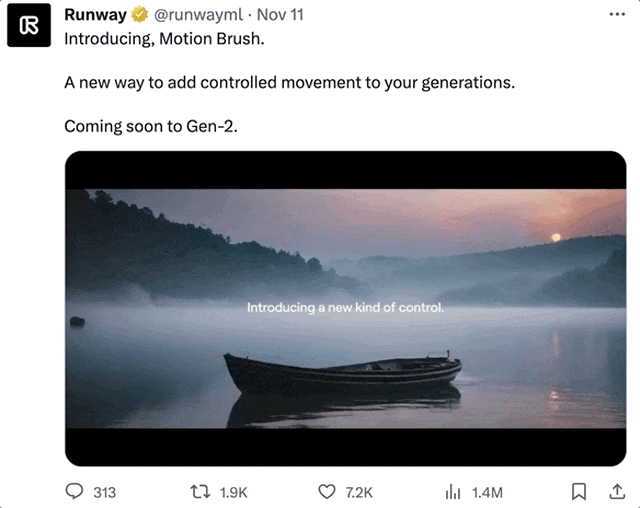
这个Runway新出的功能,叫做运动笔刷(Motion Brush)。
顾名思义,只需要用这个笔刷对着画面中的任意对象“涂”一下,就能让他们动起来。
不仅可以是静止的人,连裙摆和头部的动作都很自然:

还可以是流动的液体如瀑布,连雾气都能还原:

或者是一根还没熄灭的烟:

一团正在众人面前燃烧的篝火:

更大块的背景也能做成动态的,甚至改变画面的光影效果,例如正在飞速移动的乌云:

当然,上面这些都还是Runway“亮明牌”,主动告诉你他们对照片“做了手脚”。
下面这些没有涂抹痕迹的视频,更是几乎完全看不出有AI修饰的成分在里面:

一连串效果炸出,也导致功能还没正式放出来,网友已经迫不及待了。
不少人试图理解这个功能究竟是怎么实现的。也有网友更关注功能啥时候出,希望到时候直接321上链接(手动狗头)
确实可以期待一波了。
不过,不止是Runway推出的这个Motion Brush新功能。
最近一连串的AI生成进展似乎都在表明,视频生成领域似乎真要迎来技术大爆发了。
AI生成视频真要崛起了?
就像在这几天,还有网友开发了很火的文生动画软件Animatediff的新玩法。
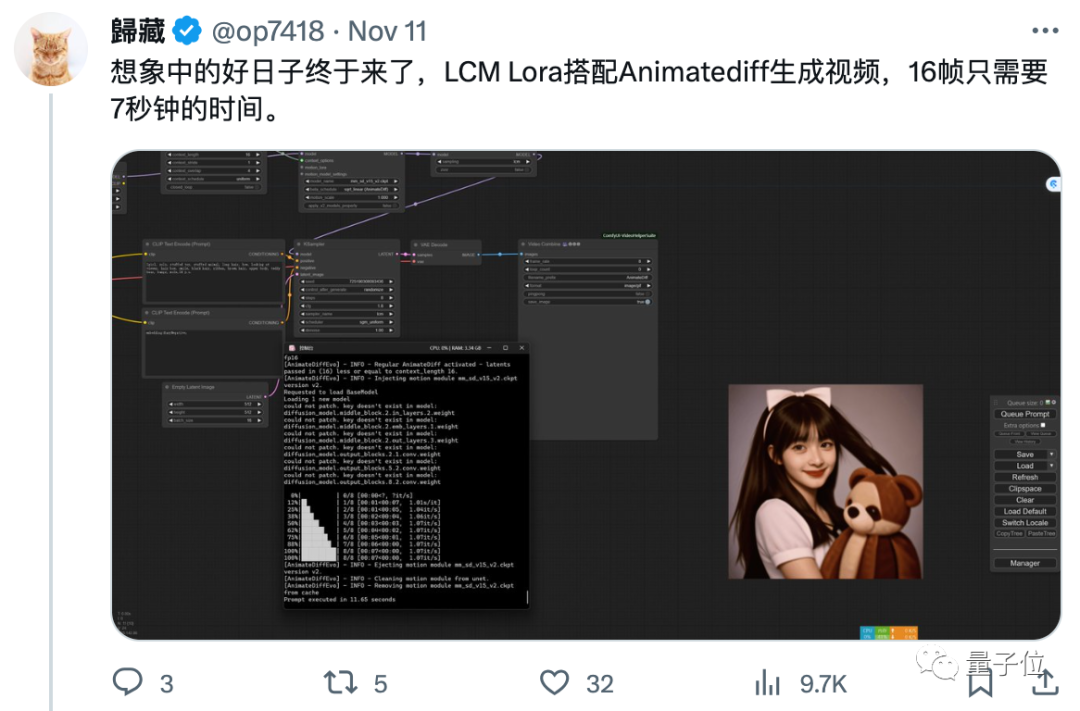
只需要结合最新的研究LCM-LORA,生成16帧的动画视频只需要7秒钟的时间。
LCM-LORA是清华大学和Hugging Face新出的一个AI图片生成技术,可以让Stable Diffusion的图片生成速度大幅提升。
其中,LCM(Latent Consistency Models)是基于今年早些时候OpenAI的“一致性模型”提出来的一种图像生成新方法,能快速生成768×768的高分辨率图片。
但LCM不兼容现有模型,因此清华和抱抱脸的成员又新出了一版LCM-LORA模型,可以兼容所有Stable Diffusion模型,加速出图速度。

结合Animatediff软件,生成一个这样的动画只需要7秒钟左右:

目前LCM-LORA已经在抱抱脸上开源。

你感觉最近的AI视频生成进展如何,距离可用上还有多远?
参考链接:
[1]https://twitter.com/runwayml/status/1723033256067489937
[2]https://twitter.com/op7418/status/1723016460220735748
CVPR / ICCV 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集计算机视觉和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer444,即可添加CVer小助手微信,便可申请加入CVer-计算机视觉或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer444,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
















 7821
7821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









