






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信:CVer444,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球,可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文搞科研,强烈推荐!

转载自:机器之心
Drive-WM 模型通过多视图世界模型,能够想象不同规划路线的未来情景,并根据视觉预测获取相应的奖惩反馈,从而优化当前的路线选择,为自动驾驶系统的安全提供了保障。
近期,世界模型的概念引发了火热浪潮,而自动驾驶领域岂能隔岸观「火」。来自中科院自动化所的团队,首次提出了一种名为 Drive-WM 的全新多视图世界模型,旨在增强端到端自动驾驶规划的安全性。

网站:https://drive-wm.github.io
论文链接:https://arxiv.org/abs/2311.17918
首个多视图预测和规划的自动驾驶世界模型
在 CVPR2023 自动驾驶的研讨会上,特斯拉和 Wayve 两大科技巨头狂秀黑科技,一种名为「生成式世界模型」的全新概念随之火爆自动驾驶领域。Wayve 更是发布了 GAIA-1 的生成式 AI 模型,展示了令人震撼的视频场景生成能力。而最近,中科院自动化所的研究者们也提出了一个新的自动驾驶世界模型 ——Drive-WM,首次实现了多视图预测的世界模型,与当下主流的端到端自动驾驶规划器无缝结合。
Drive-WM 利用了 Diffusion 模型的强大生成能力,能够生成逼真的视频场景。
想象一下,你正在开车,而你的车载系统正在根据你的驾驶习惯和路况预测未来的发展,并生成相应的视觉反馈来指导轨迹路线的选择。这种预见未来的能力和规划器相结合,将极大地提高自动驾驶的安全性!
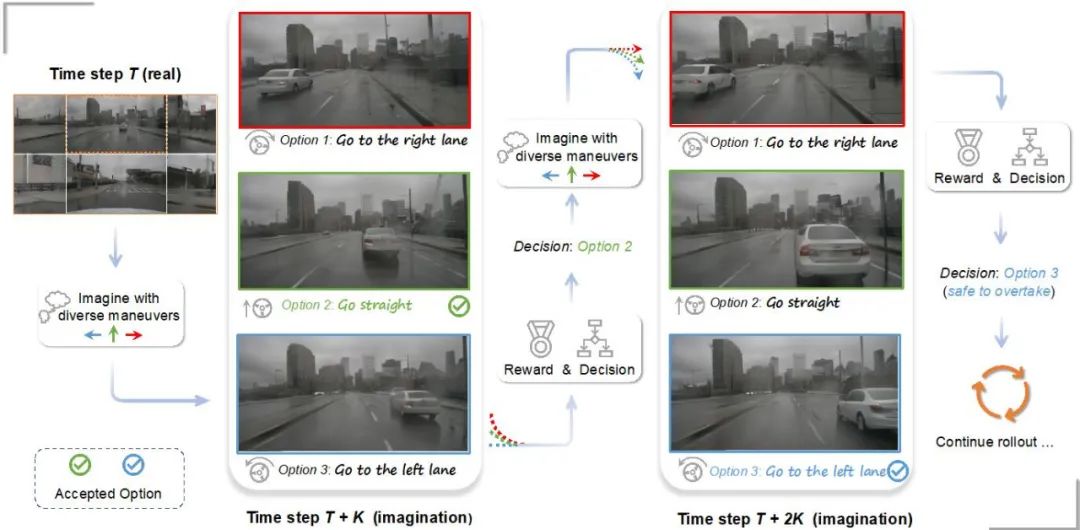
基于多视图世界模型的预测和规划。



世界模型与端到端自动驾驶的结合提升驾驶安全性
Drive-WM 模型首次将世界模型与端到端规划相结合,为端到端自动驾驶的发展打开了新的篇章。在每个时间步上,规划器可以借助世界模型预测未来可能发生的情景,再利用图像奖励函数全面评估。
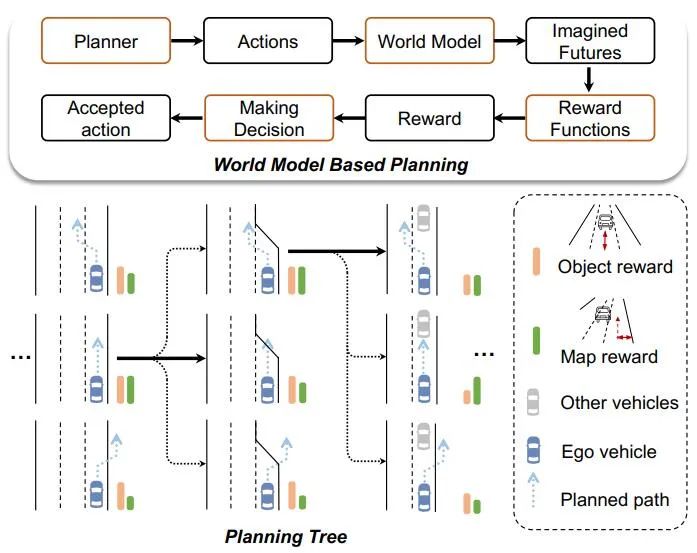
基于世界模型的端到端轨迹规划树
选择最优估计,扩展规划树,实现更安全、有效的规划。






Drive-WM 开创性地探索了世界模型在端到端规划中的两种应用:
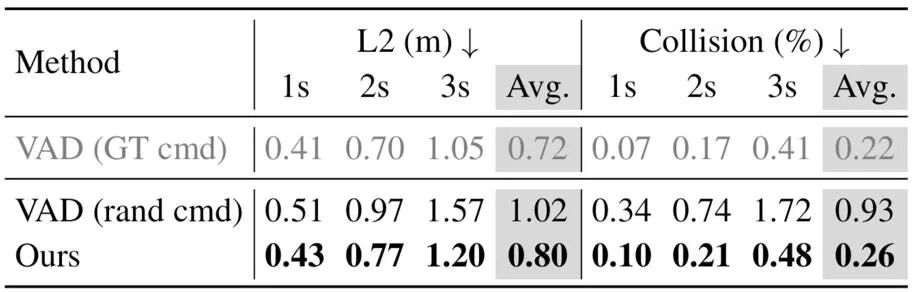
1. 展示了世界模型在面对 OOD 场景时的鲁棒性。作者通过对比实验发现了目前的端到端规划器在面对 OOD 情况时的表现并不理想。
作者给出了以下图片,当对初始位置进行轻微的横向偏移扰动后,目前的端到端规划器就难以输出合理的规划路线。

端到端规划器在面对 OOD 情况时难以输出合理的规划路线。
Drive-WM 的强大生成能力为解决 OOD 问题提供了新的思路。作者利用生成的视频来微调规划器,从 OOD 数据中进行学习,使得规划器在面对这样的场景时可以拥有更好的性能。
2. 揭示了引入未来场景评估对于端到端规划的提升作用
如何构建多视图的视频生成模型
多视图视频生成的时空一致性一直以来都是一个具有挑战性的问题。Drive-WM 通过引入时序层的编码来扩展视频生成的能力,并通过视图分解建模的方式实现多视图的视频生成。这种视图分解的生成方式可以极大地提升视图之间的一致性。
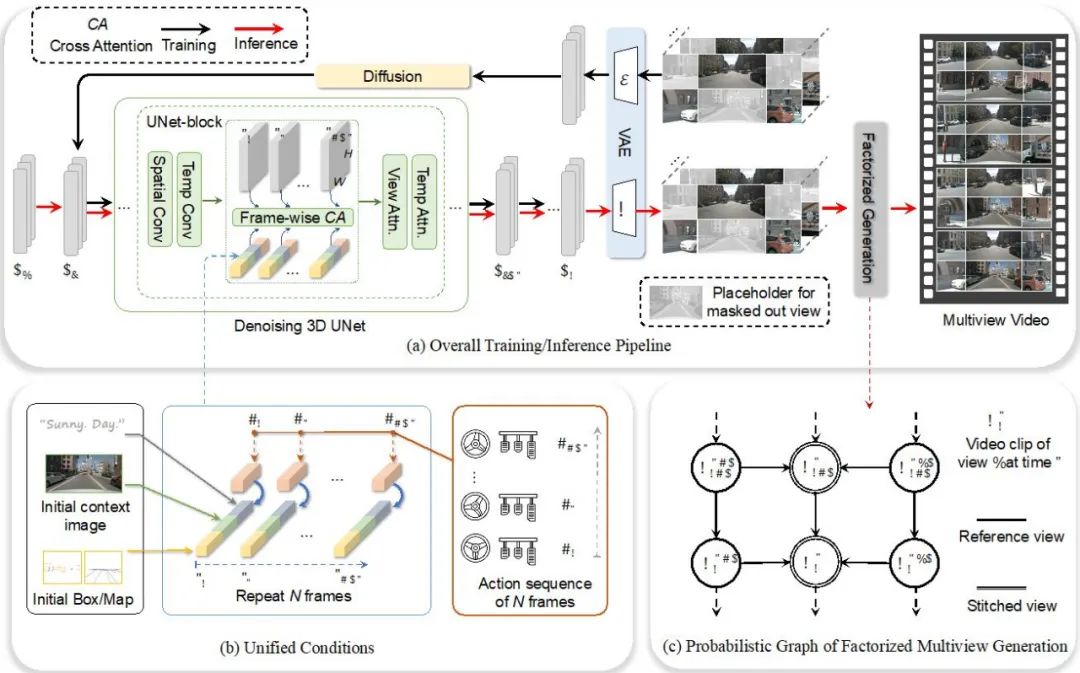
Drive-WM 整体模型设计
高质量的视频生成与可控性
Drive-WM 不仅实现了高质量的多视图视频生成,而且具有出色的可控性。Drive-WM 还提供了多种控制选项,可以通过文本、场景布局、运动信息来控制多视图视频的生成,也为将来的神经仿真器提供了新的可能性。

比如使用文本来改变天气和光照:




比如行人的生成和前景的编辑:


利用速度和方向的控制:


稀有事件的生成,例如路口掉头和开进侧方草丛:

结语
Drive-WM 不仅展示了其强大的多视图视频生成能力,也揭示了世界模型与端到端驾驶模型相结合的巨大潜力。相信在未来,世界模型可以帮助实现更安全、稳定、可靠的端到端自动驾驶系统。
CVPR 2024 论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集多模态和自动驾驶交流群成立
扫描下方二维码,或者添加微信:CVer444,即可添加CVer小助手微信,便可申请加入CVer-多模态和自动驾驶微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如多模态或者自动驾驶+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer444,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看














 3904
3904











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









