






Transformer模型最初由Google的研究人员在2017年提出,它是一种基于自注意力机制的深度学习模型,用于处理序列数据。不仅彻底改变了NLP领域,还在CV领域做出了一些开创性的工作。与卷积神经网络(CNN)相比,视觉 Transformer(ViT)依靠出色的建模能力,在 ImageNet、COCO 和 ADE20k 等多个基准上取得了非常优异的性能。随着Transformer的成功,研究人员一直在探索如何进一步改进和扩展这一架构。
5月15日,我们邀请到人工智能PHD,曾获某一区TOP期刊最佳论文奖Henry老师,为我们带来——荣登Nature!百变之王Transformer的进阶之路,深入详解Transformer最新工作进展及技术原理!
扫码免费参与直播
领导师推荐100+篇transformer必读论文&PPT原稿


部分transformer论文&ppt展示
导师简介:Henry老师
-人工智能PHD
-共发表20余篇SCI国际期刊和EI会议论文,包括一区期刊ISPRS Journal of Photogrammetry and Remote Sensing (影响因子12.7)等
-论文曾获某一区Top期刊年度最佳论文奖(为博士所在高校校史上首位获此殊荣的学者),谷歌学术被引1500余次
-研究领域:深度学习及其在计算机视觉、遥感图像处理和离岸可再生能源三大方向的应用,特别是CNN、注意力机制和视觉Transformer在图像分割、超分辨率等
直播大纲
1. Vision Transformer基础
2. Efficient ViT和加速技术
3. 自监督ViT技术
4. 多模态大模型

扫码免费参与直播
领导师推荐100+篇transformer必读论文&PPT原稿

Transformer模型的核心设计理念可以概括为以下几点:
1. 自注意力(Self-Attention)机制
-核心概念:Transformer模型的基础是自注意力机制,它允许模型在处理序列(如文本)时,对序列中的每个元素计算其与序列中其他元素的关联度。这种机制使得模型能够捕捉到序列内长距离依赖关系。
-优势:相比于之前的RNN和LSTM,自注意力机制能够在并行处理时有效地处理长距离依赖问题,显著提高了处理速度和效率。

2. 多头注意力(Multi-Head Attention)
-设计:在自注意力的基础上,Transformer引入了多头注意力机制,通过将注意力机制“拆分”成多个头并行运行,模型可以从不同的子空间学习信息。
-目的:这种设计使模型能够更好地理解语言的多种复杂关系,比如同义词和反义词关系、语法和语义关系等。
3. 位置编码(Positional Encoding)
-问题:由于Transformer完全基于注意力机制,缺乏序列的位置信息。
-解决方案:通过向输入序列的每个元素添加位置编码,模型能够利用这些信息来了解单词在句子中的位置关系。位置编码是与词嵌入相加的,以保留位置信息。
4. 编码器-解码器架构
-架构:Transformer模型包含编码器和解码器两部分。编码器用于处理输入序列,解码器则基于编码器的输出和之前的输出生成目标序列。
-特点:每个编码器和解码器层都包含多头注意力机制和前馈神经网络,通过残差连接和层归一化来优化训练过程。
5. 可扩展性和效率
-并行处理:与RNN和LSTM等序列模型相比,Transformer的自注意力机制允许对整个序列进行并行处理,显著提高了训练和推理的速度。
-适用范围:Transformer模型不仅适用于NLP任务,还被扩展到其他领域,如计算机视觉、音频处理等。
继DeepMind的新设计MoD大幅提升了 Transformer 效率后,谷歌又双叒开始爆改了!
与之前荣登Nature子刊的life2vec不同,谷歌的新成果Infini-attention机制(无限注意力)将压缩内存引入到传统的注意机制中,并在单个Transformer块中构建了掩码局部注意力和长期线性注意力机制。
这让Transformer架构大模型在有限的计算资源里处理无限长的输入,在内存大小上实现114倍压缩比。(相当于一个存放100本书的图书馆,通过新技术能存储11400本书)

扫码免费参与直播
领导师推荐100+篇transformer必读论文&PPT原稿

ViT基础
Vision Transformer(ViT)是一种基于Transformer架构的图像处理模型。它将输入图像分割成固定大小的patch,并将每个patch转换成向量表示,然后送入Transformer模型进行处理。通过自注意力机制,ViT能够有效地捕获图像中的全局和局部信息,从而在图像分类、语义分割和目标检测等任务上取得优异表现。

图1. Vision Transformer架构
Efficient Transformer和加速技术
尽管ViT在图像处理任务上取得了显著成绩,但其计算量较大,训练和推理速度较慢。为了解决这一问题,研究人员提出了一系列加速技术,如窗口注意力机制、多尺度处理、稀疏注意力等。此外,Efficient Transformer模型也在降低计算复杂度的同时保持了较好的性能,为ViT的实际应用提供了可能。
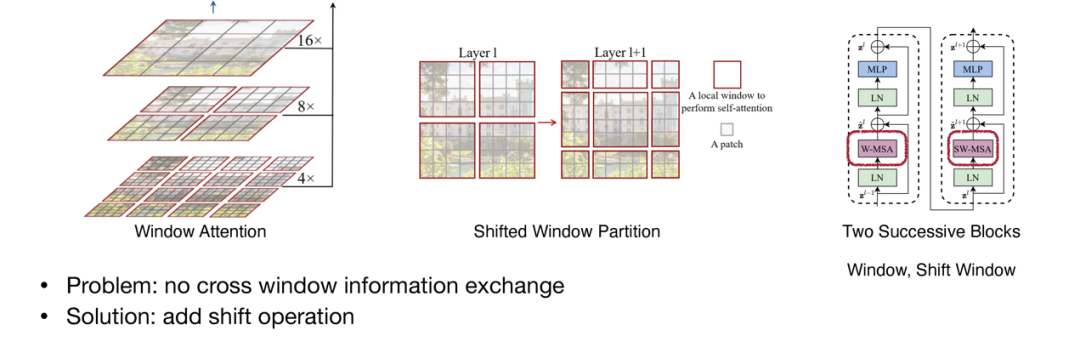
图2. Swin Transformer中的Window Attention
Transformer自监督学习
除了监督学习,Transformer模型还可以通过自监督学习进行预训练。在自监督学习中,模型通过利用输入数据的内在结构进行训练,无需人工标注的标签。这种方法不仅能够提高模型的泛化能力,还能够有效利用大规模未标记的数据进行预训练,为模型的迁移学习提供了更好的基础。

图3. 无监督学习中的对比学习
多模态LLM
除了单一模态的图像处理,Transformer模型还可以处理多模态数据,如文本和图像的联合处理。通过引入多模态LLM(Language-Image Models),模型能够同时理解文本和图像之间的关系,从而在视觉问答、图像标注等任务上取得更好的效果。
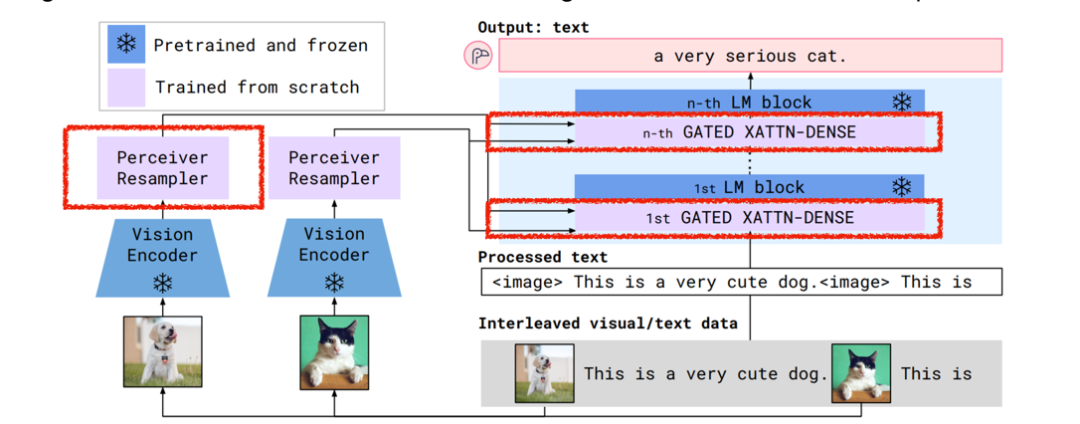
图4. Flamingo架构示意图

图5. PaLM-E架构示意图
对于想要发表论文,对科研感兴趣或正在为科研做准备的同学,想要快速发论文有两点至关重
对于还没有发过第一篇论文,还不能通过其它方面来证明自己天赋异禀的科研新手,学会如何写论文、发顶会的重要性不言而喻。
发顶会到底难不难?近年来各大顶会的论文接收数量逐年攀升,身边的朋友同学也常有听闻成功发顶会,总让人觉得发顶会这事儿好像没那么难!
但是到了真正实操阶段才发现,并不那么简单,可能照着自己的想法做下去并不能写出一篇好的论文、甚至不能写出论文。掌握方法,有人指点和引导很重要!
还在为创新点而头秃的CSer,还在愁如何写出一篇好论文的科研党,一定都需要来自顶会论文作者、顶会审稿人的经验传授和指点。
很可能你卡了很久的某个点,在和学术前辈们聊完之后就能轻松解决。
扫描二维码
与大牛导师一对一meeting

文末福利
给大家送一波大福利!我整理了100节计算机全方向必学课程,包含CV&NLP&论文写作经典课程,限时免费领!


立即扫码 赠系列课程
-END-














 59
59











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









