






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信:CVer5555,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!

引言
近期多模态大模型(MLLM)在视觉文本理解领域取得了显著进展,比如开源模型InternVL 1.5、MiniCPM-Llama3-V 2.5、TextMonkey, 闭源模型GPT-4o、Claude等,甚至在某些方面展现了超越人类的能力。然而,当前的评估主要集中在英文和中文的语言环境中,对于更具挑战的多语种环境,研究还相对缺乏。在全球化的今天,多语言环境越来越多的出现在人们日常生活中,也给人工智能的发展带来了很大的挑战。MTVQA(Multilingual Text-Centric Visual Question Answering)基准测试正是在这样的背景下应运而生,专注于以多语言文字为中心的视觉问答,旨在填补现有评测基准在多语种视觉文本领域的空白。MTVQA涵盖了阿拉伯语、韩语、日语、泰语、越南语、俄语、法语、德语和意大利语等9种语言,收集整理了自然场景和文档场景下的多语种富文本图片,如菜单、路标、地图、账单、PPT、论文、图表等。问答对都经过人类专家的精心标注,以确保视觉文本与问题及答案之间的高度一致性。
在MTVQA基准的测试结果显示,无论是开源模型还是最先进的闭源模型如GPT-4o (Acc. 27.8%),准确率不到30%,开源的文档类专家大模型表现也不尽如人意。
无论从哪方面来看,多语种文字理解能力都还有较大的提升空间。MTVQA重点关注除中英文以外广泛使用的语言,希望能促进多语种文字理解能力的发展,将多模态大模型的成果普及到更多的国家和地区。

论文:https://arxiv.org/abs/2405.11985
项目:https://bytedance.github.io/MTVQA/

图1 MTVQA中不同语种和场景样例展示
1. 背景介绍
视觉文本理解能力是多模态大模型能力中的一个关键维度,现有的benchmark如DocVQA、TextVQA、STVQA等在GPT-4o、Gemini 、Internlm VL等先进的闭源和开源MLLMs的测评中发挥了重要作用,评估了多模态大模型在不同维度的视觉文本理解能力,但是他们都专注于中英文能力的测评,缺少一个能够测评其他语种理解能力的benchmark。针对这些不足,字节和华科的研究者提出了MTVQA,首个全面测评多场景多语种视觉文本理解能力的benchmark。
2. MTVQA的构建过程
a) 数据收集
测试集包括1220张泛文档类的图片和876张自然场景的图片,数据来源可分为三部分:
(1) 网络收集的图片,如PPT、paper、logo等。
(2) 实地采集拍摄图片,包括各种场景,时间跨度2023年3月到2024年3月。
(3) 现有公开数据,从ICDAR MLT19的公开图片中采样了一些具有代表性的场景文本图片。
b) 数据标注
所有QA数据均为经过培训的母语人士进行标注,并进行多轮交叉验证,确保问题的丰富性和答案的准确性。
标注规则:
1. 问题必须和图片中的文字内容有关
2. 每张图片包括3个可以直接问答的问题和2个需要进行一定推理的问题
3. 答案尽可能和图片中的文字保持一致
4. 答案尽可能简短,不重复问题的内容
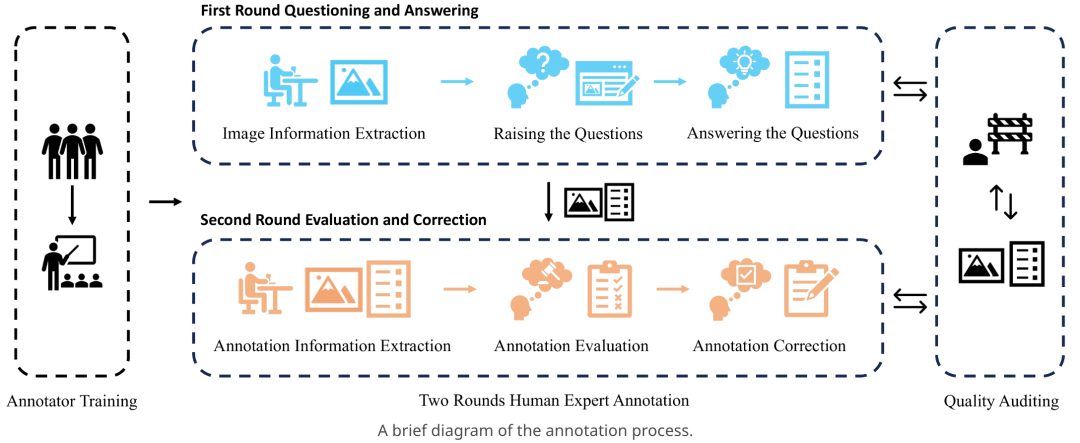
图二 MTVQA 数据标注流程
交叉评估和修改:
1. 评估问题和图片中文本内容的相关性
2. 评估答案的准确性和完整性
3. 道德评估,判断是否符合人类道德规范
c) 数据集概览
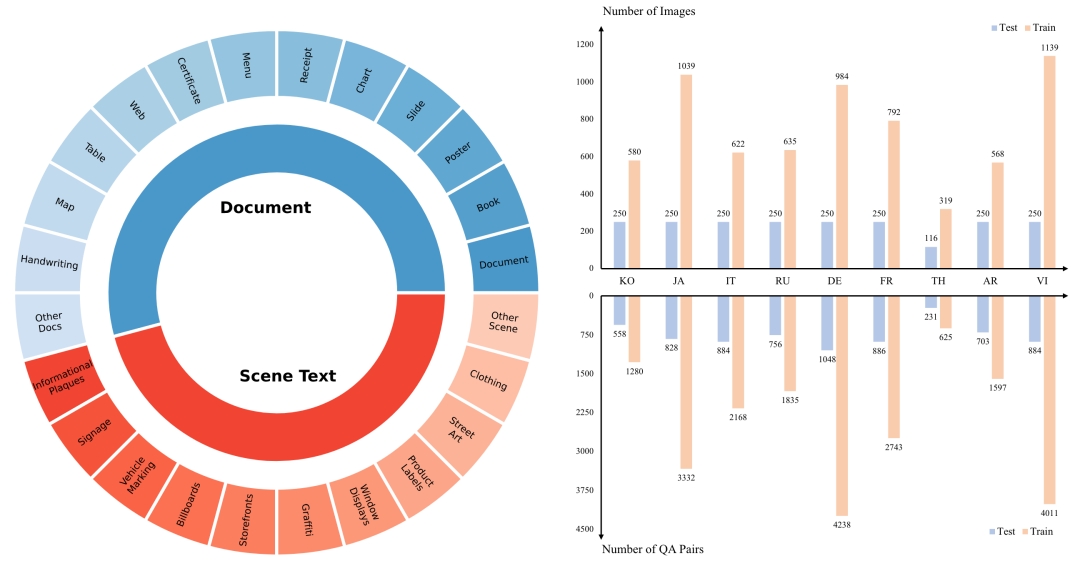
图三 MTVQA涵盖的丰富场景以及不同语种的QA数量

图4 Word Cloud
3. MLLMs在MTVQA Bench上的表现
在MTVQA上对19个先进的MLLM进行来测评,包括开源和闭源模型,测评结果如下:
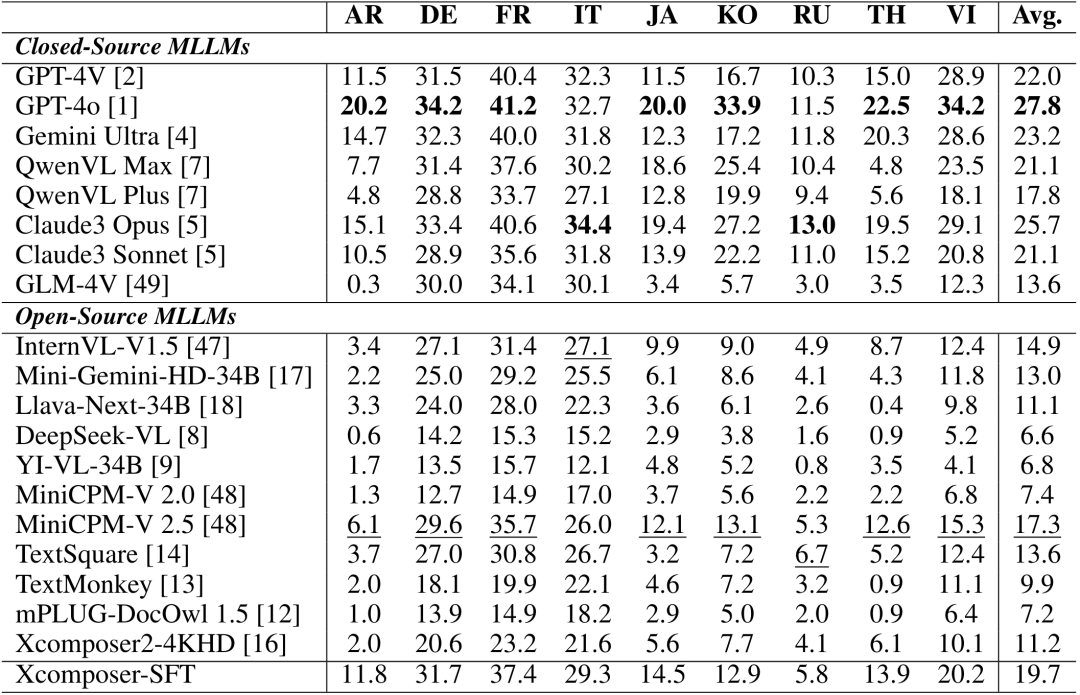
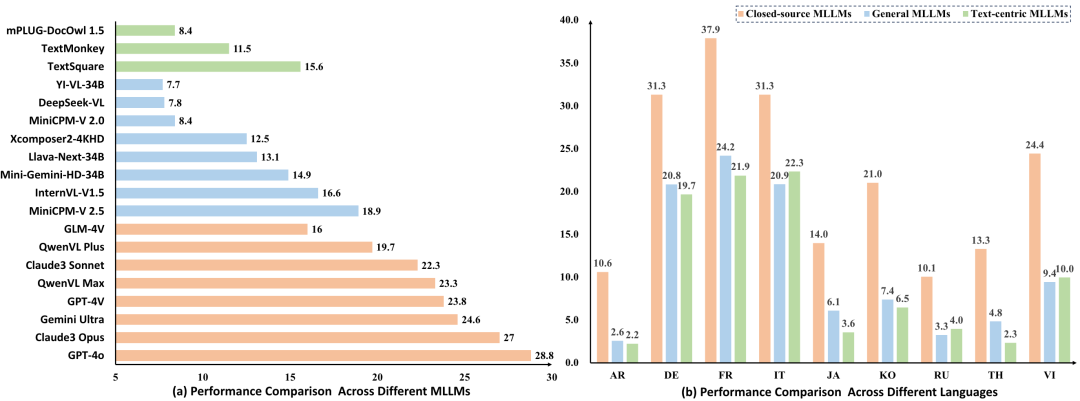
实验结果发现:
a. 多语种文字理解现阶段任然是非常有挑战性的任务。尽管GPT-4o在大部分语种和总体成绩上取得了第一名的成绩,但是平均准确率只有27.8,相比于多模态大模型的英文理解能力,差距明显,更别谈和人类的差距了。
b. 开源模型和闭源模型存在较大的差距。最优的开源模型是MiniCPM-V 2.5,取得了18.9%的成绩,但距离顶尖的闭源模型如QwenVL Max, Gemini Ultra, Claude3 Opus, GPT-4o等还比较远。
c. 以文字理解为中心的多模态大模型并没有明显的优势。研究者选取了最近的3个以视觉文字理解为中心的MLLM,mPLUG-DocOwl 1.5,TextMonkey,TextSquare,发现最优的TextSquare相比通用MLLM MiniCPM-V 2.5并没有优势(15.6 vs. 18.9)。
d. 不同语种的理解能力差距明显。拉丁类的语种如意大利语、德语、法语的表现远好于非拉丁类语种如日语、韩语、俄语。这应该是由于拉丁类语种在视觉和语义上都和英文更相似。
4. 总结
来自字节跳动和华中科大的研究者们针对多语种视觉文本理解任务提出了新的测评基准MTVQA Bench,并对多模态大模型的表现进行了测评和分析。研究发现,多语种视觉理解任务难度很大,当前多模态大模型表现较差,距离人类的水平还有很长的路要走。研究者们期待后续多模态大模型的研究和发展更加关注多语种场景,扩大多模态大模型的应用范围,使得更多国家和地区的人们能够参与其中,共享人工智能带来的便利。
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!CVPR 2024 论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集Mamba、多模态和扩散模型交流群成立
扫描下方二维码,或者添加微信:CVer5555,即可添加CVer小助手微信,便可申请加入CVer-Mamba、多模态学习或者扩散模型微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer5555,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请赞和在看
















 2898
2898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









