






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信号:CVer111,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!

转载自:机器之心
在刚刚过去的一天,来自清华的光电智能技术交叉创新团队突破智能光计算训练难题,相关论文登上 Nature。
论文共同一作是来自清华的薛智威、周天贶,通讯作者是清华的方璐教授、戴琼海院士。此外,清华电子系徐智昊、之江实验室虞绍良也参与了这项研究。

论文地址:https://www.nature.com/articles/s41586-024-07687-4
论文标题:Fully forward mode training for optical neural networks
随着大模型的规模越来越大,算力需求爆发式增长,就拿 Sora 来说,据爆料,训练参数量约为 30 亿,预计使用了 4200-10500 块 H100 训了 1 个月。全球的科技大厂都在高价求购的「卡」,都是硅基的电子芯片。在此之外,还有一种将计算载体从电变为光的光子芯片技术。它们利用光在芯片中的传播进行计算,具有超高的并行度和速度,被认为是未来颠覆性计算架构最有力的竞争方案之一。
光计算领域也在使用 AI 辅助设计系统。然而,AI 也给光计算技术套上了「瓶颈」—— 光神经网络训练严重依赖基于数据对光学系统建模的方法。这导致研究人员难以修正实验误差。更重要的是,不完善的系统加上光传播的复杂性,几乎不可能实现对光学系统的完美建模,离线模型与现实之间总是难以完全同步。
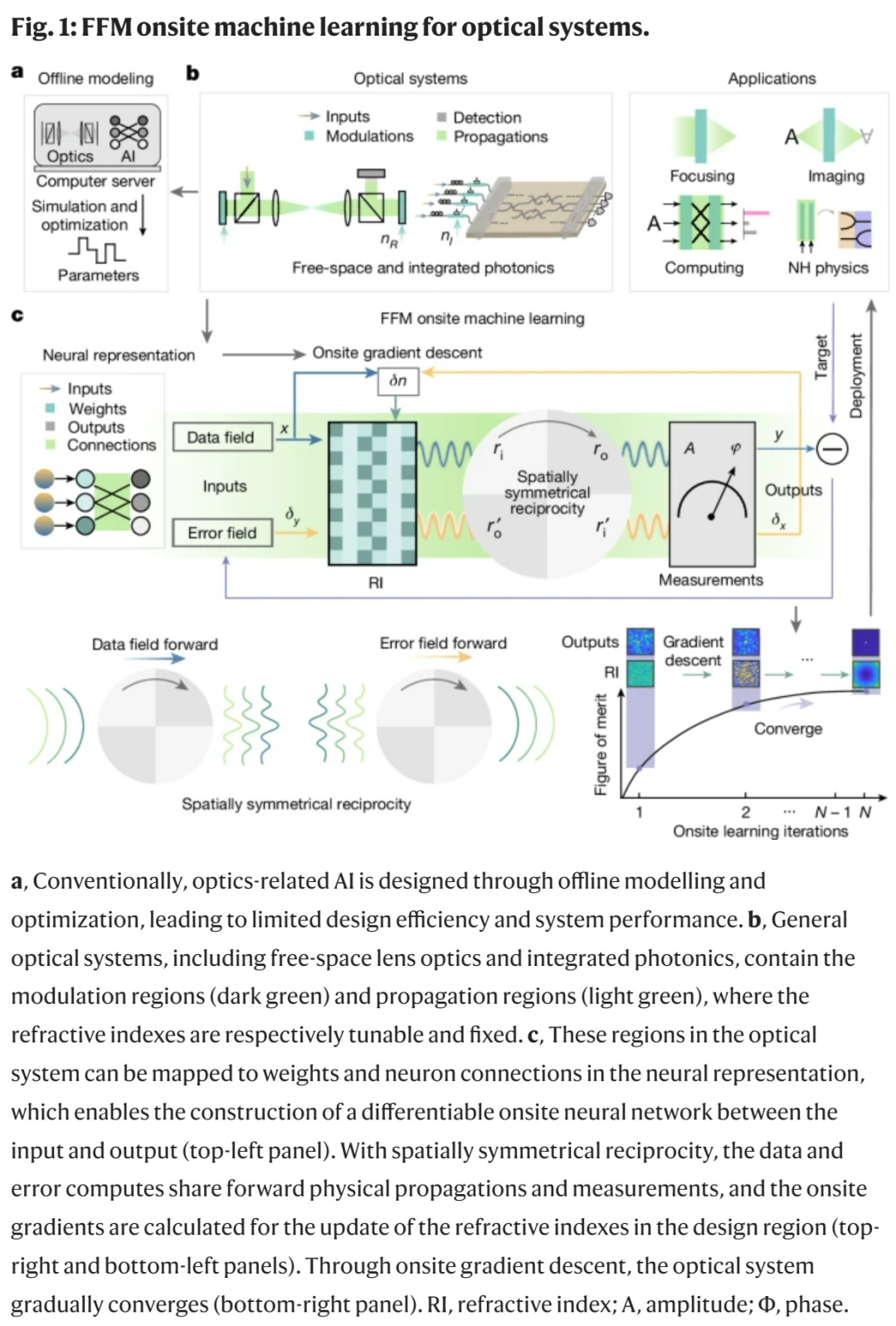
而机器学习常用的「梯度下降」和「反向传播」,来到了光学领域,也不好使了。为了使基于梯度的方法有效,光学系统必须非常精确地校准和对齐,以确保光信号能够正确地在系统中反向传播,离线模型往往很难实现这点。
来自清华大学的研究团队抓住了光子传播具有对称性这一特性,将神经网络训练中的前向与反向传播都等效为光的前向传播。该研究开发了一种称为全前向模式(FFM,fully forward mode)学习的方法,研究人员不再需要在计算机模型中建模,可以直接在物理光学系统上设计和调整光学参数,再根据测量的光场数据和误差,使用梯度下降算法有效地得出最终的模型参数。借助 FFM,大多数机器学习操作都可以有效地并行进行,从而减轻了 AI 对光学系统建模的限制。
FFM 学习表明,训练具有数百万个参数的光神经网络可以达到与理想模型相当的准确率。
此外,该方法还支持通过散射介质进行全光学聚焦,分辨率达到衍射极限;它还可以以超过千赫兹的帧率平行成像隐藏在视线外的物体,并可以在室温下进行光强弱至每像素亚光子的全光处理。
最后,研究证明了 FFM 学习可以在没有分析模型的情况下自动搜索非厄米异常点。FFM 学习不仅有助于将学习过程提高几个数量级,还可以推动深度神经网络、超灵敏感知和拓扑光学等应用和理论领域的发展。
深度 ONN 上的并行 FFM 梯度下降
图 2a 展示了使用 FFM 学习的自由空间 ONN(optical neural networks,光学神经网络)的自我训练过程。为了验证 FFM 学习的有效性,研究者首先使用基准数据集训练了一个单层 ONN 以进行对象分类。
图 2b 可视化了在 MNIST 数据集上的训练结果,可以看到,实验和理论光场之间的结构相似性指数(SSIM)超过了 0.97,这意味着相似度很高(图 2c)。值得注意的是,由于系统不完善的原因,光场和梯度的理论结果并不能精准地代表物理结果。因此,这些理论结果不应被视为基本事实。
接下来,研究者探究了用于 Fashion-MNIST 数据集分类的多层 ONN,具体如图 2d 所示。
通过将层数从 2 层增加到 8 层,他们观察到,计算机训练网络的实验测试结果平均达到了 44.0% (35.1%)、52.4%(8.8%)、58.4%(18.4%)和 58.8%(5.5%)的准确率(两倍标准差)。这些结果低于 92.2%、93.8%、96.0% 和 96.0% 的理论准确率。通过 FFM 学习,准确率数值分别提升到了 86.5%、91.0%、92.3% 和 92.5%,接近理想的计算机准确率。
图 2e 描述了 8 层 ONN 的输出结果。随着层数增加,计算机训练的实验输出逐渐偏离目标输出并最终对对象做出误分类。相比之外,FFM 设计的网络可以准确地进行正确分类。除了计算密集型数据和误传播之外,损失和梯度计算还可以通过现场光学和电子处理来执行。
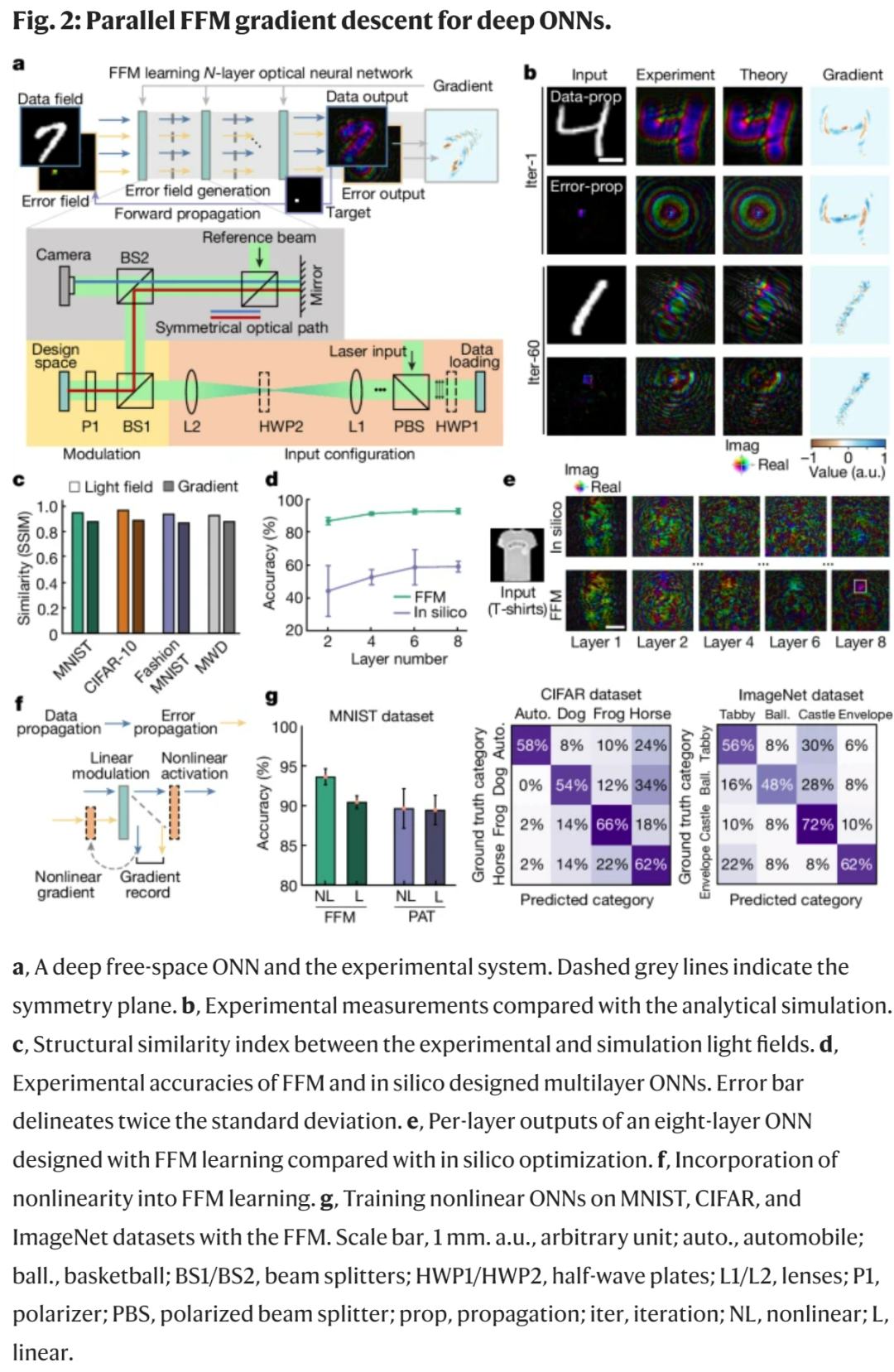
研究者进一步提出了非线性 FFM 学习,如图 2f 所示。在数据传播中,输出在馈入到下一层之前被非线性地激活,记录非线性激活的输入并计算相关梯度。在误差传播过程中,输入在传播之前与梯度相乘。
利用 FFM 进行全光学成像和处理
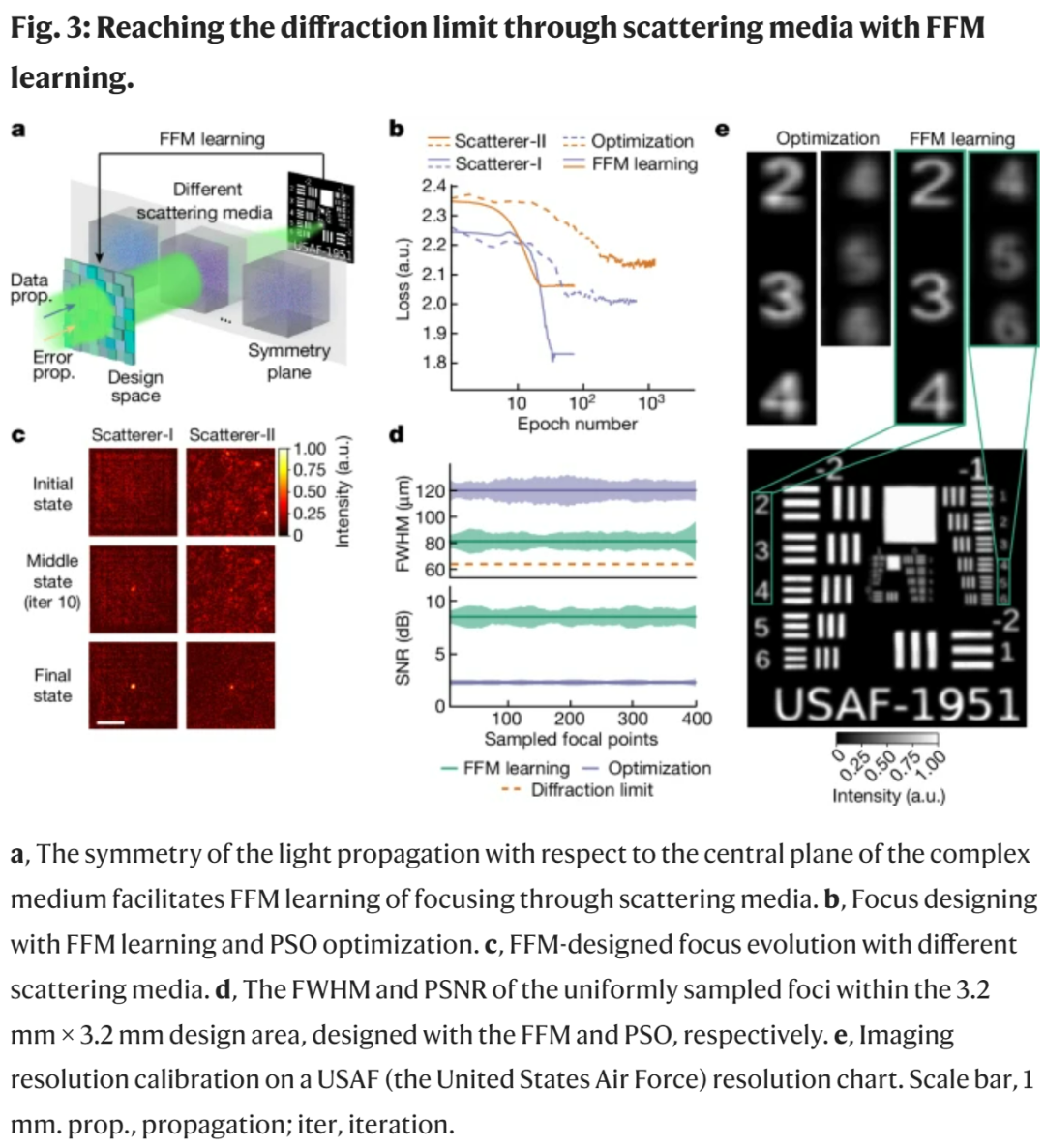
图 3a 展示了点扫描散射成像系统的实现原理。一般来说,在自适应光学中,启发式优化方法已经用于焦点优化。
研究者分析了不同的 SOTA 优化方法,并利用粒子群优化(PSO)进行比较,如图 3b 所示。出于评估的目的,这里采用了两种不同类型的散射介质,分别是随机相位板(称为 Scatterer-I)和透明胶带(称为 Scatterer-II)。基于梯度的 FFM 学习表现出更高的效率,在两种散射介质的实验中经过 25 次迭代后收敛,收敛损耗值分别为 1.84 和 2.07。相比之下,PSO 方法需要至少 400 次迭代后才能进行收敛,最终损耗值为 2.01 和 2.15。
图 3c 描述了 FFM 自我设计的演变过程,展示了最开始随机分布的强度逐渐分布图逐渐收敛到一个紧密的点,随后在整个 3.2 毫米 × 3.2 毫米成像区域来学习设计的焦点。
图 3d 比较了使用 FFM 和 PSO 分别优化的焦点的半峰全宽(FWHM)和峰值信噪比(PSNR)指标。使用 FFM,平均 FWHM 为 81.2 µm,平均 PSNR 为 8.46 dB,最低 FWHM 为 65.6 µm。当使用 3.2mm 宽的方形孔径和 0.388m 的传播距离时,通过 FFM 学习设计的焦点尺寸接近衍射极限 64.5 µm。相比之下,PSO 优化产生的 FWHM 为 120.0 µm,PSNR 为 2.29 dB。
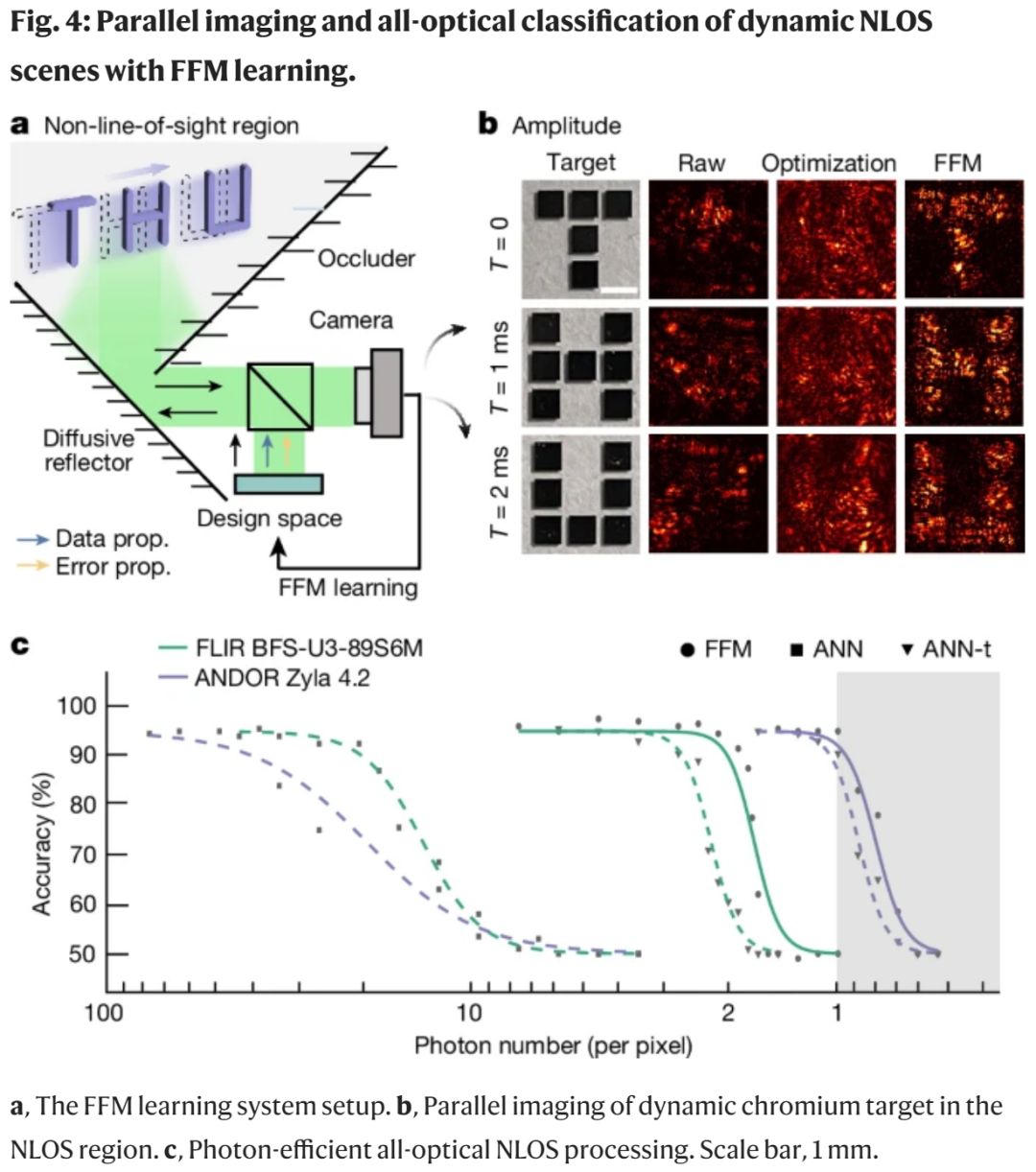
在图 4a 中,利用往返隐藏对象的光路之间的空间对称性,FFM 学习可以实现动态隐层对象的全光学现场重建和分析。图 4b 展示了 NLOS 成像,在学习过程中,输入波峰被设计用来将对象中所有网格同步映射到它们的目标位置。
现场光子集成电路与 FFM
FFM 学习方法可以推广到集成光系统的自设计中。图 5a 展示了 FFM 学习实现过程。其中矩阵的对称性允许误差传播矩阵和数据传播矩阵之间对等。因此,数据和误差传播共享相同的传播方向。图 5b 展示了对称核心实现和封装芯片实验的测试设置。
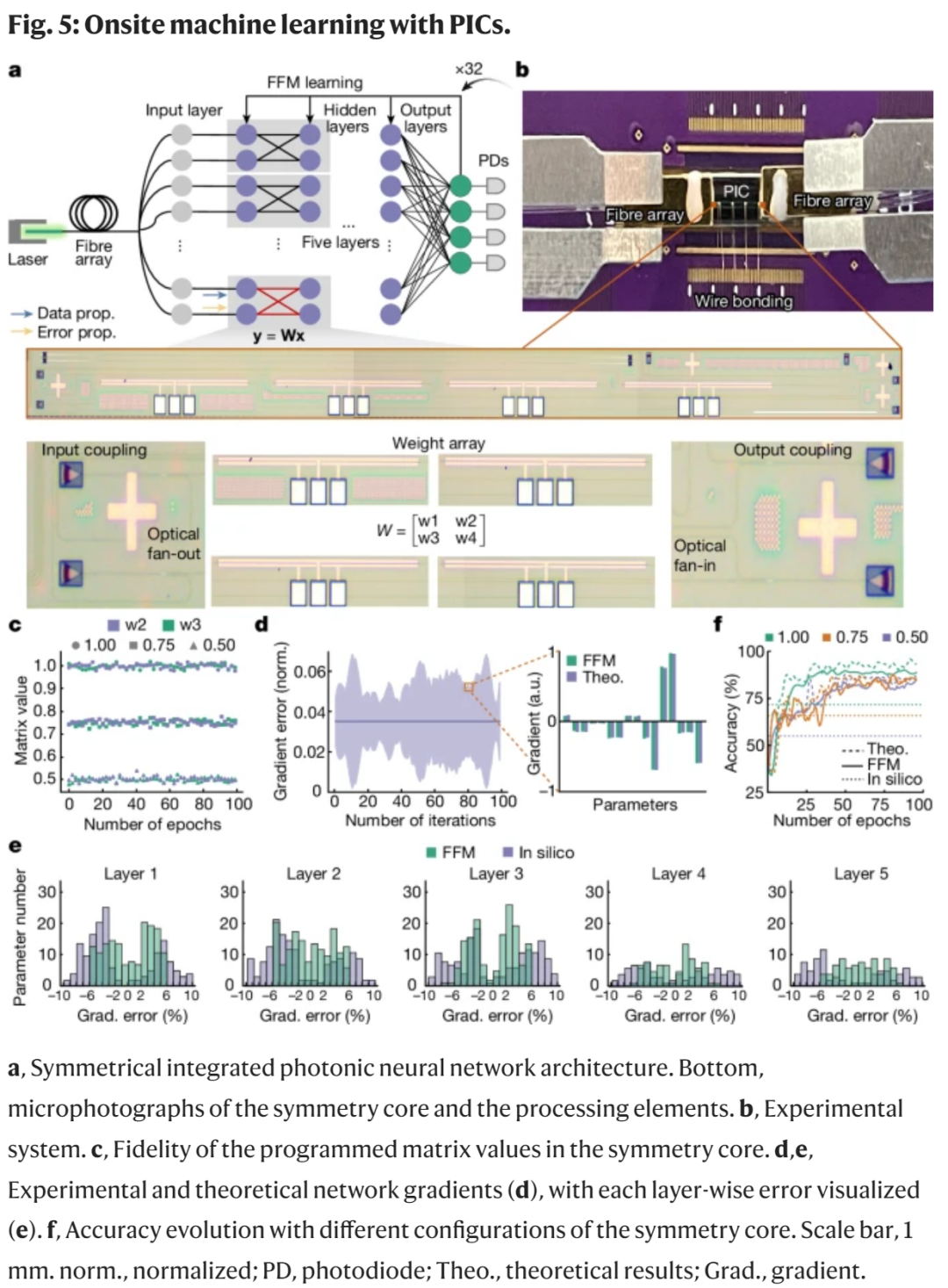
研究者构建的神经网络用于对鸢尾花(Iris)数据进行分类,输入处理为 16 × 1 向量,输出代表三种花的类别之一。训练期间矩阵编程的保真度如图 5c 中所示,三个对称矩阵值的时间漂移分别产生了 0.012%、0.012% 和 0.010% 的标准偏差。
在这种不确定下,研究者将实验梯度与模拟值进行比较。如图 5d 所示,实验梯度与理想模拟值的平均偏差为 3.5%。图 5d 还说明了第 80 次学习迭代时第二层的设计梯度,而整个神经网络的误差在图 5e 中进行了可视化。在第 80 次迭代中,FFM 学习(计算机模拟训练)的梯度误差为 3.50%(5.10%)、3.58%(5.19%)、3.51%(5.24%)、3.56%(5.29%)和 3.46%(5.94%)。设计精度的演变如图 5f 所示。理想模拟和 FFM 实验都需要大约 100 个 epoch 才能收敛。在三种对称率配置下,实验性能与模拟性能相似,网络收敛到 94.7%、89.2% 和 89.0% 的准确率。FFM 方法实现了 94.2%、89.2% 和 88.7% 的准确率。相比之下,计算机设计的网络表现出 71.7%、65.8% 和 55.0% 的实验准确率。
基于这篇论文的成果,研究团队也推出了「太极 - II」光训练芯片。「太极 - II」的研发距离上一代「太极」仅过了 4 个月,相关成果也登上了 Science。
论文链接:https://www.science.org/doi/10.1126/science.adl1203
值得一提的是,作为全球首款大规模干涉衍射异构集成芯片的「太极」,其计算能力可以比肩亿级神经元的芯片。论文的实验结果显示,「太极」的能效是英伟达 H100 的 1000 倍。这种强大的计算能力基于研究团队首创的分布式广度智能光计算架构。
更多细节,请参考原论文。
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!
ECCV 2024 论文和代码下载
在CVer公众号后台回复:ECCV2024,即可下载ECCV 2024论文和代码开源的论文合集CVPR 2024 论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集Mamba、多模态和扩散模型交流群成立
扫描下方二维码,或者添加微信号:CVer111,即可添加CVer小助手微信,便可申请加入CVer-Mamba、多模态学习或者扩散模型微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer111,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集上万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请赞和在看

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









